Go 学习笔记(76)— Go 标准库 net/http 创建客户端(发送 GET、POST 请求)
1. Get 请求
1.1 使用 net/http 包的快捷方法 GET
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
resp, err := http.Get("http://www.baidu.com")
if err != nil {
fmt.Println(err)
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(body))
}
1.2 自定义客户端
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
client := &http.Client{}
request, err := http.NewRequest("GET", "http://www.baidu.com", nil)
if err != nil {
fmt.Println(err)
}
resp, err := client.Do(request)
if err != nil {
fmt.Println(err)
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(body))
}
使用自定义 HTTP 客户端意味着可对请求设置报头、基本身份验证和 cookies 。鉴于使用快捷方法和自定义HTTP 客户端时, 发出请求所需代码的差别很小, 建议除非要完成的任务非常简单,否则都使用自定义HTTP 客户端。
2. POST 请求
package main
import (
"fmt"
"io/ioutil"
"net/http"
"strings"
)
func main() {
data := strings.NewReader(`{"some": "json"}`)
resp, err := http.Post("https://httpbin.org/post", "application/json", data)
if err != nil {
fmt.Println(err)
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(body))
}
输出结果:
{
"args": {},
"data": "{\"some\": \"json\"}",
"files": {},
"form": {},
"headers": {
"Accept-Encoding": "gzip",
"Content-Length": "16",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "Go-http-client/2.0",
"X-Amzn-Trace-Id": "Root=1-60575025-22341e95217463712e18068e"
},
"json": {
"some": "json"
},
"origin": "192.168.0.110",
"url": "https://httpbin.org/post"
}
3. 调试 HTTP
net/http/httputil 也提供了能够让您轻松调试 HTTP 客户端和服务器的方法。这个包中的方法DumpRequestOut 和 DumpResponse 能够让您查看请求和响应。
可对前一个示例进行改进,以使用 net/http/httputil 包中的 DumpRequestOut 和 DumpResponse
方法来支持日志功能。这些方法显示请求和响应的报头,还有返回的响应体。
package main
import (
"fmt"
"io/ioutil"
"net/http"
"net/http/httputil"
"strings"
)
func main() {
client := &http.Client{}
data := strings.NewReader(`{"some": "json"}`)
request, err := http.NewRequest("POST", "https://httpbin.org/post", data)
request.Header.Add("Accept", "application/json") // 增加请求报文头
/*
通过使用 Accept 报头, 客户端告诉服务器它想要的是 application/json,而服务器返回数
据时将 Content-Type 报头设置成了application/json。
*/
if err != nil {
fmt.Println(err)
}
debugReq, err := httputil.DumpRequestOut(request, true)
if err != nil {
fmt.Println(err)
}
fmt.Println("debugReq is ", string(debugReq))
resp, err := client.Do(request)
if err != nil {
fmt.Println(err)
}
defer resp.Body.Close()
debugResponse, err := httputil.DumpResponse(resp, true)
if err != nil {
fmt.Println(err)
}
fmt.Println("debugResponse is ", string(debugResponse))
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(body))
}
输出结果:
debugReq is POST /post HTTP/1.1
Host: httpbin.org
User-Agent: Go-http-client/1.1
Content-Length: 16
Accept: application/json
Accept-Encoding: gzip
{"some": "json"}
debugResponse is HTTP/2.0 200 OK
Content-Length: 441
Access-Control-Allow-Credentials: true
Access-Control-Allow-Origin: *
Content-Type: application/json
Date: Sun, 21 Mar 2021 14:35:01 GMT
Server: gunicorn/19.9.0
4. 处理超时
使用默认的 HTTP 客户端时,没有对请求设置超时时间。这意味着如果服务器没有响应,则请求将无限期地等待或挂起。对于任何请求,都建议设置超时时间。这样如果请求在指定的时间内没有完成, 将返回错误。
client := &http.Client{
Timeout: 1 * time.Second,
}
上述配置要求客户端在 1s 内完成请求。但是因为服务器的响应速度不够快。完全有可能发生请求超时的情况。如下:
Post https://httpbin.org/post: net/http:
request canceled (Client.Timeout exceeded while awaiting headers)
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x40 pc=0x63491b]
5. 使用 curl 命令访问网址
$ curl www.baidu.com -vvv
* Trying 220.181.38.150:80...
