MySQL数据库基础知识回顾
目录
MySQL介绍
了解MySQL
特征:
MySQL 基础知识
1.SQL语句的划分
2.MySQL数据类型
(1)数值类型
(2)日期/时间类型
(3)字符串类型
a.文本数据类型
b.二进制类型数据
关系的基本概念
关系的基本特点
数据库范式
第一范式(1NF):每一列保持原子特性
第二范式(2NF):属性完全依赖于主键(针对联合主键)
第三范式(3NF):属性不依赖于其他非主属性
MySQL介绍
了解MySQL
MySQL分为企业版和社区版,社区版是完全免费开源的;
MySQL属于关系型数据库,和其他的关系型数据库最大的区别在于支持可插拔式的存储引擎,其中InNoDB非常强大.
特征:
- 其体积小、速度快、总体拥有成本低,且开放源码;
- 可移植性(跨平台):MySQL可以在绝大多数的操作系统中运行,易于使用和管理。
- 是一个轻量级数据库
MySQL 基础知识
1.SQL语句的划分
(1)DDL(Data definition Language):数据定义语言,DDL语言是定义不同的 数据库、表、 列等数据库对象的定义,常见的语句关键字包括create(创建)、drop(删除)、alter(修改)等。
注:对表进行操作
(2)DML(Data Manipulation Language):数据操纵语言,用于添加、删除、修改和查询数据库记录,常用的关键字包括insert、delete、update和select等。
注:对表中的数据进行操作
(3)DCL(Data Control Language)数据控制语言,用户控制不同数据段直接的许可或访问级别的语句,定义了数据库、表、字段的用户访问权限和安全级别,主要的语句包括grant,remove。
2.MySQL数据类型
数据类型是规定了数据的大小,因此使用时需要选择合适的类型,不仅会降低表占用的磁盘空间,间接减少磁盘IO次数。表的访问效率和设计的表结构的数据类型息息相关
MySQL中提供了多种的数据类型,包括整数类型,浮点类型,定点类型,日期和时间类型,字符串和二进制类型;
归纳数据类型分为三类:数值类型, 日期和时间类型 , 字符串类型
(1)数值类型
包括定点类型、浮点类型和整数类型

整型中,如果没有指定具体的类型,就默认指定为int类型;
小数类型:默认decimal
decimal(M,D)参数含义:decimal(总长度,小数位)
例如:decimal(5,2)要求传过来的数据总长度是5位,小数位是两位,则该数据可以是:123.45、999.99.......
(2)日期/时间类型

默认的时间类型为datetime;
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
(3)字符串类型
a.文本数据类型
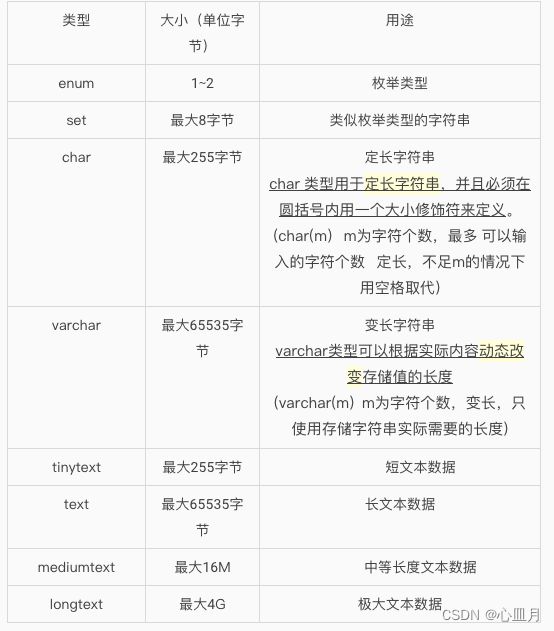
char(字符串长度)和varchar(字符串长度)的区别:
- char是定长的,varchar是变长的;如果char存入的数据长度小于定义的长度时,则用空格填充;如果varchar存入的数据小于定义的长度时,就按照实际长度存储。
例如:定义一个char(10)和varchar(10),如果存进去的是'ABC',则还剩下7个字符的空间;
在char中,剩余的空间不会被释放,系统会用空格填充,那么char所占的长度依然为10;而vachar的长度变为3了,剩余的空间会被释放出来。
- char的存取速度比varchar快得多,因为其长度固定,方便程序的存储与查找。
b.二进制类型数据
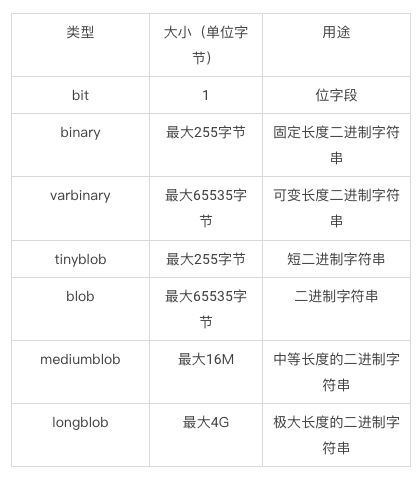
选择数据类型时:尽量选择可以保证数据正确存储的最小数据类型,小的数据类型占用空间少,操作起来更快 .
