linux文件系统-文件的写与读
只有打开可文件以后,或者建立起进程与文件之间的连接之后,才能对文件进行读写。文件的读写主要是通过系统调用read和write来完成的,对于读写的进程,目标文件由一个打开文件号代表。
为了提高效率,稍微复杂一点的操作系统对文件的读写都是带缓冲的,linux也不例外。像vfs一样,linux文件系统的缓冲机制也是它的一大特色。所谓缓冲,是指系统为最近的读写过的文件内容在内核中保留一份副本,以便当再次需要已经缓冲存储在副本的内容时不必再临时从设备上读入,而需要写的时候则可以先写到副本中,待系统较为空闲时再从副本写入设备。在多进程的系统中,由于同一个文件可能为多个进程所共享,缓冲的作用就更显著了。
然而,怎样实现缓冲,在哪一层次上实现缓冲,却是一个值得仔细加以考虑的问题。回顾一下之前博客讲述的文件系统的层次结构,在系统中处于最高层的是进程,这一层可以称为应用层,是在用户空间运行的,在这里代表着目标文件的是打开文件号。在这一层中提供缓冲似乎最贴近文件内容的使用者,所以显然是不妥的。在应用层以下是文件层,由可细分为vfs层和具体文件系统层,再下面就是设备层了。即文件内容的源头的地方,在这里实现缓冲显然是可行的。事实上,早期Unix内核中的文件缓冲就是以数据块缓冲的形式在这一层上实现的。但是,设备层上的缓冲离使用者的距离太远了一点,特别是当文件层又分为vfs和具体文件系统两个子层时,每次读写都要穿越这么多界面深入到设备层就难免使人有一种长途跋涉之惑。很自然地,设计人员把眼光投向了文件层。
在文件层中有三种主要的数据结构,就是file结构、dentry结构以及inode结构。
先看file结构。前面讲过,一个file结构代表着目标文件的一个上下文,不但不同的进程可以在同一个文件上建立不同的上下文,就是同一个文件也可以通过打开一个文件多次而建立起多个上下文。如果在file结构中设置一个缓冲区队列,那么缓冲区中的内容虽然贴近这个特定上下文的使用者,却不便为多个进程共享,甚至不便于同一个进程打开的不同上下文共享。这显然是不合适的,需要把这些缓冲区像数学上的提取公因子那样放到一个公共的地方。
那么dentry结构怎么样呢?这个数据结构并不属于某一个上下文,也不属于某一个进程,可以为所有的进程和上下文共享。可是,dentry结构与目标文件并不是一对一的关系,通过文件链接,我们可以为已经存在的文件建立别名。一个dentry结构只是唯一地代表着文件系统中的一个节点,也就是一个路径名,但是多个节点可以同时代表着同一个文件,所以,还应该再来一次提取公因子。
显然,在inode数据结构中设置一个缓冲区队列是最合适不过了,首先,inode结构与文件是一对一的关系。即使一个文件有多个路径名,最后也归结到同一个inode结构上。再说,一个文件中的内容是不能由其他文件共享的,在同一时间里,设备上的每一个记录块都只能属于至多一个文件(或者就是空闲),将载有同一个文件内容的缓冲区都放在其所属文件的inode结构中是很自然的事。因此,在inode数据结构中设置一个指针i_mapping,它指向一个address_space数据结构(通常这个数据结构就是inode结构中的i_data),缓冲区队列就在这个数据结构中。
不过,挂载缓冲区队列中的并不是记录块而是内存页面。也就是说,文件的内容并不是以记录块为单位,而是以页面为单位进行缓冲的。如果记录块的大小为1k字节,那么一个页面就相当于4个记录块。为什么要这样做呢?这是为了将文件内容的缓冲与文件的内存映射结合在一起。我们知道一个进程可以通过系统调用mmap将一个文件映射到它的用户空间。建立这样的映射之后,就可以像访问内存一样地访问这个文件。如果将文件的内容以页面为单位缓冲,放在附属于该文件的inode结构的缓冲队列中。这样,在按常规的文件操作访问一个文件时,可以通过read、write系统调用目标文件的inode结构访问这些缓冲页面;而通过内存映射机制访问这个文件时,就可以经由页面映射表直接读写这些缓冲着的页面。当目标页面不在内存中时,常规的文件操作通过系统调用read、write的底层将其从设备上读入,而通过内存映射机制访问这个文件时则由“缺页异常”的服务程序将目标页面从设备上读入。也就是说,同一个缓冲页面可以满足两方面的要求,文件系统的缓冲机制和文件的内存映射机制巧妙的结合在一起了。明白了这个背景,对于上述的指针为什么叫i_mapping,它所指向的数据结构为什么叫address_space,就不会感到奇怪了。
可是,尽管以页面为单位的缓冲对于文件层确实是很好地选择,对于设备层则不那么合适了。对设备层而言,最自然的当然还是以记录块为单位的缓冲区,因为设备的读写都是以记录块为单位的。不过,从磁盘上读写时主要的时间都花在准备工作(如磁头组的定位)上,一旦准备好了以后读一个记录块与连续读几个记录块相差不大,而且每次只读写一个记录块反而是不经济的。所以每次读写若干连续的记录块、以页面为单位来缓冲页并不成为问题。另一方面,如果以页面为单位缓冲,而一个页面相当于若干个记录块,那么无论是对于缓冲页面还是对于记录块缓冲区,其控制和附加信息(如链接指针等)显然应该游离于该页面之外,这些信息不应该映射到进程的用户空间。这个问题也不难解决,page结构本身就是这样的。在page结构中有个指针virtual指向所代表的页面,但是page结构本身则不在这个页面中。同样地,在“缓冲区头部”即buffer_head数据结构中有一个指针b_data指向缓冲区,而buffer_head结构本身不在缓冲区中。所以,在设备层中只要保持一些buffer_head结构,让它们的b_data指针分别指向缓冲页面中的相应位置上就可以了。以一个缓冲页面为例,在文件层它通过一个page数据结构挂入所属inode结构的缓冲页面队列,并且同时又可以通过各个进程的页面映射表映射到这些进程的内存空间;而在设备层则又通过若干(通常是四个,因为页面的大小为4KB,而缓冲区的大小为1KB)buffer_head结构挂入其所在设备的缓冲区队列。这样,以页面为单位为文件内容建立缓冲真是一箭三雕。下面的示意图也许有助于我们对缓冲机制的理解。
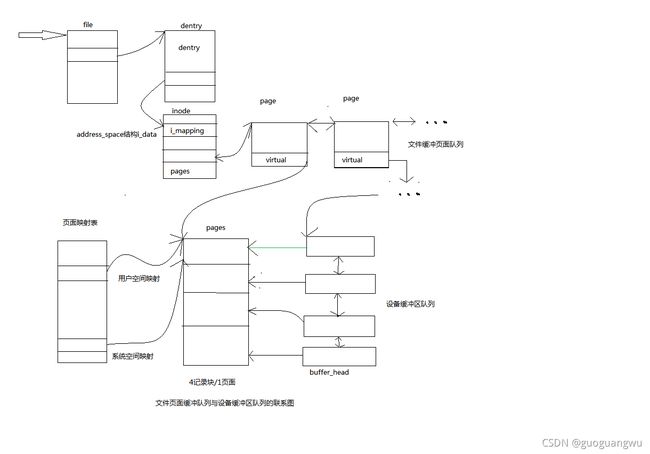
在这样一个结构框架中,一旦所欲访问的内容已经在缓冲页面队列中,读文件的效率就很高了,只要找到文件的inode结构(file结构中有指针指向dentry结构,而dentry结构中有指针指向inode结构)就找到了缓冲页面队列,从队列中找到相应的页面就可以读出来了。缓冲页面的page结构除链入附属inode结构的缓冲页面队列外,同时也链入到一个杂凑表page_hash_table中的杂凑队列中,所以寻找目标页面的操作也是效率很高的,并不需要在整个缓冲页面队列中线性搜索。
