mysql索引失效的情况以及left join关联字段字符集排序规则造成索引失效
一 索引失效的情况
1.1 新建表
CREATE TABLE `tb_user` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`u_name` varchar(255) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `n_index` (`u_name`) USING BTREE COMMENT '加快检索',
KEY `add_index` (`address`) USING BTREE COMMENT '加快检索'
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
1.1.1 like模糊匹配的时候以%开头
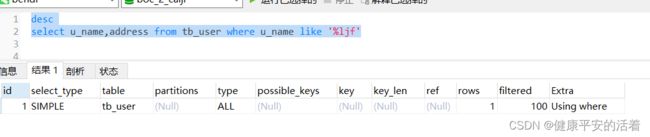
1.错误:
desc
select u_name,address from tb_user where u_name like '%ljf'
2.正确:
desc
select u_name from tb_user where u_name like 'ljf%'

1.1.2 据类型隐式或显式转换
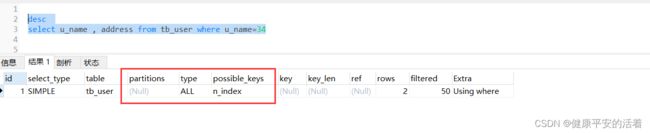
1.错误
desc
select u_name , address from tb_user where u_name=34
2.正确

1.1.3 多表联合查询的关联字段的排序规则或字符集不相同
见后面案例详解
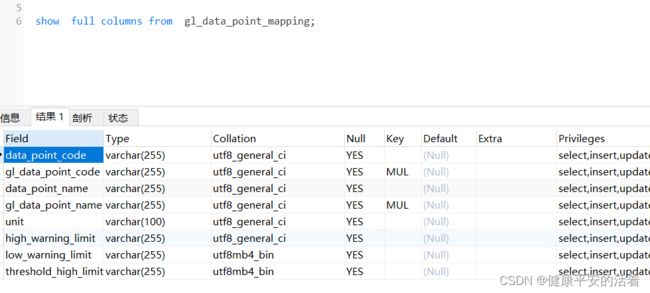
通过以下方法查看表的字符集和排序规则:
1.1.4 多表联合查询的关联字段的排序规则或字符集不相同
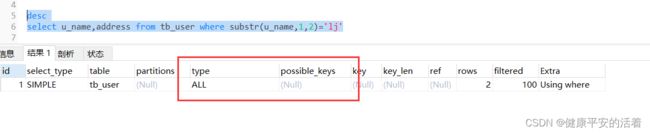
1.错误
desc
select u_name,address from tb_user where substr(u_name,1,2)='lj'
2.正确
desc
select u_name,address from tb_user where u_name='lj'

1.1.5 违反联合索引的最左匹配规则
1.错误
desc
select u_name,address from tb_user where create_time>='2022-07-08 00:00:00'

2.正确
desc
select u_name,address from tb_user where u_name='ljf' and create_time>='2022-07-08 00:00:00'

二 left join关联字段字符集和排序规则不同造成索引失效
2.1 问题描述
1.表a 的字段gl_data_point_code的字符集为:utf8mb4,排序规则为utf8mb4_bin
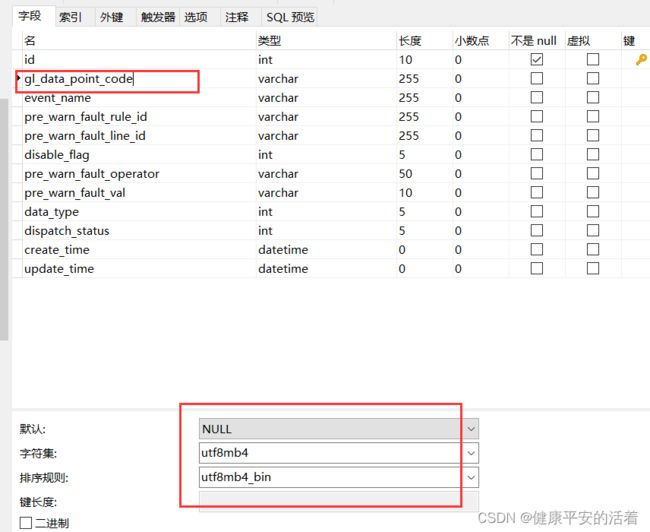
1.表a的索引

