JavaSE-12 【集合】
文章目录
- JavaSE-12 【集合】
- 第一章、Java集合
- 第二章、Collection介绍
-
- 2.1 Connection是什么:
- 2.2 集合与数组的区别
- 2.3 Collection的功能
- 2.4 Collection和Map的继承体系结构
- 2.5 Collection常用API
- 2.6 Collection的API案例
- 第三章、List集合
-
- 3.1 ArrayList集合
- 3.2 LinkList 集合
- 3.3 ArrayList和LinkList的区别
- 3.4 List的遍历方式
- 第四章、Set集合
-
- 4.1 HashSet
- 4.2 常用API
- 第五章、Map
-
- 5.1 Map集合概述
- 5.2 Map常用的子类
- 5.3 Map接口中的常用方法
- 5.4 Map集合遍历---键找值方式
- 5.5 Entry键值对对象
- 5.6 Map集合遍历---键值对方式
- 5.7 HashMap存储自定义类型键值
- 5.8 LinkedHashMap
- 5.9 HashMap和HashTable的区别
JavaSE-12 【集合】
第一章、Java集合
1、Java集合就像一个容器
- 可以存储任何类型的数据,
- 可以结合泛型来存储具体的类型对象。
- 在程序运行时,Java集合可以动态的进行扩展,随着元素的增加而扩大。
2、Java中,集合类通常存在于java.util包中
3、Java集合主要由2大体系构成
- 分别是Collection体系和Map体系
- 其中Collection和Map分别是2大体系中的顶层接口
4、Collection主要有三个子接口
-
分别为List(列表)、Set(集)、Queue(队列)。其中,List、Queue中的元素有序可重复,而Set中的元素无序不可重复
-
List中主要有ArrayList、LinkedList两个实现类;
-
Set中则是有HashSet实现类
-
Queue是在JDK1.5后才出现的新集合,主要以数组和链表两种形式存在
5、Map同属于java.util包中,是集合的一部分:但与Collection是相互独立的,没有任何关系
- Map中都是以key-value的形式存在
- 其中key必须唯一,key可以为空,value可以为空,可重复
- 主要有HashMap、HashTable、treeMap三个实现类
第二章、Collection介绍
2.1 Connection是什么:
Java是一门面向对象的语言,为了方便操作多个对象,想要存储多个对象(变量),需要一个容器,那就是collection
常用容器
- 常用的容器有:StringBuffered,StringBuilder,数组。
- 但是由于数组的长度固定;访问方式单一,只能用下标,
- 删除数据,数据不连续,需要往前移动数据
- 插入数据,数据要向后移动,这些缺点
- 所以,java就为我们提供了集合(Collection)
2.2 集合与数组的区别
长度的区别:数组的长度固定;集合的长度可变
内容的区别:数组存储的是同一种类型的元素,集合可以存储不同类型的元素(一般不这样做)
元素的数据类型:数组可以存储基本数据类型,和引用类型。集合只能存储引用类型(若是简单的int,它会自动装箱成Integer)
2.3 Collection的功能
集合可以存储多个元素,但对多个元素也有不同的需求
- 多个元素,不能有相同的
- 多个元素,能够按照某个规则排序
针对不同的需求:java就提供了很多集合类,多个集合类的数据机构不同,但是,数据结构不重要,重要的是能够存储东西,能够判断,获取。把集合共性的内容不断往上提取,最终形成集合的继承体系———Collection
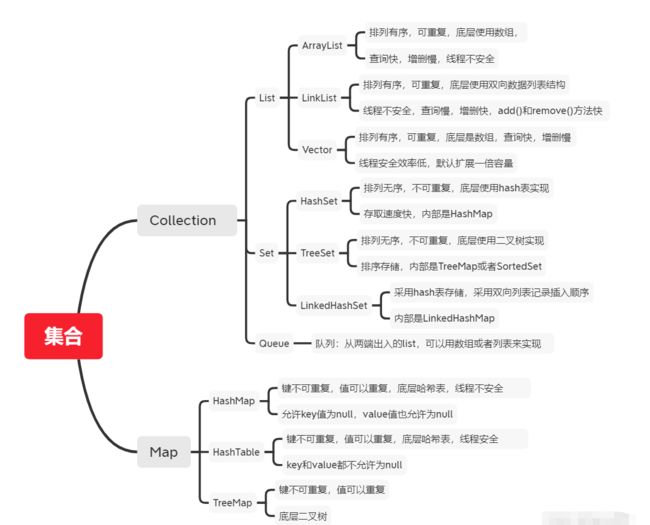
2.4 Collection和Map的继承体系结构
(4接口,9个类)
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tva4fYnE-1687769946090)(photo/JavaSE12_集合.assest/71c86975efae47bbaecce40bc005638a.png)\]](https://img-blog.csdnimg.cn/8a5d1b17c6c6451383edbce0b43c2f49.png)
2.5 Collection常用API
添加功能:
boolean add(Object obj) 添加一个元素
boolean addAll(Collection c) 添加一个集合元素
获取功能:
Iterator<E> iterator() 迭代器
int size() 获取元素的个数即集合的长度
Object[] toArray() 将集合转为数组
删除功能:
void clear() 移除所有元素
boolean remove(Object) 移除一个元素
boolean removeAll(Collection c) 移除一个集合的元素,只要一个元素被移除课就返回true
判断功能:
boolean contains(Object o) 判断集合是否包含该元素
boolean containsAll(Collection c) 判断集合中是否包含指定的集合元素,只有包含所有的元素才叫包含
boolean isEmpty() 判断集合是否为空
交集功能:
boolean retainAll(Collection c)
移除此collection中未包含在指定collection中的所有元素
即:集合A和集合B做交集,最终的结果会保存在集合A,返回值表示的是集合A是否发生过变化
2.6 Collection的API案例
package com.zzy.collection;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Iterator;
/**
* 测试Collection集合
*/
public class TestCollection {
public static void main(String[] args) {
Collection<Integer> c1 = new ArrayList<>();
//1 添加元素
c1.add(1);
c1.add(2);
c1.add(3);
