python自动读取文件代码_详解python脚本自动生成需要文件实例代码
详解python脚本自动生成需要文件实例代码
python脚本自动生成需要文件
在工作中我们经常需要通过一个文件写出另外一个文件,然而既然是对应关系肯定可以总结规律让计算机帮我们完成,今天我们就通过一个通用文件生成的python脚本来实现这个功能,将大家从每日重复的劳动中解放!
定义一个函数
def produceBnf(infilename,outfilename):
List=[]
with open(infilename,'r') as inf:
for line in inf.readlines():
List.append(re.match("正则表达式").group(?))
with open(outfilename,'w') as outf:
i=0
outf.write("文件头");
for command in List:
outf.write(“写入刚刚读取的内容(也可能是某种对应关系)”)
outf.write("写入其他内容")
outf.write("写入文件尾")
差不多,大多数情况下,都是这样的框架,这个函数需要一个输入文件,一个输出文件,一般情况下,我们希望,能够从命令行中将输入文件参数传入,然后在本目录下生成输出文件
获得输入输出路径
infile=sys.argv[1]
produceBnf(infile,os.path.join(os.path.dirname(infile),"输出文件的名字"));
ok,搞定,然后在命令行中我们执行这个python脚本然后加个参数就完工了。
脚本就是用来帮助我们简化重复的工作,让我们去做更有意义,更加需要思考的事情,所以希望大家以后多用脚本来简化自己的重复工作。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
时间: 2017-02-02
我在工作的时候,在测试环境下使用的数据库跟生产环境的数据库不一致,当我们的测试环境下的数据库完成测试准备更新到生产环境上的数据库时候,需要准备更新脚本,真是一不小心没记下来就会忘了改了哪里,哪里添加了什么,这个真是非常让人头疼.因此我就试着用Python来实现自动的生成更新脚本,以免我这烂记性,记不住事. 主要操作如下: 1.在原先 basedao.py 中添加如下方法,这样旧能很方便的获取数据库的数据,为测试数据库和生产数据库做对比打下了基础. def select_database_stru

这篇主要记录一下如何实现对数据库的并行运算来节省代码运行时间.语言是Python,其他语言思路一样. 前言 一共23w条数据,是之前通过自然语言分析处理过的数据,附一张截图: 要实现对news主体的读取,并且找到其中含有的股票名称,只要发现,就将这支股票和对应的日期.score写入数据库. 显然,几十万条数据要是一条条读写,然后在本机上操作,耗时太久,可行性极低.所以,如何有效并行的读取内容,并且进行操作,最后再写入数据库呢? 并行读取和写入 并行读取:创建N*max_process个进程,对数
实例如下: # 环境: python3.x def getExportDbSql(db, index): # 获取导出一个数据库实例的sql语句 sql = 'mysqldump -u%s -p%s -h%s -P%d --default-character-set=utf8 --databases mu_ins_s%s > %s.s%d.mu_ins_%d.sql' %(db['user'], db['pwd'], db['host'], db['port'], index, db['serv
在一个Web App中,所有数据,包括用户信息.发布的日志.评论等,都存储在数据库中.在awesome-python-app中,我们选择MySQL作为数据库. Web App里面有很多地方都要访问数据库.访问数据库需要创建数据库连接.游标对象,然后执行SQL语句,最后处理异常,清理资源.这些访问数据库的代码如果分散到各个函数中,势必无法维护,也不利于代码复用. 此外,在一个Web App中,有多个用户会同时访问,系统以多进程或多线程模式来处理每个用户的请求.假设以多线程为例,每个线程在访问数据库
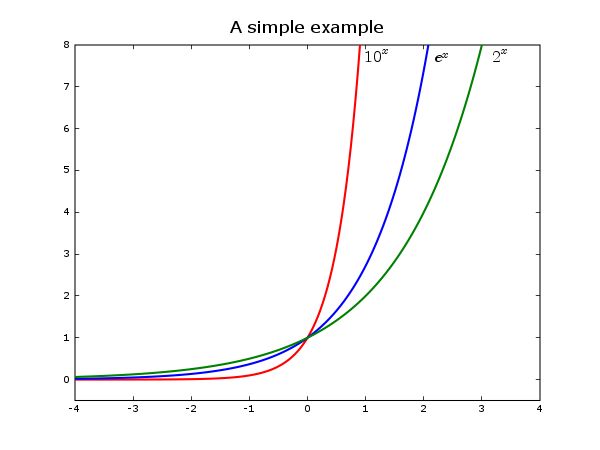
1 关于 Matplotlib 模块 Matplotlib 是一个由 John Hunter 等开发的,用以绘制二维图形的 Python 模块.它利用了 Python 下的数值计算模块 Numeric 及 Numarray,克隆了许多 Matlab 中的函数, 用以帮助用户轻松地获得高质量的二维图形.Matplotlib 可以绘制多种形式的图形包括普通的线图,直方图,饼图,散点图以及误差线图等:可以比较方便的定制图形的各种属性比如图线的类型,颜色,粗细,字体的大小等:它能够很好地支持一部分 Te
