MybatisPlus
目录
1 引入MP依赖代替Mybatis依赖
2 配置yaml
3 继承BaseMapper
3.1 默认约定
3.2 自定义约定
3.3 继承BaseMapper的常用方法
3.3.1 增
3.3.2 删
3.3.3 改
3.3.4 查
4 条件构造器
4.1 QueryWrapper
4.2 UpdateWrapper
4.3 AbstractLambdaWrapper(推荐)
4.4 自定义sql方法
4.4.1 dao接口+xml
4.4.2 用法示例
5 IService接口
5.1 Iservice常用方法
5.2 使用流程
5.3 用法示例
5.4 lambdaQuery()方法、lambdaUpdate()方法
5.5 批量操作
5.5.1 批量操作对比
5.5.2 代码示例
6 多表查询
1 引入MP依赖代替Mybatis依赖
如果你的问题本文解决不了,找MyBatis-Plus官网
com.baomidou
mybatis-plus-boot-starter
3.5.4
2 配置yaml
(见之前文章SpringBoot (2) yaml,整合项目)
3 继承BaseMapper
BaseMapper泛型为所要操作的pojo类,MP依据此泛型通过反射得到类的字节码文件,然后通过字节码信息反推出数据库中的表信息,反推要遵循约定
public interface TeacherDao extends BaseMapper {
} 3.1 默认约定
(1) 类名的驼峰转下划线作为表名: 类名HighSchool反推出的表名就是high_school
(2) 名为id的成员变量作为主键字段
(3) 类成员变量的驼峰转下划线作为字段名
3.2 自定义约定
@TableName用在pojo类上,指定表名
@TableId(value="id", type=IdType.AUTO)用在pojo类成员变量上,指定表主键字段
IdType.AUTO表示自增Id(调用insert方法后,自动给参数的主键成员变量赋值)
IdType.INPUT表示set方法设置,用户自己填写
IdType.ASSING_ID(默认)表示MP会自动利用雪花算法生成long类型的整数,长度20位
@TableField(insertStrategy=FieldStrategy.DEFAULT,updateStrategy=FieldStrategy.DEFAULT,whereStrategy=FieldStrategy.DEFAULT)用在pojo类成员变量上,指定普通字段
FieldStrategy.DEFAULT按照yaml配置文件
FieldStrategy.NOT_NULL非NULL才加入SQL
FieldStrategy.ALWAYS总是加入SQL(无论字段值是否为NULL)
FieldStrategy.NEVER总不加入SQL
(1) 对于is开头并且是boolean类型的pojo成员变量,在通过反射机制会将is去掉,那么就起不到驼峰转下划线的效果,因此is开头的boolean类型的成员变量必须用@TableField注解
(2) 对于关键字的pojo成员变量,必须用@TableField注解,并且要将关键字写在反引号``中
(3) pojo成员变量不是数据库字段,必须用@TableField(exist=false)注解
@TableName("aboluo_person")
public class Person {
@TableId
private Long id;
@TableField("user_name")
private String name;
@TableField("is_man")
private Boolean isMan;
@TableField("`select`")
private Integer select;
@TableField(exist = false)
private String other;
}3.3 继承BaseMapper的常用方法
3.3.1 增
teacherDao.insert(T); //这里的"泛型类"就是BaseMapper的泛型
3.3.2 删
teacherDao.deleteById(5)
teacherDao.delete(Wrapper)
teacherDao.deleteBatchIds(Collection)
3.3.3 改
teacherDao.updateById(T) //非空字段才更新(可以在yaml中设置)
teacherDao.update(Wrapper
) teacherDao.update(T,Wrapper
)
3.3.4 查
单查询:
teacherDao.selectOne(Wrapper
); teacherDao.selectById(6);
多查询:
teacherDao.selectList(Wrapper
); //参数为null表示(无条件)查询所有 teacherDao.selectBatchIds(List.of(1,3,9)); //根据id的List集合查询
4 条件构造器
条件构造器Wrapper支持各种复杂的where条件

4.1 QueryWrapper
下面的关于WHERE的筛选都写在括号中
有些函数可以使用condition参数判断是否执行
例如: .like(condition,column,val) //如果condition是false代表不执行
| 函数名 | 说明 | 示例 |
| .eq | 等于= | .eq("name","张三") |
| .ne | 不等于<> | |
| .gt | 大于> | .gt("age",18) |
| .ge | 大于等于>= | |
| .lt | 小于< | |
| .le | 小于等于<= | |
