Linux-内存管理机制、内存监控、buffer/cache异同
在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,表面感觉是内存不够用了,其实不然。这是Linux内存管理的一个优秀特性,主要特点是,无论物理内存有多大,Linux 都将其充份利用,将一些程序调用过的硬盘数据读入内存(buffer/cache),利用内存读写的高速特性来提高Linux系统的数据访问性能。在这方面,区别于Windows的内存管理。本文从Linux的内存管理机制入手,简单介绍linux如何使用内存、监控内存,linux与windows内存管理上的区别简介,linux内存使用的一大特点(buffer/cache的异同)
一、Linux内存管理机制
1、物理内存和虚拟内存
我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。
作为物理内存的扩展,linux会在物理内存不足(注意这一条件,这一条件的量化分析请参考https://www.douban.com/note/349467816/)时,使用交换分区的虚拟内存,更详细的说,就是内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
Linux的内存管理采取的是分页存取机制(详细可参考http://www.linuxeye.com/Linux/1931.html),为了保证物 理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
要深入了解linux内存运行机制,需要知道下面提到的几个方面:
Linux系统会根据系统配置不时地进行页面交换操作,以保持一定量的空闲物理内存,有些配置下即使并没有什么事情需要内存,Linux也会交换出暂时不用的内存页面。这可以避免等待交换所需的时间。相关的配置有/etc/sysctl.conf中的vm.swappiness配置(配制方法请参考http://www.vcaptain.com/?id=17),该参数的作用简单描述就是“当 swappiness 内容的值为 0 时,表示最大限度地使用物理内存,物理内存使用完毕后,才会使用 swap 分区;当 swappiness 内容的值为 100 时,表示积极地使用 swap 分区,并且把内存中的数据及时地置换到 swap 分区。Linux 系统初始安装完成时,其默认值为 60, 这表示空闲物理内存少于 60% 时开始启用内存置换算法,将内存中不常使用的数据置换到 swap 分区。”(具体如何起作用请参考https://www.douban.com/note/349467816/)
Linux 进行页面交换是有条件的,不是所有页面在不用时都交换到虚拟内存,linux内核根据”最近最经常使用“算法,仅仅将一些不经常使用的页面文件交换到虚拟 内存,有时我们会看到这么一个现象:linux物理内存还有很多,但是交换空间也使用了很多。其实,这并不奇怪,例如:一个占用很大内存的进程运行时,需 要耗费很多内存资源,此时就会有一些不常用页面文件被交换到虚拟内存中,但后来这个占用很多内存资源的进程结束并释放了很多内存时,刚才被交换出去的页面 文件并不会自动的交换进物理内存,除非有这个必要,那么此刻系统物理内存就会空闲很多,同时交换空间也在被使用,就出现了刚才所说的现象了。关于这点,不 用担心什么,只要知道是怎么一回事就可以了。
交换空间的页面在使用时会首先被交换到物理内存,如果此时没有足够的物理内存来容纳这些页 面,它们又会被马上交换出去,如此以来,虚拟内存中可能没有足够空间来存储这些交换页面,最终会导致linux出现假死机、服务异常等问题,linux虽 然可以在一段时间内自行恢复,但是恢复后的系统已经基本不可用了。
分配太多的Swap空间会浪费磁盘空间,而Swap空间太少,则系统会发生错误。 如果系统的物理内存用光了,系统就会跑得很慢,但仍能运行;如果Swap空间用光了,那么系统就会发生错误。例如,Web服务器能根据不同的请求数量衍生 出多个服务进程(或线程),如果Swap空间用完,则服务进程无法启动,通常会出现“application is out of memory”的错误,严重时会造成服务进程的死锁。因此Swap空间的分配是很重要的。
因此,合理规划和设计Linux内存的使用,是非常重要的。
二、内存的监控
作为一名Linux系统管理员,监控内存的使用状态是非常重要的,通过监控有助于了解内存的使用状态,比如内存占用是否正常,内存是否紧缺等等,监控内存最常使用的命令有free、top等,下面是某个系统free的输出(free默认单位是KB):
[root@xxxxx ~]# free
total used free shared buffers cached
Mem: 3894036 3473544 420492 0 72972 1332348
-/+ buffers/cache: 2068224 1825812
Swap: 4095992 906036 3189956
我们使用total1、used1、 free1、used2、free2 等名称来代表上面统计数据的各值,1、2 分别代表第一行(不考虑标题行)和第二行(不考虑标题行)的数据。
