Nginx 高级篇
文章目录
- Nginx 高级篇
-
- 一、 负载均衡
-
- 1、 负载均衡概述
- 2、 处理方式
-
- 2.1 用户手动选择
- 2.2 DNS 轮询
- 2.3 四 / 七层负载均衡
- 3、 七层负载均衡
-
- 3.1 七层负载均衡指令
-
- 3.1.1 upstream
- 3.1.2 server
- 3.2 实现流程
- 3.3 负载均衡的状态
-
- 3.3.1 down
- 3.3.2 backup
- 3.3.3 max_conns
- 3.3.4 max_fails & fail_timeout
- 3.4 负载均衡策略
-
- 3.4.1 轮询
- 3.4.2 weight
- 3.4.3 ip_hash
- 3.4.4 least_conn
- 3.4.5 url_hash
- 3.4.6 fair
- 4、 四层负载均衡
-
- 4.1 四层负载均衡指令
-
- 4.1.1 stream
- 4.1.2 upstream
- 4.2 使用示例
- 二、 Nginx 缓存集成
-
- 1、 缓存的概念
- 2、 缓存相关指令
-
- 2.1 proxy_cache_path
- 2.2 proxy_cache
- 2.3 proxy_cache_key
- 2.4 proxy_cache_valid
- 2.5 proxy_cache_min_uses
- 2.6 proxy_cache_methods
- 3、 Nginx 缓存的清除
-
- 3.1 删除缓存目录
- 3.2 使用扩展模块
- 4、 设置资源不缓存
- 三、 Nginx 实现动静分离
-
- 1、 概念
- 2、 需求分析
- 四、 Nginx 实例
-
- 1、 Nginx 制作下载站点
- 2、 用户认证
Nginx 高级篇

一、 负载均衡
1、 负载均衡概述
负载均衡(Load Balance),它在网络现有结构之上可以提供一种廉价、有效、透明的方法来扩展网络设备和服器的带宽,并可以在一定程度上增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性等。用官网说,它充当着网络流中“交通指挥官”的角色,“站在”服务器前处理所有服务器端和客户端之间的请求,从而最大度地提高响应速率和容量利用率,同时确保任何服务器都没有超负荷工作。如果单个服务器出现故障,负载均衡方法会将流量重定向到其余的集群服务器,以保证服务的稳定性。当新的服务器添加到服务器组后,也可通过负均衡的方法使其开始自动处理客户端发来的请求。
负载均衡的作用:
- 解决服务器高并发的压力,提高应用程序的处理性能
- 提供故障转移,实现高可用
- 通过添加或减少服务器数量,增强网站的可扩展性
- 在负载均衡器上进行过滤,可以提高系统的安全性
2、 处理方式
2.1 用户手动选择
这种方式比原始,主要实现的方式就是在网站主页上面提供不同线路、不同服务连接方式,让用户来选择自己访问的具体服务器,来实现负载均衡。
如,蓝奏云
2.2 DNS 轮询
DNS:域名系统服务协议是一种分布式网络目录服务,主要有用于域名与 IP 地址的相互转换
大多数域名注册商都支持对同一个主机名添加多条 A 记录,这就是 DNS 轮询,DNS 服务器将解析请求按照 A 记录的顺序,随机分配到不同的 IP 上,这样就能完成简单的负载均衡。DNS 轮询的成本非常低,在一些不重要的服务器,被经常使用。
使用 DNS 来实现轮询,不需要投入过多的成本,虽然 DNS 轮询成本低廉,但是 DNS 负载均衡存在明显的缺点:
-
可靠性低
各大宽带接入商会将众多的 DNS 存放在缓存中,以节省访问时间,导致 DNS 不会实时更新。
Windows 刷新 DNS 的命令:
ipconfig/flushdns -
负载均衡不均衡
其会导致某几台服务器负荷很低,而另外几台服务器负荷很高,处理请求的速度慢,配置高的服务器分配到的请求少,而配置低的服务器分配到的请求多。
2.3 四 / 七层负载均衡
OSI,开放式系统互联模型,这个是有国际标准化 ISO 指定的一个不基于具体机型、操作系统或公式的网络体系结构。该模型将网络通信的工作分为七层。

- 四层负载均衡:OSI 七层模型中的传输层,主要是基于 IP + PORT 的负载均衡
- 七层负载均衡:在音乐层,主要是基于虚拟的 URL 或主机 IP 的负载均衡
3、 七层负载均衡
Nginx 要实现七层负载均衡需要用到 proxy_pass 代理模块配置。Nginx 默认安装支持这个模块,我们不需要再做任何处理。Nginx 的负载均衡是在 Nginx 的反向代理的基础上把用户的请求根据指定的算法分发到一组【upstream 虚拟服务池】
3.1 七层负载均衡指令
3.1.1 upstream
该指令是用来定义一组服务器,它们可以是监听不同端口的服务器,并且也可以是同时监听 TCP 和 Unix Socket 的服务器。服务器可以指定不同的权重,默认为 1。