c1.add(4);
c1.add(5);
c1.add(6);
c1.add(7);
c1.add(8);
c1.add(1024);
//2 删除元素
c1.remove(1024);
//3 获取长度
int size = c1.size();
System.out.println("集合长度是: "+size);
// 4 判断是否为空
boolean empty = c1.isEmpty();
System.out.println("集合为空否: "+empty);
//5 集合转数组
Object[] toArray = c1.toArray();
System.out.println("集合转数组后的结果是: "+ Arrays.toString(toArray));
//6 遍历集合iterator()
Iterator<Integer> iterator = c1.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("-------------------");
Collection<String> c2 = new ArrayList<>();
c2.add("A");
c2.add("B");
c2.add("C");
//7 判断集合是否包含元素 A
boolean a = c2.contains("A");
System.out.println("包含与否"+a);
Collection<String> c3 = new ArrayList<>();
c3.add("孙悟空");
c3.add("猪八戒");
c3.add("沙和尚");
c3.add("白龙马");
//8 清空集合
c3.clear();
System.out.println(c3.toString());
/*
addAll(Collection c) 添加一个集合元素
removeAll(Collection c)
移除一个集合的元素,只要一个元素被移除就返回true
containsAll(Collection c)
判断集合中是否包含指定的集合元素,只有包含所有的元素才叫包含
retainAll(Collection c)
移除此collection中未包含在指定collection中的所有元素
即:集合A和集合B做交集,最终的结果会保存在集合A,
返回值表示的是集合A是否发生过变化
*/
Collection<String> c5 = new ArrayList<>();
Collection<String> c6 = new ArrayList<>();
Collection<String> c7 = new ArrayList<>();
Collection<String> c8 = new ArrayList<>();
c5.add("AA");
c5.add("BB");
c6.add("北京");
c6.add("成都");
c6.add("重庆");
c6.add("福州");
c7.add("福州");
c8.add("北京");
c8.add("成都");
c8.add("重庆");
//添加一个集合元素
c5.addAll(c6);
System.out.println(c5.toString());
//移除一个集合的元素
System.out.println("移除成功与否:"+c5.removeAll(c7));
System.out.println(c5.toString());
//判断集合中是否包含指定的集合元素
System.out.println("判断集合中是否包含是定集合元素:"+c5.containsAll(c8));
Collection<String> c11 = new ArrayList<>();
Collection<String> c12 = new ArrayList<>();
c11.add("AA队");
c11.add("BB队");
c11.add("CC队");
c11.add("DD队");
c12.add("AA队");
c12.add("BB队");
c12.add("FF队");
//移除此collection中未包含在指定collection中的所有元素
System.out.println("C11是否发生变化:"+c11.retainAll(c12));
System.out.println(c11.toString());
System.out.println("C12是否发生变化:"+c12.retainAll(c11));
System.out.println(c12.toString());
}
}
第三章、List集合
在Collection中,List集合是有序的,可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素
在List集合中,我们常用到ArrayList和LinkedList这两个类。
3.1 ArrayList集合
1 介绍:
- 底层通过数组实现,随着元素的增加而动态扩容
- ArrayList默认构造的容量为10,默认扩容1.5倍,新容量 = 旧容量 * 1.5
- Java集合框架中使用最多的一个类,是一个数组队列,线程不安全集合。
2 特点
- 容量不固定,随着容量的增加而动态扩容的有序集合
- 插入的元素可以为null
- 增删改查效率更高(相对于LinkedList来说)
- 线程不安全
3 功能
- ArrayList实现List,得到了List集合框架基础功能;
- ArrayList实现RandomAccess,获得了快速随机访问存储元素的功能,RandomAccess是一个标记接口,没有任何方法;
- ArrayList实现Cloneable,得到了clone()方法,可以实现克隆功能;
- ArrayList实现Serializable,表示可以被序列化,通过序列化去传输,
4 常用API
添加功能
boolean add(E e):向集合中添加一个元素
void add(int index, E element):在指定位置添加元素
boolean addAll(Collection<? extends E> c):
向集合中添加一个集合的元素。
删除功能
void clear():删除集合中的所有元素
E remove(int index):
根据指定索引删除元素,并把删除的元素返回