那么,写操作又如何呢?如前所述,一旦目标记录块已经存在于缓冲页面中,写操作只是把内容写到该缓冲页面中,所以从发动写操作的进程的角度来看速度也是很快的。至于改变了内容的缓冲页面,则由系统负责在CPU较为空闲时写入设备。为了这个目的,内核中设置了一个内核线程kflushd。平时这个线程总是在睡眠,有需要时(例如写操作以后)就将其唤醒。然后当CPU较为空闲时就会调度其运行,将已经改变了内容的缓冲页面写回设备上。这样,启动写操作的进程和kflushd就好像是一条流水作业线上下两个工位上的操作工,而改变缓冲页面的内容(写操作)与将改变了的内容的缓冲页面写回设备上(称为“同步”)则好像是上下两到工序、除这样的分工合作以外,每个打开了某个文件的进程还可以直接通过系统调用sync强制将缓冲页面写回设备上。此外,缓冲页面的page结构还链入到一个LRU队列中,要是一个页面很久没有受到访问,内存空间又比较短缺,就可以把它释放而另作他用。
除通过缓冲来提高文件读写的效率外,还有个措施就是预读。就是说,如果一个进程发动了对某一个缓冲页面的读操作,并且该页面尚不在内存中而需要从设备上读入,那么就可以预测,通常情况下它接下去可能会继续往下读写,因此不妨预先将后面几个页面一起读进来。如前所述,对于磁盘一类的块设备,读操作中最费时的是磁头组定位,一旦定了位,从设备多读入几个记录块并不相差多少时间。一般而言,对文件的访问有两种形式。一种随机访问,其访问的位置并无规律;另一种是预读访问。预读之所以可能提高效率就是因为大量的文件操作都是顺序访问。其实,以页面(而不是记录块)为单位的缓冲本身隐含着预读,因为通常一个页面包含着4个记录块,只要访问的位置不在其最后一个记录块中,就多少要预读几个记录块,只不过预读的量很小而已。
在早期的Unix系统中,由于当时的磁盘容量小,速度慢,内存也小,一般只预读一个记录块。而现在的预读,则动辄就是几十K字节,甚至上百K字节。当然,那也要视具体情况而定,定义如下:
/* read-ahead in pages.. */
#define MAX_READAHEAD 31
#define MIN_READAHEAD 3这里的数值31表示31个页面,即124K字节。从这里也可以看出,许多比较小的文件其实都是一次就全部预读入内存的。当然,这里说的是最大预读量,实际运行时还要看其他条件,未必真的预读那么多。
由于预读的提前量已经不再限于一个记录块,现在file结构中实际上要维持两个上下文了。一个就是由当前位置f_pos代表的真正的读写上下文,而另一个则是预读的上下文。为此目的,在file结构中增设了f_reada, f_ramax, f_raend, f_ralen, f_rawin等几个字段。这几个字段的名称反映了它们的用途(ra表示 read ahead),具体的含义在下面的代码中就可以看到。
另一方面,预读虽然并不花费很多时间,但毕竟还是需要一点时间。当一个进程启动一次对文件内容的访问,而访问的目标又恰好不在内存中因而需要从设备上读入时,该进程只好暂时交出运行权,进入睡眠等待,称之为受阻(blockd)。可是等待多久呢?一旦本次访问的目标页面进入了内存,等待的进程就可以而且应该恢复运行了,而没有理由等待到所有预读的页面也全部进入内存。从设备上读写一般都是通过DMA进行的,它虽然需要一定的时间,但是并不需要CPU太多的干扰,CPU完全可以忙自己的事情。所以,从设备上读入的操作可以分为两部分。第一部分是必须等待的,在此期间启动本次操作的进程只好暂时停下来,这一部分操作是同步的。第二部分则无需等待,在此期间启动本次操作的进程可以继续运行,所以这一部分是异步的。至于写操作,则如前所述在大多数情况下是留给内核线程kflushd完成的,那当然是异步的。
读完了上面这一大段的概述,现在可以开始读代码了。先看sys_write函数,这是系统调用write在内核中的实现,代码如下:
asmlinkage ssize_t sys_write(unsigned int fd, const char * buf, size_t count)
{
ssize_t ret;
struct file * file;
ret = -EBADF;
file = fget(fd);
if (file) {
if (file->f_mode & FMODE_WRITE) {
struct inode *inode = file->f_dentry->d_inode;
ret = locks_verify_area(FLOCK_VERIFY_WRITE, inode, file,
file->f_pos, count);
if (!ret) {
ssize_t (*write)(struct file *, const char *, size_t, loff_t *);
ret = -EINVAL;
if (file->f_op && (write = file->f_op->write) != NULL)
ret = write(file, buf, count, &file->f_pos);
}
}
if (ret > 0)
inode_dir_notify(file->f_dentry->d_parent->d_inode,
DN_MODIFY);
fput(file);
}
return ret;
}
注意,在调用参数中并不指明在文件中写的位置,因为文件的file结构代表着一个上下文,记录着在文件中的当前位置。函数fget根据打开文件号fd找到该已打开文件的file结构,这个函数的代码如下:
sys_write=>fget
struct file * fget(unsigned int fd)
{
struct file * file;
struct files_struct *files = current->files;
read_lock(&files->file_lock);
file = fcheck(fd);
if (file)
get_file(file);
read_unlock(&files->file_lock);
return file;
}
这个函数,或者更确切地说是它里面的宏操作get_file,一定是与另一个函数fput配对使用的,因为这二者一个递增file结构中的共享计数,另一个则递减这个计数。哪一个过程开始时递增了这个file结构中的共享计数,就负有责任在结束时递减这个计数。这里get_file的定义如下:
#define get_file(x) atomic_inc(&(x)->f_count)
根据打开文件号找到file结构,具体是由fcheck完成的,其代码如下:
sys_write=>fget=>fcheck
/*
* Check whether the specified fd has an open file.
