JVM篇:《深入理解Java虚拟机第二版.SUN技术》——笔记
深入理解Java虚拟机第二版.SUN技术
- 第1章 Java体系结构介绍
-
- 1.1 Java体系结构包括四个独立但相关的技术
- 1.2 虚拟机
- 第2章 平台无关
-
- 2.1为什么要平台无关
- 2.2Java体系结构对平台无关性的支持
-
- 2.2.1 Java平台
- 2.2.2 Java语言
- 2.2.3 class文件
- 2.2.4 可伸缩性
- 第3章 安全
- 第4章 网络移动性
- 第5章 Java虚拟机
-
- 5.1 Java虚拟机是什么
- 5.2 Java虚拟机的生命周期
- 5.3 Java虚拟机的体系结构
-
- 5.3.1 数据类型
-
- 5.3.2 字长的考量
- 5.3.3 类装载器子系统
- 5.3.4 方法区
- 5.3.5 堆
- 5.3.6 程序计数器
- 5.3.7 Java栈
- 5.3.8 栈帧
-
- 5.3.8.1栈帧的演示实例
- 5.3.9 本地方法栈
- 5.3.10执行引擎
- 5.3.11 本地方法
- 5.4 真实机器
- 第6章 Java class文件
-
- 6.1 Java class文件是什么
- 6.2 class文件的内容
- 6.3 特殊字符串
-
- 6.3.1全限定名
- 6.3.2简单名称
- 6.3.3 描述符
- 6.4 常量池
-
- 6.4.1 CONSTANT_Utf8_info表
- 6.4.2 CONSTANT_lnteger_info表
- 6.4.3 CONSTANT_Float_info表
- 6.4.4 CONSTANT_Long_info表
- 6.4.5 CONSTANT_Double_info表
- 6.4.6 CONSTANT_Class_info表
- 6.4.7 CONSTANT_String_info表
- 6.4.8 CONSTANT_Fieldref_info表
- 6.4.9 CONSTANT_Methodref_info表
- 6.4.10 CONSTANT_lnterfaceMethodref_info表
- 6.4.11 CONSTANT_NameAndType_info表
- 6.5 字段
- 6.6方法
- 6.7属性
-
- 6.7.1 属性格式
- 第7章 类型的生命周期
-
- 7.1类型装载、连接、初始化
-
- 7.1.1 装载
- 7.1.2 验证
- 7.1.3 准备
- 7.1.4 解析
- 7.1.5初始化
- 7.2 对象的生命周期
-
- 7.2.1 类的实例化
- 7.2.1 垃圾手机和对象的终结
- 7.3 卸载类型
- 第8章 链接模式
- 第9章 垃圾收集
- 第10章
- 第11章
- 第12章
- 第13章
- 第14章
- 第15章
- 第16章
- 第17章
- 第18章
- 第19章
- 第20章
- 补充
== 这篇博客是在阅读本书过程中做的笔记,以后遇到相关知识点或问题会加以补充完善==
第1章 Java体系结构介绍
1.1 Java体系结构包括四个独立但相关的技术
- Java程序设计语言
- Java class文件格式
- Java应用编程接口(API)
- Java虚拟机

1.2 虚拟机

Java面向网路的核心就是Java虚拟机,它支持Java面向网络体系结构三大支柱的所有方面,平台无关性、安全性和网络移动性。
一个Java程序可以使用两种类装载器:’启动‘类装载器和用户自定义的类装载器。启动类装载器也叫做系统类装载器,原始类装载器或者默认类装载器,启动类装载器通常使用默认的方式从本地磁盘中装载类,包括JavaAPI类。启动类装载器是Java虚拟机实现的本值部分,但是用户自定义的类装载器也能够Java编写,编译被虚拟机加载,这里不做太多记录,后边遇到了再加以理解和补充。
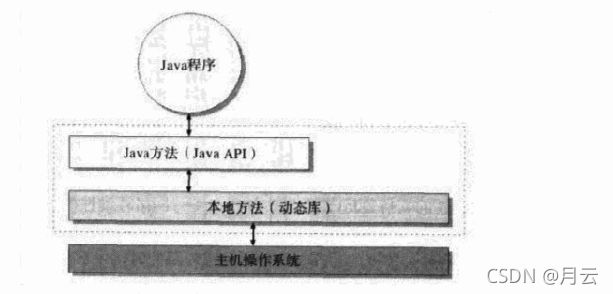
从上边的虚拟机结构图可以看出,Java虚拟机的主要任务是装载class文件并且执行其中的字节码。图中可以看到,Java虚拟机包含一个类装载器( class loader ),它可以从程序和API中装载class文件。Java API中只有程序执行时需要的那些类才会被装载。字节码由执行引擎来执行。
不同的Java虚拟中,执行引擎的实现方式可能不同,目前来说由软件实现的虚拟机中,执行引擎的实现方式有三种:
- 一次性解释字节码,将所有字节码解释为本地机器码。
- 即时编译,第一次执行的字节码编译成本地机器码,缓存到本地复用。
- 自适应优化器(重要),虚拟机开始的时候解释字节码为本地机器码,在程序运行中监视程序的活动,记录使用最频繁的代码段。程序运行的时候只把最频繁的代码解释为本地机器吗缓存本地复用,其他不频繁使用的代码由虚拟机继续解释它们。
- 将执行引擎内嵌在芯片中,用本地方法执行Java字节码,这种的虚拟机是由芯片构成的,实际上执行引擎内嵌在芯片中。
Java虚拟机操作本机资源,是通过本地方法来完成的,本地方法就是链接Java虚拟机和本机操作系统的桥梁。当然这种桥梁也是需要通行证的,Java有完备的本地方法库的api,调用前都会有权限的监控,这种权限控制当然是为了让安全性更高,其实就是一个封闭的沙箱环境。
第2章 平台无关
2.1为什么要平台无关
- Java创建的可执行二进制程序能够不加改变的运行于多个平台。
- 新兴的网络化嵌入式设备。
- Java能够减少开发和在多个平台上部署应用程序的成本和时间。
- 有助于商家拥有更多的潜在客户。
- class文件在网络传输上更有优势,可以很好的支持分布式环境,使得分布式系统可以很好的围绕‘网络移动’对象来构建。
2.2Java体系结构对平台无关性的支持
对平台无关性的支持就像安全性和网络移动性的支持一样,是分布在整个Java体系结构中的,所有的组成部分,语言、class文件、api以及虚拟机,都在对平台无关性的支持扮演者重要的角色。
2.2.1 Java平台
Java平台由Java API和Java虚拟机组成,Java平台扮演者一个运行时Java程序于其下硬件和操作系统之间的缓冲角色。Java程序被编译成 可运行在Java虚拟机中的二进制程序,API则给予Java程序访问底层计算机资源的能力。所以说,无论Java程序被部署在何处,他只需要更Java平台交互。
2.2.2 Java语言
Java语言的基本类型和行为都是Java语言自己定义的,所以不管在什么系统上运行,这一点在Java虚拟机和class文件中都是一致的,。通过确保基本类型在所在平台上的以执行来支持平台无关性。
2.2.3 class文件
class文件定义了一个的定义Java虚拟机的二进制格式,这种二进制文件就是编译原理中的中间码,因为它的格式有严格的约定,同一calss文件在不同的Java平台上运行时会被翻译成适用于当前系统可执行的机器码。从而很好的支持平台无关。
2.2.4 可伸缩性
可伸缩性是指,Java平台可以在不同的计算机上实现。
第3章 安全
做了解不做笔记,以后遇到了再做研究记录。
组成Java沙箱的基本组件
- 类装载器结构
- class文件检验器
- 内置Java虚拟机的安全特性
- 安全管理器及javaAPI
类装载器在Java安全特性中的作用
- 防止恶意代码干涉善意代码(命名空间)
- 守护被行人的类库边界
- 将代码归入某类,该类确定了代码可以进行那些操作
Class文件校验器对代码的四次检查
- 第一次检查:检查是否符合Java文件的基本结构;检查文件的完整性,是否又被删节,尾部是否有带其他的字节;检查版本号;
- 第二次检查:数据类型的语义检查,不需要查看字节码,也不需要装在和查看其他类型,查看每个组成部分,确认他们是否是其所属类型的实例,结构是否正确。
- 第三次检查:字节码验证
- 第四次检查:符号引用的验证
第4章 网络移动性
第5章 Java虚拟机
5.1 Java虚拟机是什么
要理解Java虚拟机,你首先必须意识到,当你说“Java虚拟机”时,可能指的是如下三种不同的东西:
- 抽象规范
- 一个具体的实现
- 一个运行种的虚拟实例
每个Java程序都运行于某个具体的Java虚拟机实现的实例上。在本书中,术语“Java虚拟机”可能表示上述三种情形之一,当无法联系上下文来确定其准确意思的时候,我们会在文中指明究竟是“抽象规范”,“一个具体的实现”,还是“一个运行中的虚拟机实例”。
5.2 Java虚拟机的生命周期
- 一个运行时的Java虚拟机实例的天职就是:负责运行一个Java程序。当启动一个Java程序时,一个虚拟机实例也就诞生了。当该程序关闭退出,这个虚拟机实例也就随之消亡。如果在同—台计算机上同时运行三个Java程序,将得到三个Java虚拟机实例。每个Java程序都运行于它自己的Java虚拟机实例中。
- jvm内部有两种线程,守护线程和非守护线程。守护线程通常是Java虚拟机内部自己使用,如垃圾回收任务的线程。(Java也可以将自己创建的某个线程标记为守护线程)非守护线程就是开始于main()的线程。只要还有任何非守护线程正常运行,那么这个Java程序继续运行(虚拟机任然存活),当该程序中所有的非守护线程都终止时,虚拟机将自动退出。
5.3 Java虚拟机的体系结构
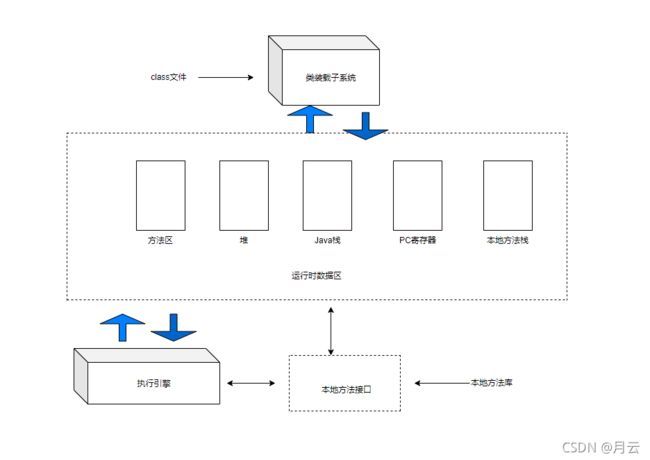
- 某些运行时数据区是由程序中所有线程共享的,还有一些则只能由一个线程拥有。每个Java虚拟机实例都有一个方法区以及一个堆,它们是由该虚拟机实例中所有线程共享的。
- 当虚拟机装载一个class文件时,它会从这个class文件包含的二进制数据中解析类型信息。然后,它把这些类型信息放到方法区中。当程序运行时,虚拟机会把所有该程序在运行时创建的对象都放到堆中。
- 当每一个新线程被创建时、它都将得到它自己的PC寄存器(程序计数器)以及一个lava栈。如果线程正在执行的是一个Java方法(非本地方法),那么PC寄存器的值将总是指示下–条将被执行的指令,而它的Java栈则总是存储该线程中Java方法调用的状态—-包括它的局部变量,被调用时传进来的参数,它的返回值.以及运算的中间结果等等。而本地方法调用的状态,则是以某种依赖于具体实现的方式存储在本地方法栈中,也可能是在寄存器或者其他某些与特定实现相关的内存区中。