boolean remove(Object o):从集合中删除指定的元素
boolean removeAll(Collection<?> c):
从集合中删除一个指定的集合元素。
修改功能
E set(int index, E element):
把指定索引位置的元素修改为指定的值,返回修改前的值。
获取功能
E get(int index):获取指定位置的元素
Iterator iterator():就是用来获取集合中每一个元素。
判断功能
boolean isEmpty():判断集合是否为空。
boolean contains(Object o):判断集合中是否存在指定元素
boolean containsAll(Collection<?> c):
判断集合中是否存在指定的一个集合中的元素。
长度功能
int size():获取集合中的元素个数
把集合转换成数组
Object[] toArray():把集合变成数组。
LinkedList特有的:
E getFirst() 获取集合中的第一个元素并返回
E getLast() 获取集合的最后一个元素并返回
5 案例
/**
* 测试ArrayList集合案例
*/
public class Test2_ArrayList {
public static void main(String[] args) {
//创建ArrayList集合
List<String> list1 = new ArrayList<>();
/*
添加功能
boolean add(E e):向集合中添加一个元素
void add(int index, E element):在指定位置添加元素
boolean addAll(Collection c):
向集合中添加一个集合的元素。
*/
list1.add("悟空");
list1.add("八戒");
list1.add("沙僧");
list1.add("小白龙");
System.out.println(list1.toString());
list1.add(2,"白骨精");
System.out.println(list1.toString());
System.out.println("--------------------------");
/*
删除功能
void clear():删除集合中的所有元素
E remove(int index):
根据指定索引删除元素,并把删除的元素返回
boolean remove(Object o):从集合中删除指定的元素
boolean removeAll(Collection c):
从集合中删除一个指定的集合元素。
*/
List<String> list2 = new ArrayList<>();
list2.add("赵四");
list2.add("刘能");
list2.add("赵德汉");
list2.add("达康书记");
list2.remove(3);
list2.remove("刘能");
System.out.println(list2.toString());
list2.clear();
System.out.println(list2.toString());
System.out.println("--------------------------");
/*
修改功能
E set(int index, E element):
把指定索引位置的元素修改为指定的值,返回修改前的值。
获取功能
E get(int index):获取指定位置的元素
Iterator iterator():就是用来获取集合中每一个元素。
*/
List<String> list3 = new ArrayList<>();
list3.add("新疆");
list3.add("西藏");
list3.add("甘肃");
list3.add("四川");
System.out.println(list3.toString());
list3.set(3, "青海");
System.out.println(list3.toString());
System.out.println(list3.get(1));
System.out.println("----------------");
/*
判断功能
boolean isEmpty():判断集合是否为空。
boolean contains(Object o):判断集合中是否存在指定元素
boolean containsAll(Collection c):
判断集合中是否存在指定的一个集合中的元素。
长度功能
int size():获取集合中的元素个数
把集合转换成数组
Object[] toArray():把集合变成数组。
*/
List<Integer> list4 = new ArrayList<>();
list4.add(1);
list4.add(2);
list4.add(3);
list4.add(4);
list4.add(5);
System.out.println(list4.size());
System.out.println(list4.isEmpty());
System.out.println(list4.contains(5));
Object[] toArray = list4.toArray();
System.out.println(Arrays.toString(toArray));
}
}
3.2 LinkList 集合
1 介绍
- 底层通过链表来实现,随着元素的增加不断向链表的后端增加节点
- LinkedList是一个双向链表,每一个节点都拥有指向前后节点的引用。相比于ArrayList来说,LinkedList的随机访问效率更低。
2 功能
- LinkedList实现List,得到了List集合框架基础功能;
- LinkedList实现Deque,Deque 是一个双向队列,既可以先入先出,又可以先入后出,既可以在头部添加元素,也可以在尾部添加元素;
- LinkedList实现Cloneable,得到了clone()方法,可以实现克隆功能;
- LinkedList实现Serializable,表示可以被序列化,通过序列化去传输,
3 常用API
- 与ArrayList相同,见上
4 案例
/**
* 测试LinkedList集合案例
*/
public class Test3_LinkedList {