| .between | BETWEEN值1 AND 值2 #包含值1和值2 | .between("age",18,30) |
| .notBetween | NOT BETWEEN值1 AND 值2 | |
| .like | LIKE'%值%' | .like("name","陈") |
| .likeLeft | LIKE'%值' | |
| .likeRight | LIKE'值%' | |
| .notLike | NOT LIKE'%值%' | |
| .notLikeLeft | NOT LIKE'%值' | |
| .notLikeRight | NOT LIKE'值%' | |
| .isNull | 字段IS NULL | .isNull("name") |
| .isNotNull | 字段IS NOT NULL | |
| .in |
字段IN(v1,v2...) | .in("age",{1,2,3}) |
| .notIn | 字段NOT IN(v1,v2...) | .notIn("age",1,2,3) |
| .inSql | 字段IN(sql语句) | .inSql("id","select id from table where id<3")==>id IN (select id from table where id<3) |
| .notInSql | 字段NOT IN(sql语句) | |
| .groupBy | 分组GROUP BY 字段1,字段2... | .groupBy("id","name") |
| .orderByAsc | 排序ORDER BY 字段1,字段2...ASC | .orderByAsc("id","name") |
| .orderByDesc | 排序ORDER BY 字段1,字段2...DESC | |
| .having | 分组后筛选 | .having("CHAR_LENGTH(name)>{0} and age>{1}", 2, 18) |
| .or |
或OR | 不调用or,则默认使用and eq("naem","张三").or().eq("naem","李四") |
| .apply | 拼接sql | sql在WHERE括号中进行拼接 方式一:(有sql注入问题) .apply("sql1"+变量1+"sql2"+常量+"sql3") 方式二:(不会有sql注入问题) .apply("sql1+{0}+sql2+{1}",变量1,变量2) |
| .last | 在最后面拼接sql | sql在WHERE括号外进行拼接 |
| .exists | 与EXISTS(子查询)作用相同 | |
| .notExist | 与NOT EXISTS(子查询)作用相同 | |
| .setEntity(T) | 不用再一个个设置条件,直接用pojo类作为条件 |
示例1:查询position中带"语文",年龄age大于18的"position,name,age"字段
/*SELECT position, name, age
FROM teacher
WHERE
position LIKE '%语文%'
AND age > 18;*/
QueryWrapper wrapper = new QueryWrapper()
.select("position", "name", "age")
.like("position", "语文")
.gt("age", 18);
List teachers = teacherDao.selectList(wrapper); 示例2:把name为"张三"的Teacher的age修改为33
/*UPDATE teacher
SET age = 45
WHERE
NAME = '张三';*/
Teacher teacher = new Teacher();
teacher.setAge(33);
QueryWrapper wrapper = new QueryWrapper()
.eq("name", "张三");
teacherDao.update(teacher, wrapper);
return Result.success(); 4.2 UpdateWrapper
UpdateWrapper提供了2种修改记录的方式:
(1) 将修改内容放在pojo类中,UpdateWrapper只做where筛选(用法同QueryWrapper)
(2) 直接UpdateWrapper对象.setSql(sql),替代sql中的set
示例3:将所有语文老师的年龄增加1岁
/*UPDATE teacher
SET age = age + 1
WHERE
position = '语文老师';*/
UpdateWrapper wrapper = new UpdateWrapper()
.setSql("age=age+1")
.eq("position", "语文老师");
teacherDao.update(wrapper); 4.3 AbstractLambdaWrapper(推荐)
QueryWrapper和UpdateWrapper在写字段时存在硬编码问题,而LambdaQueryWrapper和LambdaUpdateWrapper就可以解决这个问题
LambdaQueryWrapper替换QueryWrapper:查询position中带"语文",年龄age大于18的"position,name,age"字段
/*SELECT position, name, age
FROM teacher
WHERE
position LIKE '%语文%'
AND age > 18;*/
LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
.select(Teacher::getPosition, Teacher::getName, Teacher::getAge)
