- 解密 Python 的 MRO:C3 线性化如何优雅解决多重继承的菱形难题》
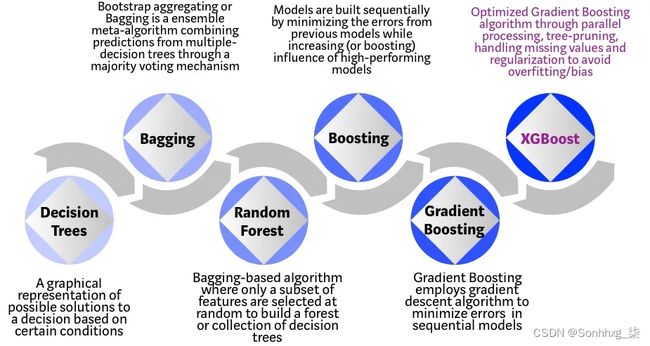
《解密Python的MRO:C3线性化如何优雅解决多重继承的菱形难题》引言:继承的优雅与复杂在Python的面向对象编程中,继承是一种强大的机制,它让我们能够复用代码、构建抽象层次、实现多态行为。然而,当我们引入多重继承时,继承体系的复杂性也随之而来,尤其是著名的“菱形继承问题”。Python通过一种称为C3线性化(C3Linearization)的算法来解决方法解析顺序(MethodResolu
- 《深入理解 Python 的对象构造机制:__new__ 与 __init__ 的本质区别与实战应用》
清水白石008
开发语言学习笔记课程教程python开发语言
《深入理解Python的对象构造机制:new与init的本质区别与实战应用》引言:对象的诞生之谜在Python的面向对象编程中,我们习惯于使用__init__方法来初始化对象。但你是否曾注意到,还有一个鲜为人知却至关重要的魔法方法——__new__?它是对象构造过程的起点,掌控着类实例的真正创建。理解__new__与__init__的区别,不仅能帮助你掌握Python的对象模型,还能在构建不可变类
- 数据库
小胡123
数据库长期保存在计算机的存储设备上,按照一定规则组织起来,可被各种用户或应用共享的数据集合数据库系统(DBS)采用数据库技术的计算机系统,由数据库,数据库管理系统,数据库管理员,硬件平台,软件平台构成数据库管理系统(DBMS)是操作和管理数据库的软件,用于建立,使用和维护数据库,对数据库进行统一管理和控制提供的功能:数据定义语言(DDL)数据操作语言(DML)数据控制语言(DCL)数据存储方式:l
- Day9: OpenCV学习(一)—— 图像基础
系列文章目录上一篇:Day8:Python工程化——模块、包文章目录系列文章目录前言一、安装和导入1.安装二、图像认识1.图像2.图像分类三、基础图像操作1.图像读取2.图像显示3.图像裁剪4.图形尺寸修改5.图像保存6.图像绘制7.视频捕获即显示总结前言OpenCV(OpenSourceComputerVisionLibrary)是一个开源的计算机视觉和机器学习软件库。由一系列C++类和函数构成
- python基础语法复习04——函数
洛华363
pythonpython
python基础语法目录python基础语法01——基本类型python基础语法02——复合类型python基础语法03——语句构成文章目录python基础语法目录一、初识函数1.定义2.调用二、函数的传参1.位置传参2.关键词传参3.参数默认值4.可变位置参数5.可变关键词参数6.参数解包7.值传递与引用传递总结一、初识函数函数是Python中可重复使用的代码块,用于执行特定任务。通过将代码封装
- ubuntu18.04安装geemap
阿西是有梦想的咸鱼
python编程之路遥感影像处理可视化可视化pythonubuntu
文章目录安装测试GEE提供了JavaScript和PythonAPI,可以向EarthEngine服务器发出计算请求。与GEEJavaScriptAPI相比,PythonAPI缺乏易于理解的操作文档和交互式可视化结果的功能。由此,geemap诞生并填补了这一空白[1]。这里给大家介绍下我折腾了一晚上才搞定的geemap的安装及测试过程。这里是geemap的GitHub参考链接。安装如Github中
- python进行geeMap环境安装
箭梭_
python
近期需要利用geemap搭建一个界面,试了一下相应环境的配置,踏了挺多坑,下面我给大家具体介绍一下geemap的环境搭建:(1)geemap是基于googleearthengine的接口进行开发的,在安装geemap之前,需要先进行earthengie包的安装,参考链接如下:https://zhuanlan.zhihu.com/p/29186942#comment-549701602?notifi
- API开发全攻略:从入门到精通的企业级API架构与实战