public static void main(String[] args) {
//创建LinkedList集合
LinkedList<String> list1 = new LinkedList<>();
/*
添加功能
boolean add(E e):向集合中添加一个元素
void add(int index, E element):在指定位置添加元素
boolean addAll(Collection c):
向集合中添加一个集合的元素。
*/
list1.add("悟空");
list1.add("八戒");
list1.add("沙僧");
list1.add("小白龙");
System.out.println(list1.toString());
list1.add(2,"白骨精");
System.out.println(list1.toString());
System.out.println("--------------------------");
/*
删除功能
void clear():删除集合中的所有元素
E remove(int index):
根据指定索引删除元素,并把删除的元素返回
boolean remove(Object o):从集合中删除指定的元素
boolean removeAll(Collection c):
从集合中删除一个指定的集合元素。
*/
LinkedList<String> list2 = new LinkedList<>();
list2.add("赵四");
list2.add("刘能");
list2.add("赵德汉");
list2.add("达康书记");
list2.remove(3);
list2.remove("刘能");
System.out.println(list2.toString());
list2.clear();
System.out.println(list2.toString());
System.out.println("--------------------------");
/*
修改功能
E set(int index, E element):
把指定索引位置的元素修改为指定的值,返回修改前的值。
获取功能
E get(int index):获取指定位置的元素
Iterator iterator():就是用来获取集合中每一个元素。
*/
LinkedList<String> list3 = new LinkedList<>();
list3.add("新疆");
list3.add("西藏");
list3.add("甘肃");
list3.add("四川");
System.out.println(list3.toString());
list3.set(3, "青海");
System.out.println(list3.toString());
System.out.println(list3.get(1));
System.out.println("----------------");
/*
判断功能
boolean isEmpty():判断集合是否为空。
boolean contains(Object o):判断集合中是否存在指定元素
boolean containsAll(Collection c):
判断集合中是否存在指定的一个集合中的元素。
长度功能
int size():获取集合中的元素个数
把集合转换成数组
Object[] toArray():把集合变成数组。
*/
LinkedList<Integer> list4 = new LinkedList<>();
list4.add(1);
list4.add(2);
list4.add(3);
list4.add(4);
list4.add(5);
System.out.println(list4.size());
System.out.println(list4.isEmpty());
System.out.println(list4.contains(5));
Object[] toArray = list4.toArray();
System.out.println(Arrays.toString(toArray));
/*
通过制定下标的位置获取对应的元素
获取集合的第一个元素
获取集合的最后一个元素
*/
System.out.println(list4.get(2));
System.out.println(list4.getFirst());
System.out.println(list4.getLast());
}
}
3.3 ArrayList和LinkList的区别
- ArrayList是实现了基于动态数组的数据结构,
- LinkedList是基于链表结构。
- 对于随机访问的get和set方法,
ArrayList要优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,
LinkedList比较占优势,因为ArrayList要移动数据。
3.4 List的遍历方式
- 普通for循环
- 加强for循环–foreach
- 普通迭代器
- 列表迭代器
- Lambda表达式遍历集合-----Iterable的forEach()方法 (JDK8新增)
1 案例
/**
* 集合遍历的方式
*/
public class Test4_forList {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("AA");
list.add("BB");
list.add("CC");
list.add("DD");
list.add("EE");
list.add("FF");
//方式一:普通for循环
for (int i=0;i<list.size();i++){
System.out.println(list.get(i));
}
System.out.println("-------------------");
//方式二:加强for循环
for (String s:list) {
System.out.println(s);
}
System.out.println("-------------------");
//方式三:普通迭代器
