缺失值处理方法和思路的总结
目录
- 一、缺失值的处理方法和思路
-
- 缺失值的处理方法
- 缺失值处理的思路
- 缺失值填充的方法有哪些?我们可以向缺失值填充一些什么样的数值?
- 二、查看是否有缺失值
- 三、缺失值删除
-
- 方法1:dropna()
- 方法2:del
- 四、填充缺失值
-
- 方法1:SimpleImputer方法
- 方法2:fillna方法
一、缺失值的处理方法和思路
缺失值的处理方法
-
1.直接删除:若数据集中某行出现缺失值,最简单的方法就是将存在缺失值的行或列直接从数据集中删除;
-
方法可行性:不好,如果你删除的某特征或某行数据是非常重要的一组数据呢?怎么判断某特征是对于模型以及数据集来说是一个非常重要的特征呢?
-
研究特征与标签的相关系数,相关系数的值越高,就说明当前特征对模型建模预测标签值的准确率的影响就越大
-
是否采用直接删除来处理缺失值,需要视情况来定;一般情况下,当某特征出现缺失值的比例占据总样本数超过50%及其以上,则认定当前特征对模型建立没有较大意义,则直接删除;
-
-
2.缺失值的填充:当某特征出现了缺失值,且缺失值占比没有达到50%以上,则当前特征不能直接删除,应该想办法将缺失值填补上;
缺失值处理的思路
- 1.先检索每个特征,确定该特征下缺失值占比的比例;
- 2.缺失值占比若超过50%,则判定为无效特征,直接删除即可;
- 3.缺失值占比未超过50%,则需完成缺失值填补;
缺失值填充的方法有哪些?我们可以向缺失值填充一些什么样的数值?
- 1.填充什么样的值,首先不会影响数据集输入到模型后对模型的拟合能力
- 2.在保证上述需求之上,继续寻找一个更好的方法,能够保证正确填充缺失值基础之上,尽可能的因为填充了缺失值,提升数据集对模型的拟合能力
- 3.常见的缺失值填充方法:
- 1.可以直接使用0填充;
- 2.可以使用均值填充;
- 3.可以使用众数填充;
- 4.可以使用中位数填充;
- 5.可以使用适当的分类、回归模型预测出某特征的缺失值应该填充为什么值,并且完成该缺失值的填充;
# 导包
import numpy as np
import pandas as pd
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
jupyter notebook的每个cell只会显示最后一个输出结果,除非用print。例如:
x = [2, 3, 4, 5]
y = x * 2
z = x * 3
x+x
y
z
输出结果:

from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
x = [2, 3, 4, 5]
y = x * 2
z = x * 3
x+x
y
z
输出结果:

# 读取数据(文末会提供数据的下载链接)
data = pd.read_excel('testData.xlsx')
data
二、查看是否有缺失值
- isnull().any():返回ndarray数组,着重看第二列,该列取值为布尔类型值,False表示无缺失值,True表示有缺失值;
- isnull().sum():返回ndarray数组,着重看第二列,该列值为int类型,表示每个特征出现了多少缺失值;
data.isnull().any()
输出结果:

可以看出除了time这一列,其他都有缺失值
data.isnull().sum()
输出结果:

可以看出每一列缺失值的个数
查看缺失值分布:missingno第三方库
- 安装:
conda/pip install missingno - 使用:
import missingno as ms - API:ms.bar(dataframe);
- 功能:绘制缺失值分布直方图;
- 参数:dataframe二维数组,即数据集;
import missingno as ms
ms.bar(data)
输出结果:

可以看出除了time这一列,其他都有缺失值
三、缺失值删除
方法1:dropna()
data.dropna(
axis:‘Axis’ = 0,
how:‘str’ =‘any’,
thresh = None,
subset = None,
inplace = ‘bool’ = False
)
- 参数axis:取值0或1,表示行方向或列方向;
- 参数how:取值{‘any’,‘all’}
- any:删除存在缺失值的行或列
- all:删除全为缺失值的行或列
- 参数thresh:取值int类型,表示阙值,即某行或列中非缺失值数量小于该阙值的行或列会被删除;一般的,该参数直接根据dataframe的行列值进行设定,例如:
dataframe.dropna(thresh = data.shape[0]*0.2) # 假设此时有1000行数据,表示删除非空值少于200个的特征列 - 参数subset:允许设置子集,取值list类型,表示一个花式索引,list中每一个元素为列索引值,表示在给定的这些特征列中进行缺失值删除
- 返回值,返回删除后的新的dataframe;
#拷贝副本方便多次测试
data1 = data.copy()
# 按列方向进行删除,删除全为缺失值的列
data1 = data1.dropna(axis=1,how='all')
data1
输出结果:

方法2:del
del(data[i]):删除data中索引为i个数据
data = pd.read_excel('testData.xlsx')
data
del data['none']
del data['none1']
data
删除前的数据:

删除后的数据:

四、填充缺失值
方法1:SimpleImputer方法
使用:from sklearn.impute import SimpleImputer
API:SimpleImputer()
SimpleImputer(*,missing_values=nan,strategy=‘mean’,fill_value=None,verbose=0,copy=True,add_indication=False)
参数missing_values:规定缺失值类型,一般为NaN,使用np.nan属性表示;
参数strategy:规定缺失值为数据类型,可选平均值、0值、众数填充;
返回值:缺失值填充对象;

方法2:fillna方法
-
API:fillna();
-
函数形式:fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
-
参数value:用于填充的空值的值。
-
参数method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
-
参数axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
-
参数inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
-
参数limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
-
参数downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
import numpy as np
import pandas as pd
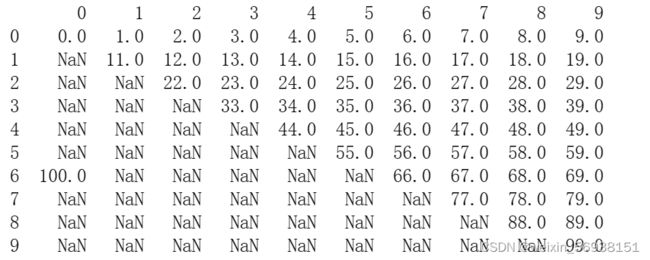
a = np.arange(100,dtype=float).reshape((10,10))
for i in range(len(a)):
a[i,:i] = np.nan
a[6,0] = 100.0
d = pd.DataFrame(data=a)
print(d)
输出结果:
# 用0填补空值
print(d.fillna(value=0))
输出结果:

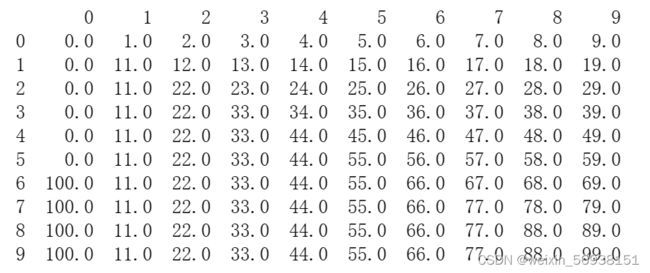
# 用前一行的值填补空值
print(d.fillna(method='pad',axis=0))
输出结果:
# 用后一列的值填补空值
print(d.fillna(method='backfill', axis=1))
输出结果:

# 连续空值,最多填补3个
print(d.fillna(method='ffill',axis=0, limit=3))

# 每条轴上,最多填补3个
print(d.fillna(value=-1,axis=0, limit=3))

本文数据:
链接:https://pan.baidu.com/s/1Q3jtATp87H7rRpz53xiqYA
提取码:7ue4