Kubernetes服务发现之Service
Kubernetes在设计之初就充分考虑了针对容器的服务发现与负载均衡机制,提供了Service资源——一种将运行在一组Pod上的应用公开为网络服务的抽象方法。使用Kubernetes,我们无需修改应用程序即可使用不熟悉的服务发现机制。Kubernetes为Pod提供自己的IP地址和一组Pod的单个DNS名称,并且可以在它们之间进行负载平衡。
本文主要参考官方文档对Kubernetes的Service进行一个总结。
一、环境信息
本文所使用的环境如下:
- 操作系统:CentOS Linux release 8.2.2004
- Docker:19.03.12
- kubernetes:v1.18.5
二、为什么要用Service
Kubernetes的Pod是有生命周期的。他们可以被创建,销毁不会再启动。 如果使用Deployment来运行应用程序,则它可以动态创建和销毁Pod。每个Pod都有自己的IP地址,但是在Deployment中,在同一时刻运行的Pod集合可能与稍后运行该应用程序的Pod集合不同。这导致了一个问题:如果一组Pod(称为“后端”)为群集内的其他Pod(称为“前端”)提供功能,那么前端如何找出并跟踪要连接的IP地址,以便前端可以使用工作量的后端部分?Service的出现就是为了解决这些问题。例如下图:

Nginx Pod作为客户端要访问Tomcat Pod中的应用,但是Pod删除重建或更新之后,Pod对象的IP地址等都会发生新的变化。IP的变动或规模的缩减会导致客户端访问错误。而Pod规模的扩容又会使得客户端无法有效的使用新增的Pod对象,从而影响达成规模扩展之目的。为此,Kubernetes特地设计了Service来解决此类问题。
三、Service的定义
Kubernetes的Service 定义了这样一种抽象:逻辑上的一组Pod,一种可以访问它们的策略——通常称为微服务。 这一组Pod能够被Service访问到,通常是通过selector实现的。例如下图:
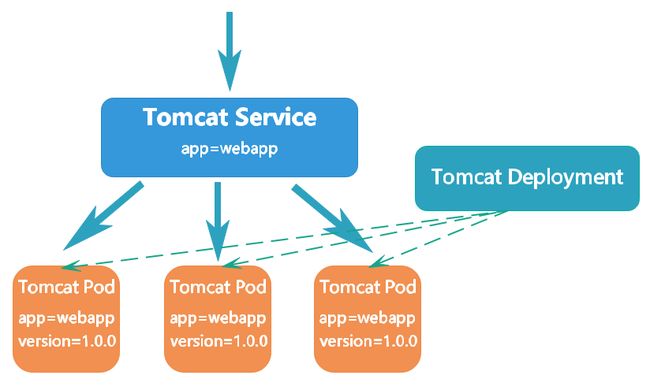
图中有名为Tomcat的Deployment创建Tomcat的Pod并维持3个副本。一个名为Tomcat的Service通过标签app=webapp来选择满足条件的Pod,这一组Pod能够被该Service访问到,只要Pod的标签中包含app=webapp即满足条件。客户端通过该Service即可访问到Tomcat的Pod,客户端不需要关心它们调用了Tomcat的哪个Pod副本。 尽管组成这一组Tomcat的Pod实际上可能会发生变化,客户端不应该也没必要知道,而且也不需要跟踪这一组Pod的状态。 Service 定义的抽象能够解耦这种关联。
四、创建Service
一个Service在Kubernetes中是一个REST对象,和Pod类似。像所有的REST对象一样,Service定义可以基于POST方式,请求API server创建新的实例。下面创建myapp-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
labels:
app: MyApp
spec:
replicas: 3
selector:
matchLabels:
app: MyApp
template:
metadata:
labels:
app: MyApp
spec:
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
创建名为myapp-deployment的Deployment:
kubectl apply -f myapp-deployment.yaml
Deployment会控制RS创建Pod并维持至3个副本数,这组Pod中的nginx容器需要监听80端口,同时Pod还被打上app=MyApp标签。查看所有Pod:
![]()
创建myapp-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 88
targetPort: 80
需要注意的是,
Service能够将一个接收port映射到任意的targetPort。默认情况下targetPort将被设置为与port字段相同的值。
创建名为myapp-service的Service:
kubectl apply -f myapp-service.yaml
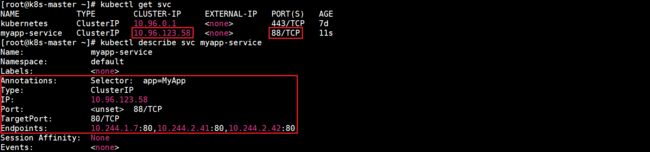
该配置创建一个名称为myapp-service的 Service 对象,它会将请求(clusterIP:port)代理到使用TCP的端口80(targetPort)并且具有标签"app=MyApp"的Pod上。Kubernetes为该服务分配一个IP地址,称为 “cluster IP” ,该IP地址由服务代理使用。服务选择器的控制器不断扫描与其选择器匹配的 Pod,然后将所有更新发布到也被称为myapp-service的Endpoint对象。查看所有Service和myapp-service详细信息:
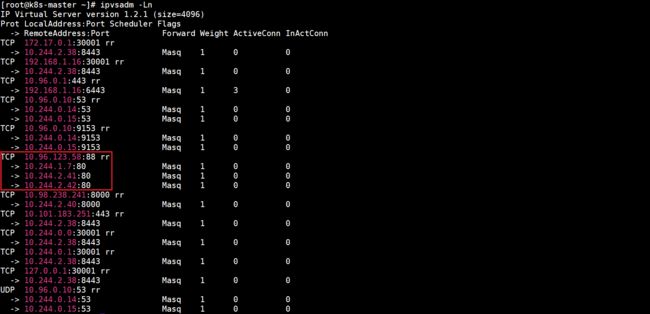
由于本文示例的k8s集群使用的IPVS模式,查看当前虚拟服务列表可知Service通过IPVS规则实现代理和负载均衡:
服务的默认协议是TCP,还可以使用任何其他受支持的协议。由于许多服务需要公开多个端口,因此Kubernetes在服务对象上支持多个端口定义。每个端口定义可以具有相同的protocol,也可以具有不同的协议。
1.没有selector的Service
Service最常见的是抽象化对Kubernetes的Pod的访问,但是它们也可以抽象化其他种类的后端。例如:
- 希望在生产环境中使用外部的数据库集群,但测试环境使用自己的数据库。
- 希望服务指向另一个命名空间(Namespace)中或其它集群中的服务。
- 正在将工作负载迁移到Kubernetes。在评估该方法时,仅在Kubernetes中运行一部分后端。
在上面这些场景中可以定义没有selector的Service。例如,创建myapp-without-selector-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: myapp-without-selector-service
spec:
ports:
- protocol: TCP
port: 88
targetPort: 80
创建myapp-without-selector-service:
kubectl apply -f myapp-without-selector-service.yaml
查看所有Service和myapp-without-selector-service详细信息:

查看当前虚拟服务列表:

根据以上信息可知由于该Service没有selector,因此不会自动创建相应的Endpoint对象。 可以通过手动添加Endpoint对象,将服务手动映射到运行该服务的网络地址和端口。创建myapp-without-selector-service-endpoints.yaml:
apiVersion: v1
kind: Endpoints
metadata:
name: myapp-without-selector-service
subsets:
- addresses:
- ip: 10.244.1.7
- ip: 10.244.2.41
- ip: 10.244.2.42
ports:
- port: 80
通过以上配置创建Endpoint对象,创建Endpoint对象会添加到myapp-without-selector-service中:
kubectl apply -f myapp-without-selector-service-endpoints.yaml
查看所有Service和myapp-without-selector-service详细信息:
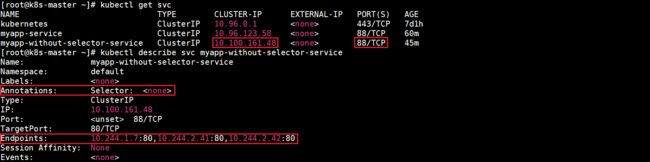
查看当前虚拟服务列表:

根据以上信息可知Endpoint对象已成功创建并添加到myapp-without-selector-service中。
注意:
Endpoint的IP地址不能是loopback(IPv4的127.0.0.0/8,IPv6的::1/128),或link-local(IPv4的169.254.0.0/16和224.0.0.0/24,IPv6的fe80::/64)。Endpoint的IP地址不能是其他Kubernetes的Service的ClusterIP,因为kube-proxy不支持将虚拟IP作为目标。
访问没有selector的Service,与有selector的Service的原理相同。请求将被路由到上面的YAML中用户定义的10.244.1.7:80,10.244.2.41:80,10.244.2.42:80 (TCP)这个Endpoint。ExternalName类型的Service是Service的特例,它没有selector,也没有使用DNS名称代替。
2.Endpoint Slice
Endpoint Slice是一种API资源,可以为Endpoint提供更可扩展的替代方案。尽管从概念上讲与Endpoint非常相似,但Endpoint Slice允许跨多个资源分布网络端点。默认情况下,一旦到达100个Endpoint,该Endpoint Slice将被视为已满,届时将创建其他Endpoint Slice来存储任何其他Endpoint。Endpoint Slice提供了附加的属性和功能。
3.多端口Service
对于某些服务,需要暴露多个端口。Kubernetes允许在Service对象上配置多个端口定义。为服务使用多个端口时,必须提供所有端口名称,以使它们无歧义。下面创建myapp-multi-port-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: myapp-multi-port-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
创建myapp-multi-port-service:
kubectl apply -f myapp-multi-port-service.yaml
查看所有Service和myapp-multi-port-service详细信息:
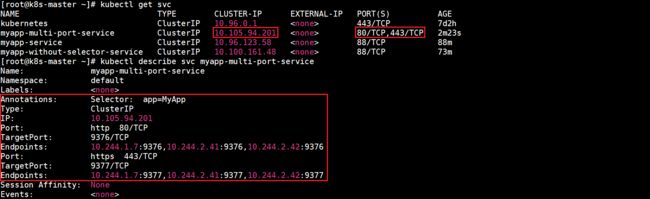
查看当前虚拟服务列表(只截取了部分内容):

注意:与一般的Kubernetes名称一样,端口名称只能包含小写字母数字字符和
-。端口名称还必须以字母数字字符开头和结尾。例如,名称123-abc和web有效,但是123_abc和-web无效。
4.指定clusterIP地址
在Service创建的请求中,可以通过spec.clusterIP字段来指定自己的clusterIP地址。 比如,希望替换一个已经已存在的DNS条目,或者遗留系统已经配置了一个固定的 IP 且很难重新配置。自己指定的IP地址必须合法,并且这个IP地址在service-cluster-ip-range CIDR范围内,这对API Server来说是通过一个标识来指定的。如果IP地址不合法,API Server会返回HTTP状态码422,表示值不合法。下面创建myapp-specify-cluster-ip-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: myapp-specify-cluster-ip-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 88
targetPort: 80
clusterIP: 10.96.59.136
创建myapp-specify-cluster-ip-service:
kubectl apply -f myapp-specify-cluster-ip-service.yaml
查看所有Service和myapp-specify-cluster-ip-service详细信息:

查看当前虚拟服务列表(只截取了部分内容):

五、VIP和Service代理
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。
1.不使用DNS轮询的原因
- DNS实现的历史由来已久,它不遵守记录TTL,并且在名称查找结果到期后对其进行缓存。
- 有些应用程序仅执行一次DNS查找,并无限期地缓存结果。
- 即使应用和库进行了适当的重新解析,DNS记录上的TTL值低或为零也可能会给DNS带来高负载,从而使管理变得困难。
2.userspace代理模式
Kubernetes v1.0开始至Kubernetes v1.1(包括v1.1),默认使用userspace模式。
这种模式,kube-proxy会监视Kubernetes控制节点对Service和Endpoint对象的添加和移除。对每个Service,它会在在本地Node上随机打开一个端口(代理端口)。任何连接到代理端口的请求,都会被代理到Service后端中的某个Pod上面,至于被代理到当前Service后端的哪个Pod对象取决于当前Service的调度方式,是kube-proxy基于SessionAffinity确定的。默认的调度策略是kube-proxy在userspace模式下通过轮询(round-robin)算法来选择后端的Pod。最后,它会配置iptables规则,捕获到达该Service的clusterIP和port的请求并重定向到代理端口,代理端口再代理请求到后端的Pod。
userspace代理的过程为:请求到达service后,其被转发至内核空间,经由套接字送往用户空间的kube-proxy,然后再由它送回内核空间,并调度至后端Pod。传输效率较低。