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("-------------------");
//方式四:列表迭代器
ListIterator<String> stringListIterator = list.listIterator();
while (stringListIterator.hasNext()){
System.out.println(stringListIterator.next());
}
System.out.println("-------------------");
//方式五:Lambda表达式遍历集合
list.forEach(s->System.out.println("集合元素是:"+s));
}
}
2 iterator与listIterator的区别(了解)
- ListIterator 继承自 Iterator 接口
- Iterator 只能单向遍历;ListIterator 可双向遍历(向前/后遍历)
- Iterator 可遍历 Set 和 List 集合;ListIterator 只能遍历 List。
- ListIterator有add()方法,可以向List中添加对象,而Iterator不能。
- ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法。可以实现逆向(顺序向前)遍历。Iterator就不可以。
- ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现,Iterator没有此功能。
- 都可实现删除对象,但是ListIterator可以实现对象的修改,
第四章、Set集合
1、介绍
- set是按照一定的次序存储元素的容器
- 在set中,每个value必须是唯一的
- set允许插入和删除,不允许修改
- set在底层用二叉搜索树(红黑树)实现
特点
- set中只放value,但是底层存放的是的键值对
- set插入元素只需要插入value即可,set中的元素唯一
- set遍历后有序,默认按照小于排序
- set中的元素不允许修改
- set的底层使用二叉搜索树(红黑树)实现
4.1 HashSet
1、介绍
- 是存在于java.util包中的类 。同时也被称为集合,
- 该容器中只能存储不重复的对象。底层是由HashMap来存储的
- HashSet不能重复的原因是,HashMap的键不能重复
2 特点
- HashSet是set接口的实现类,也是最常用的set集合
- 储存的是无序,唯一的对象。遍历可能是有序,可能是无序的
- 由于是无序的所以每组数据都没有索引,很多list可用的方法它都没有
- 凡是需要通过索引来进行操作的方法都没有,所以也不能使用普通for循环来进行遍历,只有加强型for和迭代器两种遍历方法
- HashSet的元素不能重复,HashSet中允许有NULL值
4.2 常用API
1 HashSet常用API
boolean add(E e) 添加元素
boolean remove(Object o) 删除元素
void clear( 删除所有元素
boolean contains(Object o) 是否包含指定元素
boolean isEmpty()是否为空
int size() 集合长度
2 HashSet的遍历:
方式一:加强for循环,即foreach
方式二:迭代器
1 案例
/**
* 测试HashSet的API案例
*/
public class Test5_HashSet {
public static void main(String[] args) {
HashSet<String> hashSet1 = new HashSet<>();
//添加
hashSet1.add("AA");
hashSet1.add("BB");
hashSet1.add("CC");
hashSet1.add("DD");
hashSet1.add("EE");
//删除
hashSet1.remove("CC");
System.out.println(hashSet1);
//是否为空
System.out.println(hashSet1.isEmpty());
//集合长度
System.out.println(hashSet1.size());
//是否包含指定元素
System.out.println(hashSet1.contains("BB"));
//Hash的遍历
HashSet<Integer> hashSet2 = new HashSet<>();
hashSet2.add(1);
hashSet2.add(2);
hashSet2.add(3);
hashSet2.add(4);
hashSet2.add(5);
//方式一、foreach
for (Integer h:hashSet2) {
System.out.println(h);
}
//方式二:普通迭代器
Iterator<Integer> iterator = hashSet2.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
第五章、Map
重点掌握
- 能够说出Map集合的特点
- 能够使Map集合添加方法保存数据
- 使用“键找值””键值对“的方式遍历Map集合
- 使用HashMap存储自定义键值对的数据
- 完成HashMap案例
5.1 Map集合概述
现实生活中,经常会出现这么一种集合:如 身份证与个人,ip与主机名等,这种一一对应的关系,就叫做映射,
Java提供了专门的集合来存放这种对象关系映射,即java.util.Map接口
其中,Map接口和Collection接口存储数据的形式是不同的
- Collection接口定义了单列集合规范,每次存储一个元素。Collection
- Collection中的集合,元素是独立存在的 ( 单身狗 ),向集合中存储元素采用一个一个的方式存储
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rCJhLYhL-1687769946092)(photo/JavaSE12_集合.assest/1671257470483.png)]](http://img.e-com-net.com/image/info8/5b4abb84031648b291962f180e113a43.jpg)
