Flask Web开发:数据库
目录
在虚拟环境中安装Flask-SQLAlchemy:
一、配置
数据库配置示例:
二、定义模型
Role 和 User 模型代码:
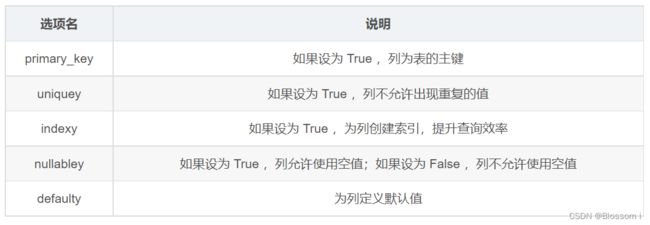
(1)常用的 SQLAlchemy 列类型:编辑
(2)常用的 SQLAlchemy 列选项:
三、关系
在数据库模型中定义关系补充如下:
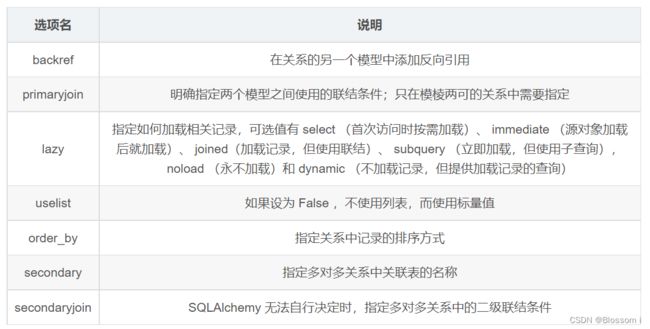
常用的 SQLAlchemy 关系选项:编辑
除了一对多关系之外:
四、数据库操作
(1)设置FLASK_APP 环境变量
(2)虚拟环境终端中使用 flask shell 命令启动
4.1 创建表
4.2 插入行
(1)创建一些角色和用户如下:
(2)对数据库的改动通过数据库会话(也称事务)管理,由 db.session 表示。准备把对象写入数据库之前,要先将其添加到会话中:
(3)然后我们调用 commit() 方法提交会话,这样对象才被真正写入了数据库。
(4)数据库会话(事务)可以保证数据库的一致性。
(5)要查看data.sqlite。
4.3 修改行
4.4 删除行
4.5 查询行
(1)Flask-SQLAlchemy 为每个模型类都提供了 query 对象。最基本的模型查询是使用 all() 方法取回对应表中所有记录:
如果退出了当前 shell,再重新打开的。
(2)常用的 SQLAlchemy 查询过滤器:
这里我们使用 Flask-SQLAlchemy 扩展来进行数据库操作,SQLAlchemy 是一个强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy 提供了高层 ORM,也提供了使用数据库原生 SQL 的低层功能。
在虚拟环境中安装Flask-SQLAlchemy:
pip install flask-sqlalchemy
一、配置
在 Flask-SQLAlchemy 中,数据库使用 URL 指定,如下:
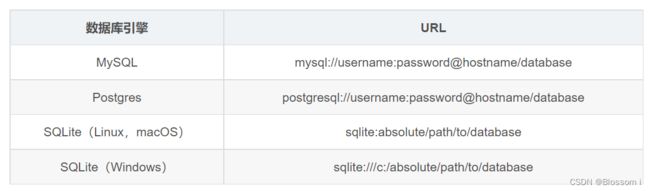
数据库引擎 URL
MySQL mysql://username:password@hostname/database
Postgres postgresql://username:password@hostname/database
SQLite(Linux,macOS) sqlite:absolute/path/to/database
SQLite(Windows) sqlite:///c:/absolute/path/to/databasehostname:数据库服务所在的主机
database:要使用的数据库名
username:数据库用户名
password:数据库密码
注意:
SQLite 数据库没有服务器,因此不用指定 hostname、username 和 password。URL 中的 database 是磁盘中的文件名。
使用的数据库URL必须保存到 Flask 配置对象的 SQLALCHEMY_DATABASE_URI 键中。
建议把 SQLALCHEMY_TRACK_MODIFICATIONS 键设为 False,以便在不需要跟踪对象变化时降低内存消耗。
数据库配置示例:
import os
from flask_sqlalchemy import SQLAlchemy
# 定义SQLite绝对路径
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + \
os.path.join(basedir, 'data.sqlite')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app) # 实例化SQLAlchemy
二、定义模型
在 ORM(对象关系映射器)中,模型一般是一个 Python 类,类中的属性对应于数据库表中的列。Flask-SQLAlchemy 实例为模型提供了一个基类以及一系列辅助类和辅助函数,可用于定义模型的结构。
如下实体 – 关系图中的 roles 表和 users 表,我们可以分别定义为 Role 和 User 模型: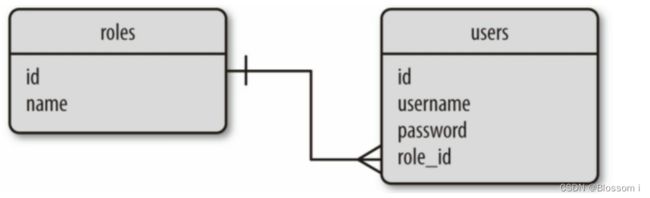
Role 和 User 模型代码:
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return '' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return '' % self.username
类变量 __tablename__ 定义在数据库中使用的表名,如不定义,则会使用默认的表名。
db.Column 类构造函数的第一个参数是数据库列和模型的类型,其他参数则是一些列选项,如主键(primary_key)、索引(index)、不允许重复(unique)等。
__repr()__ 方法返回一个具有可读性的字符串表示模型,不是强制要求,可方便调试和测试。
(1)常用的 SQLAlchemy 列类型:
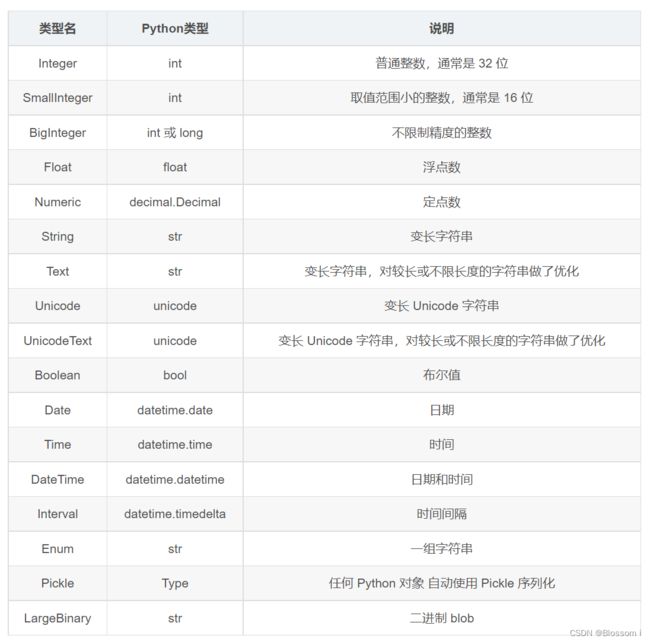
(2)常用的 SQLAlchemy 列选项:
三、关系
关系型数据库使用关系把不同表中的行联系起来,上面那个关系图中表示的实际上是一种一对多关系,即一个角色可属于多个用户,而每个用户只能由一个角色。
在数据库模型中定义关系补充如下:
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
也就是
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
users = db.relationship('User', backref='role')
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))将 User 模型中的 role_id 列定义为外键,来联接这两个表。传给 db.ForeignKey() 的参数 roles.id 声明,这列的值是 roles 表中相应行的 id值。
添加到 Role 模型中的 users 属性,代表整个关系的面向对象视角,对于一个 Role 类的实例,其 users 属性将返回与角色相关联的用户组成的列表。
db.relationship() 的第一个参数编码整个关系的另一端是哪个模型;backref 参数向 User 模型中添加一个 role 属性,从而定义反向关系。通过 User 实例的这个role属性可以获取对应的 Role 模型的对象数情况下,db.relationship() 都能自行找到关系中的外键,但有时却无法确定哪一列是外键。
例如,如果 User 模型中有两个或以上的列定义为 Role 模型的外键,SQLAlchemy 就不知道该使用哪一列。如果无法确定外键,就要为 db.relationship() 提供额外的参数。