关系的基本概念
关系:一个关系就是一张二维表,通常将一个没有重复行、重复列的二维表看成一个关系,每个关系都有一个关系名。
实体:现实世界中客观存在并可以被区别对待的事务,比如“一个学生”,“一门课”等
属性:实体具有的某一特征。比如:性别是人的一个属性,在关系型数据库中,属性又是个物理概念,属性可以看做是“表的一列”
元组:表中的一行就是一个元组
分量:元组中某个属性值。在一个关系型数据库中,是一个操作原子,即关系型数据库在做任何操作的时候,属性是不可分的,否则就不是关系型数据库
码:表中可以唯一来确定一个元组的某个属性,如果这个码不止一个,那么都叫候选码,从中挑选的一个就叫做主码
全码:如果一个码包含所有的属性,这个码称之为全码
主属性(主键):一个属性只要在一个候选码中出现过,这个属性就是主属性
非主属性(非主键):与主属性相反,没有在任何候选码中出现过,这个属性就是非主属性
外码:一个属性(或者属性组),他不是码,但是他是别的表的码,他就是外码
关系的基本特点
在关系模型中,关系具有以下基本特点:
①关系必须规范化,属性不可再分割。
②在同一关系中不允许出现相同的属性名。
③在同一关系中元组的顺序可以任意。
④在同一关系中属性的顺序可以任意。
数据库范式
关系模式要满足的条件称为规范化形式,简称范式(NF)。
关系模型规范化的目的是为了消除存储异常,减少数据冗余,保证数据的完整性和存储效率,一般规范为3NF即可。
第一范式(1NF):每一列保持原子特性
如果关系R的所有属性均为简单属性,即每个属性都不可再进行分割,则称R满足第一范式。
【关系R:指的是关系表,表的名称为R】
简单来说:第一范式就是表中无重复的列.
注意:不符合第一范式不能称之为关系型数据库。
示例:
用户表(用户id,用户姓名,省份证,用户地址);
地址信息,可以细分为省、市、区等不可拆分字段,所以用户表示不具有原子特性,不满足第一范式
因此需要拆分:
用户表:(用户id,用户姓名,省份证,省,市,区)
第二范式(2NF):属性完全依赖于主键(针对联合主键)
如果关系R满足第一范式,且每一个非主键字段完全依赖于主键,则称R满足第二范式。
(非主属性完全依赖于主关键字,如果不能依赖主键,应该拆分成新的主体,设计成一对多的关系)
示例1:
学生:Student(学号,姓名,年龄);
学号是主键,姓名和年龄就完全依赖于主键。
示例2:选课表(学号,姓名,年龄,课程名称,成绩,学分);
将“学号,课程名称”声明为联合主键
联合主键:指的是把两个属性看成一个整体,这个整体不能为空,且是唯一的,不能重复
姓名-》联合主键 =》部分依赖(姓名依赖于学号,不依赖于课程名称)
年龄-》联合主键 =》部分依赖(年龄依赖于学号,不依赖于课程名称)
成绩-》联合主键 =》完全依赖
学分-》联合主键 =》部分依赖(学分依赖于课程名称,不依赖于学号)
不满足第二范式,因此对选课表进行拆分:
学生表(学号,姓名,年龄)
课程学分表(课程名称,学分)
学生成绩表(学号,课程名称,成绩)
第三范式(3NF):属性不依赖于其他非主属性
如果关系R满足第二范式,且非主键字段之间不存在依赖关系,则称R满足第三范式。
注:一个基本的关系型数据库是要满足第一范式,一个完整的的关系型数据库必须要满足第三范式。
示例:
学生表(学号,姓名,年龄,学院名称,学院地点,学院电话);
主键:学号,
姓名,年龄,学院名称是完全依赖于主键;
而学院电话、学院地点依赖与学院名称,并不依赖于主键学号
因此该设计不符合第三范式,就应该进行拆分,将 学院专门设计成一张表;
拆分成:
学生表(学号、姓名、年龄、学院名称)=》主键是学号
学院表(学院名称、学院地址、学院电话)=》主键是:学院名称