【强化学习】ICLR 2020 强化学习相关论文与会议slides分享
关注上方“深度学习技术前沿”,选择“星标公众号”,
资源干货,第一时间送达!

作者:王小惟
知乎链接:https://zhuanlan.zhihu.com/p/137515707
本文仅作学术分享,若侵权,请联系后台删文处理
(长文来袭,建议做强化学习研究的朋友们,先收藏然后再仔细阅读!文末可扫码进强化学习微信交流群)
趁着看ICLR 2020 的虚拟会议,把看到关于RL的都整理了下,主要组成为:1. 我对这个文章的简单总结, 2. 这个文章作者talk中的ppt/slide截图。
目前论文还有一些遗漏,之后在update,主要update更新在github。
代码链接:https://github.com/wwxFromTju/awesome-reinforcement-learning-zh
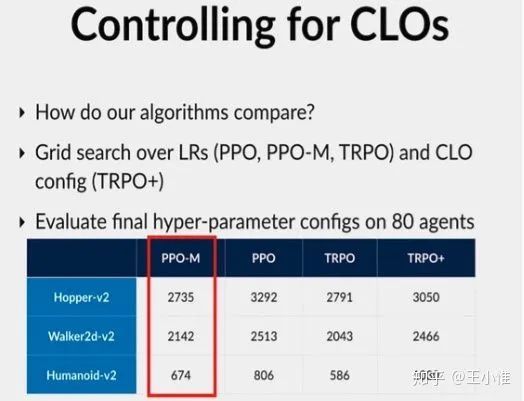
Implementation Matters in Deep RL: A Case Study on PPO and TRPO
现在DRL的效果更多偏向trick + 工程, 这容易使得idea的价值被淹没,也使得他人很难复现论文效果。
作者考虑下了ppo他们实现中的一系列论文中容易被忽略(没有提及的)trick,并分析了其对于最终性能的影响。



-M表示去掉了那一些列trick,对比下原始ppo,emmmmm。trpo+为将ppo中用的trick用到trpo上。

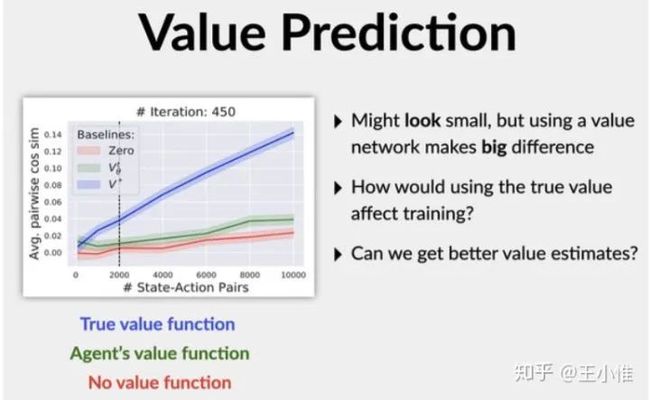
A Closer Look at Deep Policy Gradients
考虑一下虽然PG的理论蛮好的,但是我们用NN实现完后,是否会满足我们最开始的理论动机?作者主要考虑3个点:1. 理论上采用引入value function后,计算pg的advantage应该是方差减小的;2. TRPO/PPO担心PG一步更新太大,从而引入surrogate,希望能进行稳定的提升。但是这个额外项会对优化方向(梯度)有多大影响?3. 梯度更新的方差。
首先,引入value function似乎对var影响不大:
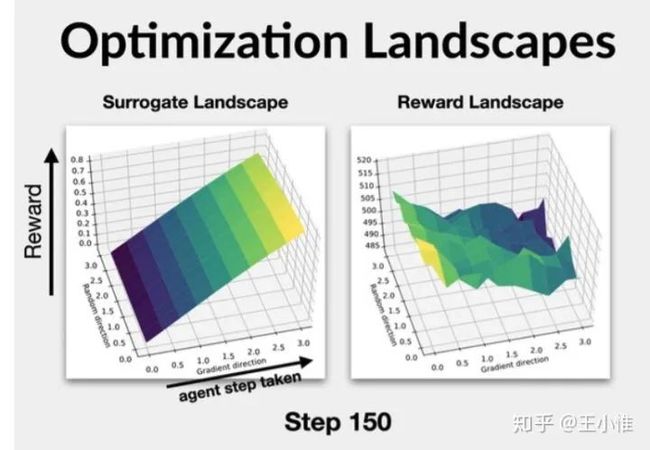
其次surrogate landscape可能修改了真实的优化目标:

Ranking Policy Gradient
从q-leaning的分析而来,q-learning + max的操作其实不用学习到准确的估值,只需要让最优的action对应的q-value比其他action的q-value大就好了。那么这个角度也可以用来设计出policy gradient的loss,从而进行更新。
简单来说,就是设计一个网络,输入state,输出relative action value,用的时候可以greedy用个一波(当然也可以用概率形式),然后PG的时候,将relative action value通过pairwise的方式把action的概率建模出来(大致上还是这个值越大,action被选中概率就越大)。
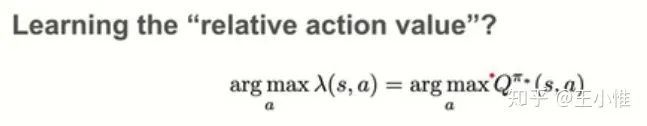





Deep Covering Options
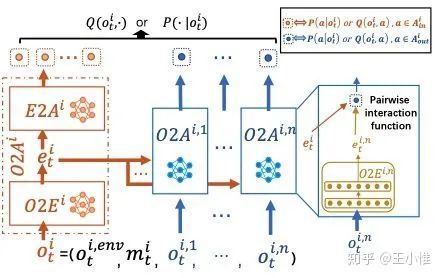
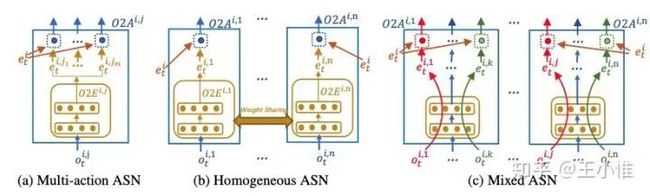
Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
私货,我们考虑MA中自然存在的交互属性,并分析其与action semantic的关系,从而设计出一系列在MA环境下更合理的网络结构,从而获得更快速速度 + 性能表现。

Graph Constrained Reinforcement Learning for Natural Language Action Spaces
针对text game这种交互形式的game,设计出相应的网络来缓解不好学 + action space带来的问题。
首先依然知识图谱 + 里面state的特定网络表征,然后与之前不同,这边考虑的是组合动作空间,相当于考虑了action的特定结构,然后可以分解成多个组合子action。

action的结构:所以相当于做了三个子action

Composing Task-Agnostic Policies with Deep Reinforcement Learning
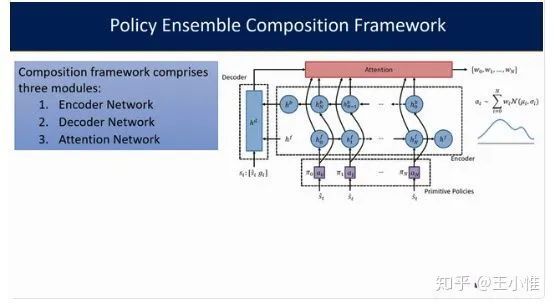
就是有一些普通的low-level策略,与任务无关,比如机器人的移动,然后高层(attention)就是学习怎么组合策略。
Sharing Knowledge in Multi-Task Deep Reinforcement Learning
偏理论的文章,“The paper attempts to give theoretical support for using shared representations among multiple tasks.”

注意下,这个h不是hidden state,而是一个(多个)共享层(layers)。相当于每个task有自己的特征抽取的layers,然后接共享的h,然后再接自己的f,mapping到action q/概率。
Sample Efficient Policy Gradient Methods with Recursive Variance Reduction
采用semi-stochastic gradient,控制variance。

下面这个做法没有做修正?
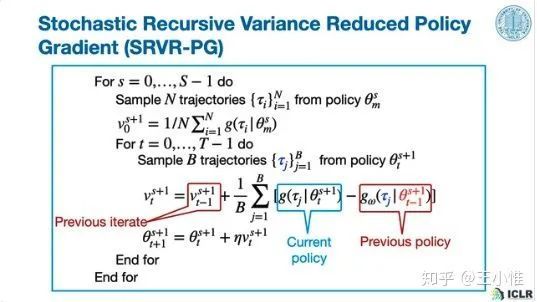
然后论文中还有一些Sample Complexity的分析

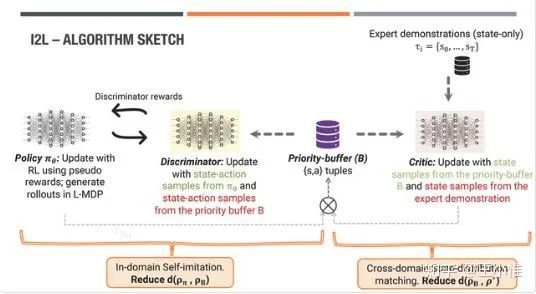
State-only Imitation with Transition Dynamics Mismatch
本文说自己是一个新的角度,关注state space (差不多)一样,但是model的动力学的model不同(状态转移),所以就可以直接做state-trajectory层面的的模仿。然后利用discriminator来引导policy学习到专家的state-trajecotry上。


