计算机编程语言的代码——编码
编码
电脑是由电路板组成,电路板里面集成了无数的电阻和电容,交流电经过电容的时候,电压比较低记为低电平,用0表示,交流电流过电阻的时候,电压比较高,记为高电平,用1来表示;所以每一个0和1在计算机中被称为位,也就是bit位。然而,如果使用一个位来表示计算机中的最小存储单元,那么这个存储单元只能存储0或1,存储范围太小,所以规定用9个bit位为一组来表示计算机的最小存储单元。
计算机底层只能存储0和1,但是计算机是如何存储诸如英文、符号字符,汉字等内容的呢?
因为语言和字形的不同,每个人都可以约定自己的一套(这就叫编码)而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示 。
常见的编码表
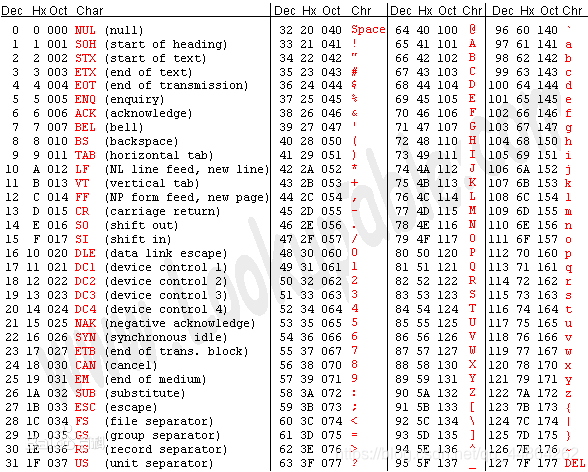
ASCII
世界上虽然有各种各样的字符,但是计算机发明之初只考虑了美国的需求,大概只需要128个字符就能全部表示出来。128个字符用7个位刚好可以表示,计算机存储的最小单位是byte,即8为,ASCII码中最高位设置为0,用剩下的7位表示字符。
数字32到126表示的这些字符都是可打印字符,0到31和127表示一些不可以打印的字符,这些字符一般用于控制目的。
ISO-8859-1
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。此字符集支持部分于欧洲使用的语言。

windows-1252
ISO-8859-1用于西欧国家,但其没有欧元€这个符号,因为欧元比较晚。实际使用中更为广泛的是windows-1252编码。
这个编码中加入了欧元符号以及一些其他常用的字符。在很多应用程序中,即使文件声明采用 ISO-8859-1编码,解析是依然采用windows-1252编码。
GB2312
美国和西欧字符只用一个字节就够了,但是中文显然是不够的。中文第一个标准时GB2312,GB2312标准主要针对的是简体中文常见字符,包括约7000个汉字。GB2312固定使用两个字节表示汉字,在这两个字节中,最高位都是1,如果是0,就认为是ASCII字符。
GBK
GBK建立在GB2312的基础上,向下兼容GB2312。GBK增加了一万四千多个汉字,共计约21000汉字,其中包括繁体字。
汉字是用两个字节表示的,在解析二进制流的时候,如果第一个字节的最高位是1,那么就将下一个字节读进来一起解析为一个汉字,而不用考虑它的最高位。解析完后,跳到第三个字节继续解析。
GB18030
GB18030主要有以下特点:
-
采用变长多字节编码,每个字可以由1个、2个或4个字节组成。
-
编码空间庞大,最多可定义161万个字符。
-
完全支持Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及emoji等字符。
Big5
Big5针对繁体中文,广泛用于台湾香港。包括一万三千多个繁体字,和GB2312类似,一个字符同样固定使用两个字节表示。和GB系列不兼容。
Unicode
世界上还有很多国家的字符,每个国家的各种计算机厂商都对自己常用的字符进行编码,在编码的时候基本忽略了其他国家的字符和编码,这样造成的结果就是,出现了太多的乱码,且互相不兼容。
世界上所有的字符能不能统一编码呢?可以,这就是Unicode。
Unicode做了一件事,就是给世界上所有字符都分配了唯一的数字编号,这个编号范围从0x000000到0x10FFFF,即65536个数字之内。每个字符都有一个Unicode编号,这个编号一般携程16进制,在前面加U+。大部分中文的编号方位在U+4E00到U+9FA5。
Unicode给所有字符分配了唯一数字编号,但是并没有规定编号如何对应到二进制表示。
UTF-32(或 UCS-4)
UTF-32 (或 UCS-4)是一种将Unicode字符编码的协定,对每一个Unicode码位使用恰好32位元。其它的Unicode transformation formats则使用不定长度编码。因为UTF-32对每个字符都使用4字节,就空间而言,是非常没有效率的。特别地,非基本多文种平面的字符在大部分文件中通常很罕见,以致于它们通常被认为不存在占用空间大小的讨论,使得UTF-32通常会是其它编码的二到四倍。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。
UTF-16
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 “storage format”)的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
UTF-8
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。