常用的 SQLAlchemy 关系选项:
除了一对多关系之外:
一对一 关系可以用一对多关系表示,但调用 db.relationship() 时要把 uselist 设为 False ,把“多”变成“一”。
多对一 关系也可使用一对多表示,对调两个表即可,或者把外键和 db.relationship() 都放在“多”这一侧。
最复杂的关系类型是多对多 ,需要用到第三张表,这个表称为关联表(或联结表 )。
四、数据库操作
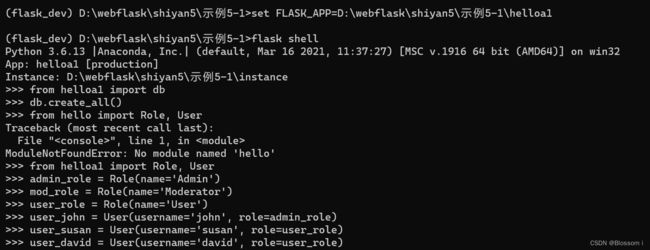
为了方便学习,我们先再Python shell中实际操作数据库模型,先设置 FLASK_APP 环境变量,然后再虚拟环境终端中使用 flask shell 命令启动。
(1)设置FLASK_APP 环境变量
先看要运行的.py文件是哪个目录下
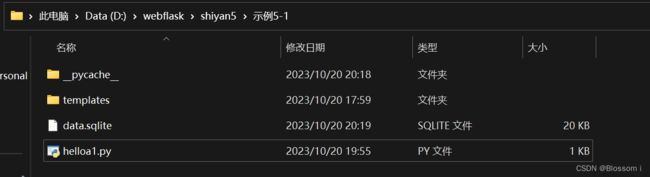
根据图片可知,路径 D:\webflask\shiyan5\示例5-1\hello5-1.py, Flask 应用程序文件名为 hello5-1.py。
在运行 flask shell 命令之前,请确保已经正确设置了环境变量 FLASK_APP,并且值为应用程序文件的完整路径。在 Windows 环境下,可以使用以下命令设置环境变量:
set FLASK_APP=D:\webflask\shiyan5\示例5-1\helloa1.py (2)虚拟环境终端中使用 flask shell 命令启动
flask shell
4.1 创建表
首先要让 Flask-SQLAlchemy 根据模型类创建数据库。 db.create_all() 函数将寻找所有 db.Model 的子类,然后再数据库中创建对应的表:
>>> from helloa1 import db
>>> db.create_all()
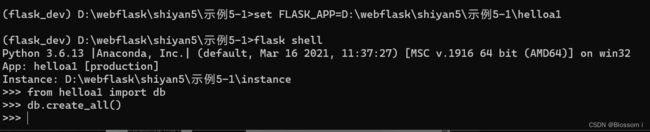
执行完上面命令后,在应用目录中就会产生一个 data.sqlite文件。
如果数据库表已经存在于数据库中,那么 db.create_all() 不会重新创建或者更新相应的表。使用 db.drop_all() 可以删除旧表,然后再重新创建,这样可以更新数据库,但是并不推荐,因为会丢失原有的数据。

更新现有数据库表的粗暴方式是先删除旧表再重新创建:
>>> db.drop_all()
>>> db.create_all()4.2 插入行
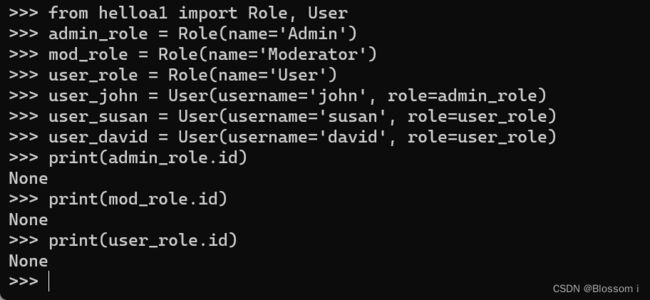
(1)创建一些角色和用户如下:
>>> from helloa1 import Role, User
>>> admin_role = Role(name='Admin')
>>> mod_role = Role(name='Moderator')
>>> user_role = Role(name='User')
>>> user_john = User(username='john', role=admin_role)
>>> user_susan = User(username='susan', role=user_role)
>>> user_david = User(username='david', role=user_role)
1.模型的构造函数接受的参数是使用关键字参数指定的模型属性初始值。
2.role 属性也可使用,虽然它不是真正的数据库列,但却是一对多关系的高级表示。
