无需管理底层基础设施,亚马逊云科技向量数据库轻松创建ML增强的搜索体验和应用程序
当我们进入一家图书馆时,图书馆的入口处会有几台电脑供你检索相关的书籍,你可以检索你想要的书籍的名字例如:《百年孤独》、《悲惨世界》等等,你也可以检索作者例如:川端康成、鲁迅、加缪等等,当然你也可以检索分类,例如:历史、哲学、文学等等,这就是传统的关系型数据库,检索这样简单关系的数据是没有任何问题的。但当你只能记起书里的某个章节或者人物的某个特征而想检索到这本书时,你就无能为力了,甚至我们可以把视野放的更大一点,你想检索一段音频或者一张偶然拍下的花朵时,传统的关系型数据库恐怕对这样的要求就捉襟见肘了,也正是基于解决这样问题的要求,向量数据库应运而生。

那么什么是向量数据库?它的原理是怎么样的?又为什么说未来是向量数据库的天下呢?
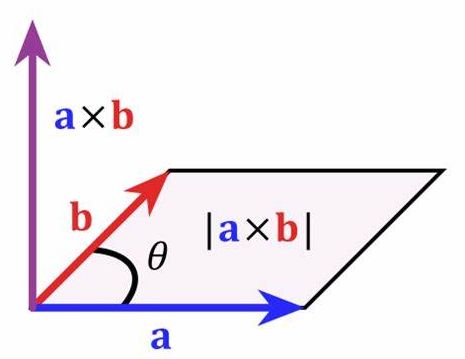
要想了解什么是向量数据库我们就必须得明白一个高中的数学知识:向量。在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过欧式距离、余弦距离等得到,这就是向量数据库运行的基本数学原理。
接下来就可以介入向量数据的元素了,前面举到的图书馆的示例只是将一群事物进行类别上标签的归类,但对于复杂的事物就难以简单地打标签了,而且想要进行更复杂的运算和检索过程就必须将一个具体的事物数据化。向量数据就是根据事物的各项特征进行向量得的赋予,例如我们想要在数据世界区别梅西和C罗,就可以从具体的特征出发比如身高、发色、鼻梁高低、眼睛大小、声音响度高低等等方面,赋予他们向量,就能发现两个人的区别。

而这种向量当赋予全球80多亿人时就会发现,每个人都不尽相同,而且给予向量的特征角度越多,那么数据就会越准确。这从数学理论方面建立了每个人的模型,利用这个模型,我们就能在二进制世界中建立另一个现实世界,这样我们就可以将一本小说、一首音乐、一段视频、一张照片数据化,这就是向量数据。
当我们想要检索某一事物时,只需要尽可能多的提供的某些特征,电脑就会将这些特征转化为向量,向量空间中会进行相似度计算和索引,而向量数据库可以实现高效的数据检索和分析,例如检索双胞胎中的某一个时,另一个就会最快出现。而当你检索一本小说中的某一桥段时,这本小说也会最快的被匹配到从而被检索出。

那么接下来就可以真正了解向量数据库了,向量数据库就是一种特殊类型的数据库,用于存储和索引向量数据。在传统数据库中,数据是以表格的形式进行组织和存储的,而向量数据库则专注于处理和查询向量数据,这些数据通常表示为多维数值数组。向量数据库的主要目的是支持高效的向量相似性搜索和查询。向量数据库广泛应用于人脸识别、图像搜索、视频分析、语音识别、推荐系统等领域。通过在向量空间中计算向量之间的距离和相似度,可以快速找到与目标向量最相似的数据对象,从而实现高效的搜索和匹配。值得注意的是,向量数据库主要适用于处理高维度的向量数据,而且在处理大规模数据集时通常能提供更高的查询性能和可扩展性。因此,在某些特定的应用场景下,向量数据库可以作为传统数据库的补充或替代选择。
之所以说未来是向量数据库的天下,是因为向量数据库让大模型有了"记忆"的功能,在初始的大语言模型中,世界知识和语义理解被压缩为静态参数,模型不会随着交互记住用户的聊天记录和喜好,也无法调用额外知识信息来辅助判断,因此模型只能根据历史训练数据回答问题,并且经常产生幻觉,给出与事实相悖的答案。也就是说大数据模型是一个计算力恐怖的大脑,但是这个大脑的记忆力奇差,而向量数据库就相当于给这个大脑装配上了海马体,让这个大脑真正的像人一样,能计算还能根据过去的记忆计算,从而使返回结果更精准,这也就是这几年AI科技发展速度奇快的原因之一。

2023年8月1日,亚马逊云科技推出了Amazon OpenSearch Serverless向量引擎预览版,为用户提供了一种简单、可扩展且高性能的相似性搜索功能,使用户能够轻松地创建现代化机器学习(ML)增强的搜索体验和生成式AI应用程序,同时无需管理底层的向量数据库基础设施。
那么Amazon OpenSearch Serverless向量引擎的优势又有哪些呢?
1、构建于Amazon OpenSearch Serverless的向量引擎天然具备鲁棒性(这个词挺抽象的,可以理解为系统更加稳健,性能更强)。因为亚马逊云科技向量引擎可自动调整资源,来适应不断变化的工作负载模式和需求,从而提供始终如一的快速性能和适当规模。用户也就不必担心后端基础设施的选型、调优和扩展问题。
2、Amazon OpenSearch Serverless向量引擎由开源OpenSearch项目中的k近邻(即kNN,可以理解为物以类聚算法,向量数据越接近越容易被检索)搜索功能提供支持,该功能能够提供可靠而精确的结果。简单来说,就是兼容了很多种算法,降低了复杂性,提升了可维护性,并且避免了数据重复、版本兼容性难题和许可问题,有效地简化了应用程序栈。
3、向量引擎支持不同领域的广泛用例,包括图像搜索、文档搜索、音乐检索、产品推荐、视频搜索、基于位置的搜索、欺诈检测以及异常检测。

在向量引擎正式版可用前,亚马逊云科技计划提供两项功能来降低客户使用向量引擎的成本。第一项功能是开发——测试选项,让用户可以在不创建备份或副本的情况下启动集合,从而减少了50%的入门成本。第二项功能是初始配置0.5个OCU资源,根据用户实际工作需要来扩展资源,这可以帮助用户进一步节约成本。除此之外,亚马逊云科技还将降低支持用户首个集合所需的最低OCU数量,从每小时4个降至每小时1个,以减少用户的成本支出。
总的来说,亚马逊云科技的向量引擎具有强大的性能和可扩展性,可以满足各种应用程序的需求。