*/
static inline struct file * fcheck(unsigned int fd)
{
struct file * file = NULL;
struct files_struct *files = current->files;
if (fd < files->max_fds)
file = files->fd[fd];
return file;
}
一个进程要对一个已经打开文件进行写操作,应满足几个必要条件。其一是相应file结构里f_mode字段中的标志位FMODE_WRITE为1。这个字段的内容是在打开文件时根据对系统调用open的参数flags经过变换而来的,具体见之前博客中的filp_open函数和dentry_open函数的代码。若标志位FMODE_WRITE为0,则表示这个文件是按只读方式打开的,所以该标志位为1是写操作的一个必要条件。
取得了目标文件的file结构指针并确认文件是按可写方式打开以后,还要检查文件中从当前位置f_pos开始的count个字节是否对写操作加上了强制锁。这是通过locks_verify_area完成的,其代码如下:
sys_write=>locks_verify_area
static inline int locks_verify_area(int read_write, struct inode *inode,
struct file *filp, loff_t offset,
size_t count)
{
if (inode->i_flock && MANDATORY_LOCK(inode))
return locks_mandatory_area(read_write, inode, filp, offset, count);
return 0;
}先检查文件究竟是否加了锁,以及是否允许使用强制锁。如果确实加了锁,并且可能是强制锁,就进一步通过locks_mandatory_area检查所要求的的区域是否也被强制锁住了。这个函数的代码就不看了。它的算法是很简单的,无非就是扫描该文件的inode结构中的i_flock队列里面每个file_lock数据结构并进行比对。从这里读者可以看出为什么强制锁并不总是比协调锁优越,因为对每一次的读写操作它都要扫描这个队列进行比对,这显然会降低文件读写的速度。特别是如果每次读写的长度都很小,那样花在强制锁检查上的开销所占用比例就相当大了。
通过了对强制锁的检查之后,就是写操作本身了。可想而知,不同的文件系统有不同的写操作,具体的文件系统通过其file_operations数据结构提供用于写操作的函数指针,就ext2文件系统而言,它有两个这样的数据结构,一个是ext2_file_operations,另一个是ext2_dir_operations,视操作的目标为文件或者目录而选择其一,在打开该文件时安装在其file结构中。对于普通文件,这个函数指针指向generic_file_write,其代码很长,我们分段来看:
sys_write=>generic_file_write
/*
* Write to a file through the page cache.
*
* We currently put everything into the page cache prior to writing it.
* This is not a problem when writing full pages. With partial pages,
* however, we first have to read the data into the cache, then
* dirty the page, and finally schedule it for writing. Alternatively, we
* could write-through just the portion of data that would go into that
* page, but that would kill performance for applications that write data
* line by line, and it's prone to race conditions.
*
* Note that this routine doesn't try to keep track of dirty pages. Each
* file system has to do this all by itself, unfortunately.
* [email protected]
*/
ssize_t
generic_file_write(struct file *file,const char *buf,size_t count,loff_t *ppos)
{
struct inode *inode = file->f_dentry->d_inode;
struct address_space *mapping = inode->i_mapping;
unsigned long limit = current->rlim[RLIMIT_FSIZE].rlim_cur;
loff_t pos;
struct page *page, *cached_page;
unsigned long written;
long status;
int err;
cached_page = NULL;
down(&inode->i_sem);
pos = *ppos;
err = -EINVAL;
if (pos < 0)
goto out;
err = file->f_error;
if (err) {
file->f_error = 0;
goto out;
}
written = 0;
if (file->f_flags & O_APPEND)
pos = inode->i_size;
/*
* Check whether we've reached the file size limit.