3.id 属性为主键,通常有数据库自身管理。而现在这些对象只存在于 Python 中,还未写入数据库,因此 id 并未赋值。
(2)对数据库的改动通过数据库会话(也称事务)管理,由 db.session 表示。准备把对象写入数据库之前,要先将其添加到会话中:
>>> db.session.add(admin_role)
>>> db.session.add(mod_role)
>>> db.session.add(user_role)
>>> db.session.add(user_john)
>>> db.session.add(user_susan)
>>> db.session.add(user_david)
也可以简写成
>>> db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david])
(3)然后我们调用 commit() 方法提交会话,这样对象才被真正写入了数据库。
>>> db.session.commit()
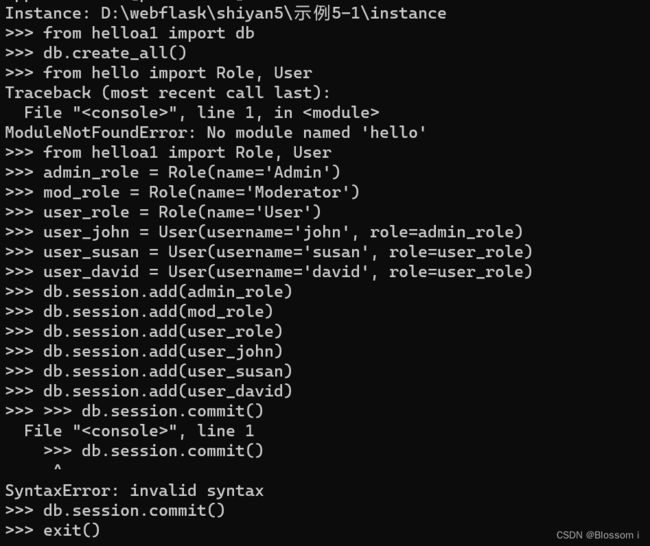
(4)数据库会话(事务)可以保证数据库的一致性。
提交操作使用原子方式把会话中的对象全部写入数据库。如果在写入会话的过程中发生了错误,那么整个会话都会失效。如果你始终把相关改动放在会话中提交,就能避免因部分更新导致的数据库不一致。
数据库会话也可以调用 db.session.rollback() 进行回滚,回滚后添加到数据库会话中的所有对象都将还原到它们在数据库中的状态。
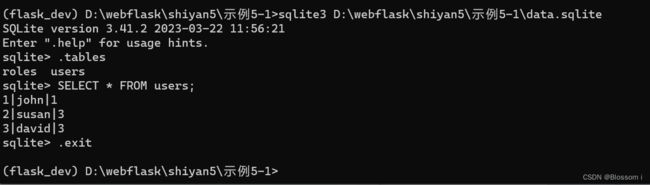
(5)要查看data.sqlite。
位于 D:\webflask\shiyan5\示例5-1\data.sqlite 路径下的 SQLite 数据库中的表,请按照以下步骤操作:
-
打开 SQLite 命令行工具。你可以在终端中输入以下命令:
sqlite3 D:\webflask\shiyan5\示例5-1\data.sqlite -
在 SQLite 命令行工具中,输入
.tables命令。这将显示出当前数据库中的所有表格名称。.tables -
如果你想查看某个特定表格中的数据,请使用 SELECT 查询语句。例如,如果你想查看名为
users的表格中的所有数据,请输入以下命令:SELECT * FROM users;这将返回
users表格中的所有数据。 -
请注意,表格名称必须以小写字母输入,否则可能会找不到表格。另外,建议在表格名称后面添加分号(
;)来结束查询语句,这样可以确保命令被正确解释。
4.3 修改行
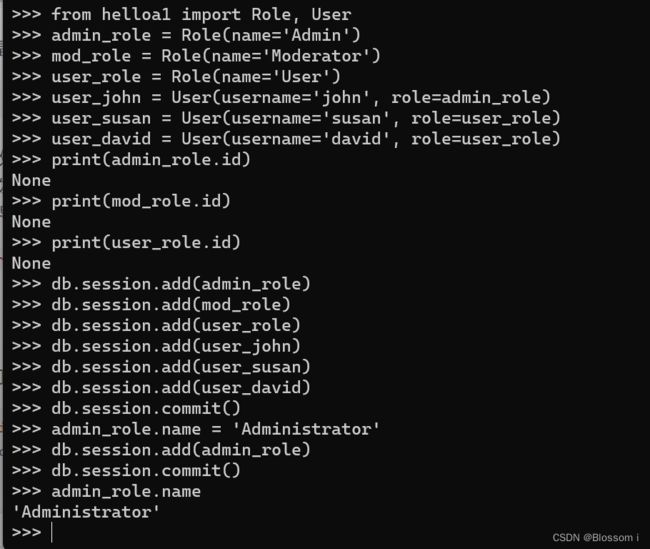
在数据库会话上调用 add() 方法也可以更新模型,如将 Admin 角色重命名未 Administrator:
>>> admin_role.name = 'Administrator'
>>> db.session.add(admin_role)
>>> db.session.commit()
>>>> admin_role.name
'Administrator'

4.4 删除行
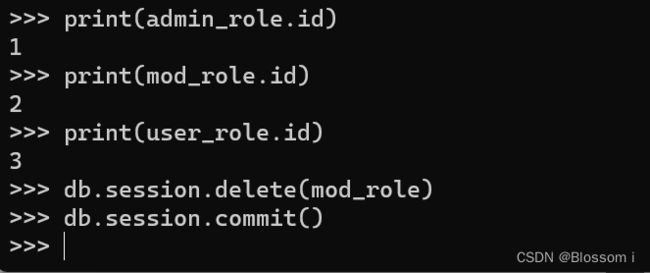
数据库会话可以用 delete() 方法来删除数据,如将 Moderator 角色从数据库中删除:
>>> db.session.delete(mod_role)
>>> db.session.commit()
