java 线程应用到项目中去_不看后悔的项目中线程池实际应用

前言:最近在看线程池方面的内容,结合源码学习完其内部原理后,心想自己在项目中有实际使用过线程池吗?想了想,确实在项目中很多地方使用到了线程池;下面来简单聊下最近在日志方面中多线程的应用:服务接口日志异步线程池化入库处理
定时任务中使用多线程进行日志清理

本文主线:
①、线程池基本原理解读;
②、线程池实际应用例子:线程池应用 Demo 项目结构描述
服务接口日志异步线程池化入库处理
定时任务中使用多线程进行日志清理
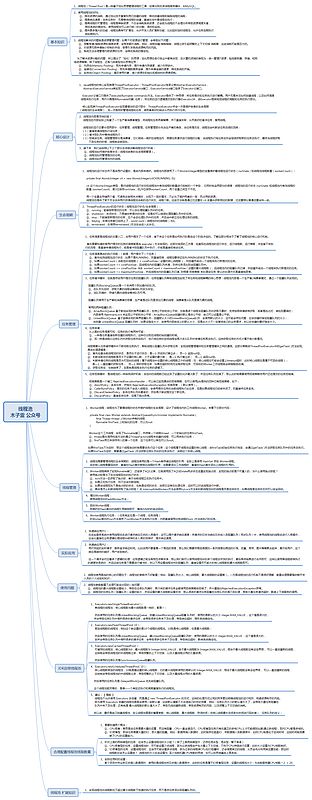
线程池基本原理解读:啥也不说,先贴一张脑图,通过脑图对线程池快速的进行了解;
除了看图外,也可以通过此文章《ava线程池实现原理及其在美团业务中的实践》对线程池进行详细的了解;
线程池实际应用例子:下面就来聊聊最近在项目日志中线程池的应用;
线程池应用Demo项目描述:
上面说的两种日志方面线程池应用已经写好了Demo,是一个 SpringBoot 项目,项目结构如下图:

服务接口日志异步线程池化入库处理:后台服务接口项目中,经常需要对接口的请求报文和响应报文日志做入库保存;
下面将通过对比 普通方式入库操作和线程池方式入库操作 ,来说说为什么线程池式入库更加优雅;
普通方式入库操作:
普通入库就是直接进行完业务逻辑处理并构建好响应后同时将日志进行入数据库,入库成功后再将响应返回;
流程图如下:

但是这样存在一个很大的弊端就是由于多了一次数据库操作(日志入库),进而可能会导致响应速度比较慢;
下面就聊聊怎么通过线程池对日志入库进行优化,提升接口的响应速度;
线程池方式入库操作:
线程池方式入库,可以将日志直接放入到队列中,然后就直接返回响应,最后使用线程池中的线程取出队列中的日志数据异步做入库操作;
流程图如下:

使用线程池方式,处理请求的主线程可以将日志放入到队列后,直接将响应返回,然后再使用线程池中的线程取出队列中的日志数据异步的将其进行入库;由于减少了一次数据库操作,会极大的提升接口响应速度。
下面来看看代码实现:
1、上面说到的存放请求报文和响应报文日志的队列: LinkedBlockingDeque// 基于链表的双向阻塞队列,在队列的两端都可以插入和移除元素,是线程安全的,多线程并发下效率更高
BlockingQueue queue = new LinkedBlockingDeque(MAX_QUEUE_SIZE);
除了 LinkedBlockingDeque 阻塞队列外,还有一些其它经常会用到的阻塞队列,如下图:

