深入理解计算机系统——第六章 The Memory Hierarchy
深入理解计算机系统——第六章 The Memory Hierarchy
- 6.1 Storage Technologies
-
- 6.1.1 Random Access Memory
-
- Nonvolatile Memory
- Accessing Main Memory
- Disk Geometry
- Connecting I/O Devices
- 6.1.3 Solid State Disks
- 6.1.4 Storage Technology Trends
- 6.2 Locality
- 6.3 The Memory Hierarchy
-
- 6.3.1 Caching in the Memory Hierarchy
- 6.4 Cache Memories
-
- 6.4.1 Generic Cache Memory Organization
- 6.4.2 Direct-Mapped Caches
- 6.4.3 Set Associative Caches
- 6.4.4 Fully Associative Caches
- 6.4.5 Issues with Writes
- 6.4.6 Anatomy of a Real Cache Hierarchy
- 6.4.7 Performance Impact of Cache Parameters
-
- Impact of Cache Size
- Impact of Block Size
- Impact of Associativity
- Impact of Write Strategy
- 6.5 Writing Cache-Friendly Code
- 6.6 Putting It Together: The Impact of Caches on Program Performance
-
- 6.6.1 The Memory Mountain
- 6.6.2 Rearranging Loops to Increase Spatial Locality
- 6.6.3 Exploiting Locality in Your Programs
资源:
视频课程
视频课件1
视频课件2
请问CPU,内核,寄存器,缓存,RAM,ROM的作用和他们之间的联系?
前面讲汇编语言时,提到将内存当作一个字节数组,可以用地址作为下标来访问该数组的元素。
但实际上存储系统(memory system)是一个非常复杂的设备层次结构(hierarchy of devices),它提供一个抽象,将内存结构抽象为一个大的线性数组。
6.1 Storage Technologies
6.1.1 Random Access Memory
特点:
RAMis traditionally packaged as a chip.- Basic storage unit is normally a
cell(one bit per cell). - Multiple RAM chips form a memory.
分类,根据存储单元(cell) 的实现方式:
- SRAM (Static RAM)
- DRAM (Dynamic RAM)
两者区别见下图:

-
DRAM只需要1个晶体管(transistor) 去存储1比特(bit),而SRAM更复杂,需要 4 或者 6个晶体管,因此SRAM的成本更高,但访问速度更快。 -
DRAM对干扰很敏感(DRAM memory cell is very sensitive to any disturbance),因此需要刷新(The memory system must periodically refresh every bit of memory by reading it out and then rewriting it. ),做错误检测等。 -
SRAM不需要刷新,只要不断电,能保持稳定(Even when a disturbance, such as electrical noise, perturbs the voltages, the circuit will return to the stable value when the disturbance is removed.)。 -
SRAM用于那些内存容量小但速度快的芯片中,叫高速缓存(cache memory). -
DRAM被广泛用于主存(main memory),以及图形中的帧缓存(frame buffers associated with graphic cards)中。
相同点:
两者都是易失的(volatile),即断电将会丢失保存的信息。
Nonvolatile Memory
非易失性存储器(nonvolatile memory),即在断电后也能保存其内容,因为历史的原因,这些存储器被叫只读存储器(read-only memories, ROMs),但其实有些 ROMs 也能写数据。
类型:
-
Read-only memory (ROM): programmed during production.
-
Programmable ROM (PROM) : can be programmed exactly once.
-
Erasable programmable ROM (EPROM): can be erased and reprogrammed on the order of 1,000 times.
-
Electrically erasable PROM (EEPROM): electronic erase capability (it does not require a physically separate programming device). An EEPROM can be reprogrammed on the order of 1 0 5 10^5 105 times before it wears out.
-
Flash memory: based on EEPROMs, with partial (block-level) erase capability.
用途:
-
固件(firmware)中使用
Programs stored in ROM devices are often referred to as firmware. When a computer system is powered up, it runs firmware stored in a ROM.
Some systems provide a small set of primitive input and output functions in firmware—for example, a PC’s BIOS (basic input/output system) routines.
Complicated devices such as graphics cards and disk drive controllers also rely on firmware to translate I/O (input/output) requests from the CPU. -
固态硬盘(Solid state disks, SSD)中使用
系统仍将它当作传统的旋转硬盘(rotating disks),但它更快。
Accessing Main Memory
总线(bus):a collection of parallel wires that carry address, data, and control signals.
Data flows back and forth between the processor and the DRAM main memory over shared electrical conduits called buses.
Buses are typically shared by multiple devices.
Each transfer of data between the CPU and memory is accomplished with a series of steps called a bus transaction.
示例:

例如执行 load 操作,即将主存中的数据写到 CPU 中:
movq A,%rax
操作过程为:
CPU 将地址 A 放到系统总线上,然后通过 I/O bridge 传输到存储器总线上, 主存接收到该信号后读取地址 A 处的数据并写到存储器总线上,最后经过系统总线传给 CPU,CPU 读取总线上的数据后复制到寄存器 %rax 中。
如果执行 store 操作则是相反的过程,即将 CPU 中的数据写入到主存,如:
movq %rax,A
操作过程为:
CPU 将地址 A 放到系统总线上,然后通过 I/O bridge 传输到存储器总线上, 主存接收到该信号后读取地址 A 并等待数据到达;然后 CPU 将寄存器 %rax 的内容复制到系统总线上,最终主存从存储总线上读取数据并存储在地址 A 处。
注意:从图中可以看到寄存器文件(register file)和 算术逻辑单元 (ALU)很近,因此它们之间的操作很快;但内存是离 CPU 相对较远的一些芯片组,因此读写内存的操作相对较慢。
Disk Geometry
这一小节没看书,视频讲的很清楚,很好理解。

-
Notice that manufacturers express disk capacity in units of gigabytes (GB) or terabytes (TB), where 1 GB = 1 0 9 10^9 109 bytes and 1 TB = 1 0 12 10^{12} 1012 bytes. (注意厂商表示磁盘容量不是用二进制,而是十进制)
-
这种磁盘访问速度比 DRAM 慢了接近 250 倍。
-
现代磁盘控制器将磁盘作为一系列的逻辑块提供给 CPU,每个块是扇区大小的整数倍,一个扇区是 512 bytes,最简单的情况下,一个逻辑块就是一个扇区,块号是一系列增长的数字,从 0 开始,0, 1,2 ,等。磁盘控制器控制物理扇区和逻辑块的映射。
-
磁盘控制器会将一些柱面保留作为备用柱面,这些区域没有被映射为逻辑块,如果有个柱面的扇区坏了,磁盘控制器将数据复制到备用的柱面,然后磁盘就能继续正常工作。因此磁盘的格式容量(formatted capacity)比实际容量小。
Connecting I/O Devices
Figure 6.11 shows a representative I/O bus structure that connects the CPU, main memory, and I/O devices.

读取磁盘扇区的过程:
1、 CPU 通过三个指令初始化磁盘
- 给磁盘发送一个读的命令告诉磁盘执行读操作,同时告诉磁盘当读数据结束后是否给 CPU 发一个中断信号
- 第二条指令告诉磁盘读取数据逻辑块编号
- 第三条指令告诉读取扇区的内容后存放在主存中的地址
2、 磁盘读取数据,同时 CPU 继续做其他事,磁盘取得总线的控制权直接复制数据,然后通过 I/O 桥将数据传输给主存,此过程无 CPU 参与,该过程称为直接存储访问 (direct memory access, DMA)。
3、 在 DMA 过程结束后,磁盘控制器给 CPU 发送一个中断信号通知 CPU。This causes the CPU to stop what it is currently working on and jump to an operating system routine. The routine records the fact that the I/O has finished and then returns control to the point where the CPU was interrupted. 例如,如果目前有某个程序等着将数据写到内存中,那么CPU可执行该操作并处理内存(之前总线控制交给磁盘)。