A Learning-based Iterative Method for Solving Vehicle Routing Problems
想利用RL的快,来解决Operations Research (OR)的问题。结论:1. learning-base的速度的确快,毕竟只是执行嘛。2. 没有classical OR solvers的解的质量高。

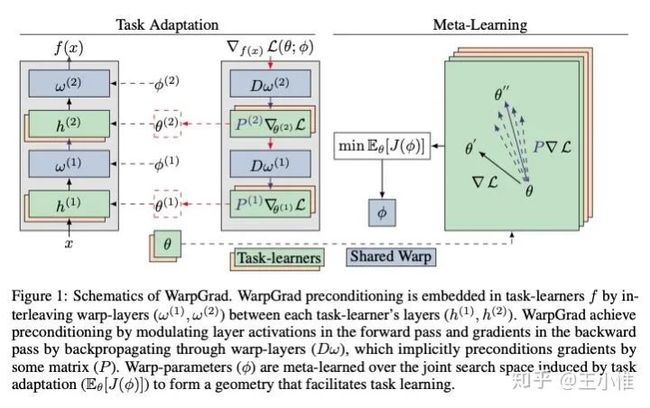
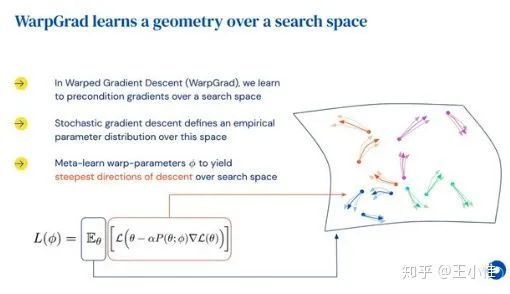
Meta-Learning with Warped Gradient Descent
考虑到gradient-base的meta的一系列问题,特别是由于loss的surface导致不好调整parameter(同时考虑到这个parameter space不一定是合理的task adapt的space)。
实际上就是:选择网络中的(间隔)部分layers,通过meta-learning学习出对应的权重,然后不变。之后再采用普通的gradient继续做meta。将meta-learning学习出的weight看成对于loss曲面(gradient)的一个投影,使其更好学习/调整。


Synthesizing Programmatic Policies that Inductively Generalize
考虑到一些重复的动作可以使用到别的任务上(或者略微不同的任务上),所以提出采用programmatic state machine policies来捕捉重复的action。
举例,比如侧方停车/出去,当比较挤的时候,需要多次重复动作。这个重复就是可以利用的:
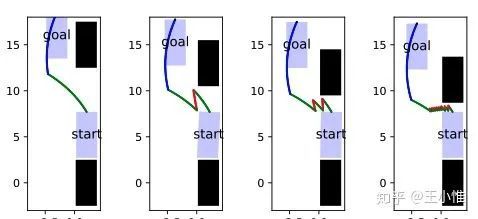
对应的状态机:
学习的时候,如图:

Meta-Q-Learning
这篇论文提出了一种新的Meta Learning的算法。简而言之,先看成一个多任务的学习过程,然后在adapt。
首先一个有意思的点,MAML work不好。PEARL不错,但是和加入context label的td3比起来差不多。所以更多的点应该在于,这个反传梯度的更新方式不太work。detect task,然后给予任务相关的信息的方式可能更work。
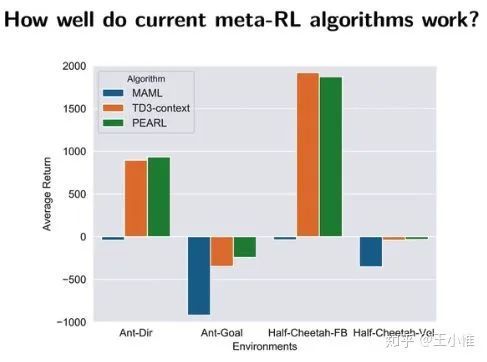
论文里面的关键点:



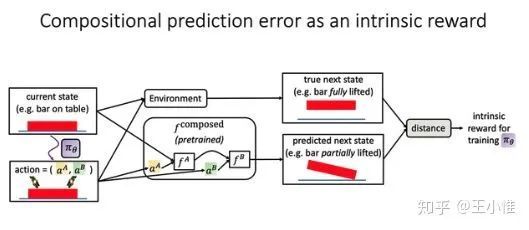
Intrinsic Motivation for Encouraging Synergistic Behavior
认为一些state是需要agent一起执行(合作)行为才能到达的。所以可以先训练单个agent的预测网络,然后通过叠加单个agent的预测网络来预测,如果与实际的state不同,就认为这个state是需要agent共同执行(特定)action-pair才能到达的,以此来鼓励agent进行合作探索。



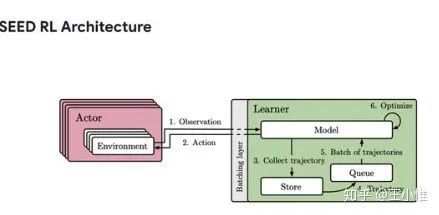
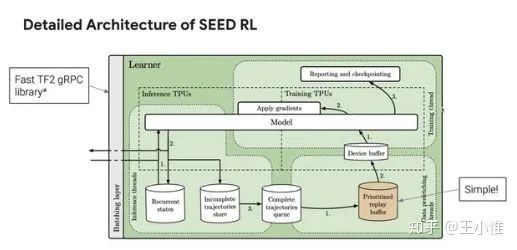
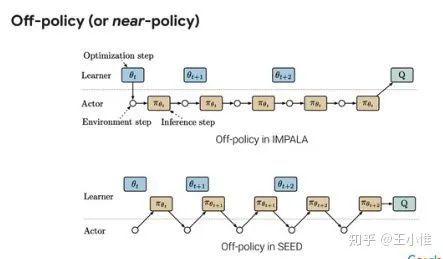
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
Google的工程美学(个人蛮喜欢看这类文章的,哈哈哈,类似于屠龙术,一般情况肯定没有资源/机会上到那么海量的资源,所以肯定也不知道到底并行时候的瓶颈在哪里,是通讯呢,还是计算呢,或者是模型同步(通讯)呢,等等,看看还是有收获的),效果不错,中心的policy,不再传递parameter。





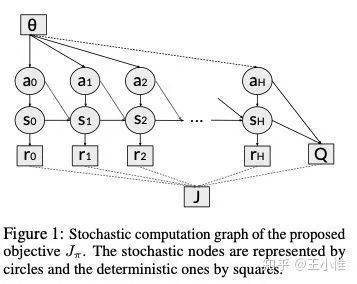
Model-Augmented Actor-Critic: Backpropagating through Paths
采用学习出来的model和pathwise derivative来做传播,效果更好。注意一下,这边用model生成了数据后,加入了buffer(我怎么觉得和dyna差不多啊),然后再用这个buffer来学习。

SVQN: Sequential Variational Soft Q-Learning Networks
采用unified graphical model来formalizes部分可观察下的hidden states和policy的优化。



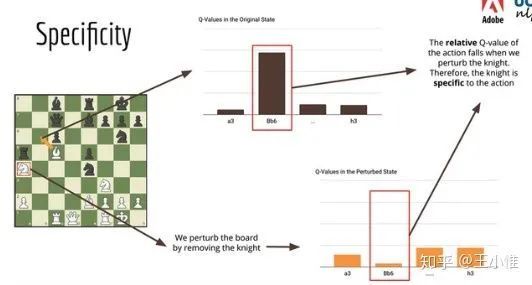
Explain Your Move: Understanding Agent Actions Using Focused Feature Saliency
尝试来解释RL agent。做法简单而言,就是:在state上增加noise/perturb,之后看看Q的变化,然后来判断是否是关键state信息。
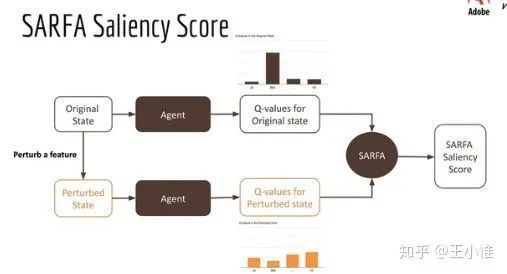
关于perturb之后,按照不同角度来分析:


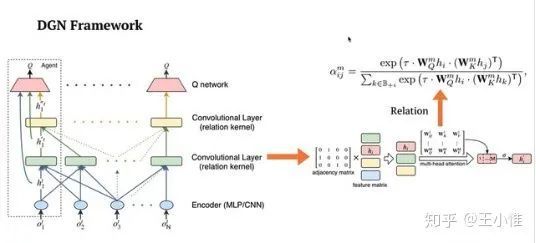
Graph Convolutional Reinforcement Learning
感觉规则的东西还是偏多,瑕不掩瑜,角度蛮好的。
首先建立graph(在这里就直接是空间距离 + rule了),然后再graph的基础上,用下面的结构来进行训练/推断。
不想每个time step下graph的变化剧烈,于是反过来用KL,约束前后的graph应该差不多