* TCP_NODELAY set
* Connected to www.baidu.com (220.181.38.150) port 80 (#0)
> GET / HTTP/1.1
> Host: www.baidu.com
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Accept-Ranges: bytes
< Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
< Connection: keep-alive
< Content-Length: 2381
< Content-Type: text/html
< Date: Sun, 11 Dec 2022 01:34:35 GMT
< Etag: "588604c8-94d"
< Last-Modified: Mon, 23 Jan 2017 13:27:36 GMT
< Pragma: no-cache
< Server: bfe/1.0.8.18
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<
<!DOCTYPE html>
........
* Connection #0 to host www.baidu.com left intact
使用 curl 命令的 -vvv 标识可以打印出详细的协议日志,下面我逐行解读一下。
- 第一行:curl 命令是执行 HTTP 请求的常见工具。其中,www.baidu.com是域名。
- 第二行通过 DNS 解析出它对应的 IP 地址为 110.242.68.3。
- 第三行:“TCP_NODELAY set ”表明 TCP 正在无延迟地直接发送数据,TCP_NODELAY 是 TCP 众多选项的一个。
- 第四行:“port 80” 代表连接到服务的 80 端口, 80 端口其实是 HTTP 协议的默认端口。
- 有> 标识的 5-8 行数据才是真正发送到服务器的 HTTP 请求。数据 GET / HTTP/1.1 表明当前使用的是 HTTP 的 GET 方法,并且协议版本是 HTTP1.1。
- HTTP 协议可以在请求头中加入多个 key-value 信息。第六行“Host: www.baidu.com”表示当前请求的主机,我们这里是百度的域名。第七行“User-Agent”表示最终用户发出 HTTP 请求的计算机程序,在这里是 curl 工具。
- 另外,第七行 Accept 标头还告诉我们 Web 服务器客户端可以理解的内容类型。这里 / 表示类型不限,可能是图片、视频、文字等。
- 十到十七行表示服务端返回的信息,它们的规则跟前面类似。“HTTP/1.1 200 OK ”是服务器的响应。服务器使用 HTTP 版本和响应状态码进行响应。状态码 1XX 表示信息,2XX 表示成功,3XX 表示重定向,4XX 表示请求有问题,5XX 表示服务器异常。在这里状态码为 200 ,说明响应成功了。
- 第十二行:“Content-Length: 2381 ”表明服务器返回消息的大小为 2381 字节。下一行的“Content-Type: text/html ”表明当前返回的是 HTML 文本。
- 第十四行:“Date: Mon, 27 Jun 2022 16:04:17 GMT ”是当前 Web 服务器生成消息时的格林威治时间。
- 第十五行:“Set-Cookie”的意思是,服务器让客户端设置 cookie 信息,这样客户端再次请求该网站时,HTTP 请求头中将带上 cookie 信息,这样服务器可以减少鉴权操作,从而加快消息处理和返回的速度。
- 一连串响应头的后面是百度返回的 HTML 文本,这就是我们在浏览器上访问页面的源代码,并最终被浏览器渲染。
- 最后 * Closing connection 0 表明连接最终被关闭。
6. HTTP 请求底层原理
借助 epoll 多路复用的机制和 Go 语言的调度器,Go 可以在同步编程的语义下实现异步 I/O 的网络编程。在这个认知基础上,我们继续来看看 HTTP 标准库如何高效实现 HTTP 协议的请求与处理。
当 http.Get 函数完成基本的请求封装后,会进入到核心的主入口函数 Transport.roundTrip,参数中会传递 request 请求数据。
Transport.roundTrip 函数会选择一个合适的连接来发送这个 request 请求,并返回 response。整个流程主要分为两步:
- 使用
getConn函数来获得底层TCP连接; - 调用
roundTrip函数发送request并返回response,此外还需要处理特殊协议,例如重定向、keep-alive等。
要注意的是,并不是每一次 getConn 函数都需要经过 TCP 的 3 次握手才能建立新的连接。具体的 getConn 函数如下:
// 获取链接
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {
...