Android洋芋
架构API设计RESTfulAPI微服务架构实战案例
简介API开发已成为现代软件架构的核心能力,掌握API设计与实现技术能显著提升开发效率和系统可扩展性。本文将从零开始,全面解析API的基础概念、架构设计、安全认证、性能优化等关键技术点,并提供完整的Python和Go语言代码实战示例,帮助开发者构建高性能、可扩展的企业级API系统。本文旨在为初学者和进阶开发者提供一份全面的API开发指南。内容涵盖API的基础概念、类型分类、架构设计、安全认证、性能
- 2023年NOC大赛创客智慧编程赛项Python 复赛模拟题(二)
青少儿编程课堂
少儿编程资料大全付费专栏pythonnumpy开发语言noc大赛真题noc试题
题目来自:NOC大赛创客智慧编程赛项Python复赛模拟题(二)NOC大赛创客智慧编程赛项Python复赛模拟题(二)第一题:编写一个成绩评价系统,当输入语文、数学和英语三门课程成绩时,输出三门课程总成绩及其等级。(1)程序提示用户输入三个数字,数字分别表示语文、数学、英语分数,对应的变量名称是Chinese、Math、English,并计算三个分数的和(score)进行输出。注:input()函
- 【RS】GEE(Python):大规模分析与导出数据
在前面的章节中,我们探讨了如何在GoogleEarthEngine(GEE)上进行数据加载、处理、分析和可视化。现在,我们将进一步扩展,探索如何处理大规模的数据集和执行复杂的分析任务。通过GEE的云计算能力,用户可以在全球范围内执行大规模的时空分析,并高效地将处理结果导出为所需的格式。大规模分析的基本原则在GEE中,大规模分析是通过ImageCollection和FeatureCollection
- 【Python篇】Python基础——08day.面向对象编程中类和对象的基本概念及属性和方法的常见分类和使用场景
WXX_s
python基础篇python分类开发语言学习
目录前言一、类和对象1.类→Class1.1概念1.2创建2.对象→Object2.1概念2.2创建二、属性和方法1.实例属性2.实例方法3.类属性4.类方法5.静态方法5.1综合应用6.构造方法7.初始化方法8.魔术方法8.1常用方法8.2案例参考总结前言这章讲的面向对象编程(Object-OrientedProgramming,简称OOP)是一种通过组织对象来设计程序的编程方法。为什么需要类和
- 【Python篇】Python基础——04day.Python中运算(简单部分,如果会的可以直接跳过)
文章目录前言一.运算符1.1算术运算符1.2比较运算符1.3逻辑运算符1.4赋值运算符1.5位运算符1.6身份运算符1.7成员运算符1.8三目运算符1.9优先级二.表达式2.1算术表达式2.2比较表达式2.3逻辑表达式2.4赋值表达式2.5成员表达式2.6身份表达式2.7三元表达式2.8函数调用表达式三.推导式3.1列表推导式3.2字典推导式3.3集合推导式总结前言这一章写的是在python中会用
- Python 现代时间序列预测第二版(五)
绝不原创的飞龙
默认分类默认分类
原文:annas-archive.org/md5/22eab741fce9c15dfad894ecf37bdd51译者:飞龙协议:CCBY-NC-SA4.0第十七章:概率预测及更多在整本书中,我们学习了生成预测的不同技术,包括一些经典方法,使用机器学习以及一些深度学习架构。但我们一直在关注一种典型的预测问题——为连续时间序列生成点预测,并且没有层级关系且历史数据足够丰富。我们之所以这样做,是因为这
- java 结合 FreeMarker 和 Docx4j 来生成包含图片的 docx 文件
liangblog
Java生产环境全栈开发Java进阶javapython开发语言
使用FreeMarker生成HTML,然后通过Docx4j将HTML转换为.docx文件;步骤1.添加依赖确保你的项目中包含了FreeMarker和Docx4j的依赖。以下是Maven的pom.xml示例:
- 自动化测试中,测试数据如何管理?