State Alignment-based Imitation Learning
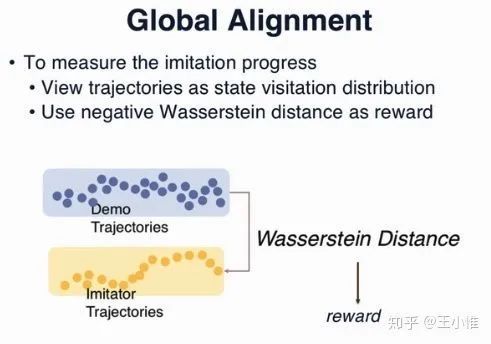
考虑的还是,虽然MDP中存在一系列不一样的地方(比如不同的机器人对应的不同的T)等等,但是从状态的角度,还是能有一些知识的迁移的(类似State-only Imitation with Transition Dynamics Mismatch那篇)。做法简单可以理解成:通过约束专家trajectory 与 自己的trajectory的Wasserstein Distance来做knowledge的迁移。此外,额外约束局部转移上的states应该可以alignment得接近,从而提供学习信号。


做法分为两个部分,global alignment和local alignment。
具体的,global alignment为:
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control


Thinking While Moving: Deep Reinforcement Learning with Concurrent Control
一个有意思的角度,之前的RL的范式是:每接收一个state,然后agent做决策,然后与环境做交互,然后接收到下一个state。这边考虑的是,在你做决策的时候,环境也在不断的变化,同时你与环境做交互(需要一定的时间交互)的同时,环境也在变化。这样的设置更真实。
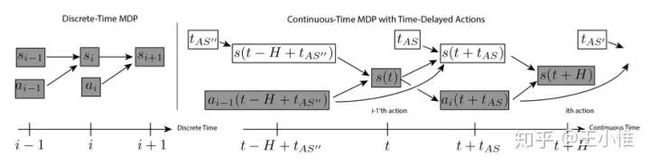
简单做法,就是将agent的执行时间 + 推断时间考虑进去(因为推断的时候没有新的action,所以推断的时间,其实就是一直执行上一个action)

更为具体地考虑,拿到state后,开始决策,决策过程中用上一个action顶着,然后算出action后,再执行,直到下一个拿到state的时间点。

Model-based reinforcement learning for biological sequence design
用来设计生物序列的,比如DNA。。。。
这里的modal体现在,挑选对应的candidate models

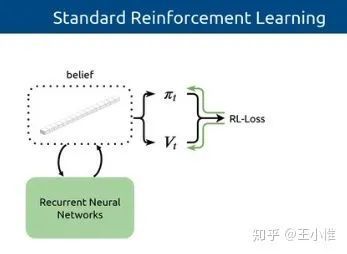
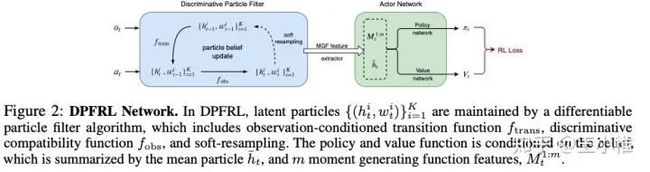
Discriminative Particle Filter Reinforcement Learning for Complex Partial observations
直观的说,常见用来解PO的方式就是加入RNN,作者首先觉得可以有更好的方式(比如类似常见的方式建立belief),然后进一步采用对应的particle filter来构建这个belief,然后利用构建出来的信息来学习。实验效果看上去比RNN(GRU)更好。



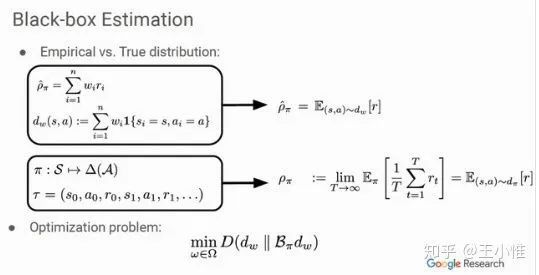
Black-box Off-policy Estimation for Infinite-Horizon Reinforcement Learning
这里的black-box的意思是behavior-agnostic,就是不需要知道behavior policy,不需要知道behavior policy去获得stationary distribution。



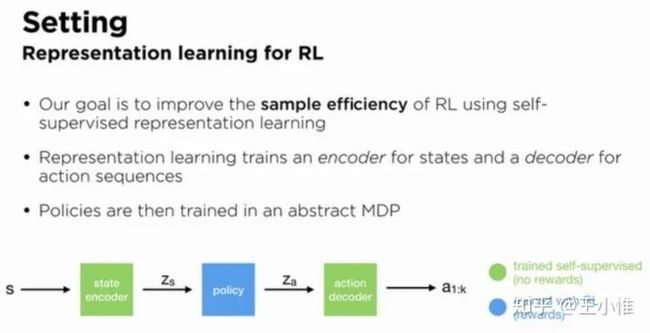
Dynamics-Aware Embeddings
如下图所示,将state,action都看成embedding,将state嵌入成z_s,然后policy作出action embedding后,再decode成对应的action。
然后用self-supervised来学习对应的embedding


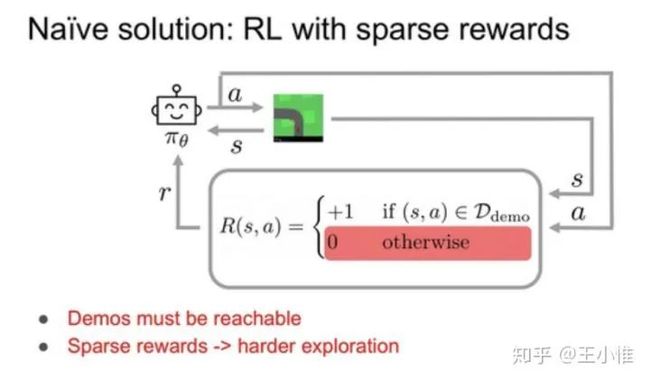
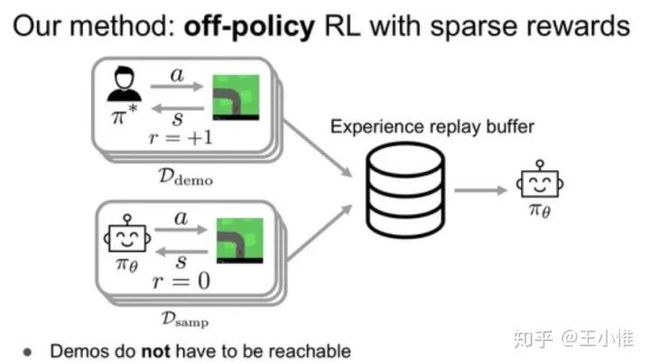
SQIL: Imitation Learning via Reinforcement Learning with Sparse Rewards
相比利用GAN来做专家经验的迁移。这里直接label对应专家经验为正奖赏,然后agent自己的经验为0。然后直接用soft q学习一波。


Hypermodels for Exploration
Ensemble DQN有个问题,就是需要比较多的参数,同时网络的数量不好确定。这篇论文简单说,就是不再是维护一组网络,而是采用hypernet来生成对应网络的参数,然后再进行学习。



Robust Reinforcement Learning for Continuous Control with Model Misspecification
考虑“model misspecification”的问题,就是transition dynamics是存在一定的波动/变化的,比如K台同款机器人,由于工艺的约束等,他们必然不可能完全一模一样,多少(在控制的时候)存在区别。那么怎么解决上面这类问题呢?作者将MPO与Robust结合,简单说,就是在transition dynamics上加入了perturbations,然后更新的时候在K个Q上取inf

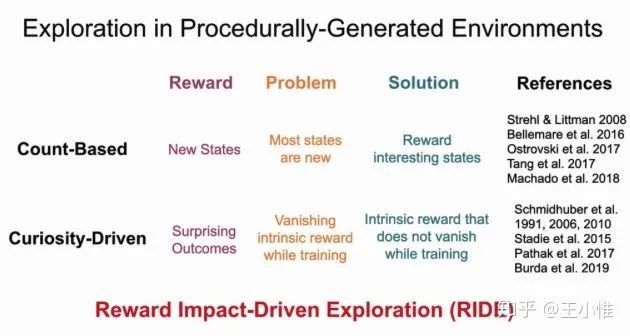
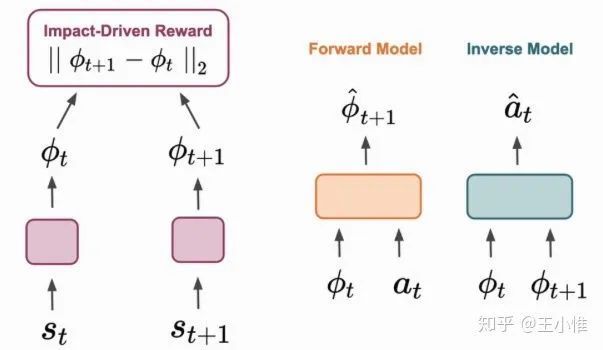
RIDE: Rewarding Impact-Driven Exploration for Procedurally-Generated Environments
一种探索的方式,简单看就是在ICM的reward基础上,除了一个当前trajectory中这个state访问的次数,稍微修正了一个trajectory/episode探索时候的balance,而不是在一个episode里一直访问建模不好的state附近从而来刷分。(感觉就是简单count + curiosity

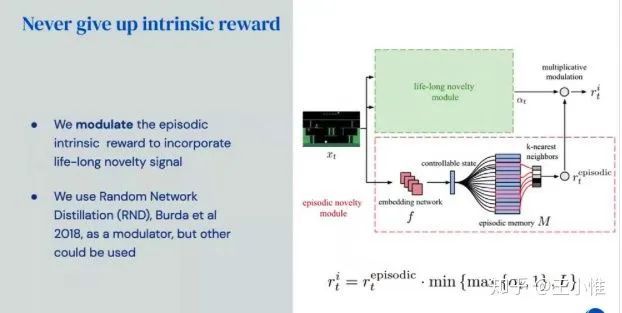
Never Give Up: Learning Directed Exploration Strategies
一种探索的方式,通过同时learning一个family的policy来变现出不同的探索行为,然后在用参数去控制。