--------第一行数据:代表内核角度的统计--------
total1:表示物理内存总量。
used1:表示已使用(已分配出去)的物理内存总量,包括真正已使用和分配给缓存(包含buffers 与cached)的数量。
free1:未被分配的物理内存。
shared1:共享内存,一般系统不会用到,这里也不讨论。
buffers1: 系统分配给buffers 的内存大小。
cached1:系统分配给cached 的内存数量。buffer 与cache 的区别见后面。
--------第二行数据:代表应用角度的统计--------
used2:实际使用内存总量。
free2:系统当前实际可用内存,包括未被分配的内存以及分配给buffers 与cached 的内存之和。
可以整理出如下等式:
total1 = used1 + free1
total1 = used2 + free2
used1 = buffers1 + cached1 + used2
free2 = buffers1 + cached1 + free1
上面提到free命令输出的内存状态,可以通过两个角度来查看:一个是从内核的角度来看,一个是从应用层的角度来看的:
1)、从内核的角度来查看内存的状态
就是内核目前可以直接分配到,不需要额外的操作,即为上面free命令输出中第二行Mem项的值,可以看出,此系统物理内存有3894036K,空闲的内存只有420492KB,也就是410MB多一点,我们来做一个这样的计算:
total1 - used1 = free1
3894036 - 3473544 = 420492
其实就是总的物理内存减去已分配的物理内存得到的就是空闲的物理内存大小,注意这里的可用内存值420492K并不包含处于buffers和cached状态的内存大小。如果你认为这个系统空闲内存太小,那你就错了,实际上,内核完全控制着内存的使用情况,Linux会在需要内存的时候,或在系统运行逐步推进时,将buffers和cached状态的内存变为free状态的内存,以供系统使用。
2)、从应用层的角度来看系统内存的使用状态
也就是Linux上运行的应用程序可以使用的内存大小,即free命令第三行(这里说的第几行包含了标题行) -/+ buffers/cached 的输出,可以看到,此系统已经使用的内存才2068224K,而空闲的内存达到1825812K,继续做这样一个计算:
free2 = buffers1 + cached1 + free1
420492+(72972+1332348)=1825812
通过这个等式可知,应用程序可用的物理内存值是Mem项的free值(free1)加上buffers1和cached1值之和,也就是说,这个free值是包括buffers和cached项大小的,对于应用程序来说,buffers/cached占有的内存是可用的,因为buffers/cached是为了提高文件读取的性能,当应用程序需要用到内存的时候,buffers/cached会很快地被回收,以供应用程序使用。
三、linux和windows内存管理的区别
Linux 优先使用物理内存,当物理内存还有空闲时,linux是不会释放内存的,即时占用内存的程序已经被关闭了(这部分内存就用来做缓存了)。也就是说,即时你 有很大的内存,用过一段时间后,也会被占满。这样做的好处是,启动那些刚开启过的程序、或是读取刚存取过得数据会比较快,对于服务器很有好处。
windows则总是给内存留下一定的空闲空间,即时内存有空闲也会让程序使用一些虚拟内存,这样做的好处是,启动新的程序比较快,直接分给它些空闲 内存就可以了,而linux下呢?由于内存经常处于全部被使用的状态,则要先清理出一块内存,再分配给新的程序使用,因此,新程序的启动会慢一些。
四、buffers与cached
1)、异同点
在Linux 操作系统中,当应用程序需要读取文件中的数据时,操作系统先分配一些内存,将数据从磁盘读入到这些内存中,然后再将数据分发给应用程序;当需要往文件中写 数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上。然而,如果有大量数据需要从磁盘读取到内存或者由内存写入磁盘时,系统的读写性 能就变得非常低下,因为无论是从磁盘读数据,还是写数据到磁盘,都是一个很消耗时间和资源的过程,在这种情况下,Linux引入了buffers和 cached机制。
buffers与cached都是内存操作,用来保存系统曾经打开过的文件以及文件属性信息,这样当操作系统需要读取某些文件时,会首先在buffers 与cached内存区查找,如果找到,直接读出传送给应用程序,如果没有找到需要数据,才从磁盘读取,这就是操作系统的缓存机制,通过缓存,大大提高了操 作系统的性能。但buffers与cached缓冲的内容却是不同的。
buffers是用来缓冲块设备做的,它只记录文件系统的元数据(metadata)以及 tracking in-flight pages,而cached是用来给文件做缓冲。更通俗一点说:buffers主要用来存放目录里面有什么内容,文件的属性以及权限等等。而cached直接用来记忆我们打开过的文件和程序。
