Python——排序实现
排序实现
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序
- 归并排序
- 快速排序
冒泡排序
-
时间复杂度:
最优时间复杂度:O(n)(表示遍历一次没有发现任何可以交换的元素,排序结束)
最坏时间复杂度:O(n**2) -
稳定性:稳定
def bubble_sort(alist):
n = len(alist)
for j in range(n-1):
# print('')
count = 0
for i in range(n-1-j):
if alist[i] > alist[i+1]:
alist[i],alist[i+1] = alist[i+1],alist[i]
count += 1
if count == 0:
break
对一万个数据进行排序时间:



排序三次,平均时间为11.82
选择排序
-
时间复杂度
最优时间复杂度:O(n2)
最坏时间复杂度:O(n2) -
稳定性:
不稳定(考虑升序每次选择最大的情况)
def selection_sort(alist):
n = len(alist)
for j in range(0,n-1):
for i in range(j+1,n):
if alist[j] > alist[i]:
alist[i], alist[j] = alist[j], alist[i]
对一万个数据进行排序时间:
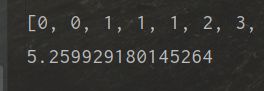


排序三次,平均时间为5.2
冒泡排序和选择排序相比,冒泡排序是相邻两个元素比较,符合要求交换一次;选择排序是一个元素与后边元素比较,符合要求交换一次。所以对于同一组数据来说,选择排序交换次数要少于冒泡排序的,所以效率高
插入排序
-
时间复杂度
最优时间复杂度:O(n)(升序排列,序列已经处于升序状态)
最坏时间复杂度:O(n**2) -
稳定性:稳定
def insert_sort(alist):
n = len(alist)
for i in range(n):
for j in range(i):
if alist[i] < alist[j]:
alist[i], alist[j] = alist[j], alist[i]
对一万个数据进行排序时间:

![]()
![]()
排序三次,平均时间为5.1,比选择排序稍微快一点点
有一位博主的写法利用了Python列表的方法,更快:
def insert_sort(ilist):
for i in range(len(ilist)):
for j in range(i):
if ilist[i] < ilist[j]:
ilist.insert(j, ilist.pop(i))
break
只用了1.7秒左右

这种方式不用交换,只需要遍历列表找到指定的位置即可
希尔排序
-
时间复杂度:
最优时间复杂度:根据步长序列的不同而不同
最坏时间复杂度:O(n**2) -
稳定性:不稳定
def shell_sort(alist):
n = len(alist)
gap = n // 2
while gap > 0:
for j in range(gap, n):
i = j
while i > 0:
if alist[i] < alist[i-gap]:
alist[i], alist[i-gap] = alist[i-gap], alist[i]
i -= gap
else:
break
gap //= 2
对一万个数据进行排序时间:

归并排序
-
时间复杂度:
最坏时间复杂度:O(nlogn)
最优时间复杂度:O(nlogn) -
稳定性:稳定
def merge_sort(alist):
n = len(alist)
# print(alist)
if n <= 1:
return alist
mid = n//2
#left_li 采用归并排序后形成的有序的新的列表
left_li = merge_sort(alist[:mid])
#right_li 采用归并排序后形成的有序的新的列表
right_li = merge_sort(alist[mid:])
#将两个有序的子序列合成一个新的整体
left_pointer,right_pointer = 0,0
print(left_li)
print(right_li)
result = []
while left_pointer < len(left_li) and right_pointer < len(right_li):
if left_li[left_pointer] < right_li[right_pointer]:
result.append(left_li[left_pointer])
left_pointer += 1
else:
result.append(right_li[right_pointer])
right_pointer += 1
result += left_li[left_pointer:]
result += right_li[right_pointer:]
return result
对一万个数据进行排序时间:

快速排序
-
时间复杂度:
最优时间复杂度:O(nlogn)
最坏时间复杂度:O(n**2) -
稳定性:不稳定
def quick_sort(alist, first, last):
if first >= last:
return
mid_value = alist[first]
low = first
high = last
while low < high:
#high左移
#当low和high的值等于,把相同的值放在分界线一边
while low < high and alist[high] >= mid_value:
high -= 1
alist[low] = alist[high]
#low右移
while low < high and alist[low] < mid_value:
low += 1
alist[high] = alist[low]
#从循环退出时,low==high
alist[low] = mid_value
# print(alist)
#对low左边的列表执行快速排序
quick_sort(alist, first, low-1)
#对low右边的列表执行快速排序
quick_sort(alist, low+1, last)
这种方法不好理解
百度百科的方法简单易懂:
def quick_sort(data):
"""快速排序"""
if len(data) >= 2: # 递归入口及出口
mid = data[len(data)//2] # 选取基准值,也可以选取第一个或最后一个元素
left, right = [], [] # 定义基准值左右两侧的列表
data.remove(mid) # 从原始数组中移除基准值
for num in data:
if num >= mid:
right.append(num)
else:
left.append(num)
return quick_sort(left) + [mid] + quick_sort(right)
else:
return data
对一万个数据进行排序时间:

本文所用的数据是随机生成的一万个整数,几种排序用的是一样的数据。
几种排序是从b站上学习的:https://www.bilibili.com/video/BV1p441167Wc/?spm_id_from=333.788.videocard.3
排序具体代码实现有多种写法,如果有错误请大家指出。