- 方法区和堆是由所有线程所共享的运行时数据区。
- Java栈是由许多栈帧( stack framc)或者说帧( frame )组成的,一个栈帧包含一个Java方法调用的状态。可以不是很形象的说,Java方法是一系列操作的指令集,一个方法就是一个栈帧,执行方法会有具体的栈帧,会将方法中的变量放到栈帧中的局部变量中,后边会详细讲到。
- 当线程调用一个Java方法时,虚拟机压入一个新的栈帧到该线程的Java栈中;当该方法返回时、这个栈帧被从Java栈中弹出并抛弃。
- Java虚拟机没有寄存器,其指令集使用Java栈来存储中间数据。

- 上图展示了一个虚拟机实例的快照,它有三个线程正在执行。线程1和线程2都正在执行Java方法、而线程3则正在执行一个本地方法。
- 上图可以看出,Java栈都是向下生长的(单出口,先进后出),而栈顶都显示在图的底部。当前正在执行的方法的栈帧则以浅色表示。
- 对于一个正在运行Java方法的线程而言,它的PC寄存器总是指向下一条将被执行的指令。
- 在图中,像这样的PC寄存器(比如线程1和线程2的)都是以浅色显示的﹒由于线程3当前正在执行一个本地方法,因此,它的PC寄存器–─以深色显示的那个、其值是不确定的。
5.3.1 数据类型