鱼鱼说测试
javalinux服务器
今晚在某个测试群,看到有人问了一个问题:把测试数据放配置文件读取和放文件通过函数调用读取有什么区别?Python接口自动化测试零基础入门到精通(2025最新版)当时我下意识的这么回答:数据量越大,配置文件越臃肿,放在专门的数据文件(比如excel,csv),方便针对性的维护。乍看没毛病,但回头和人讨论这个问题的时候,就认真思考了一下这个问题,下面是我的一些思考和讨论的一些结果,仅供参考。。。自动化
- 基于selenium的pyse自动化测试框架
鱼鱼说测试
selenium测试工具
Python接口自动化测试零基础入门到精通(2025最新版)介绍:pyse基于selenium(webdriver)进行了简单的二次封装,比selenium所提供的方法操作更简洁。特点:默认使用CSS定位,同时支持多种定位方法(id\name\class\link_text\xpath\css)。本框架只是对selenium(webdriver)原生方法进行了简单的封装,精简为大约30个方法,这些
- 自动化测试准备
鱼鱼说测试
自动化测试
什么是自动化测?Python接口自动化测试零基础入门到精通(2025最新版)首先理清自动化测试的概念,广义上来讲,自动化包括一切通过工具(程序)的方式来代替或辅助手工测试的行为都可以看做自动化,包括性能测试工具(loadrunner、jmeter),或自己所写的一段程序,用于生成1到100个测试数据。狭义上来讲,通工具记录或编写脚本的方式模拟手工测试的过程,通过回放或运行脚本来执行测试用例,从而代
- 2019-07-21
yao枫叶_acf3
急性缺血性脑卒中,发作3小时之内,使用阿替普酶,一般推荐剂量为0.6mg/kg体重,总量的10%静脉推入,剩下的60分钟之内持续静脉滴注桥接不用肝素化,无桥接可半量约2000u1小时后1000iv锁骨下:5ml/s7ml200pa颈总A:5ml/s7ml300pa椎动脉4ml/s6ml200pa动脉溶栓25万u+50mlNS微泵1万u/min每10万U造影一次通则停,未通则追加至40万u,无rtP
- 重塑未来:AI如何重新定义全栈开发
熊猫钓鱼>_>
人工智能
在传统认知中,全栈开发者被誉为技术界的“全能选手”。——他们需要精通前端界面构建(HTML/CSS/JavaScript)、后端业务逻辑实现(Python/Java/Node.js)、数据库设计优化(MySQL/MongoDB)以及服务器部署运维(Linux/Docker)。这种“一人包打天下”的能力模型长期被视为高效开发的黄金标准,尤其受到创业公司和小型团队的青睐,因为它能大幅减少沟通成本,加速
- Vue3 业务落地全景:脚手架、权限、国际化、微前端、跨端与低代码 50 条实战心法
代码老y
前端低代码
写给架构师、TL、全栈工程师的“踩坑地图”(零)阅读指南•不贴源码,用伪代码+流程图+决策树。•50条心法分6大篇章,可跳跃阅读。(一)脚手架与工程化8条心法1:用create-vue而不是vue-cli开启新项目,Vite冷启动300msvsWebpack30s。心法2:eslint-config-prettier+@vue/eslint-config-typescript一键集成,团队争议减少
- os.path.join坑的记录
半步江南
importrequestsimportosfromos.pathimportjointar=r"\219\1.html"root=os.getcwd()print(root)file_path=join(str(root),str(tar))print(file_path)输出为D:\workdir\py-dir\crapt_web_siteD:\219\1.html与需要的D:\workdir
- OpenCV稠密光流法可直接运行的例程(python)
indrrra
opencvpython人工智能
#dense_optical_flow.pyimportcv2importnumpyasnpimportargparsedefdense_optical_flow(method,video_path,params=[],to_gray=False):#读取视频cap=cv2.VideoCapture(video_path)#读取第一帧ret,old_frame=cap.read()#创建HSV并使