| 语法 | 默认值 | 位置 |
|---|---|---|
| upstream name {…} | - | http |
3.1.2 server
该指令是用来指定后端服务器的名称和一些参数,可以使用域名、IP、端口或者 Unix Socket。
| 语法 | 默认值 | 位置 |
|---|---|---|
| server name [paramerters] | - | upstream |
3.2 实现流程

使用示例:
server {
listen 9001;
server_name localhost;
default_type text/html;
location / {
return 200 "port=9001";
}
}
server {
listen 9002;
server_name localhost;
default_type text/html;
location / {
return 200 "port=9002";
}
}
upstream backend {
server localhost:9001;
server localhost:9002;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend; # backend 为服务组的名称
}
}
3.3 负载均衡的状态
代理服务器在负责负载均衡调度中的状态有以下几个:
| 状态 | 描述 |
|---|---|
| down | 当前 server 暂时不参与负载均衡 |
| backup | 预留的备份服务器 |
| max_fails | 允许请求失败的次数 |
| fail_timeout | 经过 max_fails 失败后,服务暂停时间 |
| max_conns | 限制最大的接收数 |
3.3.1 down
将服务器标记为永久不可用,那么该服务器将不参与负载均衡
upstream backend {
server localhost:9001 down;
server localhost:9002;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend; # backend 为服务组的名称
}
}
该状态一般会对需要停机维护的服务器进行设置。
3.3.2 backup
将该服务器标记为备份服务器,当主服务器不可用时,将用来传递请求。
upstream backend {
server localhost:9001 backup; # 备份服务器
server localhost:9002 down;
server localhost:9003; # 主服务器
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend; # backend 为服务组的名称
}
}
此时需要将 9003 端口的访问禁止调来模拟唯一能对外提供访问的服务宕机以后,backup 的备份服务器就要开始对外提供服务,此时为了测试验证,我们需要使用防火墙来进行拦截。
这时,我们需要使用 ufw 工具来对防火墙进行控制:
sudo apt install ufw # 安装 ufw
ufw enadble # 开启防火墙
ufw deny 9003/tcp # 关闭 9003 端口
ufw allow 9001:9002/tcp # 允许开启 9001 和 9002
ufw allow http # 开放http
这里我使用的是 ubuntu 系统
3.3.3 max_conns
max_conns=number:其用来设置代理服务器同时活动链接的最大数量,默认为 0 ,表示不限制,使用该配置可以根据后端服务器处理请求的并发量来进行设置,防止后端服务器被压垮。
3.3.4 max_fails & fail_timeout
max_fails=number:设置允许请求代理服务器失败的次数,默认为 1 。
fail_timeout=time:设置经过 max_fails 失败后,服务暂停的时间,默认是 10 秒。
upstream backend {
server localhost:9001 backup; # 备份服务器
server localhost:9002 down;
server localhost:9003 max_fails=3 fail_timeout=15; # 主服务器
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend; # backend 为服务组的名称
}
}
3.4 负载均衡策略
学完负载均衡的相关指令后,我们已经可以实现将用户的请求分发到不同的服务器上,那么除了采用默认的分配方式以外,我们还能采用什么样的负载算法?