2、项目中进行日志入库操作的线程池: 单线程的线程池 + 固定数线程的线程池单线程的线程池:用来循环的监听队列中的日志数量以及决策什么时候将队列中的日志取出交由固定数线程的线程池做入库操作;
固定数线程的线程池:主要用来进行日志的入库操作;
部分代码实现如下:/**
* 初始化
*/
public void init(){
// 基于链表的双向阻塞队列,在队列的两端都可以插入和移除元素,是线程安全的,多线程并发下效率更高
queue = new LinkedBlockingDeque(MAX_QUEUE_SIZE);
lastExecuteTime = System.currentTimeMillis();
logger.info("LogPoolManager init successfully......");
logManagerThreadPool.execute(new Runnable() {
@Override
public void run() {
while (run.get()){
try {
// 线程休眠,具体时间根据项目的实际情况配置
Thread.sleep(SLEEP_TIME);
} catch (InterruptedException e) {
logger.error("log Manager Thread sleep fail ", e);
}
// 满足存放了10个日志 或 满足时间间隔已经大于设置的最大时间间隔时 执行日志插入
if (logCount.get() >= BATCH_SIZE || (System.currentTimeMillis() - lastExecuteTime) > MAX_EXE_TiME) {
if (logCount.get() > 0) {
logger.info("begin drain log queue to database...");
List list = new ArrayList();
/**
* drainTo (): 一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),
* 通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
* 将取出的数据放入指定的list集合中
*/
queue.drainTo(list);
// 任务队列 中任务数量置为0
logCount.set(0);
// 从线程池中取出线程执行日志插入
logWorkerThreadPool.execute(new InsertThread(testLogService, list));
logger.info("end drain log queue to database...");
}
// 获取当前执行的时间
lastExecuteTime = System.currentTimeMillis();
}
}
logger.info("LogPoolManager shutdown successfully");
}
});
}本项目中测试服务接口日志异步线程池化入库处理,项目启动后,在浏览器输入下面URL,并刷新页面即可:
http://127.0.0.1:8081/v1/api/log/test
定时任务中使用多线程进行日志清理:当日志表中的数据量过多,占用了太多的磁盘空间,导致磁盘不断的告警,此时需要对日志表进行瘦身;
此时可以使用多线程将日志表中部分数据清理掉,释放磁盘空间;
日志表中哪些数据需要清理掉呢?下面这个场景就可能会在需求中出现:
领导说需要保留日志表中最新一年的数据,就是从当前日期向前推365天;例如:今天2020-12-30,向前推365天的日期是2019-12-30,所以2019-12-30之前生成的日志都需要清理掉;
下面来看代码,由于需要尽可能保证程序的灵活性,所以需要将删除的表名,根据删除的字段等进行灵活的配置;配置参数如下图: application-cleanLog.properties 配置文件## 线程池大小
threads.pool.num=8
## 需要进行清理的表
log.clean.table=t_test_log
## 清理时根据的字段
log.clean.filed=createts
## 每次清理的数据量大小
log.clean.batchCount=1000
## 每次定时清理时 循环清理的次数
log.clean.batchNum=6
## 需保留据当前多少天的最新数据,其余的数据才可以被清理掉
log.clean.dateNum=1
注意:线程池大小需要结合服务器硬件配置和实际的业务日志量大小进行合理配置;如果设置的过大,可能会占用过多的内存和频繁的进行上下文切换,从而可能导致效率变低;