.like(Teacher::getPosition, "语文")
.gt(Teacher::getAge, 18);
List teachers = teacherDao.selectList(wrapper); LambdaUpdateWrapper替换UpdateWrapper:将所有语文老师的年龄增加1岁
/*UPDATE teacher
SET age = age + 1
WHERE
position = '语文老师';*/
LambdaUpdateWrapper wrapper = new LambdaUpdateWrapper()
.setSql("age=age+1")
.eq(Teacher::getPosition, "语文老师");
teacherDao.update(wrapper); 4.4 自定义sql方法
✖问题1:Mybatis只有Dao接口,通过xml映射在SpringIOC中生成Dao实例,因此Wrapper只能写在Service层,导致sql语句无法被其它Service复用
✖问题2:条件构造器善于处理where后面的sql,但不善于处理where前的sql(例如:聚合查询,查询字段起别名...),所以只能将sql写在业务层中(如"示例3"),但实际开发中并不建议在业务层写sql
✔解决:用"where前交给xml文件处理,where后交给MP条件构造器处理"方式解决
4.4.1 dao接口+xml
同mybatis一样,在dao接口中自定义sql方法(此方法与xml文件能映射),方法参数是@Param("ew")Wrapper和自定义参数
xml文件中用#{自定义参数},${ew.customerSqlSegment}引用
4.4.2 用法示例
示例1:查询position中带"语文",年龄age大于18的"position,name,age"字段
//dao接口
public interface TeacherDao extends BaseMapper {
List customSQL1(@Param("ew") LambdaQueryWrapper wrapper);
}
//xml文件
//使用"自定义sql"
@RequestMapping("/customSQL1.do")
public Result customSQL1() {
LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
.like(Teacher::getPosition, "英语")
.gt(Teacher::getAge, 18);
List teachers = teacherDao.customSQL1(wrapper);
return Result.success(teachers);
} 示例2:把name为"张三"的Teacher的age修改为33
//dao接口
public interface TeacherDao extends BaseMapper {
Integer customSQL2(@Param("ew") LambdaQueryWrapper wrapper, @Param("teacher") Teacher teacher);
}
//xml文件
update teacher set age=#{teacher.age} ${ew.customSqlSegment}
//使用"自定义sql"
@RequestMapping("/customSQL2.do")
public Result customSQL2() {
Teacher teacher = new Teacher();
teacher.setAge(33);
LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
.eq(Teacher::getName, "张三");
teacherDao.customSQL2(wrapper, teacher);
return Result.success();
}
//使用BaseMapper方法
@RequestMapping("/customSQL3.do")
public Result customSQL3() {
LambdaUpdateWrapper wrapper = new LambdaUpdateWrapper()
.set(Teacher::getAge,33)
.eq(Teacher::getName, "张三");
teacherDao.update(wrapper);
return Result.success();
} 5 IService接口
BaseMapper接口是增强Dao接口的,dao接口直接继承BaseMap"增删改查"等方法
IService接口是增强Service接口的,Service接口直接继承IService"增删改查"等方法
5.1 Iservice常用方法
| 类型 | 方法 | 说明 |
| 增 | save(T) | |
| saveBatch(Collection |
||
| saveOrUpdate(T) | ||
| saveOrUpdate(T,Wrapper |
||
| saveOrUpdateBatch(Collection |
||
| 删 | remove(Wrapper |
|
| removeById(T) | ||
| removeBatchByIds(Collection) | ||
| 改 | update(Wrapper |
|
| update(T,Wrapper |
||
| updateById(T) | ||
| updateBatchById(Collectiion |
||
| 查 | getById(Serializable) //参数是泛型T,并且T继承Serializable,并且用@TableId标记出那个字段是ID | 查询一个用get开头 |