// 第一步,查看idle conn连接池中是否有空闲链接,如果有,则直接获取到并返回。如果没有,当前w会放入到idleConnWait等待队列中。
if delivered := t.queueForIdleConn(w); delivered {
pc := w.pc
return pc, nil
}
// 如果没有闲置的连接,则尝试与对端进行tcp连接。
// 注意这里连接是异步的,这意味着当前请求是有可能提前从另一个刚闲置的连接中拿到请求的。这取决于哪一个更快。
t.queueForDial(w)
// Wait for completion or cancellation.
// 拿到conn后会close(w.ready)
select {
case <-w.ready:
return w.pc, w.err
// 处理请求的退出与
case <-req.Cancel:
return nil, errRequestCanceledConn
...
}
return nil, err
}
}
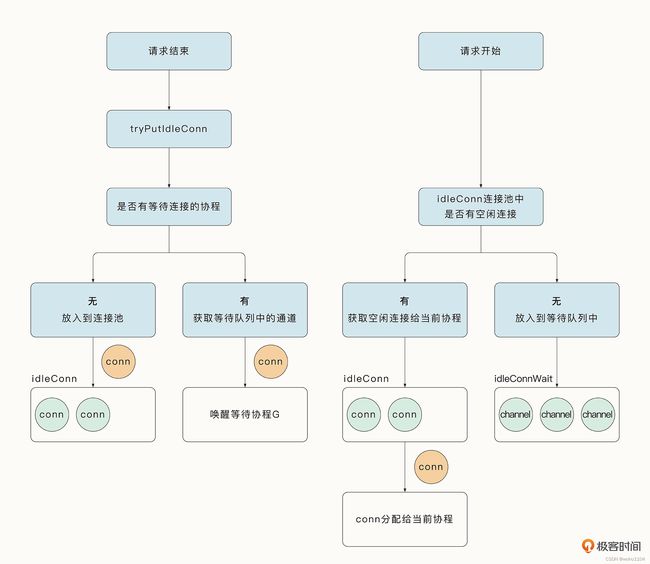
可以看到,Go 标准库在这里使用了连接池来优化获取连接的过程。之前已经与服务器完成请求的连接一般不会立即被销毁(HTTP/1.1 默认使用了 keep-alive:true,可以复用连接),而是会调用 tryPutIdleConn 函数放入到连接池中。通过下图左侧的部分可以看到请求结束后连接的归宿(连接也可能会直接被销毁,例如请求头中指定了 keep-alive 属性为 false 或者连接已经超时)。

使用连接池的收益是非常明显的,因为复用连接之后就不用再进行 TCP 三次握手了,这大大减少了请求的时间。举个特别的例子,在使用了 HTTPS 协议时,在三次握手基础上还增加了额外的鉴权协调,初始化的建连过程甚至需要花费几十到上百毫秒。
另外连接池的设计也很有讲究,例如连接池中的连接到了一定的时间需要强制关闭。获取连接时的逻辑如下:
- 当连接池中有对应的空闲连接时,直接使用该连接;
- 当连接池中没有对应的空闲连接时,正常情况下会通过异步与服务端建连的方式获取连接,并将当前协程放入到等待队列中。
连接的第一步是通过 Resolver.resolveAddrList 方法访问 DNS 服务器,获取 www.baidu.com 网站对应的 IP 地址。下面这张图展示了借助 DNS 协议查找域名对应的 IP 地址的过程。
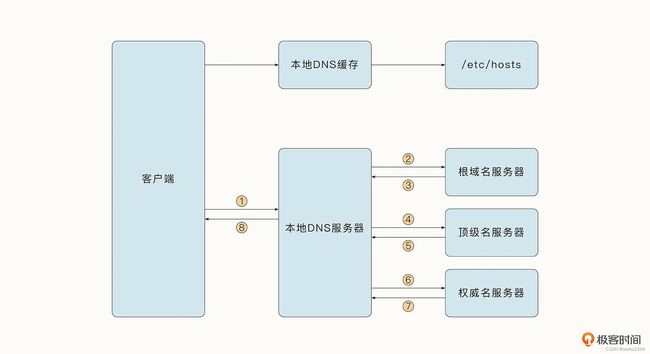
客户端首先查看是否有本地缓存,如果没有,则会用递归方式从权威域名服务器中获取 DNS 信息并缓存下来。
