SeaTunnel及SeaTunnel Web部署指南(小白版)
现在你能搜索到的SeaTunnel的安装。部署基本都有坑,官网的文档也是见到到相当于没有,基本很难找到一个适合新手小白第一次上手就能成功安装部署的版本,于是就有了这个部署指南的分享,小主已经把可能遇到的坑都填过了,希望大家都能安安稳稳上路,不掉坑,话不多说,走起~
1.预置环境
1.1.所需软件包及版本要求
-
CentOS 7.6.18_x86_64
-
JDK >= 1.8.151
-
Maven >= 3.6.3
-
Apache Seatunnel ==2.3.3
-
Apache Seatunnel Web == 1.0.0
-
MySQL >= 5.7.28

1.2.下载地址
官网下载入口: 下载入口
apache-seatunnel-2.3.3: apache-seatunnel-2.3.3-bin.tar.gz

apache-seatunnel-web-1.0.0: apache-seatunnel-web-1.0.0

1.3.准备工作
1.3.1.安装JDK
安装及配置系统环境变量略过,自行百度
1.3.2.安装Maven
安装及配置系统环境变量、配置阿里云仓库镜像, 略过,自行百度
1.3.3.创建安装软件目录
创建seatunnel后端服务安装目录
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend
**创建seatunnel前端服务安装目录
mkdir -p /opt/bigdata/seatunnel-2.3.3/web

1.3.4.下载或者本地上传安装包
下载apache-seatunnel-2.3.3-bin.tar.gz
#进入1.3.2中创建好的安装目录
cd /opt/bigdata/seatunnel-2.3.3/backend
#下载安装包
wget https://dlcdn.apache.org/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz
下载[apache-seatunnel-web-1.0.0.tar.gz
#进入1.3.2中创建好的安装目录
cd /opt/bigdata/seatunnel-2.3.3/web
#下载安装包
wget https://dlcdn.apache.org/seatunnel/seatunnel-web/1.0.0/apache-seatunnel-web-1.0.0-bin.tar.gz
如果你已经将安装包下载到本地, 可通过FTP工具上传安装包到前后端各自的安装目录。
2.安装Apache Seatunnel
2.1.解压安装包
#解压后端安装包
tar -zxf /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3-bin.tar.gz
#重命名安装包
mv apache-seatunnel-2.3.3-bin apache-seatunnel-2.3.3

#解压前端安装包
tar -zxf /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0-bin.tar.gz
#重命名安装包
mv apache-seatunnel-web-1.0.0-bin apache-seatunnel-web-1.0.0

2.2.配置环境变量
在/etc/profile中配置环境变量

让修改配置立即生效
source /etc/profile
2.3.下载JAR包
2.3.1.创建目录
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/flink
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/flink-sql
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/spark
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/seatunnel
 ### 2.3.2.修改下载脚本
### 2.3.2.修改下载脚本
下载脚本的位置
/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/bin

修改install-plugin.sh之前请先备份
mvn加速下载seatunnel相关jar包
安装seatunnel过程中,解压文件后官方默认提供的connector的jar包只有2个,要想连接mysql,oracle,SqlServer,hive,kafka,clickhouse,doris等时,还需下载对应的jar包。

使用本地Maven加速下载connector相关jar包
seatunnel下载connector的jar时,使用mvnw来下载jar包,默认是从https://repo.maven.apache.org 下载,速度及其缓慢。我们可以改成自己在linux系统上安装的mvn,配置阿里云远程仓库地址,从阿里云mvn源下载会快很多, 下面教大家如何进行修改。
修改其安装插件相关脚本,复制bin目录下install-plugin.sh重命名为install-plugin.sh.bak