本项目中是根据日期字段进行数据清理的,如果表已经根据日期进行了分区,可以直接根据分区进行清理,分区清理速度更加快些,但是按分区进行删除本项目中暂未实现;
每次清理的数据量大小:指的是进行一次 delete 时需要删除的数据量;建议不要设置的太大,因为删除的数据量太大的话,可能会导致锁表,从而影响表的正常查询、新增等操作;
定时任务执行时循环清理的次数:指的是定时任务执行时进行几次 delete 操作;上面有说道 每次delete的数据量别设置太大,那么在总清理的数据量不变的情况下,就需要将清理的次数设置大些;
总清理的数据量 = 每次清理的数据量大小 * 清理的次数
多线程进行日志清理的流程图如下所示:
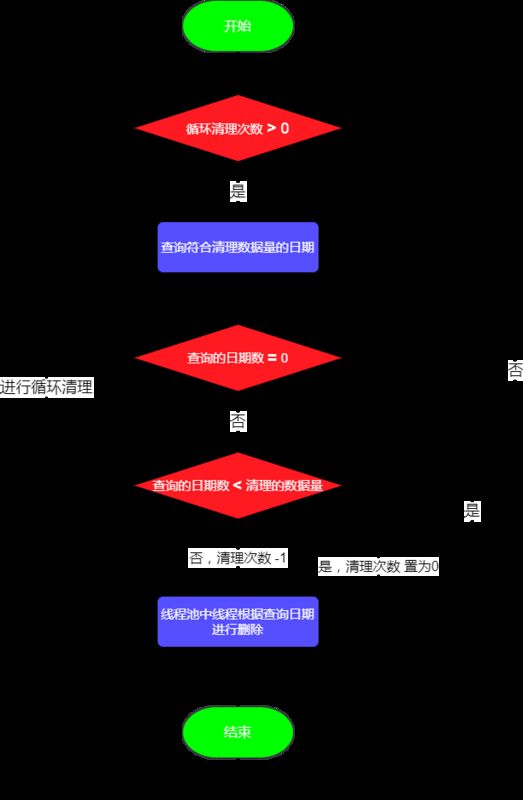
下面来看看代码实现:部分代码实现如下所示:/**
* 多线程清理日志启动
*/
public void cleanLogStart(){
// 循环进行日志清理的次数
int whileNum = props.getInt("log.clean.batchNum");
LogCleanBean logClean = null;
while (whileNum > 0){
// 查询符合每次删除数据量的时间段
List list = logCleanService.selectTime(logCleanBean);
if (list != null && list.size() > 0){
logClean = new LogCleanBean();
logClean.setTableName(logCleanBean.getTableName());
logClean.setFieldName(logCleanBean.getFieldName());
// 获取可以删除日志的最小生成时间
logClean.setMinTime(list.get(list.size()-1));
// 获取可以删除日志的最大生成时间
logClean.setMaxTime(list.get(0));
logCleanBean.setMinTime(logClean.getMinTime());
// 此次查询已经不满足设置的每次清理的数据量大小了,说明已经清理干净了
if (list.size() < logCleanBean.getBatchCleanCount()){
whileNum = 0;
}else {
// 清理次数进行递减
--whileNum;
}
}else {
break;
}
// 进行多线程处理
cleanManagerThreadPool.execute(new CleanThread(this.logCleanService, logClean));
}
}
扩展:
本项目中使用 delete 并且根据时间字段进行的数据删除,如果是 MySql 数据库 的话,则在删除数据后去查看磁盘空间的话,发现可用磁盘空间并没有增多,并且可用磁盘空间还有可能减少了呢,why 为什么?因为在 InnoDB 存储引擎中,delete 其实并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记为已删除,因此 delete 删除表中的数据时,表文件在磁盘上所占空间不会变小,存储空间不会被释放,只是把删除的数据行设置为不可见。然未释放磁盘空间,但是下次插入数据的时候,仍然可以重用这部分空间(重用 → 覆盖)。
并且由于在 delete 删除数据时,会记录 binlog日志 等,如果删除的数据中存在 Text和BLOB 等大字段,可能日志文件会变得额外的大,占用部分磁盘空间 ,这就会导致 free 磁盘空间的进一步减少;
解决方案:如果删除的数据中不存在Text和BLOB 等大字段,可以直接不用管,直接覆盖使用,并且等待MySql 的自动清理操作即可,但是需要一定时间;
可以在delete操作以后使用 optimize table table_name 会立刻释放磁盘空间。但是,由于optimize执行时会将表锁住,所以不要在高峰期使用,也不要经常使用;因为其会阻塞正常的查询、更新等操作的。
也可以使用 truncate 、drop 进行数据的删除,快速释放磁盘空间;具体结合当前项目的实际情况进行选择 。-- END --
本文中介绍了在日志处理场景中线程池的使用场景,除此之外,还有很多场景使用到了线程池,并且在很多框架中也使用到了线程池,大家也可以通过阅读框架源码学习线程池的使用方法。
❤ 点赞 + 评论 + 转发 哟
如果本文对您有帮助的话,请挥动下您爱发财的小手点下赞呀,您的支持就是我不断创作的动力,谢谢啦!
您可以微信搜索【木子雷】公众号,大量Java学习干货文章,您可以来瞧一瞧哟!