Java虚拟机中的基本类型:
- Java语言中的所有基本类型同样也是Java虚拟机中的基本类型。其中
boolean类型有点特别,虽然Java虚拟机也将boolean看作是基本类型,但是指令集(指令集:指挥机器工作的指令和命令)对boolean的支持是有限的。当编译器将Java源码编译成字节码时,他会用int或byte来表示boolea。 - 在Java虚拟机中,
false用零(0)来表示,所有的非零数都表示true,涉及boolea的操作会使用int。 boolean数组是当作byte数组来访问的,但是在“堆”区,他可以被表示为位域。returnAddress是一个旨在Java虚拟机内部使用的基本类型。
Java虚拟机中的以用类型:
- Java虚拟机的引用类型被统称为“引用”( reference ),有三种引用类型:类类型,接口类型,以及数组类型,它们的值都是对动态创建对象的引用。
- 类类型的值是对类实例的引用;
- 数组类型的值是对数组对象的引用,在Java虚拟机中,数组是个真正的对象;
- 接口类型的值,则是对实现了该接口的某个类实例的引用。
- 还有一种特殊的引用值是null,它表示该引用变量没有引用任何对象。
5.3.2 字长的考量
Java虚拟机中,最基本的数据单元就是字( word ),它的大小是由每个虚拟机实现的设计者来决定的。字长必须足够大,至少是一个字单元就足以持有byte、short、int、char、float、returnAddress或者reference类型的值,而两个字单元就足以持有long或者double类型的值。因此,虚拟机实现的设计者至少得选择32位作为字长,或者选择更为高效的字长大小。通常根据底层主机平台的指针长度来选择字长。
在Java虚拟机规范中,关于运行时数据区的大部分内容,都是基于“字”这个抽象概念的。比如,关于栈帧的两个部分―局部变量和操作数栈-—都是按照“字”来定义的。这些内存区域能够容纳任何虚拟机数据类型的值,当把这些值放到局部变量或者操作数栈中时,它将占用一个或两个字单元。
在运行时,Java程序无法侦测到底层虚拟机的字长大小;同样,虚拟机的字长大小也不会影响程序的行为——它仅仅是虚拟机实现的内部属性。
5.3.3 类装载器子系统
- 在Java虚拟机中,负责查找并装载类型的那部分被称为类装载器子系统。
- 装载、连接以及初始化类装载器子系统除了要定位和导人二进制class文件外,还必须负责验证被导人类的正确性,为类变量分配并初始化内存,以及帮助解析符号引用。这些动作必须严格按以下顺序进行:
1)装载——查找并装载类型的二进制数据。
2)连接-—执行验证,准备,以及解析(可选)。验证确保被导入类型的正确性。准备为类变量分配内存,并将其初始化为默认值。解析把类型中的符号引用转换为直接引用。
3)初始化—一把类变量初始化为正确切始值。
5.3.4 方法区
-
在Java虚拟机中,关于被装载类型的信息存储在一个逻辑上被称为方法区的内存中。当虚拟机装载某个类型时,它使用类装载器定位相应的class文件,然后读入这个class文件——一个线性二进制数据流,然后将它传输到虚拟机中。紧接着虚拟机提取其中的类型信息,并将这些信息存储到方法区。该类型中的类(静态)变量同样也是存储在方法区中。
-
由于所有线程都共享方法区,因此它们对方法区数据的访问必须被设计为是线程安全的。比如,假设同时有两个线程都企图访问一个名为Lava的类,而这个类还没有被装入虚拟机,那么,这时只应该有一个线程去装载它,而另一个线程则只能等待。
-
方法区的大小不必是固定的,虚拟机可以根据应用的需要动态调整。同样,方法区也不必是连续的,方法区可以在一个堆(甚至是虚拟机自己的堆)中自由分配。另外,虚拟机也可以允许用户或者程序员指定方法区的初始大小以及最小和最大尺寸等。
-
方法区也可以被垃圾收集,当某个类不在被引用时,Java虚拟机就可以写在这个类(垃圾收集),从而使方法区占用的内存达到最小。
-
方法区中存储的类信息:
1、这个类型的全限定名。
2、这个类型的直接超类的全限定名(除非这个类型是java.lang.Object,它没有超类)。·
3、这个类型是类类型还是接口类型。
4、这个类型的访问修饰符(( public、abstract或final的某个子集)。·
5、任何直接超接口的全限定名的有序列表。
6、该类型的常量池。详细内容第6章讲常量池主要用于存放两大类常量:
- 字面量(Literal),字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等。
- 符号引用量(Symbolic References),符号引用则属于编译原理方面的概念,包括了如下三种类型的 >常量:类和接口的全限定名、字段名称和描述符、方法名称和描述符
7、字段信息。
- 字段名
- 字段类型
- 字段的修饰符( public、private、protected、static、final、volatile、transient的某个子集))
8、方法信息。
- 方法名
- 方法的返回类型(或void)
- 方法参数的数量和类型(按声明顺序)
- 字段的修饰符( public、private、protected、static、final、volatile、transient的某个子集))
- 如果某个方法不是抽象方法和本地方法它还需要保存方法的字节码bytecodes
- 操作数栈和该方法的栈帧中的局部变量区的大小(这些在本章的后面会详细描述)。
- 异常表 (参见17章)
9、除了常量以外的所有类(静态)变量。
类(静态)变量是由所有类实例共享的,但是即使没有任何类实例,它也可以被访问。这些变量只与类有关—―而非类的实例,因此它们总是作为类型信息的一部分而存储在方法区*。除了在类中声明的编译时常量外,虚拟机在使用某个类之前,必须在方法区中为这些类(静态)变量分配空间。
10、一个到类ClassLoader的引用。
- 指向ClassLoader类的引用﹐每个类型被装载的时候,虚拟机必须跟踪它是由启动类装载器还是由用户自定义类装载器装载的。如果是用户自定义类装载器装载的,那么虚拟机必须在类型信息中存储对该装载器的引用。这是作为方法表中的类型数据的一部分保存的。
- 虚拟机会在动态连接期间使用这个信息。当某个类型引用另一个类型的时候,虚拟机会请求装载发起引用类型的类装载器来装载被引用的类型。这个动态连接的过程,对于虚拟机分离命名空间的方式也是至关重要的。为了能够正确地执行动态连接以及维护多个命名空间,虚拟机需要在方法表中得知每个类都是由哪个类装载器装载的。关于动态连接和命名空间的细节请参见第8章。
11、一个到类Class的引用。
指向Class类的引用﹐对于每一个被装载的类型(不管是类还是接口),虚拟机都会相应地为它创建一个java.lang.Class类的实例,而且虚拟机还必须以某种方式把这个实例和存储在方法区中的类型数据关联起来。
// on CD-ROM in file jvm/ex2/Lava. java
class Lava {
private int speed = 5; // 5 kilometers per hour
voia flow() {
}
}
// on CD-ROM in file jvn/ex2 /volcano.java
class volcano {
public static void main (string []args) {
Lava Lava = new Lava( );
1ava.f1ow();
}
}
- 要运行Volcano程序,首先得以某种“依赖于实现的”方式告诉虚拟机“Volcano”这个名字。之后,虚拟机将找到并读入相应的class文件“Volcano.class”。
- 然后它会从导入的class文件里的二进制数据中提取类型信息并放到方法区中。
- 通过执行保存在方法区中的字节码,虚拟机开始执行main( )方法,在执行时,它会一直持有指向当前类( Volcano类)的常量池(方法区中的一个数据结构)的指针。
- main ( )的第一条指令告知虚拟机为列在常量池第一项的类分配足够的内存。所以虚拟机使用指向Volcano常量池的指针找到第一项(引用变量Lavan),发现它是一个对Lava类的符号引用,然后它就检致方法区,看Lava类是否已经被装载了。
- 当虚拟机发现还没有装载过名为“Lava”的类时,它就开始查找并装载文件“Lava.class",并把从读人的二进制数据中提取的类型信息放在方法区中。
- 紧接着,虚拟机以一个直接指向方法区Lava类数据的指针来替换常量池第一项(就是那个字符串“Lava")—-以后就可以用这个指针来快速地访问Lava类了。这个替换过程称为常量池解析,即把常量池中的符号引用替换为直接引用。这是通过在方法区中搜索被引用的元素实现的,在这期间可能又需要装载其他类。在这里,我们替换掉符号引用的“直接引用”是一个本地指针。·
- Java虚拟机总能够通过存储于方法区的类型信息来确定个对象需要多少内存,当Java虚拟机确定了一个Lava对象的大小后,它就在堆上分配这么大的空间,并把这个对象实例的变量speed初始化为默认初始值0。假如Lava类的超类Object也有实例变量,则也会在此时被初始化为相应的默认值。
- 当把新生成的Lava对象的引用压到栈中,main( )方法的第一条指令也完成了。接下来的指令通过这个引用调用Java代码(该代码把speed变量初始化为正确初始值5 )。另外一条指令将用这个引用调用Lava对象引用的flow ()方法。
注意,虚拟机开始执行Volcano类中main ( )方法的字节码的时候,尽管Lava类还没被装载,但是和大多数(也许所有)虚拟机实现一样,它不会等到把程序中用到的所有类都装载后才开始运行程序。恰好相反,它只在需要时才装载相应的类。
5.3.5 堆
- 一个Java程序独占一个Java虚拟机实例,而一个Java虚拟机实例中只存在一个堆空间,所以每个Java程序都有它自己的堆空间一它们不会彼此干扰。
- Java程序在运行时创建的所有类实例或数组都放在同一个堆中,因此所有线程都将共享这个堆。
在这种情况下,就得考虑多线程访问对象(堆数据)的同步问题了。 - 虚拟机有一条在堆中给新对象分配内存的指令,没有释放内存的指令,堆内存的释放需要GC。
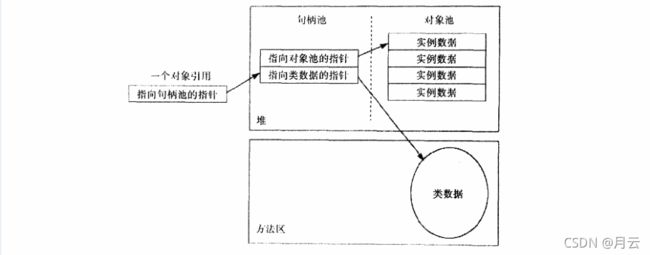
上图堆空间设计就是,把堆分为两部分:一个句柄池,一个对象池。而一个对象引用就是一个指向句柄池的本地指针。句柄池的每个条目有两部分:一个指向对象实例变量的指针,一个指向方法区类型数据的指针。
- 好处是有利于堆碎片的整理,当移动对象池中的对象时,句柄部分只需要更改一下指针指向对象的新地址就可以了一就是在句柄池中的那个指针。
- 缺点是每次访问对象的实例变量都要经过两次指针传递。
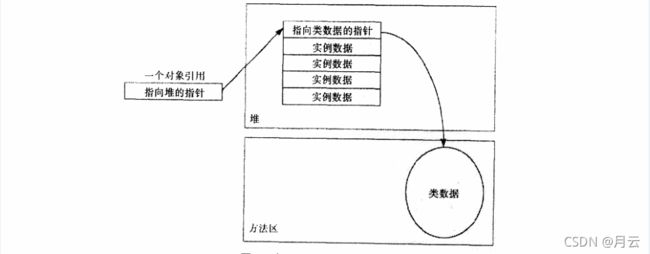
上图堆空间设计就是使对象指针直接指向一组数据,而该数据包括对象实例数据以及指向方法区中类数据的指针。这样设计的优缺点正好与前面的方法相反,它只需要一个指针就可以访问对象的实例数据,但是移动对象就变得更加复杂。当使用这种堆的虚拟机为了减少内存碎片而移动对象的时候,它必须在整个运行时数据区中更新指向被移动对象的引用。
方法表
不管虚拟机的实现使用什么样的对象表示法,很可能每个对象都有–个方法表,因为方法表加快了调用实例方法时的效率,从而对Java虚拟机实现的整体性能起着非常重要的正面作用。但是Java虚拟机规范并未要求必须使用方法表,所以并不是所有实现中都会使用它。比如那些具有严格内存资源限制的实现,或许它们根本不可能有足够的额外内存资源来存储方法表。如果一个实现使用方法表,那么仅仅使用一个指向对象的引用,就可以很快地访问到对象的方法表。
这个方法表结构可以包括两部分:
- 一个指向方法区对应数据的指针
- 对象的方法表
方法表指向的实例方法数据信息:
- 此方法的操作数栈和局部变量区的大小
- 此方法的字节码
- 异常表
对象方法表:
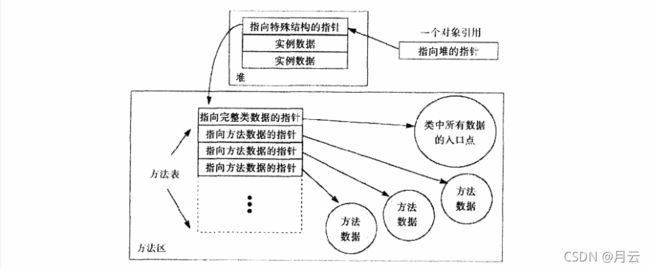
对象锁:
虚拟机中,堆中每个对象都有一个对象锁,用于协调多线程时对象访问的同步。除了实现锁所需要的数据外,每个Java对象逻辑上还与实现等待集合( wait set)的数据相关联。锁是用来实现多个线程对共享数据的互斥访问的,而等待集合是用来让多个线程为完成一个共同目标而协调工作的。
5.3.6 程序计数器
对于一个运行中的Java程序而言.其中的每一个线程都有它自己的PC(程序计数器)寄存器,它是在该线程启动时创建的。PC寄存器的大小是一个字长,因此它既能够持有一个本地指针,也能够持有一个returnAddress。当线程执行某个Java方法时,PC寄存器的内容总是下一条将被执行指令的“地址",这里的“地址”可以是一个本地指针,也可以是在方法字节码中相对于该方法起始指令的偏移量。如果该线程正在执行一个本地方法,那么此时PC寄存器的值是“undefined”。
5.3.7 Java栈
- 每当启动一个新线程时,Java虚拟机都会为它分配一个Java栈。前面我们曾经提到,Java栈以栈帧为单位保存线程的运行状态,虚拟机只会对Java栈执行两种操作,以帧为单位的压栈或出栈。
理解内容1:
在5.3.5中有说到,一个Java程序独占一个Java虚拟机实例,也就是一个Java虚拟机实例就是一个Java程序。那如果是程序他就可以产生多个线程。比如说你的Java程序在启动时需要初始化很多东西,就像大量的图片和图片的文字性说明,这是你就可以创建两个线程T1、T2,一个用于加载图片,一个用于加载图片说明。这时候Java虚拟机就会给这T1、T2两个线程分配Java栈。
是不是可以理解为Java栈就是线程的活动空间?
- 某个线程正在执行的方法被称为该线程的当前方法,当前方法使用的栈帧称为当前帧,当前方法所属的类称为当前类,当前类的常量池称为当前常量池。在线程执行一个方法时,它会跟踪当前类和当前常量池。此外,当虚拟机遇到栈内操作指令时,它对当前帧内数据执行操作。
- 每当线程调用一个Java方法时,虚拟机都会在该线程的Java栈中压入一个新帧。而这个新帧自然就成为了当前帧。在执行这个方法时,它使用这个帧来存储参数、局部变量、中间运算结果等等数据。方法执行结束,该栈帧弹出Java栈然后释放掉。
理解内容2:
在【理解内容1】中提到了两个线程T1、T2,这两个线程在加载图片或说明时肯定需要执行加载图片的方法methodT()1和加载说明的方法methodT2()。
以methodT1()为例,T1线程在调用methodT1()方法时,为T1线程创建的栈会先创建一个栈帧,在他执行的时候将方法的局部变量、参数等数据放入栈帧中,方法执行结束后再将这个栈帧释放掉。
这样的话又可以理解为:每一个方法都可以看做一个栈帧。每当有方法被调用执行,就把该方法的栈帧入栈,方法执行完毕时出栈。
方法的调用和执行:
方法总是先调用再执行,方法调用的过程分为解析和分派两个过程。在Java程序中我们通过方法名调用特定方法,为什么通过方法名就能找到具体方法呢?在class文件中每个方法名只是一个字面量而已,把这个字面量变成对具体方法的引用就是解析的过程。通过解析,我们可以通过方法名得到恰当的具体方法,具有了方法调用的前提。接下来要做的事就是选择要调用的方法,把不同的调用分派到不同的方法。分派又分为静态分派和动态分派两种。
-
动态分派:
动态分派强调的是从覆盖的方法中分派合适的方法,并且因为这个分配的结果是在实际运行时得出的,所以成为动态分派。(重载方法) -
静态分派:
静态分派强调的是从重载的方法中分派合适的方法。JVM根据方法调用时根据传入参数不同分派给类中的重载方法就是静态分配的过程。只是这个分派的过程在编译期根据源代码就能确定下来,所以称为静态分派。 -
单分派和多分派:
单分派和多分派,根据方法分派时依据的宗量不同,分派又分为单分派和多分派。
动态分派时只需根据实例类型这一因素选择分派即可,所以它只有一个宗量,是单分派。
静态分派时需要根据引用类型和参数表两个因素才能确定分派的方法,所有它有两个宗量,是多分派。
Java是一种静态多分派,动态单分派语言。
执行,通过调用获得了恰当方法,然后才是执行方法的过程。
5.3.8 栈帧
栈帧由三部分组成:局部变量区,操作数栈和帧数据区。局部变量区和操作数栈的大小要视对应的方法而定,它们是按字长计算的。编译器在编译时就确定了这些值并放在class文件中。而帧数据区的大小依赖于具体的实现。
当虚拟机调用一个Java方法时,它从对应类的类型信息中得到此方法的局部变量区和操作数栈的大小,并据此分配栈帧内存,然后压入Java栈中。
- 局部变量区包含对应方法的局部变量和方法参数。编译器会按声明的顺序吧这些变量放入局部变量数组。