- 分布式锁特点、以及用python3实现redis分布式锁
数据知道
python3案例和总结分布式redis数据库python
更多内容请见:python3案例和总结-专栏介绍和目录文章目录一、Redis分布式锁核心原理1.1Redis锁机制1.2锁释放二、基础实现代码2.1使用`redis-py`客户端2.2分布式锁类三、使用示例3.1基础锁操作3.2装饰器模式四、高级特性实现4.1Redlock算法(高可用方案)五、生产环境最佳实践5.1锁粒度控制5.2异常处理5.3监控与调试5.4重试机制六、测试代码6.1并发测试6
- 云服务器性能优化全攻略:CPU、内存、磁盘IO调优实战
Gloria歌洛莉亚
c语言数据库服务器python性能优化
在云计算时代,服务器性能直接影响应用响应速度、用户体验和运营成本。无论是高并发网站、实时数据分析还是机器学习训练,优化云服务器性能都是开发者必须掌握的核心技能。本攻略将从CPU调度、内存管理、磁盘IO三个维度,结合Linux系统特性和实际场景,提供可落地的优化方案。一、CPU性能调优:从调度策略到并行计算1.1CPU资源监控与瓶颈定位实时监控工具:top-c#动态查看进程CPU占用(按P键按CPU
- XSS Payload 学习浏览器解码
菜鸟一个昂
servlet
目录问题一:问题二:问题三:问题四:问题五:问题六:问题七:问题八:问题九:问题十:问题十一:问题十二:问题十三:问题十四:问题十五:问题一:无法弹窗原因:urlcode无法识别协议(javascript:)html解码顺序:1、html实体编码2、urlcode编码3,unicode编码问题二:可以弹窗首先先HTML实体编码解码,得到href中为URL,URL模块可识别为javascript协议
- php、go、python后端接口签名实现
奇华智能
后台开发linux签名接口安全
1.php实现/**生成签名,$args为请求参数,$key为私钥*/functionmakeSignature($args,$key){if(isset($args['sign'])){$oldSign=$args['sign'];unset($args['sign']);}else{$oldSign='';}ksort($args);$requestString='';foreach($arg
- 浏览器解码过程分析
浏览器解码过程分析前言在学习xss漏洞的过程中我发现一个问题,当我想绕过过滤机制时,可以采用编码的方式进行绕过这种方法,但是并不是每一种编码格式都能绕过,需要不停的尝试才行,这样过于浪费时间。后来我发现浏览器与服务器数据传输过程中有好几种编码格式,不同的编码格式有着不同的解析引擎,作为一个浏览器,在解析一篇HTML文档时主要有三个处理过程:HTML解析,URL解析和JavaScript解析。每个解
- 「Chrome 开发环境快速屏蔽 CORS 跨域限制详细教程」*
Chrome开发环境快速屏蔽CORS跨域限制【超详细教程】为什么需要临时屏蔽CORS?在日常前后端开发中,我们经常会遇到这样的报错:Accesstofetchat'https://api.example.com'fromorigin'http://localhost:3000'hasbeenblockedbyCORSpolicy.或者类似:AccesstoXMLHttpRequestat'http
- 从XSS Payload学习浏览器解码
caker丶
XSS-labsXSSxss学习javascript
从XSSPayload学习浏览器解码HTML解析URL解析JavaScript解析案例解析总结作为一个浏览器在解析一篇HTML文档时主要有三个处理过程,每个解析器负责解码和解析HTML文档中它所对应的部分,下面我将按照解码顺序依次讲解。HTMl解析URL解析JavaScript解析HTML解析一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时
- SAP Word 模板与 XML 数据流合并过程深度剖析——以表格结构为例
汪子熙
ABAP百科全书wordxmlCRMABAPNetWeaverSAP