*/
err = -EFBIG;
if (limit != RLIM_INFINITY) {
if (pos >= limit) {
send_sig(SIGXFSZ, current, 0);
goto out;
}
if (count > limit - pos) {
send_sig(SIGXFSZ, current, 0);
count = limit - pos;
}
}
status = 0;
if (count) {
remove_suid(inode);
inode->i_ctime = inode->i_mtime = CURRENT_TIME;
mark_inode_dirty_sync(inode);
}
如前所述,inode结构中有个指针i_mapping,指向一个address_space数据结构,其定义如下:
struct address_space {
struct list_head clean_pages; /* list of clean pages */
struct list_head dirty_pages; /* list of dirty pages */
struct list_head locked_pages; /* list of locked pages */
unsigned long nrpages; /* number of total pages */
struct address_space_operations *a_ops; /* methods */
struct inode *host; /* owner: inode, block_device */
struct vm_area_struct *i_mmap; /* list of private mappings */
struct vm_area_struct *i_mmap_shared; /* list of shared mappings */
spinlock_t i_shared_lock; /* and spinlock protecting it */
};通常这个数据结构就在inode结构中,成为inode结构的一部分,那就是i_data(注意切莫与ext2_inode_info结构中的数组i_data[]数组混淆)。结构中的队列头pages就是用来维持缓冲页面队列的。如果将文件映射到某些进程的用户空间,则指针i_mmap指向一串虚存空间,即vm_area_struct结构,其中的每一个数据结构都代表着该文件在某一个进程的空间映射。还有个指针a_ops也是很重要的,它指向一个address_space_operations数据结构。这个结构中的函数指针给出了缓冲页面与具体文件系统的设备层之间的关系和操作,例如怎样从具体文件系统的设备上读或写一个缓冲页面等等。就ext2文件系统而言,这个数据结构为ext2_aops,定义如下:
struct address_space_operations ext2_aops = {
readpage: ext2_readpage,
writepage: ext2_writepage,
sync_page: block_sync_page,
prepare_write: ext2_prepare_write,
commit_write: generic_commit_write,
bmap: ext2_bmap
};系统调用在某些条件下会中途流产,而流产以后的对策就是重新执行一遍系统调用。文件操作也是这样。但是在某些特殊的情况下,如果在中途流产的同时或之前已经发生了其他的出错,则此时的重新执行所应该做的只是将出错代码返回给进程,而不应该进行任何实质性的操作,file结构中的f_error字段就是为此目的而设置的。
如果在打开文件时的参数中将O_APPEND标志位设为1,则表示对此文件的写操作只能在尾端追加,所以要将当前位置pos调整到文件的尾端。此外,对每个进程可以使用的各种字段,包括文件大小,是可以加上限制的。进程的task_struct结构中有个数组rlim就规定了对该进程使用各种资源的上限。其中有一项,即下标为RLIMIT_FSIZE处的元素,就表示对该进程的文件大小的限制。如果企图写入的位置超出了这个限制,那就要给这个进程发一个信号SIGXFSZ,并且让系统调用失败而返回出错代码-EFBIG。
至此,只要待写的长度不为0,那就是一次有效的写操作了,所以要在inode结构中打上时间印记,并将该inode标志成脏,表示其内容应写回设备上的相应索引节点。这里还有一个函数remove_suid,代码定义如下:
sys_write=>generic_file_write=>remove_suid
static inline void remove_suid(struct inode *inode)
{
unsigned int mode;
/* set S_IGID if S_IXGRP is set, and always set S_ISUID */
mode = (inode->i_mode & S_IXGRP)*(S_ISGID/S_IXGRP) | S_ISUID;
/* was any of the uid bits set? */
mode &= inode->i_mode;
if (mode && !capable(CAP_FSETID)) {
inode->i_mode &= ~mode;
mark_inode_dirty(inode);
}
}
这段程序的意图恰如其函数名所述。如果当前进程并无设置set uid,即S_ISUID标志位的特权,而且目标文件的 set uid标志位S_ISUID和S_ISGID为1,则应将inode结构中的这些标志位清0,也就是剥夺该文件的set uid和set gid特性。之所以要这样做的原因是很简单的(我们把它留给读者,见本段后的附加说明),但是这里的代码确不那么直观。函数中的局部变量mode实际上是作为屏蔽字使用的,第2416行的目的就是注释中所说的。如果i_mode中的标志位S_IXGRP为0,那么两项相乘以后的结构也是0,所以mode成为S_ISUID。而如果i_mode中的标志位为1,那么相乘以后的结果为S_ISGID,所以mode就成为(S_ISGID/S_IXGRP)。其余的就比较简单直观了。
此处顺便请读者考虑,如果当前进程不具备设置S_ISUID的特权,却具备有对一个已经存在的set uid可执行文件的写访问权限,则它可以把这个文件中的内容全部改写。这样,就相当于当前进程创建了自己的set uid可执行文件。
回到generic_file_write代码中继续往下看:
sys_write=>generic_file_write
while (count) {
unsigned long bytes, index, offset;
char *kaddr;
int deactivate = 1;
/*
* Try to find the page in the cache. If it isn't there,
* allocate a free page.
*/
offset = (pos & (PAGE_CACHE_SIZE -1)); /* Within page */
index = pos >> PAGE_CACHE_SHIFT;
bytes = PAGE_CACHE_SIZE - offset;
if (bytes > count) {
bytes = count;
deactivate = 0;
}
/*
* Bring in the user page that we will copy from _first_.
* Otherwise there's a nasty deadlock on copying from the
* same page as we're writing to, without it being marked
* up-to-date.
*/
{ volatile unsigned char dummy;
__get_user(dummy, buf);
__get_user(dummy, buf+bytes-1);
}
status = -ENOMEM; /* we'll assign it later anyway */
page = __grab_cache_page(mapping, index, &cached_page);
if (!page)
break;
/* We have exclusive IO access to the page.. */
if (!PageLocked(page)) {
PAGE_BUG(page);
}
status = mapping->a_ops->prepare_write(file, page, offset, offset+bytes);
if (status)
goto unlock;
kaddr = page_address(page);
status = copy_from_user(kaddr+offset, buf, bytes);
flush_dcache_page(page);
if (status)
goto fail_write;
status = mapping->a_ops->commit_write(file, page, offset, offset+bytes);
if (!status)
status = bytes;
if (status >= 0) {
written += status;
count -= status;
pos += status;
buf += status;
}
unlock:
/* Mark it unlocked again and drop the page.. */
UnlockPage(page);
if (deactivate)
deactivate_page(page);
page_cache_release(page);
if (status < 0)
break;
}
*ppos = pos;
if (cached_page)
page_cache_free(cached_page);
/* For now, when the user asks for O_SYNC, we'll actually
* provide O_DSYNC. */
if ((status >= 0) && (file->f_flags & O_SYNC))
status = generic_osync_inode(inode, 1); /* 1 means datasync */
err = written ? written : status;
out:
up(&inode->i_sem);
return err;
fail_write:
status = -EFAULT;
ClearPageUptodate(page);
kunmap(page);
goto unlock;
}
写操作的主体部分是由一个while循环实现的。循环的次数取决于写的长度和位置,在每一次循环中,只往一个缓冲页面中写,并且将当前位置pos相应的向前推进,而剩下未写的长度count则逐次减少。首先要根据当前位置pos计算出本次循环中要写的缓冲页面index、在该页面中的起点offset以及写入长度bytes。计算时将整个文件的内容当做一个连续的线性存储空间,将pos右移
PAGE_CACHE_SHIFT位跟将pos被页面大小所整除是等价的(但是更快)。 计算出了缓冲页面在目标文件中的逻辑序列号index以后,就通过__grab_cache_page找到该缓冲页面,如找不到,就分配、建立一个缓冲页面,其代码如下:
sys_write=>generic_file_write=>__grab_cache_page
static inline struct page * __grab_cache_page(struct address_space *mapping,
unsigned long index, struct page **cached_page)
{
struct page *page, **hash = page_hash(mapping, index);
repeat:
page = __find_lock_page(mapping, index, hash);
if (!page) {
if (!*cached_page) {
*cached_page = page_cache_alloc();
if (!*cached_page)
return NULL;
}
page = *cached_page;
if (add_to_page_cache_unique(page, mapping, index, hash))
goto repeat;
*cached_page = NULL;
}
return page;
}
首先是通过杂凑计算从页面杂凑表page_hash_table中找到所在或应该在的杂凑队列。与page_hash有关的代码如下:
extern struct page **page_hash_table;
extern void page_cache_init(unsigned long);
/*
* We use a power-of-two hash table to avoid a modulus,
* and get a reasonable hash by knowing roughly how the
* inode pointer and indexes are distributed (ie, we
* roughly know which bits are "significant")
*
* For the time being it will work for struct address_space too (most of
* them sitting inside the inodes). We might want to change it later.