3.iptables代理模式
Kubernetes v1.1添加了iptables代理模式,从Kubernetes v1.2开始,默认使用iptables模式。
这种模式,kube-proxy会监视Kubernetes控制节点对Service和Endpoint对象的添加和移除。对每个Service,它会配置iptables规则,从而捕获到达该Service 的clusterIP和port的请求并将请求重定向到Service的后端中的某个Pod上面。对于每个Endpoint对象,它也会配置选择一个后端Pod的iptables规则。默认的调度策略是kube-proxy在iptables模式下通过随机(random)算法来选择一个后端的Pod。
iptables代理过程为:请求到达service后,其被相关service上的iptables规则进行调度和目标地址转换后再转发至集群内的Pod对象之上。使用iptables处理流量具有较低的系统开销,因为流量由Linux netfilter处理,而无需在用户空间和内核空间之间切换。
如果kube-proxy在iptables模式下运行,并且所选的第一个Pod没有响应,则连接失败。而userspace模式在这种情况下,kube-proxy将检测到与第一个Pod的连接已失败,并会自动使用后端的其他Pod重试。可以使用Pod的readiness探测器验证后端Pod可以正常工作,以便iptables模式下的kube-proxy仅看到测试正常的后端Pod。这样可以避免将流量通过kube-proxy发送到已知已失败的Pod上。

4.IPVS代理模式
Kubernetes v1.8添加了ipvs代理模式。
在ipvs模式下,kube-proxy监视Kubernetes的Service和Endpoint,调用netlink接口相应地创建IPVS规则,并定期将IPVS规则与Kubernetes的Service和Endpoint同步。该控制循环可确保IPVS状态与所需状态匹配。访问服务时,IPVS将流量定向到其中一个后端Pod。
IPVS代理模式基于类似于iptables模式的netfilter挂钩函数,但使用哈希表作为基础数据结构并在内核空间中工作。这意味着,与iptables模式下的kube-proxy相比,IPVS模式下的kube-proxy重定向通信的延迟更短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS模式还支持更高的网络流量吞吐量。IPVS还为负载均衡提供了更多选项。这些选项如下:
rr:轮询(round-robin)lc:最小连接数(least connection)dh:目标哈希(destination hashing)sh:源哈希(source hashing)sed:最短期望延迟(shortest expected delay)nq:永不排队(never queue)
注意:要在IPVS模式下运行kube-proxy,必须在启动kube-proxy之前使IPVS Linux在节点上可用。当 kube-proxy以IPVS代理模式启动时,它将验证IPVS内核模块是否可用。如果未检测到IPVS内核模块,则kube-proxy将退回到以iptables代理模式运行。