在CRMWebClientUI的Office集成功能里,Word模板与XML数据流的动态合并,是合同、报价单等文档自动生成的技术核心。本文结合SAP官方示例代码与OpenXML规范,从模板绑定、数据预处理、运行时递归填充到实际排错技巧,全景展示表格结构合并的幕后细节,并给出一段源自真实项目的实战案例,帮助读者迅速掌握这一看似神秘的“魔术”。(document567.rssing.com,docum
- Java实现的基于模板的网页结构化信息精准抽取组件:HtmlExtractor
yangshangchuan
信息抽取HtmlExtractor精准抽取信息采集
HtmlExtractor是一个Java实现的基于模板的网页结构化信息精准抽取组件,本身并不包含爬虫功能,但可被爬虫或其他程序调用以便更精准地对网页结构化信息进行抽取。
HtmlExtractor是为大规模分布式环境设计的,采用主从架构,主节点负责维护抽取规则,从节点向主节点请求抽取规则,当抽取规则发生变化,主节点主动通知从节点,从而能实现抽取规则变化之后的实时动态生效。
如
- java编程思想 -- 多态
百合不是茶
java多态详解
一: 向上转型和向下转型
面向对象中的转型只会发生在有继承关系的子类和父类中(接口的实现也包括在这里)。父类:人 子类:男人向上转型: Person p = new Man() ; //向上转型不需要强制类型转化向下转型: Man man =
- [自动数据处理]稳扎稳打,逐步形成自有ADP系统体系
comsci
dp
对于国内的IT行业来讲,虽然我们已经有了"两弹一星",在局部领域形成了自己独有的技术特征,并初步摆脱了国外的控制...但是前面的路还很长....
首先是我们的自动数据处理系统还无法处理很多高级工程...中等规模的拓扑分析系统也没有完成,更加复杂的
- storm 自定义 日志文件
商人shang
stormclusterlogback
Storm中的日志级级别默认为INFO,并且,日志文件是根据worker号来进行区分的,这样,同一个log文件中的信息不一定是一个业务的,这样就会有以下两个需求出现:
1. 想要进行一些调试信息的输出
2. 调试信息或者业务日志信息想要输出到一些固定的文件中
不要怕,不要烦恼,其实Storm已经提供了这样的支持,可以通过自定义logback 下的 cluster.xml 来输
- Extjs3 SpringMVC使用 @RequestBody 标签问题记录
21jhf
springMVC使用 @RequestBody(required = false) UserVO userInfo
传递json对象数据,往往会出现http 415,400,500等错误,总结一下需要使用ajax提交json数据才行,ajax提交使用proxy,参数为jsonData,不能为params;另外,需要设置Content-type属性为json,代码如下:
(由于使用了父类aaa
- 一些排错方法
文强chu
方法
1、java.lang.IllegalStateException: Class invariant violation
at org.apache.log4j.LogManager.getLoggerRepository(LogManager.java:199)at org.apache.log4j.LogManager.getLogger(LogManager.java:228)
at o
- Swing中文件恢复我觉得很难
小桔子
swing
我那个草了!老大怎么回事,怎么做项目评估的?只会说相信你可以做的,试一下,有的是时间!
用java开发一个图文处理工具,类似word,任意位置插入、拖动、删除图片以及文本等。文本框、流程图等,数据保存数据库,其余可保存pdf格式。ok,姐姐千辛万苦,
- php 文件操作
aichenglong
PHP读取文件写入文件
1 写入文件
@$fp=fopen("$DOCUMENT_ROOT/order.txt", "ab");
if(!$fp){
echo "open file error" ;
exit;
}
$outputstring="date:"." \t tire:".$tire."