替换脚本中的${SEATUNNEL_HOME}/mvnw为mvn,即可使用本地mvn,配合阿里云的mvn源,可加速下载。
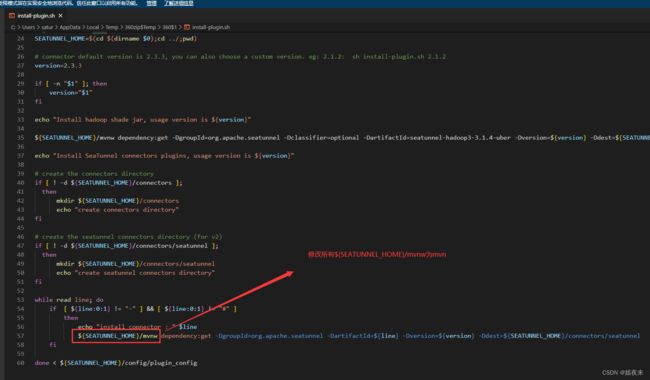
2.3.3.执行下载
2.3.3.1.自动下载
执行命令即可,一般不推荐,因为从官网下载速度太慢,可以通过修改相关的代码进行手动加速下载。
系统默认自动下载时会下载所有的连接器JAR, 如果暂时不需要使用, 可以在执行下载脚本执行之前先在/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/config/pulgun_config配置中注释掉不需要的连接器

sh /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/bin/install-plugin.sh

自动下载完成之后, 将/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/seatunnel下所有的jar包都拷贝到/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/lib目录下
2.3.3.2.手动下载
修改代码,通过阿里云的mvn源快速下载,然后将相关jar包复制到对应目录即可。
seatunnel-connectors下载地址
注意:下载jar复制到两个文件夹,一个是lib文件夹,一个是connectors/seatunnel文件夹。
2.3.4.测试验证
#进入安装目录
cd /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3
#启动服务
./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local

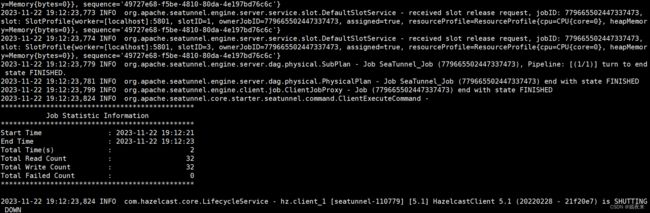

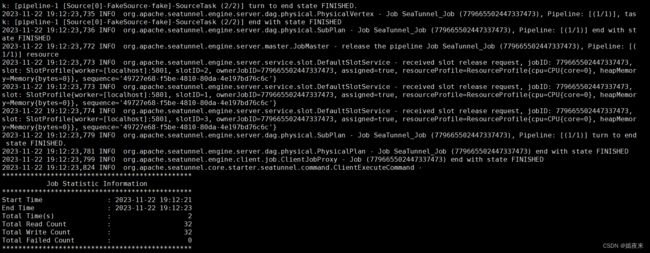
2.4.启动服务
#进入安装目录
cd /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3
#启动服务
nohup sh bin/seatunnel-cluster.sh 2>&1 &
在seatunnel的安装目录下查看日志
tail -f logs/seatunnel-engine-server.log 有以下类似信息打印出,说明启动成功。

必须保证Apache SeaTunnel的Server正常运行,Web端服务才能正常运行。
3.安装Apache Seatunnel Web
3.1.安装配置Seatunnel引擎集群
在SeaTunnel的Web端机器上需要安装SeaTunnel客户端,如果服务端与Web端在同一台机器,则可直接跳过这个步骤。
本文档的安装过程中,Seatunnel服务端和web是安装在同一台机器上, 所以直接跳过此步安装步骤。
这里所说的Seatunnel引擎客户端其实就是我们章2中安装的Seatunnel服务端, 下面讲解一下如何进行Seatunnel集群的安装配置
3.1.1.准备服务器节点
我们现在需要搭建Seatunnel引擎集群,需要准备n台服务器节点, 我这里使用了3台服务器。比如, 已知我们的3台服务器的IP分别是
192.168.1.110
192.168.1.111
192.168.1.112
我们直接在章2中已经安装部署好的Seatunnel单节点中进行集群的配置,主要的配置修改包含以下几项:
3.1.2.修改JVM参数
在seatunnel的安装目录,找到$SEATUNNEL_HOME/bin/seatunnel-cluster.sh