以前方法的问题:

Never Give Up的做法:

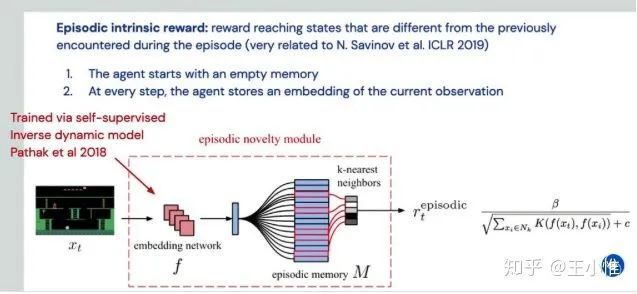

On Bonus Based Exploration Methods In The Arcade Learning Environment
本文关注点在,当前的探索算法都是集中在几个特定的环境中(比如探索论文几乎标配的Montezuma's Revenge),那么这些算法适用于其他ALE的环境吗?--这个问题其实就等价在说:我们不只是针对特定的环境要研究特定的算法(那么这样的适用范围就被约束了),更需要探索更高效的“通用”的探索算法。
直接说结论,在一些不太需要特定的探索行为的环境中,一系列特定提出的探索方式效果和e-greedy差不多(或者差一些)。这也说明这些探索算法不通用。


一些我觉得蛮有用的信息:
ALE环境的分类



实现时候控制的条件

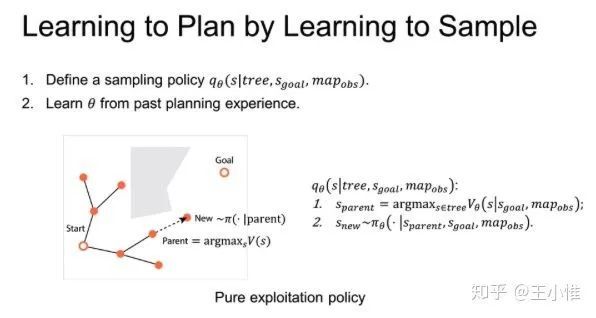
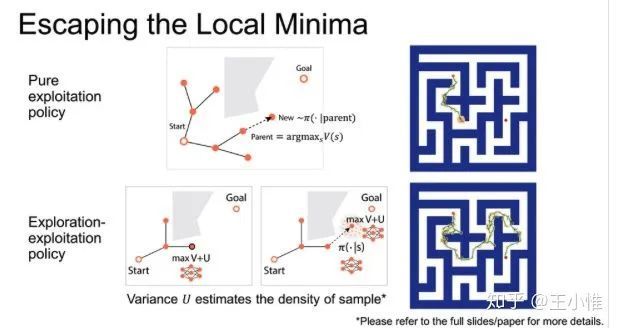
Learning to Plan in High Dimensions via Neural Exploration-Exploitation Trees
考虑当前大部分方法在tree展开选择下一个node的时候,采用uniform distribution的方式,这样肯定性能不太好。于是将“选点”的操作建模成一个learning的过程,通过修改过Q-learning的方式,给予每个点赋予一个Value,然后基于这个value值来做加权的采样。


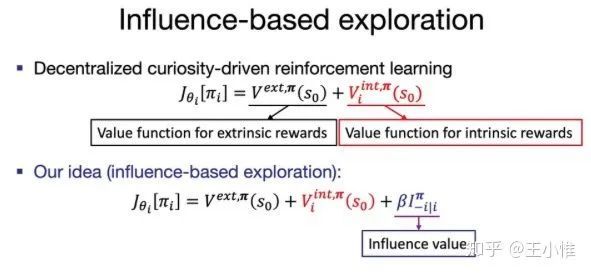
Influence-Based Multi-Agent Exploration
如下所示,考虑到MAS中agent交互的特性,来考虑特殊的探索需求,然后形式化一下,来做引导。


Model Based Reinforcement Learning for Atari
一种model-based的RL,大思路还是Dyna那一套:收集数据,建模world,利用world继续学习,然后继续收集数据。这边的主要创新就是对应网络结构,作者声称很work。

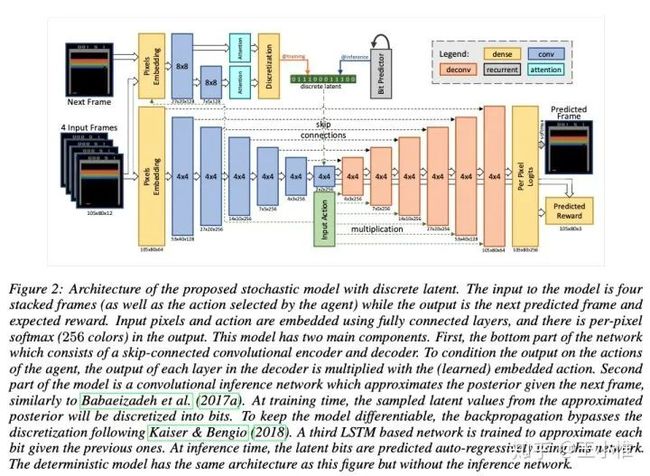
stochastic world model with discrete latent variable,predicts plausible futures.


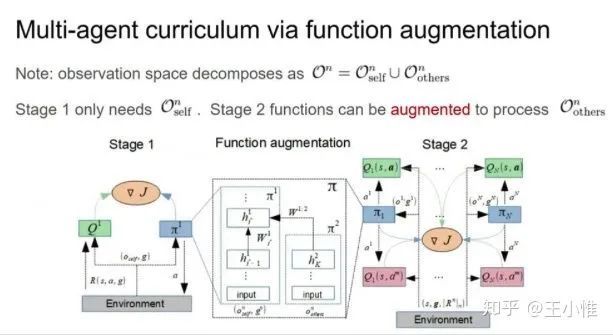
CM3: Cooperative Multi-goal Multi-stage Multi-agent Reinforcement Learning
考虑multi-goal的设置,采用curriculum的方式,先训练single-agent下的policy,然后作为ma下的初始化,然后在学习其中的部分参数(每个curricula的input不一样来加速学习)

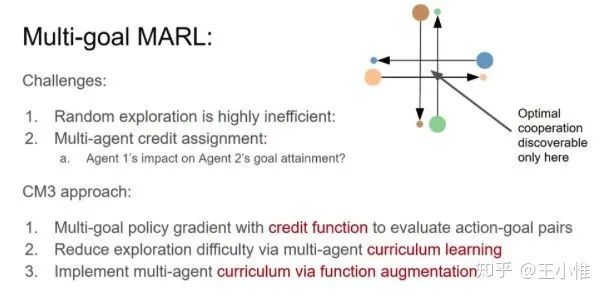
直接定义了不同agent对于不同goal的Q的value



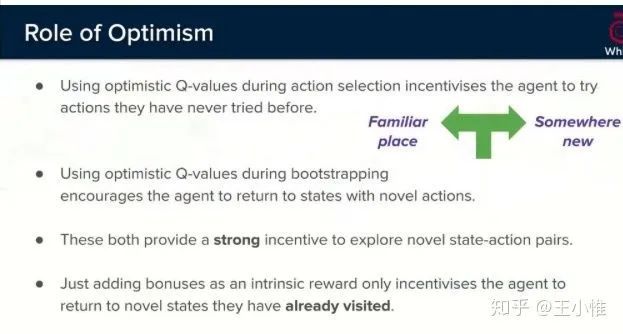
Optimistic Exploration even with a Pessimistic Initialisation
将optimistic initialisation引入NN,但是并没有做NN初始化上面的工作,而是将Q扩展为Q+,为普通的Q + 一个与访问次数成反比的数值。



Making Sense of Reinforcement Learning and Probabilistic Inference
将RL优化的问题建模成Bayesian inference problem,那么优化的角度就变成了最小化bayes regret了。然后对Thompson Sampling,K-learning,Soft Q-learning做了分析。







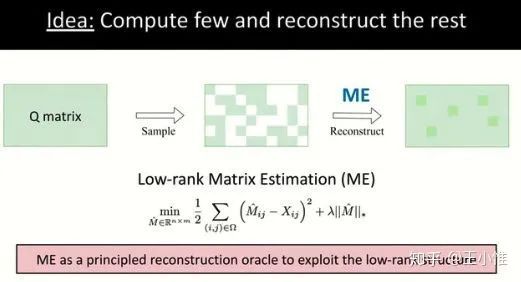
Harnessing Structures for Value-Based Planning and Reinforcement Learning
利用Q-value的structures特性--low rank来构建planning和RL的算法。
个人感觉其实并不太涉及Planing和RL的core的问题,而是利用这个structures来做一些数据的扩充/不确定的约减。(所以其实这个流程并没有和RL强耦合,其他SL的算法中也有见过类似的做法)
具体过程如下,简单总结就是:1. sample出数据,数据不是全部的state-action space上的所有点,2. 利用low-rank + ME来将其他点重建出来,3. 利用RL/planning来做学习。