- Map接口定义了双列集合的规范,每次存放一对元素。Map
- Map中的集合。元素是成对成对的 ( 小情侣 ),每个元素由键和值两部分组成,通常键可以找到指定的值,
- Map中的集合,键是唯一的,值可以重复,每个键只能对应一个值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tHJx8kCm-1687769946093)(photo/JavaSE12_集合.assest/1671257716107.png)]](http://img.e-com-net.com/image/info8/6e00c8b30eb54e458d98382a0eb68e15.jpg)
5.2 Map常用的子类
Map有多个子类,其中常用的事HashMap和LinkedHashMap
- HashMap
- LinkedHashMap(K,V) :HashMap下的子类LinkedHashMap,存储数据采用的事哈希表+链表结构,通过链表结构可以保证元素的存储顺序一致。通过哈希表结构可以保证键的唯一和不重复。需要重写键的hashCode()方法和equals()方法
5.3 Map接口中的常用方法
Map接口中定义了很多方法:常用如下:

Map接口常用方法案例
import java.util.HashMap;
import java.util.Map;
public class Demo01Map {
/*
Map集合的特点
1、Map是一个双列集合,一个元素包含两个值:一个key一个value
2、Map集合中的元素,key和value的数据类型,可以相同,也可以不同
3、Map集合中的元素,key是不允许重复的,value是可以重复的
4、Map集合中的元素,key和value是一一对应的
HashMap实现了Map接口
1、HashMap底层是哈希表,查询速度快
2、HashMap是一个无序的集合,存储元素和取出元素的顺序可能不一致
LinkHashMap继承自HashMap
1、LinkHashMap集合底层是哈希表+链表,保证了迭代的顺序
2、LinkHashMap是一个有序的集合,存储元素和取出元素的顺序是一致的
*/
public static void main(String[] args) {
/*
1 将指定的值与此映射中的指定键相关联
public V put(K key, V value)
返回值:V
key不重复,返回值是null
key重复,原先value被覆盖,返回覆盖的value值
*/
method1();
/*
2 从该集合中删除指定键的映射(如果存在
public V remove(Object key)
返回值:V
key存在,键值对被删除,返回被删除的key对应的值
key不存在,返回值为null
*/
method2();
/*
3 如果此映射包含指定键的映射,则返回 true
boolean containsKey(Object key)
包含返回true,不包含返回false
*/
method3();
/*
4 public V get(Object key)
返回到指定键所映射的值
返回值:V
如果key存在,返回对应的value的值
如果key不存在,返回null
*/
method4();
}
private static void method4() {
Map<Integer,String> map = new HashMap<>();
map.put(1,"赵四");
map.put(2,"刘能");
map.put(3,"谢广坤");
map.put(4,"王老七");
String s1 = map.get(1);
System.out.println(s1);//赵四
String s2 = map.get(5);//null
System.out.println(s2);
System.out.println(map);
}
private static void method3() {
Map<String,String> map = new HashMap<>();
map.put("悟空","猴子");
map.put("八戒","飞猪");
map.put("白龙马","小白龙");
boolean b1 = map.containsKey("八戒");
System.out.println(b1);//true
boolean b2 = map.containsKey("唐僧");
System.out.println(b2);//false
System.out.println(map);
}
private static void method2() {
Map<String,String> map = new HashMap<>();
map.put("季军","克罗地亚");
map.put("亚军","法国");
map.put("冠军","阿根廷");
String s1 = map.remove("亚军");
System.out.println(s1);//法国
String s2 = map.remove("冷军");
System.out.println(s2);//null
System.out.println(map);
}
private static void method1() {
Map<String, String> map = new HashMap<>();
String s1 = map.put("阿根廷", "梅西");
System.out.println(s1);//null
String s2 = map.put("阿根廷", "夺冠");
System.out.println(s2);//梅西
System.out.println(map);
}
}
5.4 Map集合遍历—键找值方式
步骤图:

Map集合遍历键找值方式案例
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Demo02_MapKeySet {
/*
Map集合的遍历
方式一:通过键找值的方式
返回Map中包含的键的Set视图。
Set keySet();
实现步骤:
1、使用Map集合中的keySet()方法,将Map集合中所有的key取出,存储在Set集合中
2、遍历Set集合,获取Map集合中的每个Key
