redis安装详解及redis的主从复制
redis
redis 是一个高性能的 key-value 数据库。 redis 的出现,很大程度补偿了memcached 这类 keyvalue 存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了 Python,Ruby,Erlang,PHP 客户端,使用很方便。Redis 的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为“半持久化模式”);也可以把每一次数据变化都写入到一个 appendonly file(aof)里面(这称为“全持久化模式”)。
1.安装redis
[root@server1 ~]# tar -zxf redis-4.0.8.tar.gz -C /usr/local/
[root@server1 ~]# cd /usr/local/
[root@server1 local]# cd redis-4.0.8/
[root@server1 redis-4.0.8]# make
Make时出错,由于没安装gcc

在安装gcc后make时又出现错误
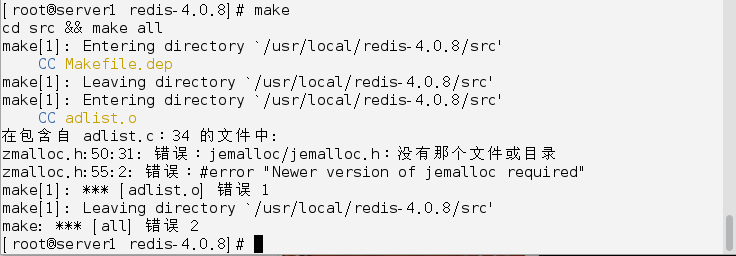
分析原因,可能是编译换境不纯净的原因,删除所有解压后的文件后,重新解压后再make
[root@server1 redis-4.0.8]# cd
[root@server1 ~]# rm -fr /usr/local/redis-4.0.8/
[root@server1 ~]# tar -zxf redis-4.0.8.tar.gz -C /usr/local/
[root@server1 ~]# cd /usr/local/redis-4.0.8/
[root@server1 redis-4.0.8]# make
[root@server1 redis-4.0.8]# make install
2. 配置并启动服务
[root@server1 redis-4.0.8]# cd utils/
[root@server1 utils]# ./install_server.sh 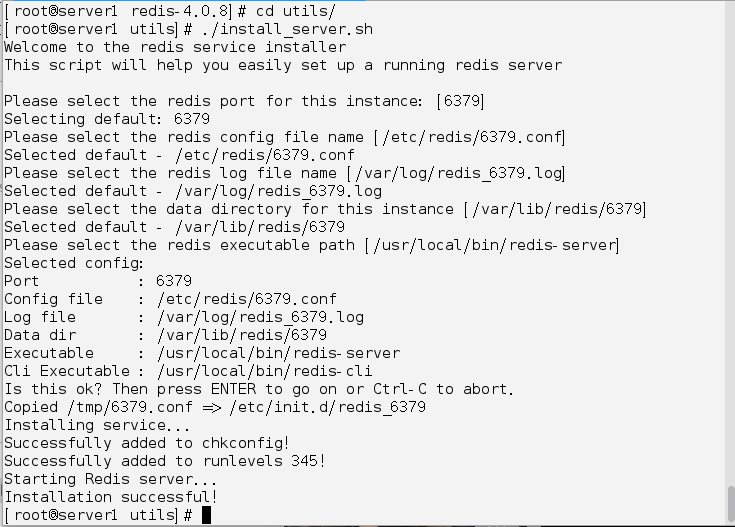
3. Redis.conf 文件详解:
daemonize yes #默认值 no,该参数用于定制 redis 服务是否以守护模式运行。
pidfile /var/run/redis_6379.pid #指定 redis 服务的进程号文件路径.
port 6379 #默认值 6379,指定 redis 服务的端口号。
bind 127.0.0.1 #绑定 ip,默认是本机所有网络接口;
timeout 0 #客户端空闲 n 秒后断开连接;默认是 0 表示不断开。
loglevel notice #设置服务端的日志级别,有下列几种选择:
debug: #记录详细信息,用于开发或调试;
verbose: #提供很多有用的信息,但是又不像 debug 那么详尽,默认就是这一选项;
Notice:#适度提醒,多用于产品环境;
warning:#仅显示重要的警告信息;
logfile stdout #指定日志的输出路径,默认值 stdout,表示输出到屏幕,守护模式时则输出到/dev/null;如果要输出日志到 syslog 中,可以启动 syslog-enabled yes,默认该选项值为no。
syslog-enabled no
databases 16 #指定数据库的数量,默认为 16 个,默认使用的数据库是 DB 0,可以使用 SELECT
save
save 900 1 #每 900 秒(15 分钟)至少一次键值变更时被触发;
save 300 10 #每 300 秒(5 分钟)至少 10 次键值变更时被触发;
save 60 10000 #每 60 秒至少 10000 次键值变更时被触发;
rdbcompression yes #默认值 yes,当 dump 数据库时使用 LZF 压缩字符串对象,如果 CPU 资源比较紧张,可以设置为 no,选择不压缩,但会导致数据库文件变的巨大。
rdbchecksum yes
dbfilename dump.rdb #默认值 dump.rdb,dump 到文件系统中的文件名。