| getOne(Wrapper |
||
| listByIds(Collection) | 查询多个用list开头 | |
| list(Wrapper |
参数null,表示查所有 | |
| lambdaQuery(T) | 参数null,表示查所有 | |
| lambdaUpdate() | ||
| 其它 | count(Wrapper |
统计(参数null,表示统计所有) |
| page(E) | 分页查询 | |
| page(E,Wrapper |
5.2 使用流程
因为dao接口是通过xml文件在SpringIOC中反射生成实现类,dao接口直接继承BaseMapper就可以用了,因此不需要写实现类
继承Iservice接口的xxxService接口有xxxServiceImpl实现类,并且实现类需要重写xxxService接口方法和Iservice接口方法,但在实际开发中我们只想重写自定义的xxxService接口,不想重写Iservice接口方法,xxxServiceImpl可以继承MP提供的ServiceImpl方法
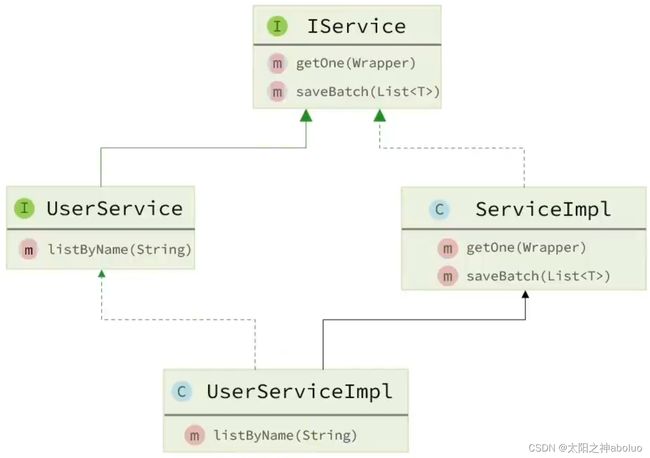
5.3 用法示例
(1) xxxService继承IService接口要写pojo泛型
(2) xxxServiceImpl继承ServiceImpl要写dao泛型和pojo泛型
//xxxService
public interface TeacherService extends IService {
}
//xxxServiceImpl
@Service
public class TeacherServiceImpl extends ServiceImpl implements TeacherService {
}
//查询position中带"语文",年龄大于18的"position,name,age"字段
@RequestMapping("/service3.do")
public Result service3() {
LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
.select(Teacher::getPosition, Teacher::getName, Teacher::getAge)
.like(Teacher::getPosition, "语文")
.gt(Teacher::getAge, 18);
return Result.success(teacherService.list(wrapper));
}
//把name为"张三"的Teacher的age修改为33(方式一)
@RequestMapping("/service4.do")
public Result service4() {
Teacher teacher = new Teacher();
teacher.setAge(33);
LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
.eq(Teacher::getName, "张三");
teacherService.update(teacher, wrapper);
return Result.success();
}
//把name为"张三"的Teacher的age修改为33(方式二)
@RequestMapping("/service5.do")
public Result service5() {
LambdaUpdateWrapper wrapper = new LambdaUpdateWrapper()
.set(Teacher::getAge, 33)
.eq(Teacher::getName, "张三");
teacherService.update(wrapper);
return Result.success();
} 5.4 lambdaQuery()方法、lambdaUpdate()方法
这2个方法通常用于复杂条件的查询
lambdaQuery().one表示查一条记录.list查多条记录.page分页查询.count统计
lambdaUpdate().set表示设置字段值.update(T)表示执行lambdaUpdate更新 //更新哪些字段可以以.set方法规定的字段为准,也可以以T中的非空成员变量为准
lambdaQuery()示例:根据"position模糊"查询,"name精确"查询,"大于age"查询,并且position,name,age3个字段允许为null,当为null时对此字段不做筛选
//xxxService
public interface TeacherService extends IService {
Result lambdaQuery1(Teacher teacher);
}
//xxxServiceImpl
@Service
public class TeacherServiceImpl extends ServiceImpl implements TeacherService {
@Override
public Result lambdaQuery1(Teacher teacher) {
List teachers = lambdaQuery()
//第一个参数condition表示判断,如果为true则执行这一步筛选
.like(teacher.getPosition() != null, Teacher::getPosition, teacher.getPosition())
.eq(teacher.getName() != null, Teacher::getName, teacher.getName())