3、通过Map集合中的get(key)方法,通过key找到value
*/
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1,"tom");
map.put(2,"anny");
map.put(3,"jack");
map.put(4,"mary");
//1、第一步使用keySet()方法。将key存储在Set集合中
Set<Integer> s1 = map.keySet();
//2、第二步,遍历Set集合
//迭代器遍历
Iterator<Integer> iterator = s1.iterator();
while (iterator.hasNext()){
Integer key = iterator.next();
//3、第三步,获取Map集合中key对应的value
String value = map.get(key);
System.out.println(key+"="+value);
}
System.out.println("--------------------");
//加强for遍历
for (Integer key : s1) {
//3、第三步,获取Map集合中key对应的value
String value = map.get(key);
System.out.println(key+"="+value);
}
}
}
5.5 Entry键值对对象
Map中存放的是两种对象,一种称为key键,一种称为value值,它们是一一对应的关系
这样的一对对象又称之为Map的一个Entry项,Entry将键值对的对应关系封装成了对象,即键值对对象
在遍历Map集合的时候,就可以从每一个键值对对象Entry中获取对应的键和对应的值
Entry表示一对键和值,同时提供了获取对应键和对应值的方法
- public V getKey( ); 获取Entry对象中的键
- publi V getValue( ); 获取Entry对象中的值
Map集合提供了获取所有Entry对象的方法
- public Set
5.6 Map集合遍历—键值对方式
遍历步骤:
遍历键值对方式:通过集合中每个键值对对象Entry,获取键值对对象Entry中的键和值
实现步骤:
- 1、获取Map集合中的所有键值对Entry对象,以Set集合的形式返回,使用entrySet()
- 2、遍历Set集合,得到每一个Entry对象
- 3、通过键值对Entry对象,获取Entry对象的键和值,方式使用getKey()和getValue()
Map集合遍历键值对方式案例
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Demo03_MapEntrySet {
/*
遍历键值对方式:
通过集合中每个键值对对象Entry,
获取键值对对象Entry中的键和值
实现步骤:
1、获取Map集合中的所有键值对Entry对象,以Set集合的形式返回,使用entrySet()
2、遍历Set集合,得到每一个Entry对象
3、通过键值对Entry对象,获取Entry对象的键和值,方式使用getKey()和getValue()
*/
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1,"卡卡");
map.put(2,"姆巴佩");
map.put(3,"梅西");
map.put(4,"C罗");
//1、获取Map集合中的所有键值对Entry对象,以Set集合的形式返回,使用entrySet()
Set<Map.Entry<Integer, String>> set = map.entrySet();
//2、遍历Set集合,得到每一个Entry对象
//迭代器遍历set集合
Iterator<Map.Entry<Integer, String>> it = set.iterator();
while (it.hasNext()){
Map.Entry<Integer, String> entry = it.next();
//3、通过键值对Entry对象,获取Entry对象的键和值,方式使用getKey()和getValue()
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);
}
System.out.println("-------------------------");
//加强for遍历set集合
for (Map.Entry<Integer, String> entry:set){
//3、通过键值对Entry对象,获取Entry对象的键和值,方式使用getKey()和getValue()
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);
}
}
}
5.7 HashMap存储自定义类型键值
HashMap存储自定义类型键值,Map集合保证key是唯一的,
作为key的元素,必须重写hashCode()和equals()方法。
案例:
import java.util.Objects;
public class User {
private String name;
private String address;
public User() {
}
public User(String name, String address) {
this.name = name;
this.address = address;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", address='" + address + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(name, user.name) && Objects.equals(address, user.address);
}
@Override
public int hashCode() {
return Objects.hash(name, address);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Demo04_MapDefined {
public static void main(String[] args) {