为了验证我们的结论是否正确,可以通过vi打开一个非常大的文件,看看cached的变化,然后再次vi这个文件,感觉一下两次打开的速度有何异同,是不 是第二次打开的速度明显快于第一次呢?这里提供一个小脚本打印首次及第二次打开一个大文件(catalina.logaa 约2G)耗时及cached/buffers的变化:

#!/bin/bash
sync
sync
echo 3 > /proc/sys/vm/drop_caches
echo -e "----------------------缓存释放后,内存使用情况(KB):----------------------"
free
cached1=`free |grep Mem:|awk '{print $7}'`
buffers1=`free |grep Mem:|awk '{print $6}'`
date1=`date +"%Y%m%d%H%M%S"`
cat catalina.logaa >1
date2=`date +"%Y%m%d%H%M%S"`
echo -e "----------------------首次读取大文件后,内存使用情况(KB):----------------------"
free
cached2=`free |grep Mem:|awk '{print $7}'`
buffers2=`free |grep Mem:|awk '{print $6}'`
#echo $date1
#echo $date2
interval_1=`expr ${date2} - ${date1}`
cached_increment1=`expr ${cached2} - ${cached1}`
buffers_increment1=`expr ${buffers2} - ${buffers1}`
date3=`date +"%Y%m%d%H%M%S"`
cat catalina.logaa >1
date4=`date +"%Y%m%d%H%M%S"`
echo -e "----------------------再次读取大文件后,内存使用情况(KB):----------------------"
free
cached3=`free |grep Mem:|awk '{print $7}'`
buffers3=`free |grep Mem:|awk '{print $6}'`
#echo $date3
#echo $date4
interval_2=`expr ${date4} - ${date3}`
cached_increment2=`expr ${cached3} - ${cached2}`
buffers_increment2=`expr ${buffers3} - ${buffers2}`
echo -e "----------------------统计汇总数据如下:----------------------"
echo -e "首次读取大文件,cached增量:${cached_increment1},单位:KB"
echo -e "首次读取大文件,buffers增量:${buffers_increment1},单位:KB"
echo -e "首次读取大文件,耗时:${interval_1},单位:s \n"
echo -e "再次读取大文件,cached增量:${cached_increment2},单位:KB"
echo -e "再次读取大文件,buffers增量:${buffers_increment2},单位:KB"
echo -e "再次读取大文件,耗时:${interval_2},单位:s"
执行结果如下(由于打印出来的free结果跟参数赋值时用的free命令之间有时间间隔,计算起来可能会略有不同):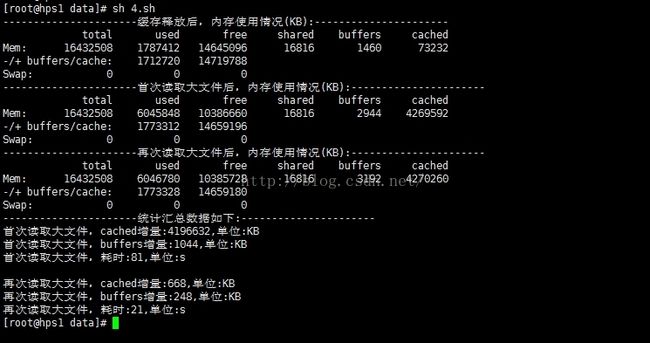
接着执行下面的命令:find /* -name *.conf ,看 看buffers的值是否变化,然后重复执行find命令,看看两次显示速度有何不同。如下脚本(需要注意使用bc计算浮点型数据时需要安装相应软件,我 的系统是centos7.0,内核4.3.3的版本,安装的是bc-1.06.95-13.el7.x86_64服务):
#!/bin/bash
sync
sync
echo 3 > /proc/sys/vm/drop_caches
echo -e "----------------------缓存释放后,内存使用情况(KB):----------------------"
free
cached1=`free |grep Mem:|awk '{print $7}'`
buffers1=`free |grep Mem:|awk '{print $6}'`
date1=`date +%s.%N`
find /* -name *.conf >2
date2=`date +%s.%N`
echo -e "----------------------首次查询后,内存使用情况(KB):----------------------"
free
cached2=`free |grep Mem:|awk '{print $7}'`
buffers2=`free |grep Mem:|awk '{print $6}'`