| 算法名称 | 说明 |
|---|---|
| 轮询 | 默认方式 |
| weight | 权重方式 |
| ip_hash | 依据 ip 分配方式 |
| least_conn | 依据最少连接方式 |
| url_hash | 依据 URL 分配方式 |
| fair | 依据响应时间方式 |
3.4.1 轮询
其是 upstream 模块负载均衡默认的策略。每个请求会按时间顺序逐个分配到不同的后端服务器。轮询不需要额外的配置。
upstream backend {
server localhost:9001;
server localhost:9002;
server localhost:9003;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
}
3.4.2 weight
weight=number:用来设置服务器的权重,默认为 1 ,权重数据越大,被分配到请求的几率越大;该权重值,主要是针对实际工作环境中不同的后端服务器硬件配置进行调整的,所有此策略比较适合服务器的硬件配置差别比较大的情况。
upstream backend {
server localhost:9001 weight=10;
server localhost:9002;
server localhost:9003;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
}
3.4.3 ip_hash
当后端的多台动态应用服务器做负载均衡时,ip_hash 指令能够将某个客户端 IP 的请求通过哈希算法定位到同一台后端服务器上。这样,当来自某一个 IP 的用户在后端 Web 服务器 A 上登录后,当访问该站点的其他 URL ,能够访问的还是后端 Web 服务器 A。
| 语法 | 默认值 | 位置 |
|---|---|---|
| ip_hash; | - | upstream |
upstream backend {
ip_hash;
server localhost:9001;
server localhost:9002;
server localhost:9003;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
}
3.4.4 least_conn
最少连接,把请求转发给连接数较少的后端服务器,轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。这种情况下,least_conn 这种方式就可以达到更好的负载均衡效果。
upstream backend {
least_conn;
server localhost:9001;
server localhost:9002;
server localhost:9003;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
}
此负载均衡策略适合请求处理时间长短不一造成服务器过载的情况。
3.4.5 url_hash
按访问 url 的 hash 结果来分配请求,使每个 url 定向到同一个后端服务器,要配合缓存命中来使用。同一个资源多次请求,可能会到达不同的服务器上,导致不必要的多次下载,缓存命中率不高,以及一些资源时间的浪费。而使用 url_hash ,可以使得同一个 url (也就是同一个资源请求)会到达同一台服务器,一旦缓存了资源,再此收到请求,就可以从缓存中读取。
upstream backend {
url_hash &request_uri;
server localhost:9001;
server localhost:9002;
server localhost:9003;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
}
3.4.6 fair
fair 采用的不是内建负载均衡使用的轮询的均衡算法,而是可以根据页面大小、加载事件长短智能的进行负载均衡。那么,如何使用第三方模块的 fair 负载均衡策略?
upstream backend {
fair;
server localhost:9001;
server localhost:9002;
server localhost:9003;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://backend;
}
}
但是,直接使用会报错,因为 fair 属于第三方模块实现的负载均衡。需要添加nginx-upstream-fair,如何添加呢?
-
下载
nginx-upstream-fair模块:https://github.com/gnosek/nginx-upstream-fair.gitcd git clone https://github.com/gnosek/nginx-upstream-fair.git -
使用
./confirgure命令将资源添加到 Nginx 模块中nginx -V # 复制原来的配置参数 cd /root/nginx-1.22.1/ # 进入 Nginx 安装目录 ./configure old_args -add-module=/root/nginx-upstream-fair # 添加第三方模块 make # 进行编译 mv objs/nginx /usr/local/nginx/sbin/ # 将编译后的 Nginx 替换原来的 Nginx make upgrade # 进行在线升级在编译过程中会发现编译失败了:

我们需要运行:
vim src/http/ngx_http_upstream.h找到对应位置,添加图片中的内容,然后再进行一次编译就可以了。
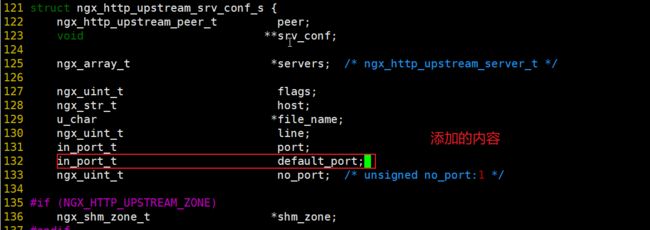
4、 四层负载均衡
Nginx 增加了 stream 模块,用来实现四层协议的转发、代理、负载均衡等。stream 模块的用法跟 http 的用法类似,允许我们配置一组 TCP 或者 UDP 等协议的监听,然后通过 proxy_pass 来转发我们的请求,通过 upstream 添加多个后端服务,实现负载均衡。