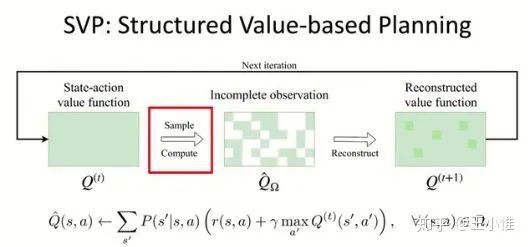
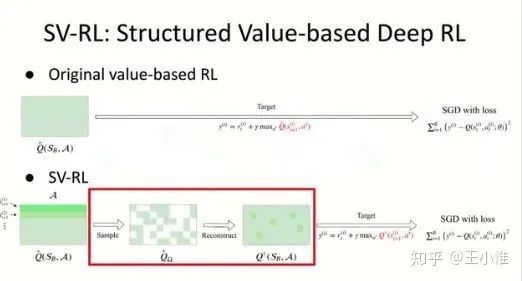
DRL(image space)通常处理的空间比较大,不太可能在state-action层面上做操作--->reduce成batch上面来做:
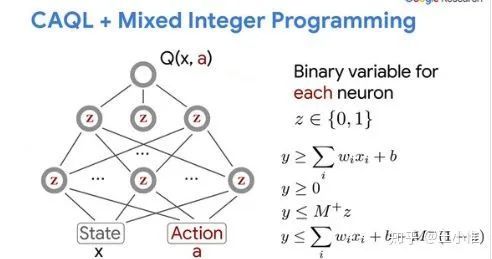
CAQL: Continuous Action Q-Learning
Q-leaning(及其变体)由于求解max的操作符,使得很难运用在continuous action space上面(有无穷个action,怎么求解max?)。这篇论文采用Mixed-Integer Programming(MIP)的方式来求解max的action。







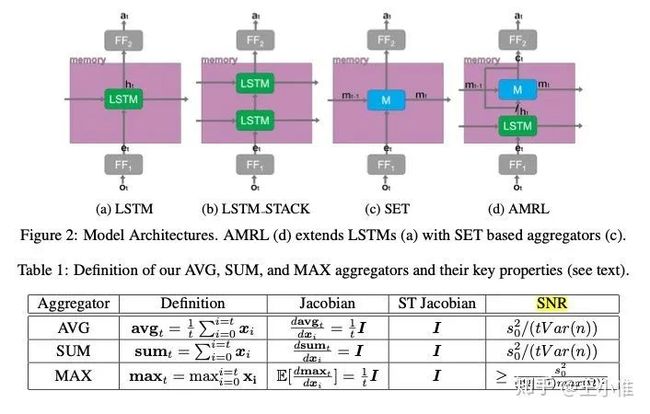
AMRL: Aggregated Memory For Reinforcement Learning
改进RNN-like的memory的网络结构,结合了order-invariant function来缓解普通RNN存在的gradient decay和对于noise的敏感。

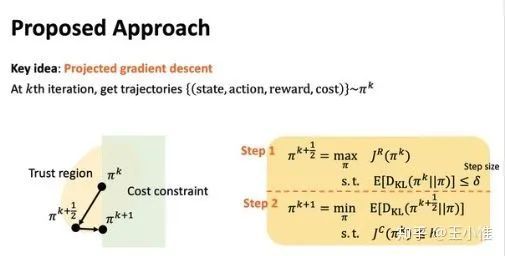
Projection-Based Constrained Policy Optimization
考虑到带约束的RL的情况,做法简单说就是分为两步,1. 优化当前策略,2. 基于1优化后的策略,projection(搜索)出一个接近的策略,同时满足constrained。

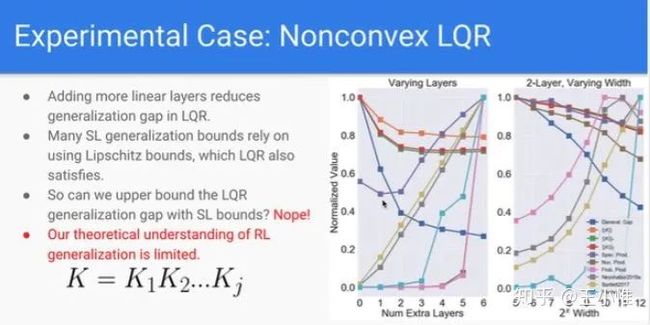
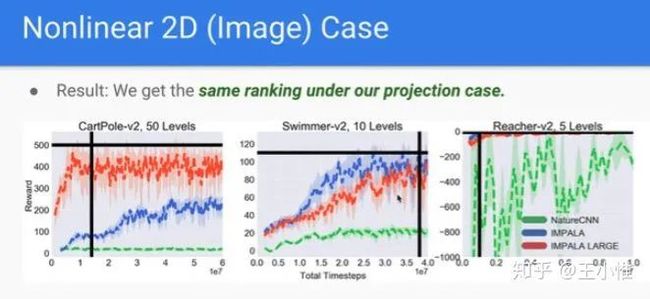
Observational Overfitting in Reinforcement Learning
分析Observational Overfitting的一篇文章。










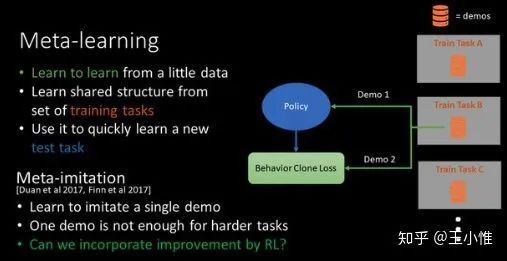
Watch, Try, Learn: Meta-Learning from Demonstrations and Rewards
通常IL需要比较多的专家的数据。但是在很多环境中获得的数据不多。所以论文想要用 一点点专家的数据 + 几次尝试,来做快速的learning。
大致的流程就是:1. 先在一系列的任务上收集一些demo,2. 利用这些demo来训练一个meta-imitation policy,3. 利用这个meta-imitation policy去与环境交互收集少量数据,4. 利用demo + 少量数据来训练一个conditioned policy。目的就是优化:3 + 4 的调整的速度。






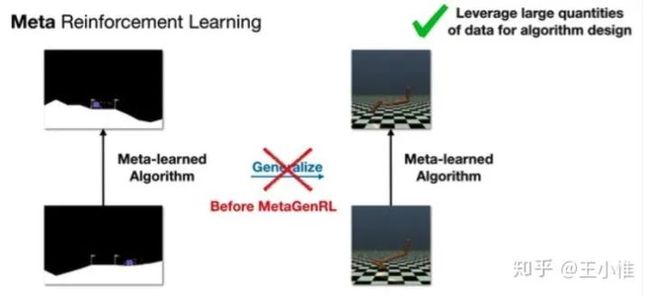
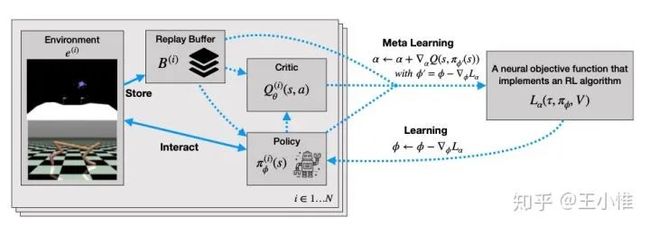
Improving Generalization in Meta Reinforcement Learning using Learned Objectives
RL虽然用learning的方式来进行policy/value的学习,但是实际上,learning中使用的loss其实就是人类/专家的知识的注入,那么一方面这个loss可能不是很好优化啊,另外一方面这个loss可能不能优化到最有解。作者从这个角度输入,希望能够从data-drive的角度来自动learning出一个loss函数,这个函数可以迁移到其他的RL任务下,同时带来更好的新性能/收敛速度。
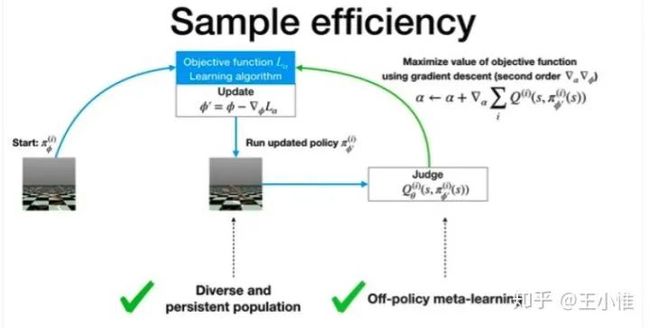
实际的做法就是采用一个LSTM作为loss的表示,然后meta的时候主要就是其中一个比较好的参数的(alpha)。同时可以采用off-policy,population来加速。



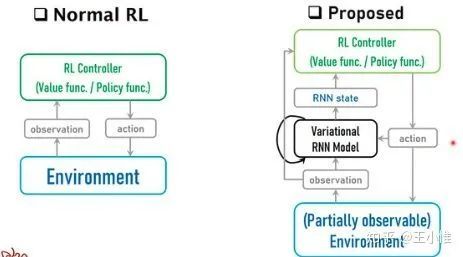
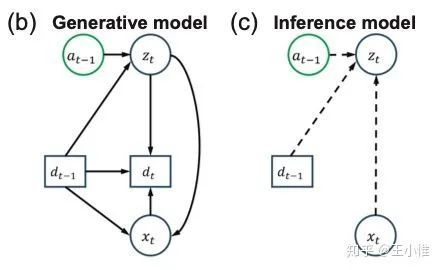
Variational Recurrent Models for Solving Partially Observable Control Tasks
考虑PO下面的不确定导致的难学,于是提出采用variational recurrent model (VRM) 来对环境进行建模。然后RL在学习/决策的时候,除了环境获得的observation外,同时还会收到VRM建模出的额外的信息,然后利用两个信息来进行学习/决策。