在与远程服务器建连的过程中,当前的协程会进入阻塞等待的状态。正常情况下,当前请求的协程会等待连接完毕。但是因为建立连接的过程还是比较耗时的,所以如果在这个过程中正好有一个其他连接使用完了,协程就会优先使用该连接。
这种巧妙的设计依托了轻量级协程的优势,获取连接的具体流程如下图右侧所示:
为利用协程并发的优势,Transport.roundTrip 协程获取到连接后,会调用 Transport.dialConn 创建读写 buffer 以及读数据与写数据的两个协程,分别负责处理发送请求和服务器返回的消息:
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
...
// buffer
pconn.br = bufio.NewReaderSize(pconn, t.readBufferSize())
pconn.bw = bufio.NewWriterSize(persistConnWriter{pconn}, t.writeBufferSize())
// 创建读写通道,writeLoop用于发送request,readLoop用于接收响应。roundTrip函数中会通过chan给writeLoop发送
// pconn.br给readLoop使用,pconn.bw给writeLoop使用
go pconn.readLoop()
go pconn.writeLoop()
}
整个处理流程和协程间协调如下图所示:
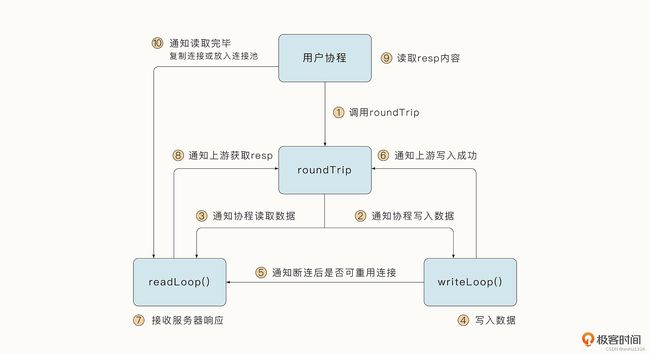
HTTP 请求调用的核心函数是 roundTrip,它会首先传递请求给 writeLoop 协程,让 writeLoop 协程写入数据。接着,通知 readLoop 协程让它准备好读取数据。等 writeLoop 成功写入数据后,writeLoop 会通知 readLoop 断开后是否可以重用连接。然后 writeLoop 会通知上游写入是否成功。如果写入失败,上游会直接关闭连接。
当 readLoop 接收到服务器发送的响应数据之后,会通知上游并且将 response 数据返回到上游,应用层会获取返回的 response 数据,并进行相应的业务处理 。应用层读取完毕 response 数据后,HTTP 标准库会自动调用 close 函数,该函数会通知 readLoop “数据读取完毕”。这样 readLoop 就可以进一步决策了。readLoop 需要判断是继续循环等待服务器消息,还是将当前连接放入到连接池中,或者是直接销毁。
Go HTTP 标准库使用了连接池等技术帮助我们更好地管理连接、高效读写消息、并托管了与操作系统之间的交互。
本小节来源:
https://time.geekbang.org/column/article/604252