将 JVM 选项添加到$SEATUNNEL_HOME/bin/seatunnel-cluster.sh第一行
JAVA_OPTS=“-Xms2G -Xmx2G”
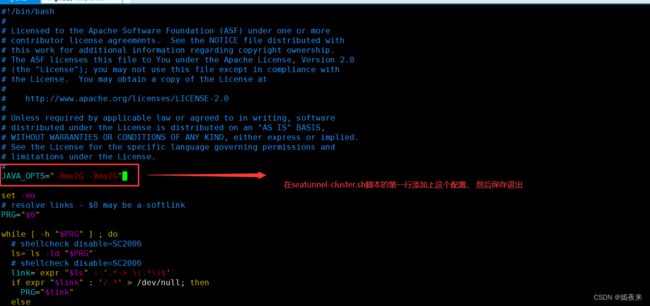
如果不想这样进行修改,也可以, 不过需要在进行集群启动时,自行增加JVM参数进行启动, 启动命令如下:
nohup sh $SEATUNNEL_HOME/bin/seatunnel-cluster.sh -DJvmOption="-Xms2G -Xmx2G" 2>&1 &

3.1.3.SeaTunnel Engine配置
SeaTunnel Engine Server配置是在sh $SEATUNNEL_HOME/config/seatunnel.yaml .
详细配置想可参考官方文档4. Config SeaTunnel Engine,这里不赘述
3.1.4.SeaTunnel Engine Server配置
SeaTunnel Engine Server配置是在sh $SEATUNNEL_HOME/config/hazelcast.yaml .
3.1.4.1.集群名称配置
SeaTunnel Engine 节点使用集群名称来确定对方是否与自己是一个集群。 如果两个节点之间的集群名称不同,SeaTunnel 引擎将拒绝服务请求。
3.1.4.2.网络配置
SeaTunnel Engine 集群基于 Hazelcast,是运行 SeaTunnel Engine Server 的集群成员的网络。 集群成员自动连接在一起形成集群。 这种自动加入是通过集群成员用来查找彼此的各种发现机制来实现的。
请注意,集群形成后,集群成员之间的通信始终通过 TCP/IP 进行,无论使用何种发现机制。
SeaTunnel 引擎使用以下发现机制。
TCP
您可以将 SeaTunnel Engine 配置为完整的 TCP/IP 集群。 有关配置详细信息,请参阅通过 TCP 发现成员部分。
hazelcast.yaml配置示例如下:
hazelcast:
cluster-name: seatunnel
network:
join:
tcp-ip:
enabled: true
member-list:
- hostname1
port:
auto-increment: false
port: 5801
properties:
hazelcast.logging.type: log4j2
在独立 SeaTunnel 引擎集群中我们建议使用TCP方式。
另一方面,Hazelcast 提供了一些其他的服务发现方法。 详情请参考hazelcast网
3.1.4.3 Map配置
- type
imap持久化类型,目前仅支持hdfs。
- namespace
命令空间用于区分不同业务的数据存储位置,例如OSS的桶名。
- clusterName
这个参数主要用于集群隔离,我们可以通过这个来区分不同的集群,比如cluster1、cluster2,这个也可以用来区分不同的业务
- fs.defaultFS
We used hdfs api read/write file, so used this storage need provide hdfs configuration
if you used HDFS, you can config like this:
map:
engine*:
map-store:
enabled: true
initial-mode: EAGER
factory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactory
properties:
type: hdfs
namespace: /tmp/seatunnel/imap
clusterName: seatunnel-cluster
storage.type: hdfs
fs.defaultFS: hdfs://localhost:9000
如果没有 HDFS 并且您的集群只有一个节点,您可以配置为使用本地文件,如下所示:
map:
engine*:
map-store:
enabled: true
initial-mode: EAGER
factory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactory
properties:
type: hdfs
namespace: /tmp/seatunnel/imap
clusterName: seatunnel-cluster
storage.type: hdfs
fs.defaultFS: file:///
如果你使用OSS,你可以这样配置:
map:
engine*:
map-store:
enabled: true
initial-mode: EAGER
factory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactory
properties:
type: hdfs
namespace: /tmp/seatunnel/imap
clusterName: seatunnel-cluster
storage.type: oss
block.size: block size(bytes)
oss.bucket: oss://bucket name/
fs.oss.accessKeyId: OSS access key id
fs.oss.accessKeySecret: OSS access key secret
fs.oss.endpoint: OSS endpoint
fs.oss.credentials.provider: org.apache.hadoop.fs.aliyun.oss.AliyunCredentialsProvider
3.1.5.SeaTunnel Engine Client配置
SeaTunnel Engine Client配置是在sh $SEATUNNEL_HOME/config/hazelcast-client.yaml .
3.1.5.1.集群名称配置
客户端必须与 SeaTunnel 引擎具有相同的集群名称。 否则,SeaTunnel 引擎将拒绝客户端请求。
3.1.5.2.网络配置
cluster-members
所有 SeaTunnel 引擎服务器节点地址都需要添加到此处。
hazelcast-client:
cluster-name: seatunnel
properties:
hazelcast.logging.type: log4j2
network:
cluster-members:
- hostname1:5801
3.1.6.启动Seatunnel引擎服务端节点
mkdir -p $SEATUNNEL_HOME/logs
cd $SEATUNNEL_HOME
./bin/seatunnel-cluster.sh -d
如果集群存在多台节点, 需要启动所有节点上的Seatunnel引擎服务。
3.1.7.安装Seatunnel引擎客户端并启动
您只需将SeaTunnel引擎节点上的安装目录目录复制到客户端节点主机的相同安装目录下,并像SeaTunnel引擎服务器节点一样配置SEATUNNEL_HOME,之后启动服务即可。
3.2.配置Seatunnel Web服务
3.2.1.数据库初始化
3.2.1.1.修改数据库连接配置
将script/seatunnel_server_env.sh相关配置改为你的对应的数据库信息