局部变量:
- 局部变量区Java栈帧的局部变量区被组织为一个以字长为单位、从0开始计数的数组。字节码指令通过从0开始的索引来使用其中的数据。类型为int、float、reference和returnAddress的值在数组中只占据-项,而类型为byte、short和char的值在存人数组前都将被转换为int值,因而同样占据一项。但是类型为long和double的值在数组中却占据连续的两项。
—————— 所以可以看到上图数组中缺少下标2和3。 - byte 、short 、 char 、 boolean都被转为int处理。
操作数栈:
- 操作数栈和局部变量区一样,操作数栈也是被组织成-一个以字长为单位的数组。但是和前者不同的是,它不是通过索引来访问,而是通过标准的栈操作——压栈和出栈来访问的。比如,如果某个指令把一个值压入到操作数栈中,稍后另一个指令就可以弹出这个值来使用。
- 虚拟机在操作数栈中存储数据的方式和在局部变量区中是一样的,如int、long、float,double、reference和returnType的存储。对于byte、short以及char类型的值在压入到操作数栈之前,也会被转换为int。
- 虚拟机把操作数栈作为它的工作区–大多数指令都要从这里弹出数据,执行运算,然后把结果压回操作数栈。
帧数据区:
除了局部变量区和操作数栈外,Java栈帧还需要一些数据来支持常量池解析、正常方法返回以及异常派发机制。这些信息都保存在Java栈帧的帧数据区中。
- 常量池解析
Java虚拟机中大多数指令都涉及到常量池入口,如取数据压栈。
另外,每当虚拟机要执行某个需要用到常量池数据的指令时,它都会通过帧数据区中指向常量池的指针来访问它。以前讲过,常量池中对类型、字段和方法的引用在开始时都是符号。当虚拟机在常量池中搜索的时候,如果遇到指向类、接口、字段或者方法的入口,假若它们仍然是符号,虚拟机那时候才会(也必须)进行解析。 - 处理异常(异常表)
除了用于常量池的解析外,帧数据区还要帮助虚拟机处理Java方法的正常结束或异常中止。如果是通过return正常结束,虚拟机必须恢复发起调用的方法的栈帧,包括设置PC寄存器指向发起调用的方法中的指令-——-即紧跟着调用了完成方法的指令的下-·个指令。假如方法有返回值,虚拟机必须将它压入到发起调用的方法的操作数栈。
为了处理Java方法执行期间的异常退出情况,帧数据区还必须保存一个对此方法异常表的引用。异常表会在第17章深入描述,它定义了在这个方法的字节码中受catch子句保护的范围、异常表中的每一项都有一个被catch子句保护的代码的起始和结束位置(译者注:即try子句内部的代码)、可能被catch的异常类在常量池中的索引值,以及catch子句内的代码开始的位置。
当某个方法抛出异常时,虚拟机根据帧数据区对应的异常表来决定如何处理。如果在异常表中找到了匹配的catch子句,就会把控制权转交给catch子句内的代码。如果没有发现,方法会立即异常中止。然后虚拟机使用帧数据区的信息恢复发起调用的方法的帧,然后在发起调用的方法的上下文中重新抛出同样的异常。
5.3.8.1栈帧的演示实例
演示代码:
public class Add {
public static void main(String[] args) {
int a = 1;
int b = 2;
int c = a + b;
System.out.print(c);
}
}
编译后的字节码