这种直接存储访问的方式原因是:磁盘读数据过程很慢,CPU 如果等磁盘读数据,则太浪费时间。
6.1.3 Solid State Disks
固态硬盘(SSD)的访问速度介于旋转磁盘和 DRAM 之间。
对于 CPU 来说,固态硬盘和旋转磁盘完全相同,它们有相同的接口,但固态硬盘没有那些机械部件,他是完全由闪存构建。

见上图所示,固态硬盘中有一个固件(firmware)设备 ,称为闪存翻译层(flash translation layer),充当旋转磁盘中磁盘控制器(disk controller)的功能。
固态硬盘中以页(page)为单位从闪存中读写数据,页的大小根据技术的不同,通常在 512 字节 to 4 KB。
一系列的页组成一块(block),注意这个块和前面提到的的逻辑块不同。
写数据:如果要写数据到某一页,必须保证该页所在的块的内容全部被擦除(erased),因此在写数据前必须将该块的其他页的数据内容复制到一个新的已经被擦除的块中,因此写操作很复杂。
读数据:直接读取。
一个块被反复擦除大约10万次后将被磨损,无法使用。
SSD 的性能:

从上图可见:
- 顺序访问(Sequential access)比随机访问(Random access)更快;
- 随机写数据的速度十分慢,因为前面提到的要擦除和复制的过程。
SSD 和 旋转磁盘 的比较:
1)优点
- SSD 没有移动部分,因此读写速度更快,耗电更少,更结实。
2)缺点
-
可能磨损,但对于现在的固态硬盘,可能该问题没有跟大影响,如 Intel SSD 730 在磨损前可以写 128 PB(petabyte) 次。
-
比旋转磁盘贵。
6.1.4 Storage Technology Trends
下图展示了不同存储设备相对于 CPU 的性能:

y 轴表示访问时间,在 2003 以前,制造商通过减小CPU的尺寸, 让各个部分更紧密,按比例增加时钟频率,从而使 CPU 的时钟周期更短。
但由于时钟频率越高,消耗的功率越大,因此在 2003 因为功率的问题达到瓶颈,停止继续增加时钟频率。
为了时 CPU 更快,2003 年后开始在芯片上放置更多处理器内核(process cores),将 CPU 芯片细分为独立的处理器内核,每个内核可以执行自己的指令,通过并行运行,提高效率。
现代的 CPU 执行时间逐渐趋于稳定。
从图中可以看出,旋转磁盘,SSD,DRAM 和 CPU 访问时间相差很大,而程序使用的数据很多存在磁盘和内存中,因此尽管 CPU 的执行时间越来越短,但存储设备的访问速度却基本不变,甚至相对来说越来越慢,那么计算机的性能实际不会增加,因为受访问数据的时间限制。
6.2 Locality
The key to bridging this CPU-Memory gap is a fundamental property of computer programs known as locality.
Principle locality : Programs tend to use data and instructions with address near or equal to those they have used recently.
局部性有两种形式:
-
Temporal locality
Recently referenced items are likely to be referenced again in the near future. -
Spatial locality
If a memory location is referenced once, then the program is likely to reference a nearby memory location in the near future.
示例:

上述代码分析:
- 循环内部每次引用数组元素,由于是连续的步长为1的引用,因此是 Spacial locality。
- 循环内每次对
sum变量的引用属于 temporal locality。 - 循环内每次迭代引用一系列的指令,属于 spacial locality。
- 每次循环都要循环使用相同的指令,属于 temporal locality。
对程序局部性的评估:

图 6.18 的程序局部性好,而图 6.19 程序的局部性差。
第二段代码的 spacial locality 很差,因为不是连续的访问数组元素,数组的元素在内存中是按行存储的(row-major order,row-wise)。
6.3 The Memory Hierarchy
Some fundamental and enduring properties of storage technology and computer software:
-
Faster storage technologies cost more per byte than slower ones and have less capacity and require more power (heat!).
-
The gap between CPU and main memory speed is widening.
-
Well-written programs tend to exhibit good locality.
Their complementary nature suggests an approach for organizing memory systems, known as the memory hierarchy, that is used in all modern computer systems.