IMPACT: Importance Weighted Asynchronous Architectures with Clipped Target Networks
考虑一个有意思的点,sample efficiency不一定能带来更快速的学习速度,因为每个step下的推断速度,每个训练的开销,都可能带来速度上的瓶颈。所以作者从希望获得一个快速learning的RL的算法。
这边主要关注了,并行的时候带来的瓶颈约束:
PPO需要on-policy的数据,所以需要Synchronous,导致没有办法持续产生数据(actor/policy与环境交互的数据),而是需要等待policy update后,再继续产生数据。
IMPALA虽然可以持续不断的产生数据,但是Sample efficient没有PPO/SAC好。
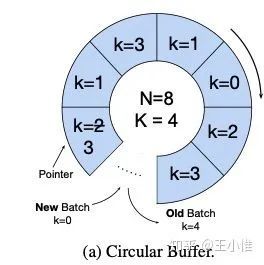
目前的做法就是提出采用:Maximal target-worker clipping objective + circular replay buffer
这边做类似IS的时候,除了考虑worker的policy与当前policy的差别,还额外考虑了target network(policy)的修正


circular replay buffer 其实就是一个batch会被访问K次,访问k次后,会被新的数据取代掉。感觉就是比普通的buffer而言,更新的更快的buffer。
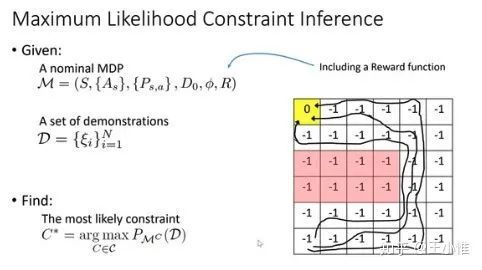
Maximum Likelihood Constraint Inference for Inverse Reinforcement Learning
考虑到现实世界的很多问题都是带约束的,那么约束从哪里来?这篇论文认为可以从Demonstrations来,通过demonstrations学习到对应的约束,从而来帮助RL进行学习。
具体的是迭代的选择出对应的约束。


Automated curriculum generation through setter-solver interactions
自动生成Curricula来加速RL的学习,这边考虑的环境是你可以直接控制goal的环境,然后agent的目的就是去完成这个goal(所以采用goal-condition policy来学习)。
具体就是采用:setter-solver的架构,setter就是给agent/环境设置对应的goal,其实就是curricula,然后solver就是RL agent。从这个角度来看,要生成合理的curriculum的关键就是setter生成合理的goal序列






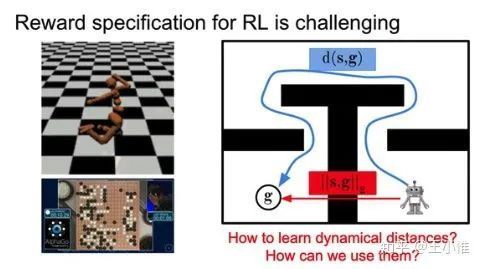
Dynamical Distance Learning for Semi-Supervised and Unsupervised Skill Discovery
主要是考虑reward不好定义问题,这边关注的是state到达的任务,那么就可以分成:1. 在环境中sample出一系列trajectory, 2. 利用这个trajectory来学习出到达特定state的distance函数(这个distance的输入可以就是目标state与当前state),3. 利用这个distance来进行RL训练


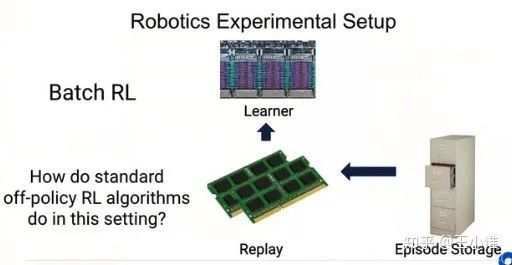
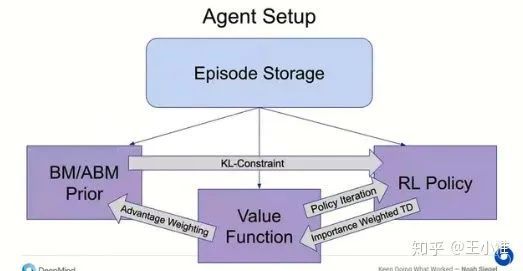
Keep Doing What Worked: Behavior Modelling Priors for Offline Reinforcement Learning
考虑Offline RL带来的Inaccurate的估计,类似BCQ的做法,就是约束agent做之前做过/见过的action,考虑到连续action space带来的判断问题,于是就先用BC的方式先学出一个policy,然后用这个policy来对learning的policy做KL的约束,从而希望约束其在data distribution中,进而提升性能。





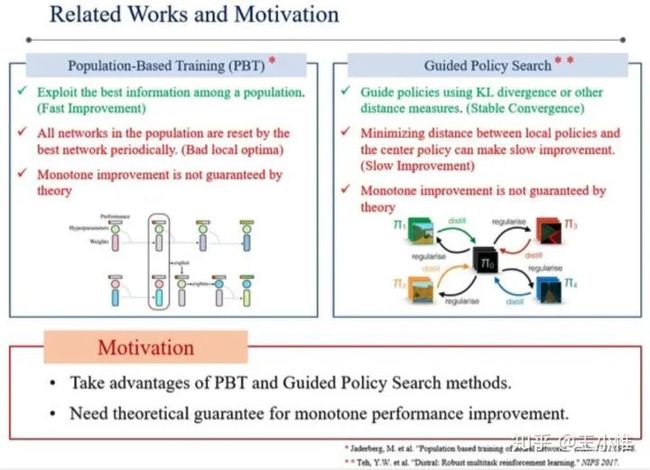
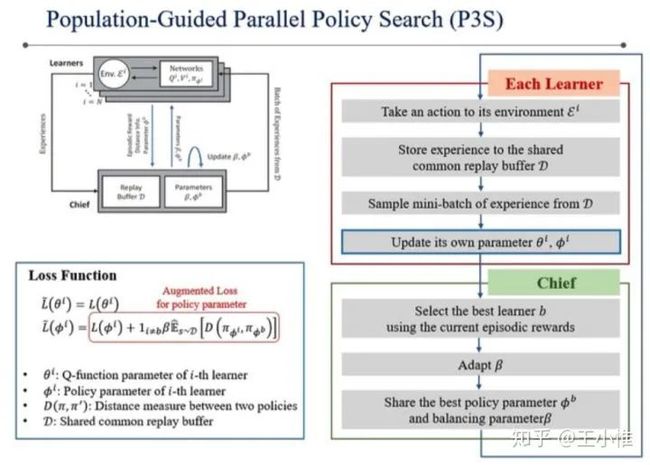
Population-Guided Parallel Policy Search for Reinforcement Learning
将PBT + PS 结合在一起,其实就是learning的时候并行开N个learner一起学习,学习的时候约束不要偏离太多学习初始的策略,然后一段时间后选择这N个learner中最佳的policy,然后以此为初始化策略继续开N个learner,重复这个过程。另外给了一些稳定提升的理论保证。





Infinite-horizon Off-Policy Policy Evaluation with Multiple Behavior Policies
偏理论的论文了,目的如标题所示就是evaluation得准。然后通过learning的方式来建模(mixture)behavior police

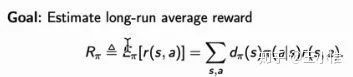








Doubly Robust Bias Reduction in Infinite Horizon Off-Policy Estimation
目的同样是Estimation得准确。







GenDICE: Generalized Offline Estimation of Stationary Values
一样还是estimation









Imitation Learning via Off-Policy Distribution Matching
采用将IL视为Distribution Matching的优化问题,然后考虑说之前的算法主要存在两点问题:1.要求on-policy的形式,需要一大堆与环境的交互,2. GAIL类的方式,需要额外一个RL算法来学习,带了复杂性。
这里提出ValueDICE采用off-policy的方式来做estimation,然后进行divergence minimization。









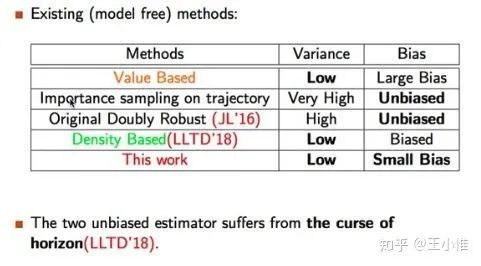
Maxmin Q-learning: Controlling the Estimation Bias of Q-learning
Q-learning的高估是大家的共同认识,所以有些人就关注在如何降低这个高估的误差(就是估计的更准)。作者这里提出,高估不一定会带来问题,有些环境下的高估反而会帮助学习,所以作者提出“parameter-tuning mechanism to flexibly control bias.“。实际的做法有点像bootstrap的double变体,就是开N个Q,在选择target的时候,选择每个action的最低估计Q,然后在这些最低估计Q中选择出最大的action及其对应的Q。