四层协议负载均衡的实现,一般都会用到 LVS、HAProxy、F5等,而 Nginx 的配置相对来说更简单,更能快速完成工作。四层负载均衡不经常使用,了解即可。
Nginx 默认是没有编译这个模块的,需要使用到 stream 模块,那么需要在编译的时候加上 --with-stream,和添加一般模块的步骤类似。
4.1 四层负载均衡指令
4.1.1 stream
该指令提供在其中指定流服务器指令的配置文件上下文,和 http 同级。
| 语法 | 默认值 | 位置 |
|---|---|---|
| stream{…} | - | main |
4.1.2 upstream
该指令和 http 的upstream 指令是类似的。
4.2 使用示例
stream {
upstream redisbackend {
server localhost:6379; # 第一台 Redis 服务器
server localhost:6378; # 第二台 Redis 服务器
}
server {
listen 81;
proxy_pass redisbackend;
}
}
stream {
upstream flaskbackend {
server localhost:8080; # flask 服务器
}
server {
listen 82;
proxy_pass flaskbackend;
}
}
http {
server {
listen 80;
server_name localhost;
charset koi8-r;
access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
一个 81 端口绑定了两台 redis 服务器,同时将 82 端口绑定到 flask 服务器上面。
二、 Nginx 缓存集成
1、 缓存的概念
缓存就是数据交换的缓冲区,当用户要获取数据的时候,会先从缓存中去查询获取数据,如果缓存中有就会直接返回给用户,如果缓存中没有,则会发送请求从服务器重新查询数据,将数据返回给用户的同时将数据放入缓存,下次用户就会直接从缓存中获取数据。
缓存的应用场景:
| 场景 | 作用 |
|---|---|
| 操作系统磁盘缓存 | 减少磁盘机械操作 |
| 数据库缓存 | 减少文件系统的 IO 操作 |
| 应用程序缓存 | 减少对数据库的查询 |
| Web 服务器缓存 | 减少对应用服务器请求次数 |
| 浏览器缓存 | 减少与后台的交互次数 |
缓存的优点:
- 减少数据传输,节省网络流量,加快响应速度,提升用户体验
- 减轻服务器压力
- 提供服务端的高可用性
缓存的缺点:
- 数据不一致
- 增加成本
2、 缓存相关指令
Nginx 的 Web 缓存服务器主要是使用 ngx_http_proxy_module模块相关指令集来完成。
2.1 proxy_cache_path
该指令用于设置缓存文件的存放路径
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache_path path [levels=number] keys_zone=zone_name:zone_size [inactive=time][max_size=size]; |
- | http |
path:缓存路径地址,如:/usr/local//proxy_cache
levels:指定该缓存空间对应的目录,最多可设置三层,每层取值为 1 | 2,如:
levels=1:2 缓存空间有两层目录,第一次是 1 个字母,第二次是 2 个字母
# 最终存储路径为 /usr/local//proxy_cache/d/07
keys_zone:用来为这个缓存区设置名称和指定大小
inactive:指定缓存的珊瑚橘多次时间未被访问就将被删除
max_size:设置最大缓存空间,如果缓存空间存满,默认会覆盖缓存时间最长的资源
2.2 proxy_cache
该指令用来开启或关闭代理缓存,如果是开启则自定义使用哪个缓存区来进行缓存。
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache zone_name | off; | proxy_cache off; | http、server、location |
zone_name:指定使用缓存区的名称
2.3 proxy_cache_key
该指令用来设置 Web 缓存的 Key 值,Nginx 会根据 Key 值 MD5 哈希存缓存。
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache_key key; | proxy_cache s c h e m e scheme schemeproxy_host$request_uri; | http、server、location |
2.4 proxy_cache_valid
该指令用来对不同返回状态码的 URL 设置不同的缓存时间
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache_valid [code …] time; | - | http、server、location |
2.5 proxy_cache_min_uses
该指令用来设置资源被访问多少次后被缓存
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache_min_uses number; | proxy_cache_min_uses 1; | http、server、location |
2.6 proxy_cache_methods
该指令用户设置缓存哪些 HTTP 方法
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache_methods GET | HEAD | POST; | proxy_cache_methods GET HESAD; | http、server、location |
默认缓存 HTTP 的 GET 和 HEAD 方法,不缓存 POST 方法。
3、 Nginx 缓存的清除
3.1 删除缓存目录
rm -rf /usr/local/proxy_cache/...