2.表b的gl_data_point_code的字符集为 utf8 排序规则为utf8_general_ci

2.表b的索引

两张表的关联字段gl_data_point_code都建立了索引。
3.两张表的数据量为:4176 和34090
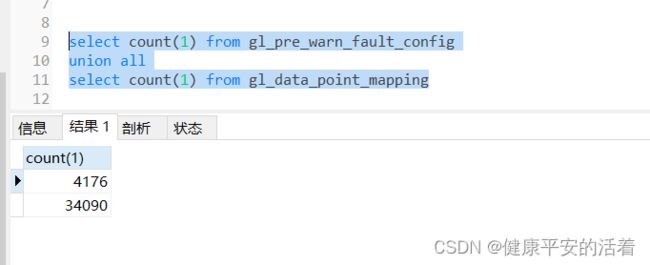
4.写关联查询sql:
select a.gl_data_point_code,b.gl_data_point_code from gl_pre_warn_fault_config as a left join gl_data_point_mapping as b on a.gl_data_point_code=b.gl_data_point_code
可以看到耗时:24.943秒
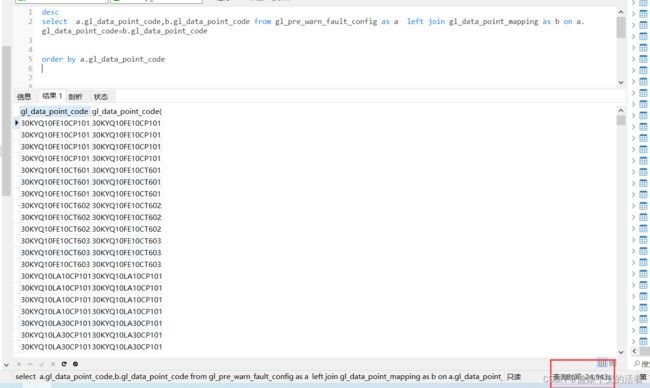
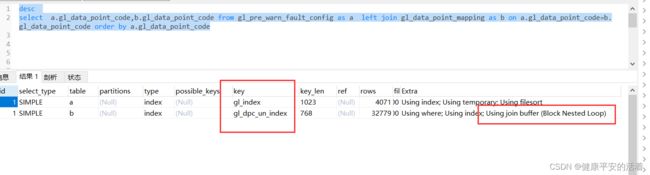
查看执行计划:可以看到a表使用到了normal索引 gl_index,b表使用了unique索引且extar中存在:Using join buffer (Block Nested Loop) ,耗时24s多,简直不能容忍!!!
2.2 解决办法
结果排查,好巧不巧,中招了,根据前面列举出两张表的关联字段gl_data_point_code的字符集不同一个:表a 的字段gl_data_point_code的字符集为:utf8mb4,排序规则为utf8mb4_bin;表b的gl_data_point_code的字符集为 utf8 排序规则为utf8_general_ci。正好违背了多表联合查询的关联字段的排序规则或字符集不相同,索引失效的情况。
1.这里将a表中gl_data_point_code字符集修改成:字符集为 utf8 排序规则为utf8_general_ci
2.再次执行sql:可以看到耗时0.054s 从24秒 提速到0.054秒
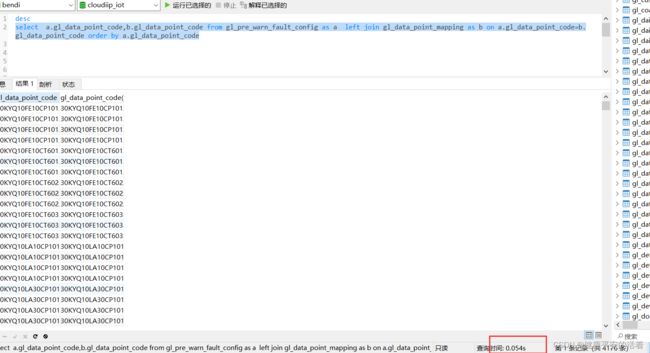
3.查看sql执行计划:b表使用了unique索引且extar中为:Using index

2.3 原因分析
这是因为两个表的关联字段gl_data_point_code字符集不同,一个是utf8,一个是utf8mb4,所以做表连接查询的时候用不上关联字段的索引。utf8mb4是utf8的超集,所以当这两个类型的字符串在做比较的时候,MySQL内部的操作是先将utf8转换成utf8mb4字符集,再做比较。
select a.gl_data_point_code,b.gl_data_point_code from gl_pre_warn_fault_config as a left join gl_data_point_mapping as b on convert(a.gl_data_point_code using utf8 ) =b.gl_data_point_code
这就会触发:对索引字段做函数操作,优化器会放弃树搜索功能, 关联字段的索引失效。
结论:
如果将两个表的关联字段的字符集不相同,而且排序规则也不同,那么索引会失效。
如果将两个表的关联字段的字符集保持相同,但是排序规则不同,那么索引会失效。
有没有排序规则相同而字符集不同呢?哈哈哈,显然是没有的,排序规则就是根据字符集来定义的。