CA FE BA BE :这四位表示这是一个class文件,虚拟机只识别这四位开头的文件。
00 00 00 34:这四位是版本号,后两位是主版本号,接着就是常量池的大小和常量池数据,这里不做说明。
常量池:

反汇编码:

执行过程分析:
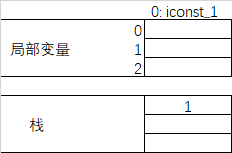
- 0: iconst_1
将int型1推送至栈顶
- 1: istore_1
将栈顶的int型1存放到本地局部变量索引为1的位置

- 2: iconst_2
将int型2推送至栈顶

- 3: istore_2
将栈顶的int型2存放到本地局部变量索引为2的位置

- 4: iload_1
将局部变量中索引为1的int型变量推送至栈顶

- 5: iload_2
将局部变量中索引为2的int型变量推送至栈顶

- 6: iadd
对操作数栈中的变量做加法运算并推送至栈顶
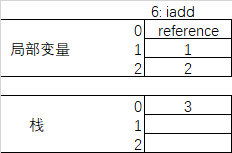
- 7: istore_3
将栈顶的int型3存放到本地局部变量索引为3的位置

- 8: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
将输出类的静态域压栈
- 11: iload_3
将局部变量中索引为3的int型变量推送至栈顶