3.2 使用扩展模块
使用模块ngx_cache_purge
-
下载资源包:https://github.com/FRiCKLE/ngx_cache_purge.git
git clone https://github.com/FRiCKLE/ngx_cache_purge.git -
进行安装
nginx -V # 查询 Nginx 的配置参数 ./configure old_args --add-module=/root/nginx-1.22.1/modules/ngx_cache_purge make mv objs/nginx /usr/local/nginx/sbin/ make upgrade
| 语法 | 默认值 | 位置 |
|---|---|---|
| proxy_cache_purge zone_name proxy_cache_key | - | http、server、location |
具体的使用方式可以查看:https://github.com/FRiCKLE/ngx_cache_purge
4、 设置资源不缓存
并不是所有的数据都适合缓存,比如说一些经常发生变化的数据。
这时候需要使用到如下两个指令:
-
proxy_no_cache
该指令是用来定义不将数据进行缓存的条件。
语法 默认值 位置 proxy_no_cache string …; - http、server、location proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;-
$cookie_nocache
指的是当前请求的 Cookie 中键的名称为 nocache 对应的值
-
$arg_nocache
指的是当前请求的参数中属性名为 nocache 的值
-
$arg_comment
指的是当前请求的参数中属性名为 comment 的值
-
-
proxy_cache_bypass
该指令是用来设置不从缓存中获取数据的条件
语法 默认值 位置 proxy_cache_bypass string …; - http、server、location proxy_cache_bypass $cookie_nocache $arg_nocache $arg_comment;
上述两个指令都有一个指定条件,这个条件可以是多个,并且多个条件中至少有一个不为空且不等于 0,则条件满足成立。
使用示例:
http{
proxy_cache_path /usr/local/nginx/proxy_cache levels=2:1 keys_zone=temp:200m inactive=1d max_szie=20g;
upstream backend {
server localhost:8080;
}
server {
location / {
# 如果请求的文件为 js 文件,不进行缓存
if ($request_uri ~ /.*\.js$) {
set $nocache 1;
}
proxy_cache temp;
proxy_cache_key temp_;
proxy_cache_min_uses 5;
proxy_cache_valid 200 5d;
proxy_cache_valid 404 30s;
proxy_cache_valid any 1m;
proxy_no_cache $nocache;
proxy_cache_bypass $nocache;
proxy_pass http://backend/;
}
location /purge(/.*) {
proxy_cache_purge temp temp_;
}
}
}
三、 Nginx 实现动静分离
1、 概念
什么是动静分离?
- 动:后台应用程序的业务处理
- 静:网站静态资源
- 分离:将两者进行分开部署访问,提供用户进行访问。举例说明就是以后所有和静态资源相关的内容都交给 Nginx 来部署访问,非静态内容则交给类似于 Flask 的服务器来部署访问。
为什么要静态分离?
- Nginx 在处理静态资源的时候,效率非常高,而且 Nginx 的并发访问量也是名列前茅的,而 Flask 等服务器则相对比较弱一些,所以把静态文件交给 Nginx 后,可以减轻 Flask 服务器的访问压力并提高静态资源的访问速度。
- 动静分离后,减低了动态资源和静态资源的耦合度。如果动态资源宕机了也不影响动态资源的展示。
如果实现动静分离?
- 实现动静分离的方式很多,比如,静态资源化可以部署到 CDN、Nginx 等服务器上,动态资源可以部署到 Flask 等上面,这里使用Nginx + Flask 来实现动静分离。
2、 需求分析
我们需要将动态的链接发送到 Flask,静态的访问直接通过 Nginx 来进行处理。
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream flaskservice{
server localhost:8080;
}
server {
listen 80;
server_name localhost;
location ~/.*\.(html|htm|js|css|ico|png|jpg|gif|svg|txt) {
root /root/www/static;
}
location /demo{
proxy_pass http://flaskservice;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
四、 Nginx 实例
1、 Nginx 制作下载站点
首先,我们要清除什么是下载站点?
