2、数仓理论概述与相关概念
1、问:数据仓库 建设过程中 经常会遇到那些问题?
模型(逻辑)重复建设
数据不一致性
维度不一致:命名、维度属性值、维度定义
指标不一致:命名、计算口径
数据不规范(字段命名、表名、分层、主题命名规范)
2、OneData数据建设核心方法论?

3、OneData数据建设体系架构?
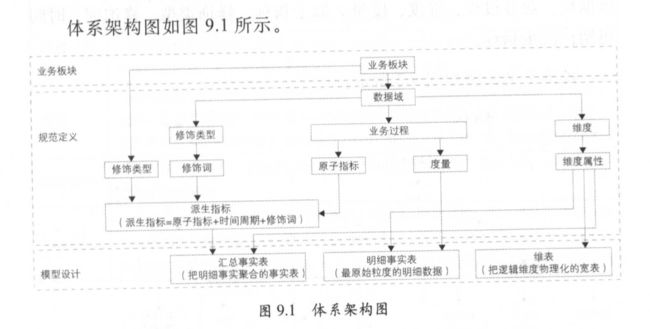
4、数据仓库中经常用到的概念?
4.1 什么是 业务过程?
是企业活动中一个个不可拆分的行为事件,如 下单、支付、退款都是业务过程
4.2 什么是 数据域/主题域?
指定是 将业务过程或者维度进行抽象的集合
为保证数仓的稳定性,数据域需要抽象提炼,并且长期维护和更新,但不轻易变动。
4.3 什么是 度量/原子指标?
原子指标和度量含义相同,是基于某个业务过程下的度量值,表示不可再拆分的指标
经常以数值的形式出现,具有明确的业务含义的名称,如支付金额
4.4 什么是 修饰词?
业务过程中对业务场景限定的抽象(除维度以外),例如 流量域中有修饰词 PC端、APP端
4.5 什么是 修饰类型?
对修饰词抽象划分,修饰类型从属于某个业务域
如流量域中有访问终端类型,该类型下有 PC端、移动端
4.6 什么是 维度?
维度是业务过程中度量的环境,也可以称为实体对象
4.7 什么是 维度属性?
维度属性隶属于一个维度,是维度的组成部分
如 地理维度包含(国家、地区、省份、城市等级等属性)
4.8 什么是 时间周期?
用来明确数据统计的时间范围或者时间点,如最近30天、自然周、历史至今
4.9 什么是 派生指标?
派生指标 = 一个原子指标 + 修饰词(可选多个) + 时间周期
可以理解为 对原子指标按照业务统计范围的圈定
例如:原子指标:支付金额
派生指标:最近1天海外买家的支付金额
(最近一天为时间周期、海外为修饰词、买家为维度)
5、指标体系的构成是什么?
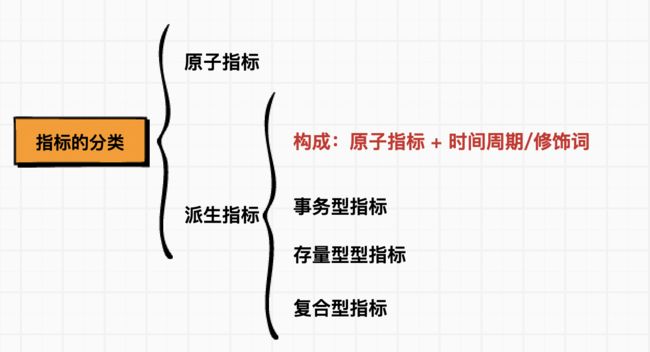
原子指标:
含义:某个业务过程中不可拆分的度量
构成:动作 + 度量
示例:支付金额、借款金额
派生指标:
含义:将原子指标按照业务范围的圈定(聚合)
构成:多个修饰词(可选) + 时间周期 + 原子指标
示例:最近一天海外买家的支付金额
派生指标分类:
事务型指标、存量型指标、复合型指标
事务型指标:
含义:对某个业务活动进行衡量的指标
示例:订单支付金额、新增会员数
存量型指标:
含义:对实体对象(如商品、会员)某些状态的统计
示例:商品总数、注册会员数
复合型指标:
含义:在 事务型指标和存量型指标的基础上复合而成
示例:流量UV-下单买家数的转化率
6、数仓中模型设计时的指导理论?