- 12: invokevirtual #3 // Method java/io/PrintStream.print:(I)V
执行接口方法
- 15: return
结束出栈
5.3.9 本地方法栈
任何本地方法接口都会使用某种本地方法栈。当线程调用Java方法时,虚拟机会创建一个新的栈帧并压入Java栈。然而当它调用的是本地方法时,虚拟机会保持Java栈不变,不再在线程的Java栈中压入新的帧,虚拟机只是简单地动态连接并直接调用指定的本地方法。可以把这看做是虚拟机利用本地方法来动态扩展自己。就如同Java虚拟机的实现在按照其中运行的Java程序的吩咐,调用属于虚拟机内部的另-一个(动态连接的)方法。
5.3.10执行引擎
执行引擎:
这个术语也可以有三种理解:
- 抽象的规范(抽象规范使用指令集规定了执行引擎的行为)
- 具体的实现(具体实现可能使用多种不同的技术-——包括软件方面、硬件方面或数种技术的集合)
- 正在运行的实例(作为运行时实例的执行引擎就是一个线程)
运行中Java程序的每一个线程都是一个独立的虚拟机执行引擎的实例。
从线程生命周期的开始到结束,它要么在执行字节码,要么在执行本地方法。一个线程可能通过解释或者使用芯片级指令直接执行字节码,或者间接通过即时编译器执行编译过的本地代码。Java虚拟机的实现可能用一些对用户程序不可见的线程,比如垃圾收集器。这样的线程不需要是实现的执行引擎的实例。所有属于用户运行程序的线程,都是在实际工作的执行引擎。
指令集:
含操作数
- 方法的字节码流是由Java虚拟机的指令序列构成的,每一条指令包含一个单字节的操作码,后面跟随0个或多个操作数。操作码表明需要执行的操作;操作数向Java虚拟机提供执行操作码需要的额外信息。操作码本身就已经规定了它是否需要跟随操作数,以及如果有操作数的话,它是什么形式的。
指令0: iconst_1,iconst表示操作码,1表示操作数,这个指令的意思就是将int类型的1
压栈。
不含操作数
- 很多Java虚拟机的指令不包含操作数仅仅是由一个操作码字节构成的。根据操作码的需要,虚拟机可能除了跟随操作码的操作数之外,还需要从另外一些存储区域得到操作数。当虚拟机执行一条指令的时候,可能使用当前常量池中的项、当前帧的局部变量中的值,或者位于当前帧操作数栈顶端的值。
例如指令iadd,后边没有操作数,他表示将操作数栈种的值相加,将结果压栈。
代码示例
代码:
public class Add { public static void main(String[] args) { Add add = new Add(); add.addMethod(); } public void addMethod(){ int a = 1; int b = 2; int c = a + b; System.out.print(c); } }反汇编:
public class com.github.erbudu.prj.test.Add { public com.github.erbudu.prj.test.Add(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."":()V 4: return public static void main(java.lang.String[]); Code: 0: new #2 // class com/github/erbudu/prj/test/Add 3: dup 4: invokespecial #3 // Method " ":()V 7: astore_1 8: aload_1 9: invokevirtual #4 // Method addMethod:()V 12: return public void addMethod(); Code: 0: iconst_1 1: istore_1 2: iconst_2 3: istore_2 4: iload_1 5: iload_2 6: iadd 7: istore_3 8: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream; 11: iload_3 12: invokevirtual #6 // Method java/io/PrintStream.print:(I)V 15: return } 指令集序列(方法的字节码流):
public static void main(java.lang.String[]); Code: 0: new #2 // class com/github/erbudu/prj/test/Add 3: dup 4: invokespecial #3 // Method "":()V 7: astore_1 8: aload_1 9: invokevirtual #4 // Method addMethod:()V 12: return ——————————————————————————————————————————— public void addMethod(); Code: 0: iconst_1 1: istore_1 2: iconst_2 3: istore_2 4: iload_1 5: iload_2 6: iadd 7: istore_3 8: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream; 11: iload_3 12: invokevirtual #6 // Method java/io/PrintStream.print:(I)V 15: return 说明:
含操作数的指令
- 例如指令0: iconst_1,
iconst表示操作码,1表示操作数,这个指令的意思就是将int类型的1
压栈。不含操作数的指令
- 例如指令iadd,后边没有操作数,他表示将操作数栈种的值相加,将结果压栈。
执行引擎实例执行指令集:
- 抽象的执行引擎实例(线程)每次执行一条字节码指令
线程 ==》 执行引擎实例;
方法 ==》指令集序列
- 执行一条指令包含的任务之一就是决定下一条要执行的是什么指令。执行引擎决定下一个操作码时有三种方法。很多指令的下一个操作码就是在当前操作码和操作数之后紧跟的那个字节(如果字节码流里面还有的话)。另外一些指令,比如goto或者return,执行引擎决定下一个操作码时把它当做当前执行指令的一部分。假若一条指令抛出了—个异常,那么执行引擎将搜索合适的catch子句,以决定下一个将执行的操作码是什么。
- 每个方法都有一个局部变量集合,指令集实际的工作方式就是把栈帧中局部变量当作寄存器,用索引来访问。
- 执行技术瞭实现可以使用多种执行技术:解释、即时编译、自适应优化、芯片级直接执行,这些在第1章中介绍过。关于执行技术要记住的最主要的一点就是,实现可以自由选择任何技术来执行字节码,只要它遵守Java虚拟机指令集的定义。自适应优化技术是最有意义也是最迅速的执行技术之一,就是热缓存。
5.3.11 本地方法
5.4 真实机器
第6章 Java class文件
6.1 Java class文件是什么
Java class文件是Java程序二进制文件的精确定义。每一个class文件都对Java类或者Java接口做出了全面的描述。一个Java文件中只能包含一个类或接口。正是对Java文件的明确定义,使得所有Java虚拟机能够正确的读取和解释所有Java class文件。
以下观点为个人理解,慎重参考:
1.windows有windows的可执行文件,linux有linux的可执行文件,所以,Java虚拟机的可执行文件就是class文件。
2.class文件除了能被虚拟机识别外,在其他地方可能一无是处。虚拟机可以识别解析class文件的数据结构和指令集。
3.解释执行:Java方法就是一系列的指令集,当然这些指令集只有虚拟机可以识别。执行的时候将指令集解释为本地操作系统可执行的机器码再执行。
4.编译执行:也可直接将class文件翻译为计算机可执行文件直接执行,各有优缺。
class文件结构的数据类型:
-
无符号类型(基本类型)字节占位符,用来描述数字、索引引用、数量值或UTF-8编码构成的字符串值。
类型名称 字节数 u1 1 u2 2 u4 4 u8 8 -
表
表是由多个无符号数或其他表作为数据项构成的复合数据类型,一般以"_info"结尾; 表用来描述有层次关系的复合结构的数据; 表中的项长度不固定;
6.2 class文件的内容
class文件基本类型
| 占位符 | 字节长度 | 符号类型 |
|---|---|---|
| u1 | 1 | 无符号类型 |
| u2 | 2 | 无符号类型 |
| u4 | 3 | 无符号类型 |
| u8 | 8 | 无符号类型 |
ClassFile表的格式
| 类型 | 名称 | 数量 | 说明 |
|---|---|---|---|
| u4 | magic | 1 | 魔数,Java文件的前四位,固定的四位CA FE BA BE ,用于区分该文件是否是Java文件,虚拟机只识别以正确魔数开头的文件。 |
| u2 | minor_version | 1 | 次版本号,魔数后的两位。 |
| u2 | major_version | 1 | 主版本号,次版本号后边的两位。和次版本号共同确定了特定的class文件格式,通常只有给定主版本号和一系列次版本号后,Java虚拟机才能够读取class文件。如果class文件的版本号超出了Java虚拟机所能处理的有效范围,Java虚拟机将不会处理该class文件。 |
| u2 | constant_pool_count | 1 | 常量池计数,主版本号的后两位。常量池列表中没有索引为0的入口,但是被constant_pool_count计数在内,所以计数比实际的常量池中要多1 |
| cp_info | constant_pool | constant_pool_count-l | 常量池,常量池计数后的是常量池,文件中的常量内容。常量池入口大多都指向了常量池其他表的入口。 每个常量池人口都从一个长度为一个字节的标志开始,这个标志指出了列表中该位置的常量类型。一旦Java虚拟机获取并解析这个标志,Java虚拟机就会知道在标志后的常量类型是什么。 |
| u2 | access_flags | 1 | 紧接常量池后的两个字节称为access_flags,它展示了文件中定义的类或接口的几段信息。例如,访问标志指明文件中定义的是类还是接口;访问标志还定义了在类或接口的声明中,使用了哪种修饰符﹔类和接口是抽象的,还是公共的;类的类型可以为final,而final类不可能是抽象的;接口不能为final类型。这些标志位的定义如表6-4所示。 |
| u2 | this_class | 1 | 对常量池的索引 |
| u2 | super_class | 1 | 常量池索引 |
| u2 | interfaces_count | 1 | 紧接着super_class的是interfaces_count。此项的含义为:在文件中由该类直接实现或者由接口所扩展的父接口的数量。 |
| u2 | interfaces | interfaces_count | 在接口计数的后面,是名为interfaces的数组,它包含了对每个由该类或者接口直接实现的父接口的常量池索引。每个父接口都使用一个常量池中的CONSTANT_Class_info人口来描述,该CONSTANT_Class_info人口指向接口的全限定名。这个数组只容纳那些直接出现在类声明的implements子句或者接口声明的extends子句中的父接口。超类按照在implements子句和extends子句中出现的顺序(从左到右)在这个数组中显现。 |
| u2 | fields_count | 1 | 变量计数,它是类变量和实例变量的字段的数量总和。 |
| field_info | fields | fields_count | 同长度的field_info表的序列( fields_count指出了序列中有多少个field_info表)。只有在文件中由类或者接口声明了的字段才能在fields列表中列出。在fields列表中,不列出从超类或者父接口继承而来的字段。另一方面,fields列表可能会包含在对应的Java源文件中没有叙述的字段,这是因为Java编译器可能会在编译时向类或者接口添加字段。例如,对于一个内部类的fields列表来说,为了保持对外围类实例的引用,Java编译器会为每个外围类实例添加实例变量。源代码中并没有叙述任何在fields列表中的字段,它们是被Java编译器在编译时添加进去的,这些字段使用Synthetic属性标识。 每个field_info表都展示了一个字段的信息。此表包含了字段的名字、描述符和修饰符。如果该字段被声明为final,field_info表还会展示其常量值。这样的信息有些放在field_info表中,有些则放在由field_info表所指向的常量池中。 |
| u2 | methods_count | 1 | 方法计数 |
| method_info | methods | methods_count | method_info表中包含了与方法相关的一些信息,包括方法名和描述符(方法的返回值类型和参数类型)。如果方法既不是抽象的,又不是本地的,那么method_info表就包含方法局部变量所需的栈空间长度、为方法所捕获的异常表、字节码序列以及可选的行数和局部变量表。如果方法能够抛出任何已验证的异常,那么method_info表就会包括一个关于这些已验证异常的列表。 |
| u2 | attributes_count | 1 | 属性计数,attribute _info表的数量总和。 |
| attribute_info | attribute | attributes_count | 每个attribute _info的第一项是指向常量池中CONSTANT_Utf8_info表的索引、该表给出了属性的名称。 |
常量池标志对应表↓