如果要确保每次都将来自特定客户端的连接传递到同一Pod,可以通过将service.spec.sessionAffinity设置为"ClientIP",默认值是 “None”,来基于客户端的IP地址选择会话关联。可以通过service.spec.sessionAffinityConfig.clientIP.timeoutSeconds来设置最大会话停留时间,默认值为10800秒,即3小时。
5.避免冲突
为了使用户能够为他们的Service选择一个端口号,必须确保不能有2个Service发生冲突。Kubernetes通过为每个Service分配它们自己的 IP地址来实现。为了保证每个Service被分配到一个唯一的IP,需要一个内部的分配器能够原子地更新etcd中的一个全局分配映射表,这个更新操作要先于创建每一个Service。为了使Service能够获取到IP,这个映射表对象必须在注册中心存在,否则Service创建将会失败并显示一条指示一个IP不能被分配的消息。
在控制平面中,一个后台Controller负责创建映射表(需要支持从使用了内存锁的Kubernetes的旧版本迁移过来)。同时Kubernetes会通过控制器检查不合理的分配(如管理员干预导致的)以及清理已被分配但不再被任何Service使用的IP地址。
6.Service IP地址
Service的IP不像Pod的IP地址实际路由到一个固定的目的地,它实际上不能通过单个主机来进行应答。所以使用iptables来定义一个虚拟IP地址(VIP),它可以根据需要透明地进行重定向。当客户端连接到VIP时,它们的流量会自动地传输到一个合适的Endpoint。Service的环境变量和DNS实际上会根据Service的虚拟IP地址和端口来进行填充。kube-proxy支持三种代理模式各自的操作略有不同。
userspace模式,创建Service时,Kubernetes master会给它分配一个虚拟IP地址,该Service会被集群中所有的kube-proxy实例观察到。当代理看到一个新的Service时,它会打开一个新的随机端口(代理端口),建立一个从该虚拟IP地址重定向到新端口的iptables,并开始接收请求连接。当一个客户端连接到一个Service的虚拟IP地址时,iptables规则开始起作用,它会重定向该数据包到Service的代理端口。Service代理选择一个后端的Pod并将客户端的流量代理到该后端Pod上。这意味着Service的所有者能够选择他们想使用的任何端口而不会发生冲突。客户端可以简单地连接到一个IP和端口,而不需要知道实际访问了哪些Pod。
iptables模式,创建Service时,Kubernetes控制面板会给它分配一个虚拟IP地址,该Service会被集群中所有的kube-proxy实例观察到。当代理看到一个新的Service时, 它会配置一系列从虚拟IP地址重定向per-Service规则的iptables规则。该per-Service规则链接到重定向(使用目标NAT)到后端的Pod的per-Endpoint规则。当一个客户端连接到一个Service的虚拟IP地址时,iptables规则开始起作用。一个后端Pod会被选择(或者根据会话亲和性或者随机)并且数据包被重定向到该后端Pod。与userspace代理不同,数据包从来不会拷贝到用户空间,kube-proxy不是必须为该虚拟IP工作而运行,并且节点会看到来自未更改的客户端IP地址的流量。当流量通过节点端口或负载均衡器进入时,尽管在这种情况下,客户端IP发生更改,也会执行相同的基本流程。
IPVS模式,专为负载均衡设计,并基于内核中的哈希表。在大规模集群中,iptables操作会显着降低速度时。可以通过基于IPVS的kube-proxy在大量服务中实现性能一致性。 同时,基于IPVS的kube-proxy具有更复杂的负载均衡算法。
六、服务发现
Kubernetes支持2种基本的服务发现模式——环境变量和DNS。
1.环境变量
当Pod运行在 Node 上,kubelet会为每个活跃的Service添加一组环境变量。它同时支持Docker links兼容变量、简单的{SVCNAME}_SERVICE_HOST和{SVCNAME}_SERVICE_PORT变量,这里Service的名称需大写,横线被转换成下划线。举个例子,一个名为redis-master的Service暴露了TCP端口6379,同时给它分配了Cluster IP地址10.0.0.11,这个Service生成了如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
注意:当有需要访问服务的Pod时,并且正在使用环境变量方法将端口和群集IP发布到客户端Pod时,必须在客户端Pod出现之前创建服务。 否则,这些客户端Pod将不会设定其环境变量。如果仅使用DNS查找服务的群集IP,则无需担心此设定问题。
2.DNS
可以使用附加组件为Kubernetes集群设置DNS服务。支持群集的DNS服务器(例如CoreDNS)监视Kubernetes API中的新服务,并为每个服务创建一组DNS记录。如果在整个群集中都启用了DNS,则所有Pod都应该能够通过其DNS名称自动解析服务。例如,如果在 Kubernetes命名空间my-ns中有一个名为my-service"的服务,则控制平面和DNS服务共同为my-service.my-ns创建DNS记录。my-ns命名空间中的Pod应该能够通过简单地对my-service进行名称查找来找到它( my-service.my-ns 也可以)。其他命名空间中的Pod必须将名称限定为my-service.my-ns。这些名称将解析为为服务分配的群集IP。
Kubernetes还支持命名端口的DNS SRV(服务)记录。如果my-service.my-ns服务具有名为http的端口,且协议设置为TCP,则可以对_http._tcp.my-service.my-ns执行DNS SRV查询查询以发现该端口号,http以及IP地址。Kubernetes DNS服务器是唯一的一种能够访问ExternalName类型的Service的方式。
七、发布Service和Service类型
对于应用的某些部分,比如前端,可能希望暴露一个服务到Kubernetes集群外部的一个外部IP地址上。Kubernetes的ServiceTypes允许指定Service的类型,Service有ClusterIP、NodePort、LoadBalancer和ExternalName这四种类型,默认是ClusterIP类型。也可以使用Ingress来暴露自己的服务。Ingress不是服务类型,但它充当集群的入口点。它可以将路由规则整合到一个资源中,因为它可以在同一IP地址下暴露多个服务。
1.ClusterIP类型
通过集群的内部IP暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。