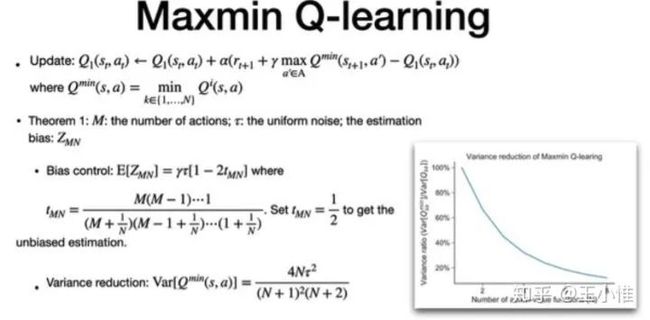
Dynamics-Aware Unsupervised Skill Discovery
同样关注reward不好设置的环境,提出先采用Unsupervised learning方式学习出一系列的skill及其在skill上的环境转移,然后利用skill(及其状态转移)(+ 当前任务的reward function)来进行model-predictive-control (MPC)。
我感觉这种隐空间plan的方式,有点像VPN啊。另外,感觉就是对action space的大小做了一下reduce。
实际做法就是用基于条件的互信息,优化出关于laten variable的状态转移(认为这个是skill),然后利用上面优化出的laten variable及其状态转移来做规划。
之前的做法更多的是考虑多样性(z与state的关联性),而没有考虑对下一个state的影响。

修改一下优化目标,希望关注的是状态转移 与 z的关联性(而不是单纯的一个state)。-- 然后就优化了关于z的转移函数



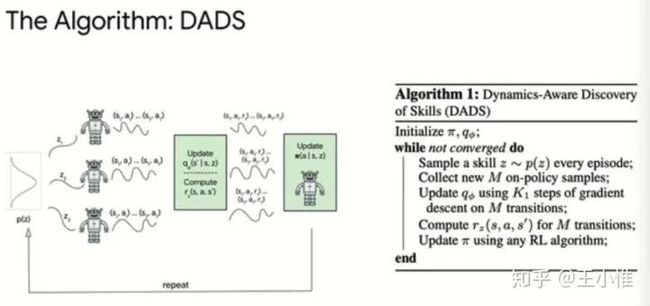
然后就可以利用这关于z的转移,来做规划了。
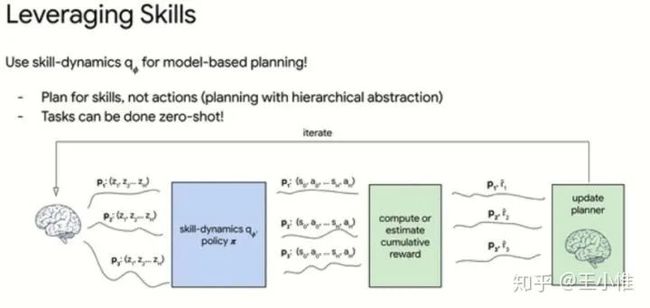
Sub-policy Adaptation for Hierarchical Reinforcement Learning
一种新的HRL的方法,从整体的return的角度来直接导出不同level policy的gradient。(之前HRL由于low level 决策时的sample,导致没有办法求导过去。)
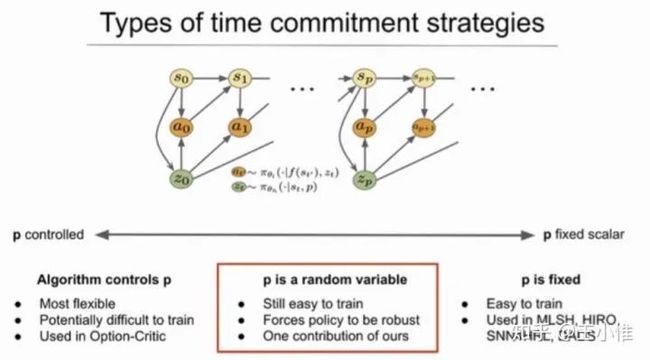




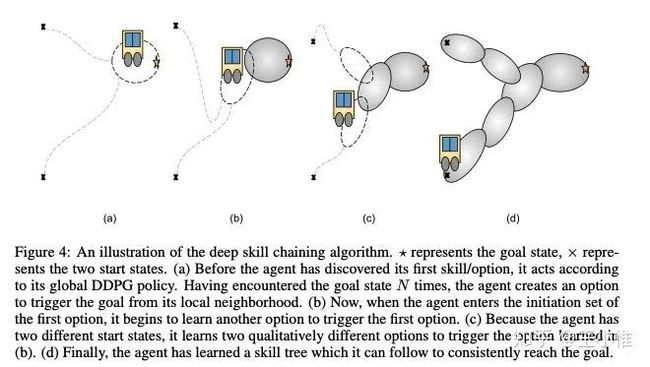
Option Discovery using Deep Skill Chaining
如图所示,在到达goal-state的环境下,可以从后往前进行option的抽象。然后将新生成的option放在set中,就变成了离散的option选择了。
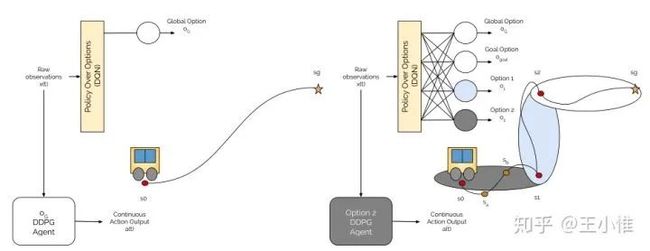

Learning to Coordinate Manipulation Skills via Skill Behavior Diversification
简单说分为两步,1. 用diverse的思路(mutual information)训练出一堆的skill,2. 利用meta policy直接控制多个机械臂,不过控制维度不再是直接的action,而是skill的选择。

Multi-Agent Interactions Modeling with Correlated Policies
认为之前的MAIL的方式建模少考虑了其他智能体策略间策略的互相影响,从而近似reduce成多个independent的agent来直接处理。然后这里多考虑了其他agent action对于该智能体决策的影响,从而IL更好。






Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
其实就是skill的组合使用,目前就是同时训练k个policy,每次训练的时候,sample出一个policy(skill)来用。
具体是采用IB的方式把policy用中间变量z来表示,同时用KL来约束这个z的分布与先验(高斯)分布接近,同时用这个KL的值来计算每个policy的选择概率。(这里可以理解成,因为约束了与高斯接近,所以大家都差不多,只有会带来高收益的policy,其z的分布才会偏离高斯,从而带来更高的选中概率)。额外在约束下这个采样policy的entropy,不要坍塌到只选择一个policy上。




Behaviour Suite for Reinforcement Learning
一套用来衡量RL算法的benchmark环境,并给出在Generalization,Exploration,Credit Assignment,Scale,Noise,Memory等维度的定量评价。
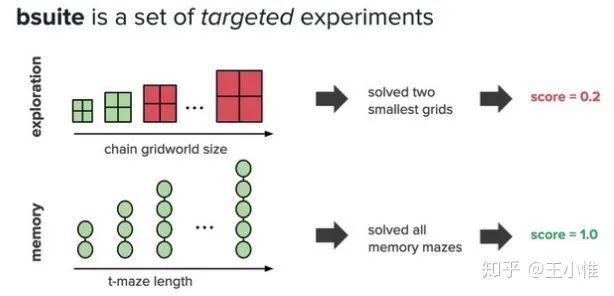

Measuring the Reliability of Reinforcement Learning Algorithms
考虑到RL的性能评价受到很多因素影响(比如seed个数,seed选择,具体实现等等),认为应该不只是统计reward/return的mean +- var 来评判RL算法的好坏,并提出另外集中衡量标准。

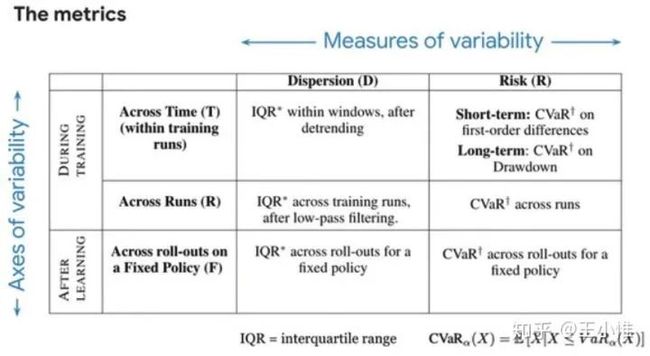
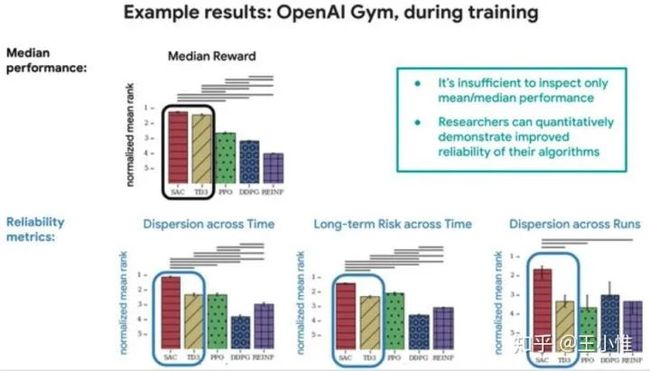
不同衡量指标下gap差别蛮大的:
An Inductive Bias for Distances: Neural Nets that Respect the Triangle Inequality
一种学习metric的方式,作者将其与UVFA结合,效果更好。

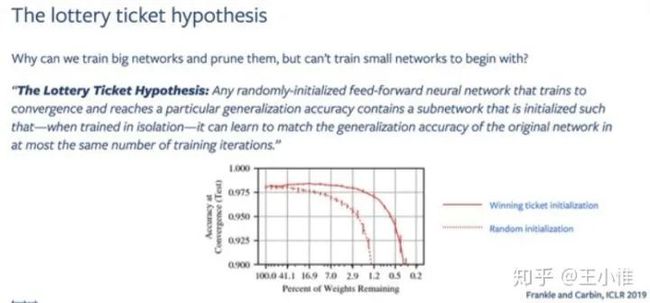
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
将lottery tickets扩展到RL,理论论文。