dir /var/lib/redis/6379 #默认值./,即当前目录,dump 出的数据文件的存储路径。
# slaveof
# masterauth
slave-serve-stale-data yes #默认值 yes。当 slave 丢失与 master 端的连接,或者复制仍在处理,那么 slave 会有下列两种表现:
当本参数值为 yes 时,slave 为继续响应客户端请求,尽管数据已不同步甚至没有数据(出现在初次同步的情况下);
当本参数值为 no 时, slave 会返回"SYNC with master in progreee"的错误信息;
slave-read-only yes #默认 salve 是只读模式
# repl-ping-slave-period 10 #默认值 10,指定 slave 定期 ping master 的周期;
# repl-timeout 60 #默认值 60,指定超时时间。注意本参数包括批量传输数据和 ping 响应的时间。
# requirepass foobared #指定一个密码,客户端连接时也需要通过密码才能成功连接;
# rename-command CONFIG
b840fc02d524045429941cc15f59e41cb7be6c52 #重定义命令,例如将CONFIG 命令更名为一个很复杂的名字:
# rename-command CONFIG "" 取消这个命令;
# maxclients 10000 #指定客户端的最大并发连接数,默认是没有限制,直到redis 无法创建新的进程为止,设置该参数值为 0 也表示不限制,如果该参数指定了值,当并发连接达到指定值时,redis 会关闭所有新连接,并返回'maxnumber of clients reached'的错误信息;
# maxmemory
# maxmemory-policy volatile-lru #默认值 volatile-lru,指定清除策略,有下列几种方法:
volatile-lru -> remove the key with an expire set using an LRU algorithmallkeys-lru -> remove any key accordingly to the LRU algorithm
volatile-random -> remove a random key with an expire set
allkeys->random -> remove a random key, any key
volatile-ttl -> remove the key with the nearest expire time (minor TTL)
noeviction -> don't expire at all, just return an error on write operations
# maxmemory-samples 3#默认值 3,LRU 和最小 TTL 策略并非严谨的策略,而是大约估算的方式,因此可以选择取样值以便检查。
ONLY 模式的设置,默认情况下 redis 采用异步方式 dump 数据到磁盘上,极端情况下这可能会导致丢失部分数据(比如服务器突然宕机),如果数据比较重要,不 希望丢失,可以启用直写的模式,这种模式下 redis 会将所有接收到的写操作同步到 appendonly.aof 文件中,该文件会在 redis 服务启动时 在内存中重建所有数据。注意这种模式对性能影响非常之大。
appendonly no #默认值 no,指定是否启用直写模式;
# appendfilename appendonly.aof #直写模式的默认文件名 appendonly.aof
appendfsync:调用 fsync()方式让操作系统写数据到磁盘上,数据同步方式,有下列几种模式:
always:每次都调用,比如安全,但速度最慢;
everysec:每秒同步,这也是默认方式;
no:不调用 fsync,由操作系统决定何时同步,比如快的模式;
no-appendfsync-on-rewrite:默认值 no。当 AOF fsync 策略设置为 always或 everysec,后台保存进程会执行大量的 I/O 操作。某些 linux 配置下 redis 可能会阻塞过多的 fsync()调用。