*/
extern inline unsigned long _page_hashfn(struct address_space * mapping, unsigned long index)
{
#define i (((unsigned long) mapping)/(sizeof(struct inode) & ~ (sizeof(struct inode) - 1)))
#define s(x) ((x)+((x)>>PAGE_HASH_BITS))
return s(i+index) & (PAGE_HASH_SIZE-1);
#undef i
#undef s
}
#define page_hash(mapping,index) (page_hash_table+_page_hashfn(mapping,index))
值得注意的是,在杂凑计算中除页面的逻辑序号inodex外还是用了指针mapping,这是因为页面在文件中的逻辑序号在系统范围内不是惟一的。
这里page_hash返回的是一个指向数组page_hash_table中某一个元素的指针,而这个元素本身则又是一个page结构指针,指向队列中的第一个page结构。
找到了目标页面所在,或者应该在杂凑队列后,就要搜索这个队列,找到该页面的page结构,这是由__find_lock_page完成的。我们在这里就不看这些低层函数的代码了。
总之,如果在队列中找到了目标页面就万事大吉。找不到就要通过分配一个空闲(并且空白)的页面,并通过add_to_page_cache_unique将其链入相应的杂凑队列中。不过,在调用__grab_cache_page时也可以通过调用参数带下一个空间页面来,此时就把带下来的页面先用掉,而不分配新的页面了。
这样,只要系统中还有可用的页面,从__grab_cache_page返回到generic_file_write中时一定已经有了一个缓冲页面,只是这个页面有可能是个新分配的空白页面。新分配的空白页面与业已存在的缓冲页面除在内容上有根本性的区别外,在结构上也有个重要的区别。那就是前面所讲的,缓冲页面一方面与一个page结构相联系,另一方面又要与若干记录块缓冲区的头部,即buffer_head数据结构相联系。而新分配的页面则尚无buffer_head结构与之挂钩。所以,对于新分配的空白页面一来要为其配备相应的buffer_head数据结构,二来要将目标页面的内容先从设备上读入(因为写操作未必是整个页面的写入)。不仅如此,就是业已存在的老页面也有个缓冲页面中的内容是否up_to_date,即是否一致的问题。这里所谓一致,是指缓冲页面或者缓冲区中的内容与设备上的逻辑内容(不一定是物理内容)一致,详细情况可看后面对__block_commit_write的讨论。换言之,在开始写入前还要做一些准备工作,而这些准备工作与具体文件系统相关,所以由具体的address_space_operations数据结构通过函数指针prepare_write提供具体的操作函数,就ext2文件系统而言,这个函数为ext2_prepare_write,代码如下:
sys_write=>generic_file_write=>ext2_prepare_write
static int ext2_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page,from,to,ext2_get_block);
}这里的block_prepare_write是个通用的函数,其具体的低层操作由作为参数传递的函数指针决定,而这里传下去的函数为ext2_get_block。
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write
int block_prepare_write(struct page *page, unsigned from, unsigned to,
get_block_t *get_block)
{
struct inode *inode = page->mapping->host;
int err = __block_prepare_write(inode, page, from, to, get_block);
if (err) {
ClearPageUptodate(page);
kunmap(page);
}
return err;
}
显然,这个函数的主体是__block_prepare_write,它的代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write
static int __block_prepare_write(struct inode *inode, struct page *page,
unsigned from, unsigned to, get_block_t *get_block)
{
unsigned block_start, block_end;
unsigned long block;
int err = 0;
unsigned blocksize, bbits;
struct buffer_head *bh, *head, *wait[2], **wait_bh=wait;
char *kaddr = kmap(page);
blocksize = inode->i_sb->s_blocksize;
if (!page->buffers)
create_empty_buffers(page, inode->i_dev, blocksize);
head = page->buffers;
bbits = inode->i_sb->s_blocksize_bits;
block = page->index << (PAGE_CACHE_SHIFT - bbits);
for(bh = head, block_start = 0; bh != head || !block_start;
block++, block_start=block_end, bh = bh->b_this_page) {
if (!bh)
BUG();
block_end = block_start+blocksize;
if (block_end <= from)
continue;
if (block_start >= to)
break;
if (!buffer_mapped(bh)) {
err = get_block(inode, block, bh, 1);
if (err)
goto out;
if (buffer_new(bh)) {
unmap_underlying_metadata(bh);
if (Page_Uptodate(page)) {
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
if (block_end > to)
memset(kaddr+to, 0, block_end-to);
if (block_start < from)
memset(kaddr+block_start, 0, from-block_start);
if (block_end > to || block_start < from)
flush_dcache_page(page);
continue;
}
}
if (Page_Uptodate(page)) {
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
if (!buffer_uptodate(bh) &&
(block_start < from || block_end > to)) {
ll_rw_block(READ, 1, &bh);
*wait_bh++=bh;
}
}
/*
* If we issued read requests - let them complete.