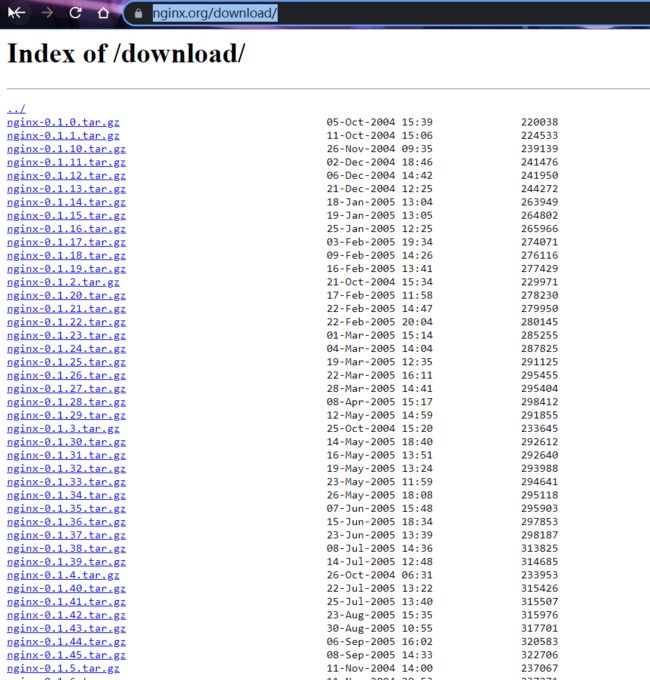
- 我们先来看一下网站:https://nginx.org/download/。
- 这个网站主要就是用来提供用户来下载相关资源的网站,就叫做下载站点。
如何制作下载站点?
- Nginx 使用的是模块
ngx_http_autoindex_module来实现的,该模块处理以斜杆结尾的请求,并生成目录列表。 - Nginx 编译的时候会自动加载该模块,但是该模块默认是关闭的,我们需要使用下面的指令来完成对应的配置
指令:
-
autoindex:启用或禁用目录列表输出
语法 默认值 位置 autoindex on | off; autoindex off; http、server、location -
autoindex_exact_size:对应 HTML 格式,指定是否在目录列表展示文件的详细大小
默认为 on,显示出文件的确切大小,单位是 bytes;改为 off 后,显示出文件的大概大小,单位是 kb 或者 Mb 或者 GB。
-
autoindex_format:设置目录列表的格式
语法 默认值 位置 autoindex_format html | xml | json | jsonp; autoindex_format html; http、server、location -
autoindex_localtime:对应 HTML 格式,是否在目录列表上显示时间
默认为 off ,显示的文件时间为 GMT 时间;改为 on 后,显示的文件时间为文件的服务器时间。
location /download {
root /root/www;
autoindex on;
autoindex_localtime on;
}
在 www 目录下有一个download 目录;同时,由于在root 目录下,需要在全局块中添加
user root;。
2、 用户认证
对于系统资源的访问,我们往往需要限制谁能访问,谁不能访问。这块就是我们通常所说的认证部分,认证需要做的就是根据用户输入的用户名和密码来判定用户是否为合法用户,如果是则放行,如果不是则拒绝访问。
Nginx 对应用户认证是通过 ngx_http_auth_basic_module模块来实现的,它允许通过使用“ HTTP 基本身份验证”协议验证用户名和密码来限制对资源的访问。默认情况下 Nginx 是已经安装了这个模块。如果没有,则使用 --without-http_auth_basic_module。
该模块的指令比较简单:
-
auth_basic:使用“ HTTP 基本认证”协议启用用户名和密码的验证
语法 默认值 位置 auth_basic string | off; auth_basic off; http、server、location、limit_except 开启后,服务端会返回 401,指定的字符串会返回到客户端,给用户以提示信息,但是不同的浏览器对内容的展示不一致。
-
auth_basic_user_file:指定用户名和密码所在的文件
语法 默认值 位置 auth_basic_user_file file; - http、server、location、limit_except 指定文件路径,还文件中的用户名和密码的设置,密码需要进行加密。可以采用工具自动生成
# 下载站点的相关配置
location /download {
root /root/www;
autoindex on;
autoindex_localtime on;
auth_basic "please inpute your auth";
auth_basic_user_file htpasswd;
}
生成用户名和密码的文件:
# 我们使用 htpasswd 工具生成
yum install -y httpd-tools
cd /usr/local/nginx/conf
htpasswd -c htpasswd username # 创建一个新文件记录用户名和密码
htpasswd -b htpasswd username password # 在指定文件新增一个用户名和密码
htpasswd -D htpasswd username # 从指定文件删除一个用户信息
htpasswd -v htpasswd username # 验证用户名和密码是否正确