6.3 特殊字符串
6.3.1全限定名
类或接口的全名,例如:在class文件中,java.util.Hashtable的全限定名表示为java/util/Hashtable。
6.3.2简单名称
字段名和方法名以简单名称的形式出现在常量池入口中。例如,一个指向类java.lang.Object所属方法String toString( )的常量池入口有一个形如“toString”的方法名。
6.3.3 描述符
字段的描述符给出了字段的类型;方法描述符给出了方法的返回值和方法参数的数量、类型以及顺序。
6.4 常量池
术语解释:
字面量:文本字符串、被声明的静态常量、基本数据类型、其他
符号应用:类和结构的完全限定名、字段名称和描述符、方法名称和描述符
每个常量池入口都从一个长度为一个字节的标志开始,这个标志指出了列表中该位置的常量类型。一旦Java虚拟机获取并解析这个标志,Java虚拟机就会知道在标志后的常量类型是什么。
常量池是一个可变长度cp_info表的有序序列。表现如下
| 类型 | 名称 | 数量 |
|---|---|---|
| u1 | tag | 1 |
| u1 | info | tag决定 |
- tag常量池标志(点击跳转到常量池标志表)
- _info表
个人理解:
常量池就像是一个归类的资源仓库,将代码中的常量分类放在同一类型的序列表中。
示例:
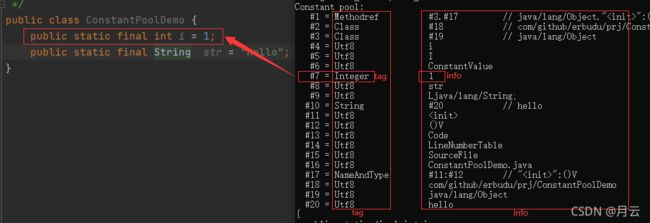
i是一个int类型的常量,在常量池中用Integer标志表示,Integer 标志对应的info表为CONSTANT_lnteger_info,

他的表结构只有两项 tag和byte,tag就是类型标志,byte是值。因为i是基本类型的常量,所以,他的直接量就是1,不再指向别的地址。
反例,比如Methodref对应方法类型的标志,他的表结构为

-
tag = 类型标志
-
class_index = 被引用方法的类的CONSTANT_Class_info人口的索引。所以这一项指向的一定是常量池中某个Class类型的入口
-
name_and_type_index = 方法描述,指向CONSTANT_NameAndType_info入口的索引,该入口提供了方法的简单名称以及描述符。
所以方法类型的常量入对应的表中第二项和第三项会分别指向class类型和ameAndType的类型入口。下图为例。
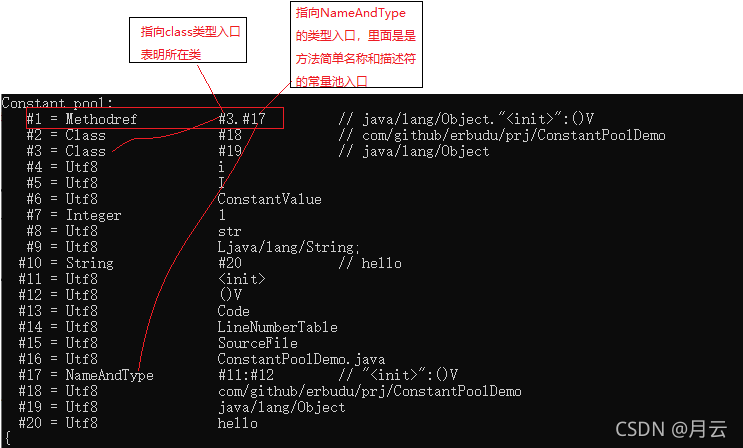
总的来讲,常量池中的类型表之间是纵横交错的相互指向,下边会对每个常量池类型表的结构一一说明。
6.4.1 CONSTANT_Utf8_info表
CONSTANT_Utf8_info

说明:
- tag:入口类型的标志值,
CONSTANT_Utf8的标志值为1(点击跳转常量池标志表) - length :表示第三项
bytes的长度,字节数。 - bytes :按照变体UTF-8格式存储的字符串中的字符。(‘lu0001’到‘lu007f’一个字节表示,空字符null (“\u0000’)和从‘\u0080’到‘\u07ff’的所有字符使用两个字节表示,"\u0800’到“uffff’的所有字符使用三个字节表示。)
可变长度的CONSTANT_Utf8_info表使用一种UTF-8格式的变体来存储一个常量字符串。这种类型的表可以存储多种字符串,包括以下:
- 文字字符串,如String对象。
- 被定义的类和接口的全限定名。
- 被定义的类的超类(如果有的话)的全限定名。
- 被定义的类和接口的父接口的全限定名。
- 由类或者接口声明的任意字段的简单名称和描述
- 由类或者接口声明的任意方法的简单名称和描述
- 任何引用的类和接口的全限定名。
- 任何引用的字段的简单名称和描述符。
- 任何引用的方法的简单名称和描述符。
- 与属性相关的字符串
6.4.2 CONSTANT_lnteger_info表
CONSTANT_lnteger_info

说明:
该表值存int类型的值,不存储符号引用。
- tag : 入口类型的标志值,
CONSTANT_lnteger的标志值为3(点击跳转常量池标志表) - bytes: bytes项中按照高位在前的格式存储int类型值。
6.4.3 CONSTANT_Float_info表
CONSTANT_Float_info

说明:
该表只存储float类型的值,不存储符号引用。
- tag:入口类型的标志值,
CONSTANT_Float的标志值为4(点击跳转常量池标志表) - bytes:bytes项中按照高位在前的格式存储float类型值。
6.4.4 CONSTANT_Long_info表