*/
while(wait_bh > wait) {
wait_on_buffer(*--wait_bh);
err = -EIO;
if (!buffer_uptodate(*wait_bh))
goto out;
}
return 0;
out:
return err;
}
参数get_block是个函数指针,对于ext2文件系统它指向ext2_get_block。这个函数的作用是为一个给定的缓冲页面中的记录块缓冲区做好写入的准备。如前所述,因具体文件系统和设备的不同,记录块的大小也有可能不同,其实际的大小记录在设备的超级块中,从而在super_block结构中。一个页面由若干个记录块构成,对于原已存在的页面,这些缓冲区的buffer_head结构都通过指针b_this_page指向同一个页面中的下一个buffer_head,而形成缓冲页面page结构里的队列buffers。而如果是新分配建立的页面,则要通过create_empty_buffers为该页面配备好相应的buffer_head结构,并建立起这个队列。这个函数的代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>create_empty_buffers
static void create_empty_buffers(struct page *page, kdev_t dev, unsigned long blocksize)
{
struct buffer_head *bh, *head, *tail;
head = create_buffers(page, blocksize, 1);
if (page->buffers)
BUG();
bh = head;
do {
bh->b_dev = dev;
bh->b_blocknr = 0;
bh->b_end_io = NULL;
tail = bh;
bh = bh->b_this_page;
} while (bh);
tail->b_this_page = head;
page->buffers = head;
page_cache_get(page);
}
这里的page_cache_get只是递增page结构中的共享计数。
回到__block_prepare_write的代码中。如前所述,虽然在文件系统层次上是以页面为单位缓冲的,在设备层次上却是以记录块为单位缓冲的。所以,如果一个缓冲页面的内容是一致的,就意味着构成这个页面的所有记录块的内容都一致,反过来,如果一个缓冲页面不一致,则未必每个记录块都不一致。因此,要根据写入的位置和长度找到具体涉及的记录块,针对这些记录块做写入操作。
做些什么准备呢?简而言之就是使用有关记录块缓冲区的内容与设备上相关记录的内容一致。如果缓冲页面已经建立起对物理记录块的映射,则需要做的只是检查一下目录记录块的内容是否一致(见第1607行和1608行),如果不一致就通过ll_rw_block将设备上的记录块读到缓冲区中。由此可见,对文件的写操作实际上往往是写中有读、欲写先读。
可是,如果缓冲页面是新的,尚未映射到物理记录块呢?那就比较复杂了,因为根据页面号、页面大小、记录块大小计算所得的记录块号(见1585行)只是文件内容的逻辑块号,这是在假定文件的内容为连续的线性空间这么个前提下计算出来的,而实际的记录块在设备上的位置则是动态地分配和回收的。另一方面,在设备层也根本没有文件的概念,而只能按设备上的记录块号读写。设备上的记录块号也是逻辑块号,与设备上的记录块位图相对应。而设备上的逻辑块号与物理记录块有着一一对应的关系,所以在文件层也可以认为是物理块号。总而言之,这里有个从文件内容的逻辑记录块号到设备上的记录块号之间的映射问题。缺少了对这种映射关系的描述,就无法根据文件内的逻辑块号到设备上的找到相应的记录块。可想而知,不同的文件系统可能有不同的映射关系或过程,这就是要由作为参数传给__block_prepare_write的函数指针get_block来完成这种映射的原因。对于ext2文件系统这个函数为ext2_get_block,代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block
/*
* Allocation strategy is simple: if we have to allocate something, we will
* have to go the whole way to leaf. So let's do it before attaching anything
* to tree, set linkage between the newborn blocks, write them if sync is
* required, recheck the path, free and repeat if check fails, otherwise
* set the last missing link (that will protect us from any truncate-generated
* removals - all blocks on the path are immune now) and possibly force the
* write on the parent block.
* That has a nice additional property: no special recovery from the failed
* allocations is needed - we simply release blocks and do not touch anything
* reachable from inode.
*/
static int ext2_get_block(struct inode *inode, long iblock, struct buffer_head *bh_result, int create)
{
int err = -EIO;
int offsets[4];
Indirect chain[4];
Indirect *partial;
unsigned long goal;
int left;
int depth = ext2_block_to_path(inode, iblock, offsets);
if (depth == 0)
goto out;
lock_kernel();
reread:
partial = ext2_get_branch(inode, depth, offsets, chain, &err);
/* Simplest case - block found, no allocation needed */
if (!partial) {
got_it:
bh_result->b_dev = inode->i_dev;
bh_result->b_blocknr = le32_to_cpu(chain[depth-1].key);
bh_result->b_state |= (1UL << BH_Mapped);
/* Clean up and exit */
partial = chain+depth-1; /* the whole chain */
goto cleanup;
}
/* Next simple case - plain lookup or failed read of indirect block */
if (!create || err == -EIO) {
cleanup:
while (partial > chain) {
brelse(partial->bh);
partial--;
}
unlock_kernel();
out:
return err;
}
/*
* Indirect block might be removed by truncate while we were
* reading it. Handling of that case (forget what we've got and
* reread) is taken out of the main path.
