python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
省流建议
本文针对以下需求:
- 想自动化标注一些目标
- 不再想使用yolo
- 想在目标检测/语意分割有所建树
- 计算机视觉项目
- 想玩一玩大模型
- 了解自动化工具
- 了解最前沿模型
- 自定义目标P图替换
- …

确定好需求,那么我们发车!
实现功能与结果
- 该模型将首先使用对语言的理解来识别文本提示中提到的对象。例如,在描述“两只用棍子的狗”中,该模型将“狗”和“棍子”一词识别为对象
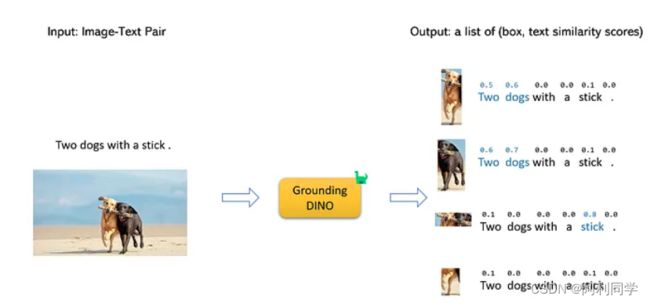
- 然后,该模型将为自然语言描述中确定的每个对象生成一组对象建议。对象建议是使用各种功能(例如对象的颜色,形状和纹理)生成的
- 接下来,模型返回每个对象建议的分数。分数是对象建议包含实际对象的可能性
- 然后,该模型将选择顶级对象建议作为最终检测。最终检测是图像中最自信的对象

我知道你对文字不感兴趣,你想直接拿代码来就用!
那么,它来了。
代码部署
在下一节中,我们将演示一个开放集对象目标检测。在这里,我们将使用一个预先训练的模型来检测’玻璃与盖子’(作为文本提示)通过摄像头饲料。
首先导入相关的库和 模块。代码的最后两行导入所需的推理模块。
import os
import cv2
import numpy as np
from PIL import Image
设置模型配置和权重文件路径
接下来,定义 模型配置文件和权重文件路径。除此之外,我们还定义了两个超参数框和图像阈值来控制对象框和图像的选择。默认情况下,模型输出900个对象框,这些对象框根据它们与输入文本的相似性得分进行排序。通过调整 max _ box 超参数,可以更改接地 DIN模型输出的对象框的数量。
HOME = os.getcwd()
# set model configuration file path
CONFIG_PATH = os.path.join(HOME, "groundingdino/config/GroundingDINO_SwinT_OGC.py")
# set model weight file ath
WEIGHTS_NAME = "groundingdino_swint_ogc.pth"
WEIGHTS_PATH = os.path.join(HOME, "weights", WEIGHTS_NAME)
# set text prompt
TEXT_PROMPT = "glass with lid"
# set box and text threshold values
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
检测
最后,我们使用 opencv 模块启动我们的摄像机 feed,并连续读取帧。在将摄像机提要传递给模型之前,我们需要对图像帧执行一些变换。首先,通过执行三个图像转换创建一个转换对象。
随机尺寸([800] ,max _ size = 1333)-此转换将图像的宽度调整为800,最大高度为1333像素。这有助于防止模型过度适应特定的尺寸。
ToTensor ()-这个转换将图像转换为一个 Python 张量。
正常化([0.485,0.456,0.406] ,[0.229,0.224,0.225])-这个转换通过减去平均值并除以 ImageNet 数据集的标准差来正常化图像。这有助于使模型对闪电和其他因素的变化更加稳健。
接下来,帧(相机帧的一个数字数组)被转换成 RGB 颜色空间中的 PIL 图像对象,最后通过执行上述三个转换转换成一个转换对象。
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# create a transform function by applying 3 image transaformations
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
# convert frame to a PIL object in RGB space
image_source = Image.fromarray(frame).convert("RGB")
# convert the PIL image object to a transform object
image_transformed, _ = transform(image_source, None)
# predict boxes, logits, phrases
boxes, logits, phrases = predict(
model=model,
image=image_transformed,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD,
device='cpu')
# annotate the image
annotated_frame = annotate(image_source=frame, boxes=boxes, logits=logits, phrases=phrases)
# display the output
out_frame = cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB)
cv2.imshow('frame', out_frame)
敲黑板 重点
自动化标注举例说明
你想获取图中熊这个目标

不是图片中所有的类别你都想要,你只想获取部分目标,那么你在定义时要如下操作:
需要将Text Prompt做替换 ,如你只想对图片中的熊感兴趣:
则Text Prompt=bear.

对应生成的label/json文件
"shapes": [
{
"label": "dog",
"points": [
[
20.913907284768214,
26.47019867549669
],
[
87.96688741721854,
97.66225165562913
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
},
{
"label": "cat",
"points": [
[
91.11258278145695,
43.35761589403974
],
[
131.50993377483442,
84.91390728476821
]
],
如果对大海和熊感兴趣,则:
Text Prompt=bear,sea
注意 逗号间隔!
自动化P图
如下我们可以选择将图中的目标狂替换为我们想要的目标!

可以说做到了完美贴合P图 ,再也不用PS工具费时费力修图啦
代码获取
code get:见博客底部推广