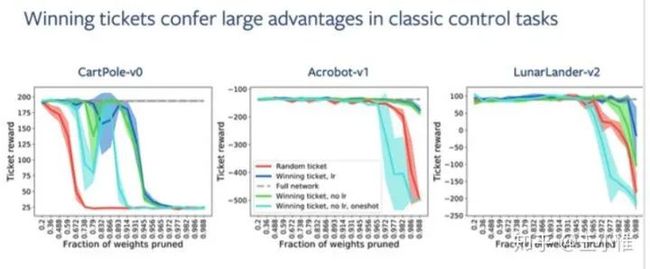


Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents
通过迭代来生成agent刚兴趣的输入(图片)进行达成RL agent的分析/测试。
首先是agent收集数据,然后在state空间上进行VAE的训练。然后定义了一系列直观的目标函数,并听过这些目标函数来做bp,直接找出(合成出)相应的state。比如:当前state下a1的Q值最高,然后我们的目标函数可是去压低这个a1对应的Q,那么找出来的state与原来的不同的地方,就是关键部分。

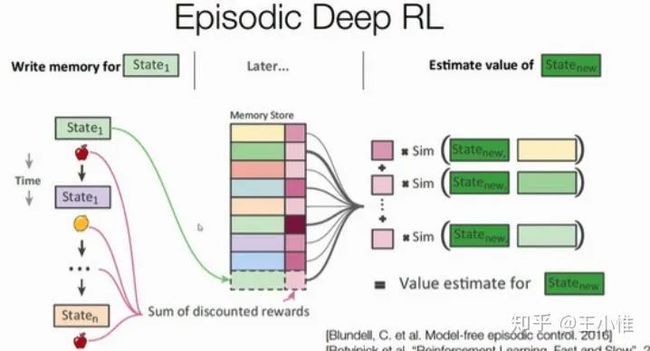
Episodic Reinforcement Learning with Associative Memory
简单而言,就是对buffer里面的trajectory进行拼接,从而间接搜索对于该状态的max return的后续trajectory,从而进行learning/Guidance。

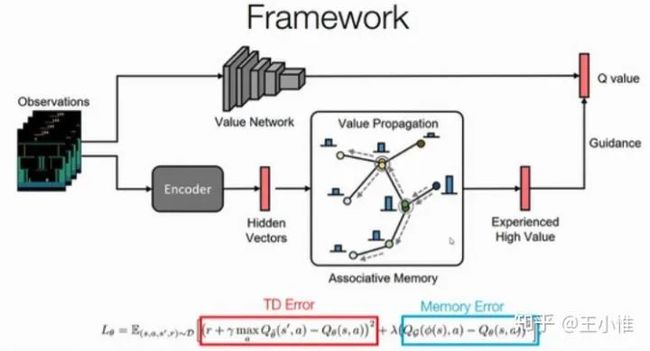
The Gambler's Problem and Beyond
理论文章




Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?
理论文章,“The authors challenge the idea that good representation in RL lead are sufficient for learning good policies with an interesting negative result -- they show that there exist MDPs which require an exponential number of samples to learn a near-optimal policy even if a good-but-not-perfect representation is given to the agent for both value-based and policy-based learning.”
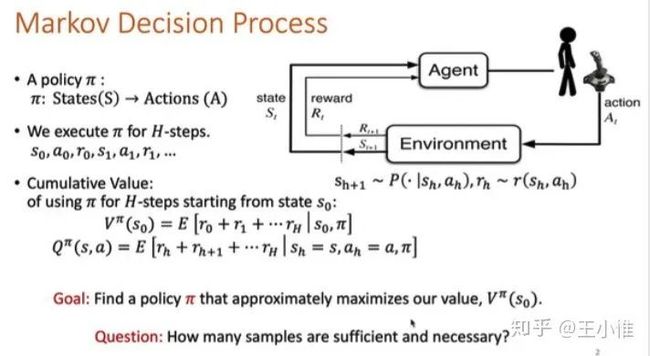






Geometric Insights into the Convergence of Nonlinear TD Learning
理论文章,“While there are convergence guarantees for temporal difference (TD) learning when using linear function approximators, the situation for nonlinear models is far less understood, and divergent examples are known. Here we take a first step towards extending theoretical convergence guarantees to TD learning with nonlinear function approximation.”



Q-learning with UCB Exploration is Sample Efficient for Infinite-Horizon MDP
理论论文,“In this paper, we adapt Q-learning with UCB-exploration bonus to infinite-horizon MDP with discounted rewards without accessing a generative model.”

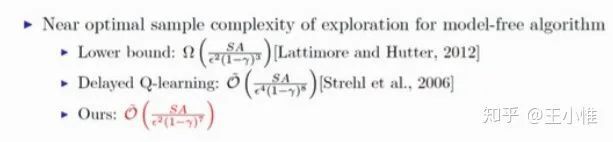
Disagreement-Regularized Imitation Learning
基于BC的基础上,提出一个考虑不确定的loss,从而使得模仿出来的策略一方面接近专家策略(专家数据),同时也避免专家策略(专家数据)不确定的action,从而提升BC的性能。
具体做法就是用ensemble的做法学习多个专家的策略,然后用这些策略间选择该action的概率的var作为衡量该action的不确定性。然后优化的时候,除了BC的loss外,额外loss约束为降低选择不确定高的action。
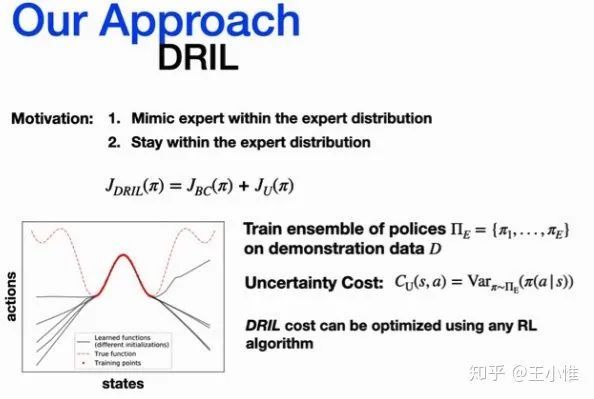

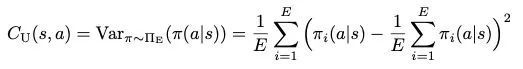
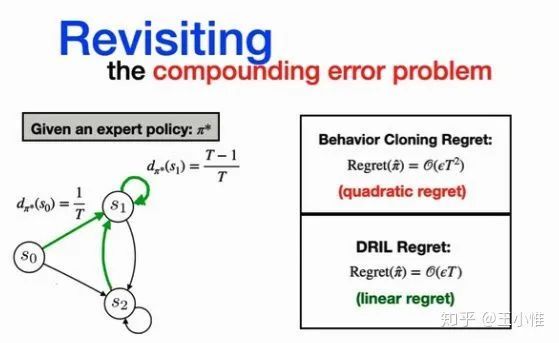

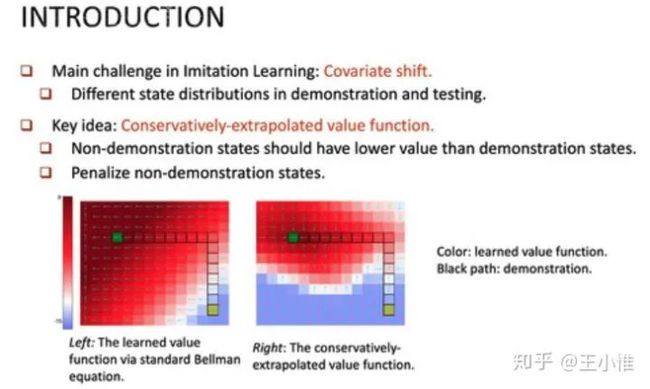
Learning Self-Correctable Policies and Value Functions from Demonstrations with Negative Sampling
在利用demonstrations的时候,作者认为随意的泛化到demonstrations外的state是一种不合理的行为(因为也不知道没有见过的state上的情况,从泛化的角度就是类似的state的value传过去),于是额外添加一个了压制没有见过state上的value的大小(实际实现就是加个perturb,然后约束这个perturb后的state的value比perturb前的state的value小,具体数值用state的距离来额外约束)。


Adversarial Policies: Attacking Deep Reinforcement Learning
考虑之前attack的话,一种主流做法就是attack observation,然后考虑说,修改observation的方式,在很多情况下不太现实。所以作者考虑训练一个policy来作为攻击者agent的策略,通过交互来引导agent们的state/observation转移到state/observation中学习不好的地方,甚至就是奇怪策略的state/observation空间去,从而达到自然的attack的效果。

重磅!DLer-强化学习交流群已成立!
欢迎各位RLer加入强化学习微信交流大群,本群旨在交流强化学习框架、策略梯度、DQN、理论推导与算法实现、前沿技术与顶会文章解读、应用场景等内容。更有求职内推、算法竞赛、资源干货、业界前沿资讯等,欢迎加群交流学习!
进群请备注:研究方向+学校/公司+昵称(如强化学习+上交+王明)
广告商、博主请绕道!

???? 长按识别,即可进群!