- MySQL的btree索引和hash索引的区别
AILIKES
数据结构mysql算法
Hash 索引结构的特殊性,其 检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
可能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢
- JAVA的抽象--- 接口 --实现
百合不是茶
抽象 接口 实现接口
//抽象 类 ,方法
//定义一个公共抽象的类 ,并在类中定义一个抽象的方法体
抽象的定义使用abstract
abstract class A 定义一个抽象类 例如:
//定义一个基类
public abstract class A{
//抽象类不能用来实例化,只能用来继承
//
- JS变量作用域实例
bijian1013
作用域
<script>
var scope='hello';
function a(){
console.log(scope); //undefined
var scope='world';
console.log(scope); //world
console.log(b);
- TDD实践(二)
bijian1013
javaTDD
实践题目:分解质因数
Step1:
单元测试:
package com.bijian.study.factor.test;
import java.util.Arrays;
import junit.framework.Assert;
import org.junit.Before;
import org.junit.Test;
import com.bijian.
- [MongoDB学习笔记一]MongoDB主从复制
bit1129
mongodb
MongoDB称为分布式数据库,主要原因是1.基于副本集的数据备份, 2.基于切片的数据扩容。副本集解决数据的读写性能问题,切片解决了MongoDB的数据扩容问题。
事实上,MongoDB提供了主从复制和副本复制两种备份方式,在MongoDB的主从复制和副本复制集群环境中,只有一台作为主服务器,另外一台或者多台服务器作为从服务器。 本文介绍MongoDB的主从复制模式,需要指明
- 【HBase五】Java API操作HBase
bit1129
hbase
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.ha
- python调用zabbix api接口实时展示数据
ronin47
zabbix api接口来进行展示。经过思考之后,计划获取如下内容: 1、 获得认证密钥 2、 获取zabbix所有的主机组 3、 获取单个组下的所有主机 4、 获取某个主机下的所有监控项
- jsp取得绝对路径
byalias
绝对路径
在JavaWeb开发中,常使用绝对路径的方式来引入JavaScript和CSS文件,这样可以避免因为目录变动导致引入文件找不到的情况,常用的做法如下:
一、使用${pageContext.request.contextPath}
代码” ${pageContext.request.contextPath}”的作用是取出部署的应用程序名,这样不管如何部署,所用路径都是正确的。
- Java定时任务调度:用ExecutorService取代Timer
bylijinnan
java
《Java并发编程实战》一书提到的用ExecutorService取代Java Timer有几个理由,我认为其中最重要的理由是:
如果TimerTask抛出未检查的异常,Timer将会产生无法预料的行为。Timer线程并不捕获异常,所以 TimerTask抛出的未检查的异常会终止timer线程。这种情况下,Timer也不会再重新恢复线程的执行了;它错误的认为整个Timer都被取消了。此时,已经被
- SQL 优化原则
chicony
sql
一、问题的提出
在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统的响应速度就成为目前系统需要解决的最主要的问题之一。系统优化中一个很重要的方面就是SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见对于一个系统
- java 线程弹球小游戏
CrazyMizzz
java游戏
最近java学到线程,于是做了一个线程弹球的小游戏,不过还没完善
这里是提纲
1.线程弹球游戏实现
1.实现界面需要使用哪些API类
JFrame
JPanel
JButton
FlowLayout
Graphics2D
Thread
Color
ActionListener
ActionEvent
MouseListener
Mouse
- hadoop jps出现process information unavailable提示解决办法
daizj
hadoopjps
hadoop jps出现process information unavailable提示解决办法
jps时出现如下信息:
3019 -- process information unavailable3053 -- process information unavailable2985 -- process information unavailable2917 --
- PHP图片水印缩放类实现
dcj3sjt126com
PHP
<?php
class Image{
private $path;
function __construct($path='./'){
$this->path=rtrim($path,'/').'/';
}
//水印函数,参数:背景图,水印图,位置,前缀,TMD透明度
public function water($b,$l,$pos
- IOS控件学习:UILabel常用属性与用法
dcj3sjt126com
iosUILabel
参考网站:
http://shijue.me/show_text/521c396a8ddf876566000007
http://www.tuicool.com/articles/zquENb
http://blog.csdn.net/a451493485/article/details/9454695
http://wiki.eoe.cn/page/iOS_pptl_artile_281
- 完全手动建立maven骨架
eksliang
javaeclipseWeb
建一个 JAVA 项目 :
mvn archetype:create
-DgroupId=com.demo
-DartifactId=App
[-Dversion=0.0.1-SNAPSHOT]
[-Dpackaging=jar]
建一个 web 项目 :
mvn archetype:create
-DgroupId=com.demo
-DartifactId=web-a
- 配置清单
gengzg
配置
1、修改grub启动的内核版本
vi /boot/grub/grub.conf
将default 0改为1
拷贝mt7601Usta.ko到/lib文件夹
拷贝RT2870STA.dat到 /etc/Wireless/RT2870STA/文件夹
拷贝wifiscan到bin文件夹,chmod 775 /bin/wifiscan
拷贝wifiget.sh到bin文件夹,chm
- Windows端口被占用处理方法
huqiji
windows
以下文章主要以80端口号为例,如果想知道其他的端口号也可以使用该方法..........................1、在windows下如何查看80端口占用情况?是被哪个进程占用?如何终止等. 这里主要是用到windows下的DOS工具,点击"开始"--"运行",输入&
- 开源ckplayer 网页播放器, 跨平台(html5, mobile),flv, f4v, mp4, rtmp协议. webm, ogg, m3u8 !
天梯梦
mobile
CKplayer,其全称为超酷flv播放器,它是一款用于网页上播放视频的软件,支持的格式有:http协议上的flv,f4v,mp4格式,同时支持rtmp视频流格 式播放,此播放器的特点在于用户可以自己定义播放器的风格,诸如播放/暂停按钮,静音按钮,全屏按钮都是以外部图片接口形式调用,用户根据自己的需要制作 出播放器风格所需要使用的各个按钮图片然后替换掉原始风格里相应的图片就可以制作出自己的风格了,
- 简单工厂设计模式
hm4123660
java工厂设计模式简单工厂模式
简单工厂模式(Simple Factory Pattern)属于类的创新型模式,又叫静态工厂方法模式。是通过专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的模式,可以理解为是不同工厂模式的一个特殊实现。
- maven笔记
zhb8015
maven
跳过测试阶段:
mvn package -DskipTests
临时性跳过测试代码的编译:
mvn package -Dmaven.test.skip=true
maven.test.skip同时控制maven-compiler-plugin和maven-surefire-plugin两个插件的行为,即跳过编译,又跳过测试。
指定测试类
mvn test
- 非mapreduce生成Hfile,然后导入hbase当中
Stark_Summer
maphbasereduceHfilepath实例
最近一个群友的boss让研究hbase,让hbase的入库速度达到5w+/s,这可愁死了,4台个人电脑组成的集群,多线程入库调了好久,速度也才1w左右,都没有达到理想的那种速度,然后就想到了这种方式,但是网上多是用mapreduce来实现入库,而现在的需求是实时入库,不生成文件了,所以就只能自己用代码实现了,但是网上查了很多资料都没有查到,最后在一个网友的指引下,看了源码,最后找到了生成Hfile
- jsp web tomcat 编码问题
王新春
tomcatjsppageEncode
今天配置jsp项目在tomcat上,windows上正常,而linux上显示乱码,最后定位原因为tomcat 的server.xml 文件的配置,添加 URIEncoding 属性:
<Connector port="8080" protocol="HTTP/1.1"
connectionTi