*/
if (err == -EAGAIN)
goto changed;
if (ext2_find_goal(inode, iblock, chain, partial, &goal) < 0)
goto changed;
left = (chain + depth) - partial;
err = ext2_alloc_branch(inode, left, goal,
offsets+(partial-chain), partial);
if (err)
goto cleanup;
if (ext2_splice_branch(inode, iblock, chain, partial, left) < 0)
goto changed;
bh_result->b_state |= (1UL << BH_New);
goto got_it;
changed:
while (partial > chain) {
bforget(partial->bh);
partial--;
}
goto reread;
}
参数iblock表示所处理的记录块在文件中的逻辑块号,inode则指向文件的inode结构;参数create表示是否需要创建。从__block_prepare_write中传下的实际参数为1,所以我们在这里只关心create为1的情景。从文件内块号到设备上块号的映射,最简单最迅速的当然莫过于使用一个以文件内块号为下标的线性数组,并且将这个数组置于索引节点inode结构中。可是,那样就需要很大的数组,从而使索引节点和inode结构也变得很大,或者就得使用可变长度的索引节点而使文件系统的结构更加复杂。
另一种方法是采用间接寻址,也就是将上述的数组分块放在设备上本来可用于存储数据的若干记录块中,而将这些记录块的块号放在索引节点和inode结构。这些记录块虽然在设备上的数据区(而不是索引节点区)中,却并不构成文件本身的内容,而只是一些管理信息。由于索引节点(和inode结构)应该是固定大小的,所以当文件较大时还要将这种间接寻址的结构框架做成树状或链状,这样才能随着文件本身的大小而扩展其容量,显然,这种方法解决了容量的问题,但是降低了运行的效率。
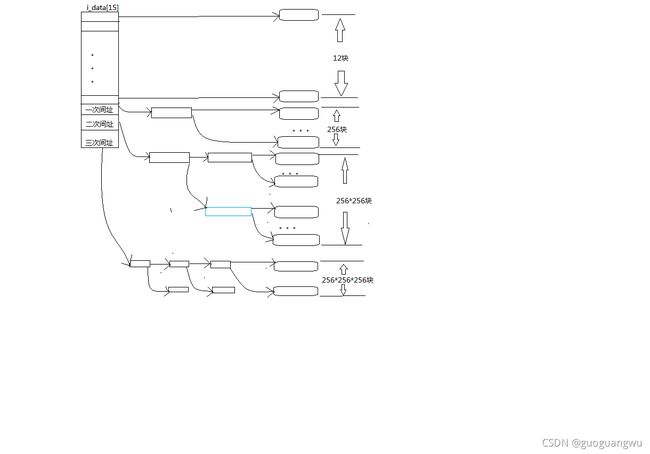
基于这些考虑,从Unix早期就采用了一种折中的方法,可以说直接与间接相结合。其方法是把整个文件的记录块寻址分成几个部分来实现。第一部分是个以文件内块号为下标的数组,这是采用直接映射的部分,对于较小的文件这一部分就够用了。由于根据文件内块号就可以在inode结构里的数组中直接找到相应的设备上块号,所以效率很高。至于比较大的文件,其开头那一部分记录块号也同样直接就可以找到,但是当文件的大小超出这一部分的容量时,超出的那一部分就采用间接寻址了。ext2文件系统的这一部分的大小为12个记录块,即数组的大小为12.当记录块大小为1K字节,相应的文件大小为12K字节。在ext2文件系统的ext2_inode_info结构中,有个大小为15的整型数组i_data[],其开头12个元素即用于此项目。当文件大小超过这一部分的容量时,该数组中的第13个元素指向一个记录块,这个记录块的内容也是一个整型数组,其中的每个元素都指向一个设备上记录块。如果记录块大小为1K字节,则该数组的大小为256,也就是说间接寻址的容量为256个记录块,即256K字节。这样,两个部分的总容量为12K+256K=268K字节。可是,更大的文件还是容纳不下,所以超过此容量的部分要进一步采用双重(二层)间接寻址。此时inode结构里i_data[]数组中的第14个元素指向另一个记录块,该记录块的内容也是一个数组,但是每个元素都指向另一个记录块中的数组,那才是文件内块号至设备上块号的映射表。这么一来,双重间接寻址部分的能力为256*256=64k个记录块。即64M字节。以此类推,数组i_data[]中的第15个元素用于三重(三层)间接寻址,这一部分容量可达256*256*256=16M个记录块,也就是16G字节,所以,对于32位结构的系统,当记录块大小为1K字节时,文件的最大容量为16G+64M+256K+12K。如果设备的容量大于这个数值,就得采用更大的记录块大小。下图是一个关于直接和间接映射的示意图。
从严格意义上说,i_data[]其实不能说是一个数组,因为它的元素并不是都是同一种类型的。但是,从另一个角度说,则这些元素毕竟都是长整型,都代表着设备上一个记录块,只是这些记录块的用途不同而已。
这里还要注意,在inode结构中有个成分名i_data,这是一个address_space数据结构。而作为inode结构一部分的ext2_inode_info结构中,也有个名为i_data的数组,实际上就是记录块映射表,二者毫无关系。从概念上说,inode结构是设备上的索引节点即ext2_inode结构的对应物,但实际上inode结构中的很多内容并非来自ext2_inode结构。相比之下,ext2_inode_info结构中的信息才是基本上与设备上的索引节点相对应的。例如,与ext2_inode_info中的数组i_data[]相对应,在ext2_inode结构中也有个数组i_block[],两个数组的大小也相同。而ext2_inode_info中的数组i_data[]之所以不能再大一些,就是因为索引节点中的数组i_block[]只能这么大了。那么内存中的inode结构为什么与设备上的索引节点有相当大的不同呢?原因在于设备上索引节点的大小受到更多的限制,所以在索引节点中只能存储必要的信息,而且是相对静态的信息。而内存中的inode结构就不同了,它受的限制比较小,除了来自索引节点的必要信息以外还可以用来保存一些为方便和提高效率所需的信息,还有一些运行时需要的更为动态的信息,如各种指针,以及为实现某些功能所需的信息,如i_sock、i_pipe、i_wait和i_flock等等。还应提醒读者,设备上的索引节点数量与设备的大小以及文件系统格式的设计有直接的关系,设备上的每一个文件都有一个索引节点,但是内存中的inode结构则主要是缓冲性质的,实际上只有很小一部分在内存中建立并保持inode结构。
有了这些背景知识,我们就可以深入到ext2_get_block的代码中了。这里用到的一些宏定义如下:
# define EXT2_BLOCK_SIZE(s) ((s)->s_blocksize)
#define EXT2_ADDR_PER_BLOCK(s) (EXT2_BLOCK_SIZE(s) / sizeof (__u32))
#define EXT2_ADDR_PER_BLOCK_BITS(s) ((s)->u.ext2_sb.s_addr_per_block_bits)
/*
* Constants relative to the data blocks
*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
这些定义中的EXT2_NDIR_BLOCKS为12,表示直接映射的记录块数量。EXT2_IND_BLOCK的值也是12,表示在i_data数组中用于一次间接映射的元素下标。而EXT2_DIND_BLOCK和EXT2_TIND_BLOCK则分别为用于二次间接和三次间接的元素下标。至于EXT2_N_BLOCKS则为i_data数组的大小。
首先根据文件内块号计算出这个记录块落在哪一个区间,要采用几重映射(1表示直接)。这里ext2_block_to_path完成的。其代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_block_to_path
/**
* ext2_block_to_path - parse the block number into array of offsets
* @inode: inode in question (we are only interested in its superblock)
* @i_block: block number to be parsed
* @offsets: array to store the offsets in
*
* To store the locations of file's data ext2 uses a data structure common
* for UNIX filesystems - tree of pointers anchored in the inode, with
* data blocks at leaves and indirect blocks in intermediate nodes.