下面创建mynginx-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mynginx-deployment
namespace: default
labels:
app: MyNginx
version: v1
spec:
replicas: 3
selector:
matchLabels:
app: MyNginx
version: v1
template:
metadata:
labels:
app: MyNginx
version: v1
env: test
spec:
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
创建Deployment以及查看Pod信息:

修改3个pod的index.html内容为各自的Pod名称:

创建mynginx-service-clusterip.yaml:
apiVersion: v1
kind: Service
metadata:
name: mynginx-service-clusterip
namespace: default
spec:
type: ClusterIP
selector:
app: MyNginx
version: v1
ports:
- name: http
port: 88
targetPort: 80
创建mynginx-service-clusterip,查看所有Service和mynginx-service-clusterip详细信息:

查看当前虚拟服务列表:

访问mynginx-service-clusterip,可知负载均衡策略为轮询:

也可以通过域名访问,格式为bind-utils包:
yum install -y bind-utils
查询DNS记录,其中的10.244.0.16是其中一个CoreDNS的IP:

对该域名进行解析:

2.NodePort类型
通过每个Node上的IP和静态端口(NodePort)暴露服务。NodePort服务会路由到ClusterIP服务,这个ClusterIP服务会自动创建。通过请求NodePort服务。Service通过spec.clusterIp:spec.ports[*].port而对外可见。

如果将type字段设置为NodePort,则Kubernetes控制平面将在--service-node-port-range指定的范围内分配端口,默认值:30000-32767。每个节点将那个端口(每个节点上端口号相同)代理到服务中。通过.spec.ports[*].nodePort字段指定要分配的NodePort端口,需要注意可能发生的端口冲突且必须使用配置用于NodePort的范围内的有效的端口号。如果想指定特定的IP代理端口,可以将kube-proxy中的--nodeport-addresses设置为特定的IP块。该标志采用逗号分隔的IP块列表(例如10.0.0.0/8,192.0.2.0/25)来指定kube-proxy认为是此节点本地的IP地址范围。下面创建mynginx-service-nodeport.yaml:
apiVersion: v1
kind: Service
metadata:
name: mynginx-service-nodeport
namespace: default
spec:
type: NodePort
selector:
app: MyNginx
version: v1
ports:
- name: http
port: 88
targetPort: 80
nodePort: 30008
创建mynginx-service-nodeport,查看所有Service和mynginx-service-nodeport详细信息:
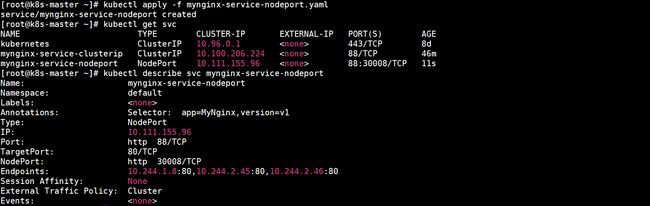
在两个节点上分别查看当前虚拟服务列表:


通过外部访问mynginx-service-nodeport,这里在Windows上访问:

3.LoadBalancer类型
使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到NodePort服务和ClusterIP服务。

如果将type字段设置为LoadBalancer,可以使用支持外部负载均衡器的云提供商的服务,将为Service提供负载均衡器。负载均衡器是异步创建的,被提供的负载均衡器的信息将会通过Service的status.loadBalancer字段发布出去。
apiVersion: v1
kind: Service
metadata:
name: mynginx-service-loadbalancer
namespace: default
spec:
selector:
app: MyNginx
version: v1
ports:
- name: http
port: 88
targetPort: 80
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
某些云提供商允许设置loadBalancerIP,将根据用户设置的loadBalancerIP来创建负载均衡器,如果没有设置loadBalancerIP,将会给负载均衡器指派一个临时IP。如果设置了loadBalancerIP,但云提供商并不支持这种特性,那么设置的loadBalancerIP值将会被忽略。由于云提供商的负载均衡服务都是第三方付费服务,这里就不演示了,更多LoadBalancer的内容可以参考官方文档。
4.ExternalName类型
通过返回CNAME和它的值,可以将服务映射到externalName字段的内容。例如,foo.bar.example.com。没有任何类型代理被创建。需要CoreDNS 1.7或更高版本才能使用ExternalName类型。
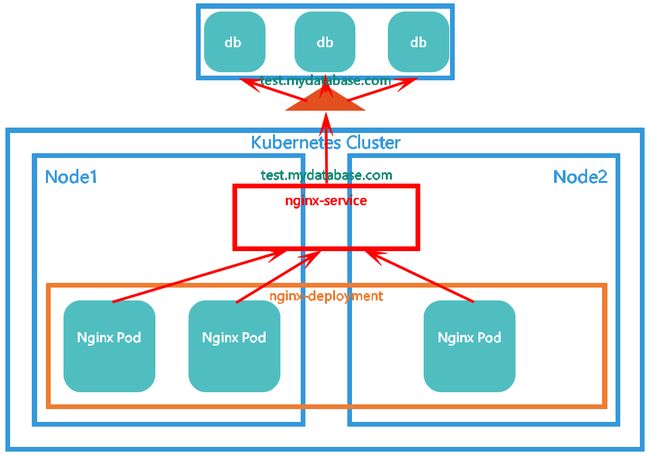
ExternalName服务将服务映射到DNS名称,对于运行在集群外部的服务,ExternalName服务通过返回外部服务的别名的方式来提供服务,可以通过spec.externalName参数指定这些外部服务。下面创建mydb-service-externalname.yaml:
apiVersion: v1
kind: Service
metadata:
name: mydb-service-externalname
namespace: default
spec:
type: ExternalName
externalName: test.mydatabase.com
该Service将default名称空间中的mydb-service-externalname服务映射到test.mydatabase.com,当查找主机mydb-service-externalname.default.svc.cluster.local时,群集DNS服务返回CNAME记录,其值为test.mydatabase.com。访问mydb-service-externalname的方式与其他服务的方式相同,但主要区别在于重定向发生在DNS级别,而不是通过代理或转发。如果以后要将外部服务移到群集内部,则可以启动其Pod并添加适当的selector或endpoint以及更改服务的类型。下面创建mydb-service-externalname,查看所有Service和mydb-service-externalname详细信息:

查询DNS记录,这里test.mydatabase.com是假设的所以找不到主机:

对该域名进行解析:

5.外部IP
如果外部的IP路由到集群中一个或多个Node上,Kubernetes的Service会被暴露给这些externalIPs。通过外部IP(作为目的IP地址)进入到集群,到达Service的端口上的流量,将会被路由到Service的Endpoint上。externalIPs不会被Kubernetes管理,它属于集群管理员的职责范畴。在Service的spec中,externalIPs可以同任意的ServiceType来一起指定。 例如以下示例,mynginx-service-externalips可以在80.11.12.10:80(externalIP:port)上被客户端访问:
apiVersion: v1
kind: Service
metadata:
name: mynginx-service-externalips
namespace: default
spec:
selector:
app: MyNginx
version: v1
ports:
- name: http
port: 88
targetPort: 80
externalIPs:
- 80.11.12.10
八、Headless Service
有时不需要或不想要负载均衡以及单独的Service IP,可以通过指定ClusterIP(spec.clusterIP)的值为"None"来创建Headless Service。可以使用headless Service与其他服务发现机制进行对接,而不必与Kubernetes的实现捆绑在一起。对这类headless Service 并不会分配Cluster IP,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。DNS如何实现自动配置,依赖于Service是否定义了selector。
1.配置Selector
对定义了selector的Headless Service,Endpoint控制器在API中创建了Endpoints记录,并且修改DNS配置返回A记录(地址),通过这个地址直接到达Service的后端Pod上。下面创建mynginx-headless-service-with-selector.yaml:
apiVersion: v1
kind: Service
metadata:
name: mynginx-headless-service-with-selector
namespace: default
spec:
clusterIP: "None"
selector:
app: MyNginx
version: v1
ports:
- name: http
port: 88
targetPort: 80
创建mynginx-headless-service-with-selector,查看所有Service和mynginx-headless-service-with-selector详细信息:

查询DNS记录:

对该域名进行解析:

2.不配置Selector
对没有定义selector的Headless Service,Endpoint控制器不会创建Endpoints记录。Dns配置分为两种情形,对ExternalName类型的服务创建CNAME记录,见上文ExternalName类型部分内容。对其他三种类型,则为那些与当前Service共享名称的所有Endpoints对象创建一条记录。下面创建mynginx-headless-service-no-selector.yaml:
apiVersion: v1
kind: Service
metadata:
name: mynginx-headless-service-no-selector
namespace: default
spec:
clusterIP: "None"
ports:
- name: http
port: 88
targetPort: 80
创建mynginx-headless-service-no-selector,查看所有Service和mynginx-headless-service-no-selector详细信息:

创建mynginx-headless-service-no-selector-endpoints.yaml:
apiVersion: v1
kind: Endpoints
metadata:
name: mynginx-headless-service-no-selector
subsets:
- addresses:
- ip: 10.244.1.8
- ip: 10.244.2.45
- ip: 10.244.2.46
ports:
- port: 80
通过以上配置创建Endpoint对象,创建Endpoint对象会添加到mynginx-headless-service-no-selector中,查看mynginx-headless-service-no-selector详细信息:
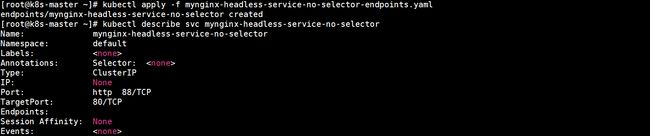
查询DNS记录:

对该域名进行解析:

九、支持的协议
- TCP:可以将TCP用于任何类型的服务,这是默认的网络协议。
- UDP:可以将UDP用于大多数服务。对于type=LoadBalancer的服务,对UDP的支持取决于提供此功能的云提供商。
- HTTP:如果自己使用的云提供商支持它,则可以在LoadBalancer模式下使用服务来设置外部HTTP/HTTPS反向代理,并将其转发到该服务的 Endpoints。也可以使用Ingress来代替Service来公开HTTP/HTTPS服务。
- PROXY协议:如果自己使用的云提供商支持它,则可以在LoadBalancer模式下使用Service在 Kubernetes本身之外配置负载均衡器,该负载均衡器将转发前缀为PROXY protocol的连接。
- SCTP:Kubernetes支持SCTP作为Service,Endpoint,NetworkPolicy和Pod定义中的
protocol值作为alpha功能。要启用此功能,集群管理员需要在apiserver上启用SCTPSupport功能,例如--feature-gates = SCTPSupport = true,…。启用此功能后,可以将Service,Endpoint,NetworkPolicy或Pod的protocol字段设置为SCTP。Kubernetes相应地为SCTP关联设置网络,就像为TCP连接一样。