auto-aof-rewrite-percentage:默认值 100
auto-aof-rewrite-min-size:默认值 64mb
appendfsync everysec
hash-max-zipmap-entries:默认值 512,当某个 map 的元素个数达到最大值,但是其中最大元素的长度没有达到设定阀值时,其 HASH 的编码采用一种特殊的方式(更有效利用内存)。本参数与下面的参数组合使用来设置这两项阀值。设置元素个数;
hash-max-zipmap-value:默认值 64,设置 map 中元素的值的最大长度;
list-max-ziplist-entries:默认值 512,与 hash 类似,满足条件的 list 数组也会采用特殊的方式以节省空间。
list-max-ziplist-value:默认值 64
set-max-intset-entries:默认值 512,当 set 类型中的数据都是数值类型,并且set 中整型元素的数量不超过指定值时,使用特殊的编码方式。
zset-max-ziplist-entries:默认值 128,与 hash 和 list 类似。
zset-max-ziplist-value:默认值 64
activerehashing:默认值 yes,用来控制是否自动重建 hash。Active rehashing每 100 微秒使用 1 微秒 cpu 时间排序,以重组 Redis 的 hash 表。重建是通过一种 lazy 方式,写入 hash 表的操作越多,需要执行 rehashing 的步骤也越多,如果服务器当前空闲,那么 rehashing 操作会一直执行。如果对实时性要求较高,
难以接受 redis 时不时出现的 2 微秒的延迟,则可以设置 activerehashing 为 no,否则建议设置为 yes,以节省内存空间。设置内存分配策略(可选,根据服务器的实际情况进行设置)
/proc/sys/vm/overcommit_memory
可选值:0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2, 表示内核允许分配超过所有物理内存和交换空间总和的内存
值得注意的一点是,redis 在 dump 数据的时候,会 fork 出一个子进程,理论上child 进程所占用的内存和 parent 是一样的,比如 parent 占用的内存为 8G,这个时候也要同样分配 8G 的内存给 child,如果内存无法负担,往往会造成 redis服务器的 down 机或者 IO 负载过高,效率下 降。所以这里比较优化的内存分配策略应该设置为 1 (表示内核允许分配所有的物理内存,而不管当前的内存状态如何)
4. Redis 客户端使用
[root@server1 ~]# redis-cli
127.0.0.1:6379> config get *
1) "dbfilename"
2) "dump.rdb"
3) "requirepass"
4) ""
5) "masterauth"登陆测试安装配置是否成功

redis 主从复制
server2 上按同样步骤安装并启动redis
[root@server2 utils]# vim /etc/redis/6379.conf #添加主机ip 和端口

[root@server2 utils]# /etc/init.d/redis_6379 restart #重启后登陆测试

发现没有数据没有同步过来
[root@server1 ~]# netstat -antlp #主机端查看端口发现 主机 6379 端口现在只对自己开放

[root@server1 ~]# vim /etc/redis/6379.conf #编辑主机配置文件
将 bind 127.0.0.1 改为 bind 0.0.0.0

[root@server1 ~]# /etc/init.d/redis_6379 restart #重启服务
[root@server1 ~]# netstat -antlp #发现此时6379端口已经对所有人开放

然后在从机端查看发现数据已经同步过来

为了确保实验准确,再次在主机端更改数据

发现从机端很快便同步过去

至此,redis的主从复制配置完毕