6.4.5 CONSTANT_Double_info表

6.4.6 CONSTANT_Class_info表
CONSTANT_Class_info

说明:
固定长度的CONSTANT_Class_info表使用符号引用来表述类或者接口。无论指向类、接口、字段,还是方法,所有的符号引用都包含一个CONSTANT_Class_info表。
- tag :入口类型的标志值,
CONSTANT_Class的标志值为7(点击跳转常量池标志表) - name_index:name_index项给出了包含类或者接口全限定名的CONSTANT_Utf8_info表的索引。
name_index给出的是指向utf8的一个索引,因为类或接口的完全限定名是在utf8表中,所以这个索引最终会指向常量表中的完全限定名。
示例:

6.4.7 CONSTANT_String_info表
固定长度的CONSTANT_String_info表用来存储文字字符串值,该值亦可表示为类java.lang.String的实例。该表只存储文字字符串值,不存储符号引用。
CONSTANT_String_info

说明:
- tag:入口类型的标志值,
CONSTANT_String的标志值为8(点击跳转常量池标志表) - string_index:给出了包含文字字符串值的CONSTANT_Utf8_info表的索引。
不存储符号引用,string_index给出的是指向utf8表的索引,因为string类型的是在utf8表中,索引最终指向的肯定是一个字符串。
6.4.8 CONSTANT_Fieldref_info表
CONSTANT_Fieldref_info

说明:
固定长度的CONSTANT_Fieldref_info表描述了指向字段的符号引用。
- tag:入口类型的标志值,
CONSTANT_Fieldref的标志值为9(点击跳转常量池标志表) - class_index:class_index项给出了声明被引用字段的类或者接口的CONSTA.NT_Class_info入口的索引。
- name_and_type_index:提供了CONSTANT_NameAndType_info人口的索引,该人口提供了字段的简单名称以及描述符。最终也是指向的utf8,有关字段的描述是在utf8表中。
6.4.9 CONSTANT_Methodref_info表
固定长度的CONSTANT_Methodref_info表使用符号引用来表述类中声明的方法(不包括接口中的方法)。
CONSTANT_Methodref_info

说明:
- tag: 入口类型的标志值,
CONSTANT_Methodref的标志值为10(点击跳转常量池标志表) - class_ index:给出了声明了被引用方法的类的CONSTANT_Class_info人口的索引。class_index所指定的CONSTANT_Class_info表必须为类,不能为接口。指向接口中声明的方的符号引用使用CONSTANT_InterfaceMethodref表。
- name_and_type_index:提供了CONSTANT_NameAndType_info入口的索引,该入口提供了方法的简单名称以及描述符。
6.4.10 CONSTANT_lnterfaceMethodref_info表

6.4.11 CONSTANT_NameAndType_info表
CONSTANT_NameAndType_info

说明:
固定长度的CONSTANT_NameAndType_info表构成指向字段或者方法的符号引用的一部分。该表提供了所引用字段或者方法的简单名称和描述符的常量池入口。
- tag: 入口类型的标志值,
CONSTANT_NameAndType的标志值为12(点击跳转常量池标志表) - name_index:给出了CONSTANT_Utf8_info入口的索引,该人口给出了字段或者方法的名称。该名称或者为一个有效的Java程序设计语言的标识符,或者为。
- descriptor_index提供了CONSTANT_Utf8_info入口的索引,该入口提供了字段或者方法的描.述符。该描述符必须为一个有效的字段或者方法的描述符。
6.5 字段
字段信息对应field_info表,不会有同名字段。
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | access_flags | 1 |
| u2 | name_index | 1 |
| u2 | descriptor_index | 1 |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attribute_count |
- access_flags:表示字段类型
- name_index:字段 简单名,的
constant_utf8_info入口的索引。 - descriptor_index:字段描述符的
constant_utf8_info入口的索引。 - attribute_count:指出列表中
attribute_info表的数量。 - attributes:由多个
attributes_info表组成。
6.6方法
在class文件中,方法由一个长度可变的method_info表来描述。

- access_flags:方法修饰符(方法类型)。
- name_index:方法简单名,的
constant_utf8_info入口的索引。 - descriptor_index:方法描述符的
constant_utf8_info入口的索引。 - attribute_count:指出列表中
attribute_info表的数量。 - attributes:由多个
attributes_info表组成。
6.7属性
6.7.1 属性格式
| 名称 | 使用者 | 描述 |
|---|---|---|
| Code | method_info | 方法的字节码和其他数据 |
| Constant Value | field_info | final变量的值 |
| Deprecated | field_info、method_info | 字段或方法被禁用的指示符 |
| Exception | method_info | 方法被抛出的可能被检测的异常 |
| Inner Class | Class File | 内部、外部类的列表 |
| Line Number Table | Code_attribute | 方法行号和字节码的映射 |
| LocalVariableTable | Code_attribute | 方法的局部变量的描述 |
| SourceFile | ClassFile | 源文件名 |
| Synthetic | field_info、method_info | 编译器产生的字段或者方法的指示符 |
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u1 | info | attribute_length |
第7章 类型的生命周期
7.1类型装载、连接、初始化
Java虚拟机通过加载、连接和初始化一个Java类型,使该类型可以被正在运行的Java程序所使用。
- 装载:将二进制的Java类型读入Java虚拟机中。
- 连接:将虚拟机中二进制类型的数据合并到虚拟机的运行时状态中去。
连接分为三个子步骤:
- 验证:去报Java类型正确可以被Java虚拟机使用。
- 准备:分配内存
- 解析:将常量池中的符号引用转换为直接引用。这个过程也可以初始化之后进行
- 初始化:给变量赋值
类和接口的初始化时机
- 创建类实例时。new 的时候
- 调用某个类的静态方法时
- 使用某个类或者接口的静态字段时,或者对该字段赋值时
- 使用反射方法时
- 初始化子类时
- 某个类被标明为启动类时
除了上边说的6种情况外,其他使用Java类型的方式都是被动使用,他们不会导致Java类型的初始化。
使用某个类型前要求所有的超类都要被初始化,而一个接口的初始化并不要求他的祖先接口预先初始化。
7.1.1 装载
装载阶段由三个基本动作组成,要装载一个类型,Java虚拟机必须:
- 用过一个该类型的完全限定名,产生一个代表该类的二进制数据流。
- 解析这个二进制数据流为方法区内的内部数据结构。
- 创建一个表示该类的java.lang.Class类的实例
7.1.2 验证
验证主要是对字节码完整性的验证,第三章有详细的讲到。
7.1.3 准备
准备阶段主要是为类变量分配内存,设置默认初始值。在准备阶段是不会执行Java代码的。
7.1.4 解析
验证、准备、解析都是连接的过程,解析就是在类型的常量池中寻找类、接口、字段、方法的符号引用,把这些符号引用替换成直接引用的过程。
7.1.5初始化
初始化就是为类变量赋予正确的初始值。注意区分不是类型的默认值,是初始值。
初始化永远先初始化这个类的超类。
7.2 对象的生命周期
一个类一旦被装载、连接、初始化之后就可以使用了。程序可以访问他的静态字段、静态方法以及创建他的实例。
7.2.1 类的实例化
三种创建类实例的方法:
- 明确的使用new操作符。
- 调用Class或者java.lang.reflect.Constructor对象的newInstance ()方法。
- 调用现有对象的clone()方法。
- java.io.ObjectInputStream类的getObject ( )方法反序列化。
以上为显示实例化类的方法,其他隐式初始化类的方式不做赘述。
7.2.1 垃圾手机和对象的终结
7.3 卸载类型
如果某些动态装载的类型只是临时需要,当他不再被使用时,占据的内存空间可以使用卸载的方式使其被释放。