/*
方式1:String字符串作为key,user对象作为value
key相同,值会覆盖
*/
method1();
System.out.println("------------------");
/*
方式2:user对象作为key。字符串作为value
使用对象作为key,必须重写实体类的hashCode和equals方法
否则,key相同,值也不会覆盖
*/
method2();
}
private static void method1() {
Map<String,User> map = new HashMap<>();
map.put("东北",new User("赵本山","辽宁"));
map.put("华北",new User("司马南","北京"));
map.put("华南",new User("刘德华","香港"));
map.put("东北",new User("小沈阳","哈尔冰"));
//1、通过keySet获取Map集合所有的key
Set<String> set = map.keySet();
//2.加强for遍历Set集合,得到key,再通过key获取Map集合中的value
for (String key:set) {
//3、通过key获取value
User user = map.get(key);
System.out.println(key+"="+user);
}
}
private static void method2() {
Map<User,String> map = new HashMap<>();
map.put(new User("张三","北京"),"喜欢篮球");
map.put(new User("李四","上海"),"喜欢排球");
map.put(new User("王五","广州"),"喜欢足球");
map.put(new User("张三","北京"),"喜欢棒球");
//1、使用wntrySet()获取Map集合中的键值对对象Entry
Set<Map.Entry<User, String>> entrySet = map.entrySet();
//2.使用迭代器遍历获取entry对象
Iterator<Map.Entry<User, String>> it = entrySet.iterator();
while (it.hasNext()){
Map.Entry<User, String> entry = it.next();
//3、获取entry中的键和值
User user = entry.getKey();
String value = entry.getValue();
System.out.println(user+"="+value);
}
}
}
- 重写之后,key相同,值会被覆盖

- 未重写,key相同,值不会被覆盖

5.8 LinkedHashMap
HashMap保证课成对元素的唯一,但是无法保证数据的有序。其子类LinkedHashMap即可以实现
LinkedHashMap的底层是链表+哈希表的存储结构,链表用于记录元素的顺序
- HashMap 存取顺序不同
- LinkedHashMap 存取顺序相同
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
public class Demo05_LinkedHashMap {
public static void main(String[] args) {
//1、创建HashMap对象,添加数据并打印
HashMap<String,String> map = new HashMap<>();
map.put("a","英文");
map.put("c","俄文");
map.put("b","中文");
map.put("d","德文");
System.out.println(map);
//2、创建LinkedHashMap对象,添加数据并打印
LinkedHashMap<Integer,String> linkedHashMap = new LinkedHashMap();
linkedHashMap.put(1,"AAA");
linkedHashMap.put(3,"CCC");
linkedHashMap.put(2,"BBB");
linkedHashMap.put(4,"DDD");
System.out.println(linkedHashMap);
}
}

5.9 HashMap和HashTable的区别
- HashTable实现了Map接口
- HashTable底层是哈希表,是一个线程安全的集合,是单线程集合,速度慢
- HashMap底层也是哈希表,是一个线程不安全的集合,是多线程集合,速度快
- HashMap可以存储null值,null键。但是HashTable不可以存储null值,null键
- HashTable在1,2版本之后被HashMap、Arraylist取代了,但是其子类Properties集合依然在使用
- Properties集合是一个唯一可以与IO流两结合的集合
import java.util.HashMap;
import java.util.Hashtable;
public class Demo06_HashTable {
public static void main(String[] args) {
//!、创建HashMap集合,存储null值,null键,并打印输出
HashMap<String, String> map = new HashMap<>();
map.put(null, "AAA");
map.put("A", null);
map.put(null, null);
System.out.println(map);
//2、创建HashTable集合,存储null值,null键,并打印输出
Hashtable<Integer, String> table = new Hashtable<>();
table.put(1, "AAA");
table.put(null, "BBB");
table.put(2, null);
table.put(null, null);
System.out.println(table);
/*
Hashtable的键和值都不能为null,否则会报空指针异常
*/
}
}