在Python中,安装第三方模块,是通过setuptools这个工具完成的.Python有两个封装了setuptools的包管理工具:easy_install和pip.目前官方推荐使用pip. 如果你正在使用Mac或Linux,安装pip本身这个步骤就可以跳过了. 如果你正在使用Windows,请参考安装Python一节的内容,确保安装时勾选了pip和Add python.exe to Path. 在命令提示符窗口下尝试运行pip,如果Windows提示未找到命令,可以重新运行安装程序添加pip
python简述: Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.自从20世纪90年代初Python语言诞生至今,它逐渐被广泛应用于处理系统管理任务和Web编程.Python[1]已经成为最受欢迎的程序设计语言之一.2011年1月,它被TIOBE编程语言排行榜评为2010年度语言.自从2004年以后,python的使用率是呈线性增长. tkinter模块介绍 tkinter模块("Tk 接口")是Python的标准Tk GUI工具包的接口.Tk和Tkinter可以
GIL 在Python中,由于历史原因(GIL),使得Python中多线程的效果非常不理想.GIL使得任何时刻Python只能利用一个CPU核,并且它的调度算法简单粗暴:多线程中,让每个线程运行一段时间t,然后强行挂起该线程,继而去运行其他线程,如此周而复始,直到所有线程结束. 这使得无法有效利用计算机系统中的"局部性",频繁的线程切换也对缓存不是很友好,造成资源的浪费. 据说Python官方曾经实现了一个去除GIL的Python解释器,但是其效果还不如有GIL的解释器,遂放弃.后来P
hashlib hashlib主要提供字符加密功能,将md5和sha模块整合到了一起,支持md5,sha1, sha224, sha256, sha384, sha512等算法 hashlib模块 #哈希算法也叫摘要算法,相同的数据始终得到相同的输出,不同的数据得到不同的输出. #(1)哈希将不可变的任意长度的数据,变成具有固定长度的唯一值 #(2)字典的键值对映射关系是通过哈希计算的,哈希存储的数据是散列(无序) # 应用场景:在需要效验功能时使用 用户密码的 => 加密,解密 相关效验的
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息: print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据:logging则可以由开发者决定将信息输出到什么地方,以及怎么输出: Logger从来不直接实例化,经常通过logging模块级方法(Modu
Socket的英文原义是"孔"或"插座".作为BSD UNIX的进程通信机制,取后一种意思.通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄.在Internet上的主机一般运行了多个服务软件,同时提供几种服务.每种服务都打开一个Socket,并绑定到一个端口上,不同的端口对应于不同的服务.Socket正如其英文原意那样,像一个多孔插座.一台主机犹如布满各种插座的房间,每个插座有一个编号,有的插座提供220伏交流电, 有的提供110
简介 Python中的select模块专注于I/O多路复用,提供了select poll epoll三个方法(其中后两个在Linux中可用,windows仅支持select),另外也提供了kqueue方法(freeBSD系统) select方法 进程指定内核监听哪些文件描述符(最多监听1024个fd)的哪些事件,当没有文件描述符事件发生时,进程被阻塞:当一个或者多个文件描述符事件发生时,进程被唤醒. 当我们调用select()时: 1.上下文切换转换为内核态 2.将fd从用户空间复制到内核空
SQLite是一种嵌入式数据库,它的数据库就是一个文件.由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成. Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用. 在使用SQLite前,我们先要搞清楚几个概念: 表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,比如学生的表,班级的表,学校的表,等等.表和表之间通过外键关联. 要操作关系数据库,首先需要连