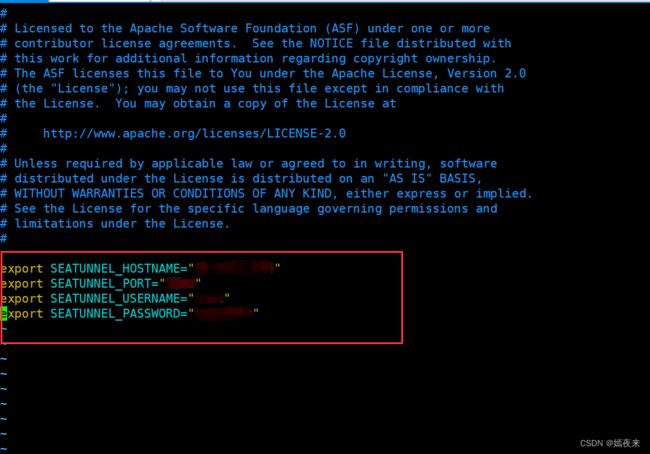
以上截图中原始文件中配置的是HOSTNAME,PORT,USERNAME,PASSWORD等,但是因为的机器上有全局配置文件也用了这几个变量名,但是链接的数据库信息和seatunnel连接的数据库不是一个数据库, 因为名称冲突导致在启动web服务时连接数据哭失败,
所以我这里修改了seatunnel_server_env.sh和init_sql.sh脚本中的HOSTNAME,PORT,USERNAME,PASSWORD可以加上前缀SEATUNNEL_,变成了
SEATUNNEL_HOSTNAME,SEATUNNEL_PORT,SEATUNNEL_USERNAME,SEATUNNEL_PASSWORD
一定要记住, 如果你按照文档修改了seatunnel_server_env.sh脚本的变量名, 一定要将init_sql.sh脚本中对应的变量名称进行同步修改,如下图:


3.2.1.2. 执行初始化数据库命令
进入seatunnel-web的安装目录,然后执行命令sh init_sql.sh,无异常则执行成功。

3.2.2.配置WEB后端服务
3.2.2.1.修改后端基础配置
web后端服务的配置文件都在${web安装目录}/conf下

vim conf/application.yml修改端口号和数据源连接信息

3.2.2.2.配置client信息
将seatunnel引擎服务节点的安装目录下的config目录下的关于引擎客户端的配置文件拷贝到seatunnel-web安装目录下的conf目录下
同一台机器下部署直接使用以下拷贝命令(注意修改服务的安装目录为你自己的安装目录)
sudo cp /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/config/hazelcast-client.yaml /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0/conf
如果不在同一台机器上, 可以使用scp命令或者下载下来然后上传到web服务的安装主机的安装目录下的conf目录下即可。
3.2.2.3.配置支持的插件信息
将seatunnel引擎服务节点的安装目录下的connectors目录下的plugin-mapping.properties配置文件拷贝到seatunnel-web安装目录下的conf目录下
sudo cp /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/plugin-mapping.properties /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0/conf
同一台机器下部署直接使用以下拷贝命令(注意修改服务的安装目录为你自己的安装目录)如果不在同一台机器上, 可以使用scp命令或者下载下来然后上传到web服务的安装主机的安装目录下的conf目录下即可。
3.2.3.下载配置数据源JAR包
这一步非常关键, 这一步如果没有配置好, 即使你正常启动了web应用,可能也会遇到下列问题:
- 数据源类型选择页面为空, 我这里因为正常配置, 所以正常显示

-
没有Source或者Sink进行选择

-
任务无法正常执行
3.2.3.1.获取下载脚本
数据源JAR包的下载脚本在seatunnel-web的源码包中存在,它的目录在:

修改配置文件如下:

执行脚本,下载数据源JAR包

正在下载

成功下载下所有的datasourceJAR包

3.2.3.2.上传到Seatunnel-Web项目的libs目录
将以上所有jar包复制到/opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0/libs目录下

3.2.3.3.上传到Seatunnel引擎服务的lib目录
将以上所有jar包复制到/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/lib目录下

3.2.4.配置元数据MySQL的驱动JAR包
MySQL的驱动包mysql-connector-java-8.0.20.jar自行下载

3.2.4.2.上传到Seatunnel引擎服务的lib目录
将mysql-connector-java-8.0.20.jar包复制到/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/lib下

3.2.5.启动WEB服务
这一步也很容易出错,很多人都配置对了,但是最后启动起来,发现无法通过浏览访问, 查看日志打印如下:
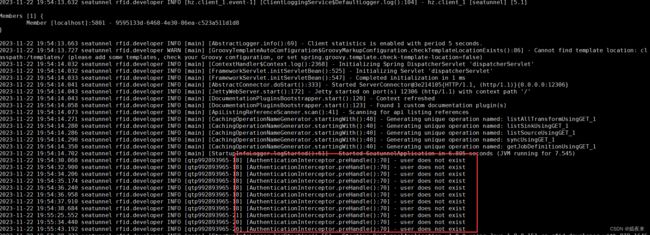
造成这样的问题就是你执行启动命令的位置不对, 注意web服务安装之后的目录结构如下图:

所以启动服务必须要保证服务可以访问到ui目录下的index.html文件才可以,因为项目启动前端的项目路径默认添加了/ui的前缀,所以后端项目的启动路径必须在ui目录的父级目录才可以,所以这里需要再web服务的安装目录下执行启动脚本,举例:
我这里的安装目录是/opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0, 所以我这里直接切换到该目录下,执行以下启动命令:
#进入web服务的安装目录
cd /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0
#执行启动脚本
sudo sh bin/seatunnel-backend-daemon.sh start
访问http://主机IP:12306 (此端口为conf/application.yml中配置的端口), 页面自动跳转到http://主机IP:12306/ui,
默认登录的用户名和密码:
username:admin
password:admin


OK, 至此所有的搭建流程就结束了。
4.资源链接
这里面有些资源的下载特别慢, 这里将整个配置好的前后端的项目资源打包存放到百度网盘,地址如下:
Seatunnel引擎及Web服务一键安装包
下载下来之后,修改所有涉及数据库连接的配置文件为你自己的连接配置信息, 然后执行3.2.1.2小节的初始化数据库命令, 然后依次启动Seatunnel引擎服务、web服务即可。
创作不易,对您有帮助,点个赞呗,感谢~~~~