#echo $date1
#echo $date2
interval_1=`echo "scale=3; ${date2} - ${date1}" | bc`
cached_increment1=`expr ${cached2} - ${cached1}`
buffers_increment1=`expr ${buffers2} - ${buffers1}`
date3=`date +%s.%N`
find /* -name *.conf >2
date4=`date +%s.%N`
echo -e "----------------------再次查询后,内存使用情况(KB):----------------------"
free
cached3=`free |grep Mem:|awk '{print $7}'`
buffers3=`free |grep Mem:|awk '{print $6}'`
#echo $date3
#echo $date4
interval_2=`echo "scale=3; ${date4} - ${date3}" | bc`
cached_increment2=`expr ${cached3} - ${cached2}`
buffers_increment2=`expr ${buffers3} - ${buffers2}`
echo -e "----------------------统计汇总数据如下:----------------------"
echo -e "首次查询,cached增量:${cached_increment1},单位:KB"
echo -e "首次查询,buffers增量:${buffers_increment1},单位:KB"
echo -e "首次查询,耗时:${interval_1},单位:s \n"
echo -e "再次查询,cached增量:${cached_increment2},单位:KB"
echo -e "再次查询,buffers增量:${buffers_increment2},单位:KB"
echo -e "再次查询,耗时:${interval_2},单位:s"
结果如下(最后那个应该是0.470702440,使用bc计算的时候那个0被去掉了):
2、内存释放
linux系统中/proc是一个虚拟文件系统,我们可以通过对它的读写操作做为与kernel实体间进行通信的一种手段。也就是说可以通过修改 /proc中的文件,来对当前kernel的行为做出调整。那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存。关于drop_caches,官方给出的说法是:
Writing to this will cause thekernel to drop clean caches, dentries and
inodes from memory, causing thatmemory to become free.
To free pagecache:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries andinodes:
echo 3 > /proc/sys/vm/drop_caches
As this is a non-destructiveoperation and dirty objects are not freeable, the
user should run `sync' first.
http://www.kernel.org/doc/Documentation/sysctl/vm.txt
# cat /proc/sys/vm/drop_caches
0
默认是0,1表示清空页缓存,2表示清空inode和目录树缓存,3清空所有的缓存
[root@hps103 ~]# sync
[root@hps103 ~]# free -m
total used free shared buffers cached
Mem: 499 323 175 0 52 188
-/+ buffers/cache: 82 416
Swap: 2047 0 2047
[root@hps103 ~]# echo 3 > /proc/sys/vm/drop_caches
[root@hps103 ~]# free -m //发现缓存明显减少了
total used free shared buffers cached
Mem: 499 83 415 0 1 17
-/+ buffers/cache: 64 434
Swap: 2047 0 2047
五、总结
Linux操作系统的内存运行原理,很大程度上是根据服务器的需求来设计的,例如系统的缓冲机制会把经常使用到的文件和数据缓存在cached 中,linux总是在力求缓存更多的数据和信息,这样再次需要这些数据时可以直接从内存中取,而不需要有一个漫长的磁盘操作,这种设计思路提高了系统的整 体性能。
主要参考文章:http://www.linuxeye.com/Linux/1932.html
转自:http://blog.csdn.net/huangjin0507/article/details/51178768