删除与插入和更新一样,只有提交数据库会话后才会执行。
4.5 查询行
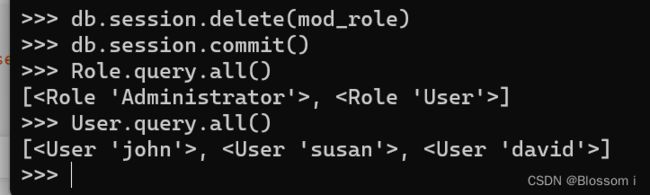
(1)Flask-SQLAlchemy 为每个模型类都提供了 query 对象。最基本的模型查询是使用 all() 方法取回对应表中所有记录:
>>> Role.query.all()
[, ]
>>>
>>> User.query.all()
[, , ]
使用过滤器可以配置 query 对象来进行更精准的数据库查询,如查找角色为 “User” 的所有用户
>>> User.query.filter_by(role=user_role).all()
[, ]

若想查看 SQLAlchemy 为查询生成的原生SQL语句,可以将 query 对象转换为字符串:
>>> str(User.query.filter_by(role=user_role))
'SELECT users.id AS users_id, users.username AS users_username, users.role_id AS users_role_id \nFROM users \nWHERE ? = users.role_id'

如果退出了当前 shell,再重新打开的。
前面例子创建的对象就不会以 Python 对象的方式存在,只能从数据库表中进行读取,重新创建Python对象。如下例发起一个查询,加载名为“User” 的用户角色:
user_role = Role.query.filter_by(name='User').first()
- first() 方法只返回第一个结果,如果没有结果的化,返回None。
- all() 方法以列表的形式返回查询到的所有结果。
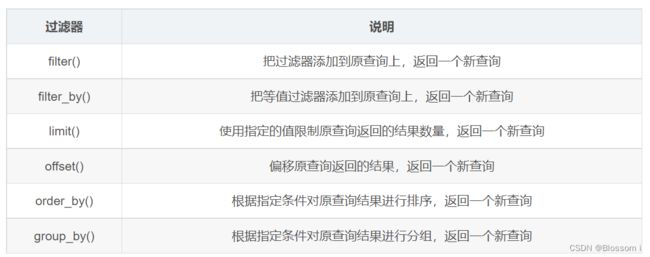
(2)常用的 SQLAlchemy 查询过滤器:
(3)常用的 SQLAlchemy 查询执行方法:

(4)关系与查询的处理方式类似,下面的例子首先查询角色为 User 的用户有哪些,然后又查询了用户susan的角色是什么,分别从关系的两端查询角色和用户之间的一对多关系。
>>> users = user_role.users
>>> users
[, ]
>>> users[0].role
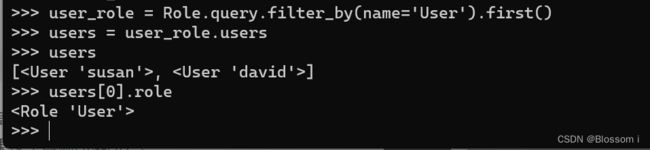
可以发现这里再执行 user_role.users时,隐式的调用了 all()方法,此时 query 对象被隐藏了,这样就无法再使用过滤器进行更精准的查询(如将结果按字母顺序排序)。
要想解决这个问题,我们需要在 Role 类的 db.relationship() 方法中加入 lazy='dynamic' 参数的设置,从而禁止自动执行查询。
示例5-4:helloa1.py:动态数据库关系
class Role(db.Model):
# ...
users = db.relationship('User', backref='role', lazy='dynamic')
# ...
原来的
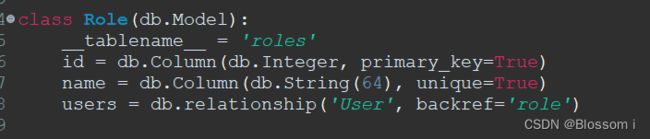
加了之后

这样配置关系之后,user_role.users 将返回一个尚未执行的查询,因此可以在其上添加过滤器:
>>> user_role.users.order_by(User.username).all()
[, ]
>>> user_role.users.count()
2