在存储器的层次结构中,每一层都包含从下一个较低级别层次所检索的数据。如最顶层的寄存器保存从 L1 高速缓存器中检索的数据。
6.3.1 Caching in the Memory Hierarchy
Cache: A small, fast storage device that acts as a staging area (暂存区) for the data objects stored in a larger, slower device.
Central idea of a memory hierarchy:
For each k, the faster and smaller storage device at level k serves as a cache for the larger and slower storage device at level k+1.
Why do memory hierarchies work?
-
Because programs tend to exhibit locality, programs tend to access the data at level
kmore often than they access the data at levelk+1. 如果要访问第k+1层存储单元,我们将会将其拷贝到第k层,因为很有可能会再次访问它。 -
由于不经常访问
k+1层的数据,因而使用速度更低,更便宜的存储设备。
The basic principle of caching in a memory hierarchy:

缓存是一个通用的概念,能应用于存储器层次结构中的所有层。
Cache Hits: 当程序需要在 k+1 层的数据时,会在 k 层查看是否有该数据,如果正好有,则称为 缓存命中 (cache hit)。
Cache Misses: 当程序需要在 k+1 层的数据时,会在 k 层查看是否有该数据,如果正没有该数据,则称为 缓存未命中 (cache miss);例如上图中如果在 k+1 层查找 块12 的数据,而第 k 层没有,因此会将 k+1 层 块12 的数据复制到 k 层,替换第 k 层中 块9 的数据。
缓存未命中的种类:
-
Cold (compulsory) miss
Cold misses occur because the cache is empty.
这是不可避免的,将数据慢慢填充到空的缓存中的过程称为 warming up your cache。 -
Capacity miss
Occur when the set of active cache blocks (working set) is larger than the cache.
这个是由于缓存的大小有限造成的,例如上图中缓存只有4块,如果需要8块的内容,则会造成 Capacity miss。 不断被程序访问的一组块被称为工作集 (working set),因此当执行不同的程序时,工作集是会变的。 -
Conflict miss
冲突未命中(conflict miss) 和缓存的实现方式有关。大多数缓存,尤其是硬件缓存,由于它们需要设计的较为简单,因此限制了块可以被放置的位置。例如 block i 只能放在 block (i mod cache size) 的地方,以上图为例,缓存的大小为4,如果要取 block 8的数据,则只能放在缓存的第0块,同样,block 9 放在缓存的 block 1处。因此,如果要取的块为 block 0, block 4,block 8,那么计算出来都应该放在缓存 block 0的位置,因此放 block 4时,会覆盖原来 block 0的数据,加入需要循环的访问 block 0,block 8,block 0,block 8,这样就会一直不能命中,即使缓存有多余的空间,但位置的限制导致一直覆盖缓存上 block 0 的数据,造成冲突未命中。
Cache Management:

缓存管理:当有请求从较低的层次中读取内容时,需要有一个过程决定如何处理这个请求,如何将其放入缓存中的某一位置。
6.4 Cache Memories
The memory hierarchies of early computer systems consisted of only three levels: CPU registers, main memory, and disk storage.
However, because of the increasing gap between CPU and main memory, system designers were compelled to insert a small SRAM cache memory, called an L1 cache (level 1 cache) between the CPU register file and main memory.

缓存存储器 (cache memory)在 CPU 芯片上,完全由硬件管理。
上图中位于寄存器文件附近的缓存用于存储主存中经常访问的块。
6.4.1 Generic Cache Memory Organization
因为缓存由硬件管理,因此硬件必须知道如何查找缓存中的块,并确定是否包含特定的块,因此必须以严格且简单的方式去组织缓存存储器。

Valid: 初始时,缓存中没有内容,但上图中 B 字节的块中有一些无效的数据,因此需要 有效位(Valid) 来识别 B 字节中的数据是否有效,0 则无效,1 有效。
Tag: 标志位,帮助搜寻块。
缓存大小: 一个缓存有 S 组,一组有 E 行,一行中的块有 B 字节,因此缓存的大小 C = S * E * B。
块的大小由内存系统决定,是内存系统的固定参数。
缓存硬件读取过程:
当程序执行 load 指令时,需要从主存的地址 A 处读取数据,因此 CPU 将地址 A 发送给缓存,缓存将地址 A 分成多个区域(由缓存的组织结构决定),如果找到该地址的内容则直接读取数据后返回给 CPU,否则从内存读取数据并放入缓存中,再将数据传给 CPU。
缓存参数:

如果有4组,那么 S 为4,s 为 2,s 表示代表组的索引的位数,组的索引为 00,01,10, 11,因此只需要2位就能表示。
如果内存地址是4位,则 m 为 4。
如果一个数据块有 2 个字节,那么 B 为 2(block[0],block[1]),b 为1,则将用最低的一位作为偏移量,表示所读取的字(word)开始的位置,例如地址 7 (0111)的偏移量为 1,将读取数据的地址起始位置为该组相应行的 block[1] 处。
标志位(Tag):如果 S 为4,E 为 1,B 为 2,m 为 4, 则标志为的数目 t = 4 - (2 + 1) = 1,即标志位只有 1 位。标志位用于比较缓存中该行的标志位和地址 A 的标志位是否一致,从而判断缓存中的根据索引找到的行的数据是否是要查找的地址 A 的数据。
(这些参数看后面的示例了解其意义)
6.4.2 Direct-Mapped Caches
直接映射缓存:E 为1,即一组只有一行。

假设一块的大小为 8 字节,一个 word 大小为 4 字节:

上图所示,如果地址中 偏移位 为 4(100),假设组的索引为( s bits) 1(00001):
- 缓存将查找 Set 1 那组的数据,忽略其他组;
- 然后将比较标志位和有效位;
- 有效位可以知道缓存上块的数据是否有效;
- 标志位则查看缓存上的数据是否是想要查找的数据;
- 如果标志位有效,则通过偏移4找到数据的起始地址处,图中获取的数据为 w 0 w 1 w 2 w 3 w_0w_1w_2w_3 w0w1w2w3,然后直接返回给 CPU并放入寄存器中。
- 如果 标志位 tag 不匹配,则表示未命中,需要去内存中找到相应的块然后将该处的块覆盖掉(包括 tag),再取出数据返回给 CPU;
关于索引,前面讲过有的硬件对块存放的位置有严格的要求,有计算公式,因此块的位置时固定的。
示例2:
Suppose we have a direct-mapped cache described by
( S , E , B , m ) = ( 4 , 1 , 2 , 4 ) (S, E, B, m) = (4, 1, 2, 4) (S,E,B,m)=(4,1,2,4)
缓存有4组,每组一行,每块有2字节,地址为 4 bits;假设一个 word 为 1 字节。

从上图可以看出,一个块包含内存中的两个地址,如 block 0 包含地址 0 和 1,他们的 Tag 和 组的索引都相同,只是偏移量不同,block 0 的偏移量为 0,block 1 的偏移量为 1。
图 6.30 可看出组的索引号采用地址的中间两位,这是考虑到前面提过的 spacial locality,如果读取相邻地址的内容,则索引会分到不同的组,而用高位作为索引则会分到相同组,容易造成 conflict miss:

读地址 0 (0000)的数据:将在缓存 set 0 中查找,初始时缓存为空,因此其有效位(Valid)值为 0,因此未命中,需要从内存中找到 block 0 的数据放入缓存中,注意因为 block 0 包含两个地址 0 和 1,因此都会存入缓存,然后返回 m[0] 给 CPU:

放入后有效位变为 1,Tag 设置为 0。
读地址 1 (0001)的数据:将在缓存 set 0 中查找,此时已有数据,且有效位和 Tag 均符合,因此根据偏移 1 获取数据 m[1] 直接发送给 CPU。
读地址 13 (1101)的数据:将在 set 2 中查找,无数据,因此从内存获取数据放入缓存,并根据偏移 1 获取 m[13] 发送给 CPU:

读地址 8 (1000)的数据:将在 set 0 中查找,其标志位为 1,和缓存中已有的标志位 0 不同,因此需要从内存中取数据并覆盖掉缓存中 set 0 的数据,返回 m[8] 到 CPU:

如果再读地址 0 的数据,则又会未命中,然后从内存取数据覆盖 set 0 中数据,尽管还有 set 1 和 set 3 两组未使用,但仍会选择相同的 set 从而造成 conflict miss。
因此缓存需要增大 E 的数目,提高关联性。
6.4.3 Set Associative Caches
当 E 大于1时,称为 E-way set associative cache :

上图 E 为2,假如入要查询的地址组索引为 set 1,set 1 中有两行,缓存将会同时比较两行的有效位和标志位,找到标志位符合的一行。
E 为 2时,如果查询的地址为0,组为 set 0,从内存中放入 m[0]和m[1] 到 set 0 的第一行后,还会同时获取 m[8] 和 m[9] 放到 set[0] 的第二行,因此从内存中获取数据块时,会尽可能的将该组中空的块写入数据。
6.4.4 Fully Associative Caches
A fully associative cache consists of a single set (i.e., E = C/B) that contains all of the cache lines.
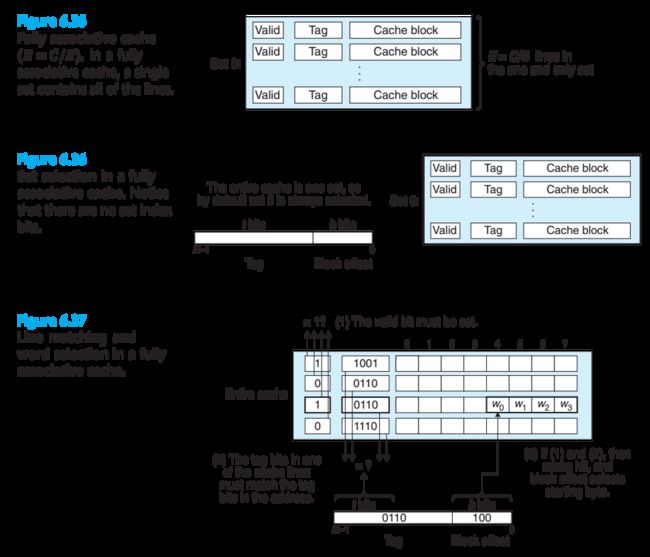
全相联高速缓存,只有一组(set),所有行都在这一组中,因此没有组索引。
全相联高速缓存和之前介绍的缓存工作模式相同,但因为所有行都在一组中,而查询时需要同时比较所有行的 Tag,因此很难做到缓存既大又快,这种设计比较适合小的缓存(如 translation lookaside buffers (TLBs) in virtual memory systems that cache page table entries)。
6.4.5 Issues with Writes
向内存中写数据和读数据相反的过程。
1. write hit
如果要写的数据 w 已经在缓存中,即是一个 write hit,那么缓存更新了 w 后,有两种处理方式:
-
Write-through
将更新后的 w 立刻写到下一个低等级的块中(前面讲过,存储器的层次等级,当前命中的缓存保存的是它第一等级的部分数据的副本),这样很费时,因为访问低层次的时间更长。 -
Write-back
w 先保存在当前缓存中,只有当前块的内容要被覆盖时才将数据写回到低等级块中。这样做的缺点是需要额外的 dirty-bit 来表示该缓存块是否被修改。
2. Write miss
如果缓存中没有数据,有两种处理方式:
-
Write-allocate
找到要写入的数据块放到缓存中,更新缓存的块。缺点是这样每次未命中都要额外花时间将数据写到缓存中,这种方式是考虑到 spacial locality,可能接下来用到的数据已经在缓存中,能命中了。 -
No-write-allocate
直接将数据写到低层次的块中,不放入缓存中。
通常的方式是:
- Write-through + No-write-allocate
- Write-back + Write-allocate (更常用)
6.4.6 Anatomy of a Real Cache Hierarchy
In fact, caches an hold instructions as well as data.
-
A cache that holds instructions only is called an i-cache.
-
A cache that holds program data only is called a d-cache.
-
A cache that holds both instructions and data is known as a unified cache.
Modern processors include separate i-caches and d-caches.
i-caches are typically read-only, and thus simpler.
将指令缓存和数据缓存分开的原因:
1、处理器能同时读指令和数据
2、防止数据访问和指令访问的 conflict miss
Characteristics of the Intel Core i7 cache hierarchy:

见上图,如果 L1 未命中,将向 L2 发送请求尝试在 L2 中查找数据,如果 L2 找不到,则向 L3 发送请求,查看能否在 L3 中找到数据,如果 L3 也找不到,则放弃查找。
6.4.7 Performance Impact of Cache Parameters
对缓存性能的评估:
-
Miss Rate
The fraction of memory references not found in cache. -
Hit Time
Time to deliver a line in the cache to the CPU, including the time for set selection, line identification, and word selection. Hit time is on the order of several clock cycles for L1 caches. -
Miss Penalty
Any additional time required because of a miss. 如果未命中,需要去取数据,然后再写到缓存中更新缓存等额外花费的时间。
Impact of Cache Size
大的缓存趋向增大命中率 (hit rate),因为大的缓存很难运行快,因此在存储器的层级结构中,低层次的缓存比高层次的大。
Impact of Block Size
块的尺寸对性能的影响:如果程序有更多的 spacial locality 比 temporal locality,那块的尺寸大会增加命中率;而如果程序更多的是 temporal locality,那么块的尺寸太大,对应的行的数量就会减少(缓存大小一样的话), 因此反而降低 hit rate;并且块越大,miss penalty 越大,因为未命中时花费的传输数据的时间更多。
Impact of Associativity
6.4.3 中讲过提高关联性,即增大一组中的行数能减小 conflict miss,但这种设计对硬件的要求高。而且行数越多,则需要用于判读的 Tag 的位越多,因此更复杂,也会增加 miss penalty 的时间。
通常的做法:更高层次相关性较低,低层次缓存相关性更高(为了增加 hit rate),如前面图 6.39 所示, L3 是 16-way,L1 和 L2 是 8-way。
Impact of Write Strategy
In general, caches further down the hierarchy are more likely to use write-back than write-through.
6.5 Writing Cache-Friendly Code
Good programmers should always try to write code that is cache friendly, in the sense that it has good locality.
- Repeated references to local variables are good because the compiler can cache them in the register file (temporal locality).
- Stride-1 reference patterns are good because caches at all levels of the memory hierarchy store data as contiguous blocks (spatial locality).
6.6 Putting It Together: The Impact of Caches on Program Performance
6.6.1 The Memory Mountain
- Read throughput (read bandwidth)
Number of bytes read from memory per second (MB/s). - Memory mountain
Measured read throughput as a function of spacial and temporal locality.
Compact way to characterize memory system performance.
测试函数:

上面测试函数通过改变 size 和 stride 两个参数分别控制 temporal locality 和 spacial locality。size 越小,则 temporal locality 越好;stride 越小,则 spacial locality 越好。
通过反复给不同尺寸的 size 和 stride 参数来执行测试函数,就能生成一个 two-dimensional function of read throughput versus temporal and spatial locality. 这个函数就是 memory mountain.

6.6.2 Rearranging Loops to Increase Spatial Locality
矩阵乘法示例:


代码实现如下:

分析循环内部代码:
对于版本 (a) ,矩阵 A 的数据是按行取,而 B 的数据则是按列取,B 的 stride 是 n (假设 n 很大),那么每次循环 B 都不能命中。
改进后的版本 (f),A 和 B 都是按行取,因此降低了未命中率。
Core i7 matrix multiply performance:

6.6.3 Exploiting Locality in Your Programs
In particular, we recommend the following techniques:
-
Focus your attention on the inner loops, where the bulk of the computations and memory accesses occur.
-
Try to maximize the spatial locality in your programs by reading data objects sequentially, with stride 1, in the order they are stored in memory.
-
Try to maximize the temporal locality in your programs by using a data object as often as possible once it has been read from memory.