设计数据模型时,主要以维度建模为理论基础,基于维度数据模型总线架构,构建一致性的维度和一致性的事实。
7、问:数据仓库为什么要分层设计(分层的好处)?
分层能够使数据有秩序的流转,数据的生命周期能够清晰的被数仓开发人员和使用人员感知到
数据结构清晰:
每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
减少重复开发:
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
统一数据口径:
通过数据分层,提供统一的数据出口,统一对外输出的数据口径
复杂问题简单化:
将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
通过构建全域的公共层数据,极大地控制了数据规模的增长,同时也能提高数据研发的效率
,解约成本,提高性能。
8、问:数据仓库应该如何分层?
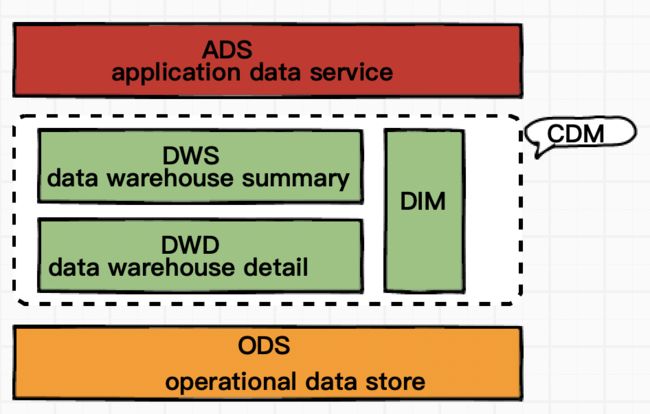
ODS_数据操作层:
存储数据特点:各个业务系统的原始数据、日志数据、第三方数据
数据加工方式:几乎无处理(基础清洗数据)
作用:数据同步(增量、全量),清洗,保存历史
CDM_公共维度模型层:
存储数据特点:存放明细事实数据、维度数据、公共指标汇总数据
细分: DWD、DWS
作用:提升公共指标的复用性,减少重复加工
DWD_明细数据层:
存储数据特点:存放明细事实数据
数据加工方式:
以维度建模为理论基础,将业务相同或相似且粒度相同的数据放到同一个模型中
采用维度退化的手段,来构建明细宽表,基于ODS和DIM表加工而成
作用:
1、整合业务相同或相似数据:
构建明细宽表,复用关联计算,减少数据扫描(DWD)
2、公共指标统一加工:
基于 OneData体系构建 命名规范、口径统一、算法统一的统计指标
为上层数据产品、应用、服务提供公共指标,并建立汇总宽表
3、构建一致性维度:
建立一致性的维表,降低多维度分析时计算口径、算法不统一的风险
DWS_汇总数据层:
存储数据特点:公共指标汇总数据
数据加工方式:
加强指标的维度退化,采用宽表化手段,构建公共指标数据层
常基于DWD和DIM表加工而成
作用:
存放公共指标汇总数据,构建公共指标宽表,提升公共指标的复用性、减少重复加工
ADS_应用数据层:
存储数据特点:存储个性化的统计指标数据
作用:计算个性化的指标(没有公用性,复杂)、基于应用的数据组装(跨主体构建宽表)
9、问:下游使用数仓模型时,应该遵循哪些原则?
优先使用公共维度模型层(CDM)数据,当公共层没有数据时,需要评估是否需要创建公共层数据,当不需要建设公共层数据时,方可直接使用操作数据层数据(ODS)