.gt(teacher.getAge() != null, Teacher::getAge, teacher.getAge())
.list();
return Result.success(teachers);
}
}
//使用
@RequestMapping("/lambdaQuery1.do")
public Result lambdaQuery1(@RequestBody Teacher teacher) {
return Result.success(teacherService.lambdaQuery1(teacher));
} lambdaUpdate()示例:将name为"张三"的用户年龄-200岁,如果年龄不足则操作失败
//xxxDao
public interface TeacherService extends IService {
Result lambdaQuery2();
}
//xxxDaoImpl
@Service
public class TeacherServiceImpl extends ServiceImpl implements TeacherService {
@Override
public Result lambdaQuery2() {
//去数据库查询name为"张三"的Teacher
LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
.eq(Teacher::getName, "张三");
Teacher teacher = getOne(wrapper);
Integer restMoney = teacher.getAge() - 200;
//修改余额
lambdaUpdate()
.set(restMoney >= 0, Teacher::getAge, restMoney)
.set(restMoney < 0, Teacher::getAge, teacher.getAge())//总有一条生效,防止都不生效导致sql错误
.eq(Teacher::getName, "张三")
.eq(Teacher::getAge, teacher.getAge())//此处是为了防止并发冲突(之前查到的age要和现在set操作时的age相同)
.update();
return Result.success();
}
}
//使用
@RequestMapping("/lambdaQuery2.do")
public Result lambdaQuery2() {
teacherService.lambdaQuery2();
return Result.success();
} 5.5 批量操作
5.5.1 批量操作对比
(1) 使用for循环逐条将sql交给mysql处理(性能极低,每执行一条sql,后台就与mysql通讯一次)
(2) MP基于预编译批量处理(例如xxxDao.saveBatch(list)),将多条sql统一交给(也不能一次给太多,对内存压力大)mysql处理(性能一般,虽然将多条sql统一交给mysql,但mysql依旧是一条条执行)
(3) 将多条sql写作一条sql 例如:多条INSERT INTO table(xx,xx,xx) VALUE (yy,yy,yy) ==> 一条INSERT INTO table(xx,xx,xx) VALUES (yy,yy,yy),(yy,yy,yy)
方式一: 使用手写拼接(不推荐)
方式二: 配置mysql的jdbc驱动(开启rewriteBatchedStatements=true),开启mysql将多条sql整合成一条sql执行
5.5.2 代码示例
例:新增10000条数据,使用"逐条新增"的方式 //耗时28817ms
@RequestMapping("/batch1.do")
public void batch1() {
//向数据库逐条插入10000条数据
for (int i = 0; i < 10000; i++) {
Teacher teacher = createTeacher(i);
teacherService.save(teacher);
}
}
public Teacher createTeacher(Integer positionNo) {
Teacher teacher = new Teacher();
teacher.setPosition("" + positionNo);
return teacher;
}例:新增10000条数据,使用"预编译"的方式 //耗时3020ms
@RequestMapping("/batch2.do")
public void batch2() {
long time1 = System.currentTimeMillis();
//每次向数据库插入1000条(一次插入过多对内存要求压力大),插入10次
for (int i = 1; i <= 10000; i++) {
teachers.add(createTeacher(i));
if (i % 1000 == 0) {
teacherService.saveBatch(teachers);
teachers.clear();
}
}
}
public Teacher createTeacher(Integer positionNo) {
Teacher teacher = new Teacher();
teacher.setPosition("" + positionNo);
return teacher;
}例:新增10000条数据,使用"预编译"+"sql整合"的方式 //耗时1284ms
spring:
datasource:
url: jdbc:mysql://localhost:3306/sunner?rewriteBatchedStatements=true6 多表查询
(使用.xml文件)