* This function translates the block number into path in that tree -
* return value is the path length and @offsets[n] is the offset of
* pointer to (n+1)th node in the nth one. If @block is out of range
* (negative or too large) warning is printed and zero returned.
*
* Note: function doesn't find node addresses, so no IO is needed. All
* we need to know is the capacity of indirect blocks (taken from the
* inode->i_sb).
*/
/*
* Portability note: the last comparison (check that we fit into triple
* indirect block) is spelled differently, because otherwise on an
* architecture with 32-bit longs and 8Kb pages we might get into trouble
* if our filesystem had 8Kb blocks. We might use long long, but that would
* kill us on x86. Oh, well, at least the sign propagation does not matter -
* i_block would have to be negative in the very beginning, so we would not
* get there at all.
*/
static int ext2_block_to_path(struct inode *inode, long i_block, int offsets[4])
{
int ptrs = EXT2_ADDR_PER_BLOCK(inode->i_sb);
int ptrs_bits = EXT2_ADDR_PER_BLOCK_BITS(inode->i_sb);
const long direct_blocks = EXT2_NDIR_BLOCKS,
indirect_blocks = ptrs,
double_blocks = (1 << (ptrs_bits * 2));
int n = 0;
if (i_block < 0) {
ext2_warning (inode->i_sb, "ext2_block_to_path", "block < 0");
} else if (i_block < direct_blocks) {
offsets[n++] = i_block;
} else if ( (i_block -= direct_blocks) < indirect_blocks) {
offsets[n++] = EXT2_IND_BLOCK;
offsets[n++] = i_block;
} else if ((i_block -= indirect_blocks) < double_blocks) {
offsets[n++] = EXT2_DIND_BLOCK;
offsets[n++] = i_block >> ptrs_bits;
offsets[n++] = i_block & (ptrs - 1);
} else if (((i_block -= double_blocks) >> (ptrs_bits * 2)) < ptrs) {
offsets[n++] = EXT2_TIND_BLOCK;
offsets[n++] = i_block >> (ptrs_bits * 2);
offsets[n++] = (i_block >> ptrs_bits) & (ptrs - 1);
offsets[n++] = i_block & (ptrs - 1);
} else {
ext2_warning (inode->i_sb, "ext2_block_to_path", "block > big");
}
return n;
}
根据上面的这些宏定义,在记录块大小为1K字节时,代码中的局部变量ptrs赋值为256,从而indirect_blocks也使256。与ptrs相对应的ptrs_bits则为8,因为256是由1左移8位而成的。同样的,二次间接的容量double_blocks就是由1左移16位,即64K。而三次间接的容量为由1左移24位,即16M。
除映射深度外,还要算出在每一层映射中使用的位移量,即数组中的下标,并将计算的结果放在一个数组offset中备用。例如,文件内块号10不需要间接映射,一步就能到位,所以返回值为1,并与offset[0]中返回在第一个数组,即i_data中的位移10。可是,假若文件内容号为20,则返回值为2,而offset[0]为12,offset[1]为8。这样,就在数组offset[]中各层映射提供了一条线路。数组的大小为4,因为最多就是三重间接。参数offset实际上是一个指针,在C语言里数组名与指针是等价的。
如果ext2_block_to_path的返回值为0表示出了错,因为文件内块号与设备上块号之间至少也得映射一次。出错的原因可能是文件内块号太大或为负值,或是下面要讲到的冲突。否则,就进一步从磁盘上逐层读入用于间接映射的记录块,这是由ext2_get_branch完成的。
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_get_branch
/**
* ext2_get_branch - read the chain of indirect blocks leading to data
* @inode: inode in question
* @depth: depth of the chain (1 - direct pointer, etc.)
* @offsets: offsets of pointers in inode/indirect blocks
* @chain: place to store the result
* @err: here we store the error value
*
* Function fills the array of triples and returns %NULL
* if everything went OK or the pointer to the last filled triple
* (incomplete one) otherwise. Upon the return chain[i].key contains
* the number of (i+1)-th block in the chain (as it is stored in memory,
* i.e. little-endian 32-bit), chain[i].p contains the address of that
* number (it points into struct inode for i==0 and into the bh->b_data
* for i>0) and chain[i].bh points to the buffer_head of i-th indirect
* block for i>0 and NULL for i==0. In other words, it holds the block
* numbers of the chain, addresses they were taken from (and where we can
* verify that chain did not change) and buffer_heads hosting these
* numbers.
*
* Function stops when it stumbles upon zero pointer (absent block)
* (pointer to last triple returned, *@err == 0)
* or when it gets an IO error reading an indirect block
* (ditto, *@err == -EIO)
* or when it notices that chain had been changed while it was reading
* (ditto, *@err == -EAGAIN)
* or when it reads all @depth-1 indirect blocks successfully and finds
* the whole chain, all way to the data (returns %NULL, *err == 0).
*/
static inline Indirect *ext2_get_branch(struct inode *inode,
int depth,
int *offsets,
Indirect chain[4],
int *err)
{
kdev_t dev = inode->i_dev;
int size = inode->i_sb->s_blocksize;
Indirect *p = chain;
struct buffer_head *bh;
*err = 0;
/* i_data is not going away, no lock needed */
add_chain (chain, NULL, inode->u.ext2_i.i_data + *offsets);
if (!p->key)
goto no_block;
while (--depth) {
bh = bread(dev, le32_to_cpu(p->key), size);
if (!bh)
goto failure;
/* Reader: pointers */
if (!verify_chain(chain, p))
goto changed;
add_chain(++p, bh, (u32*)bh->b_data + *++offsets);
/* Reader: end */
if (!p->key)
goto no_block;
}
return NULL;
changed:
*err = -EAGAIN;
goto no_block;
failure:
*err = -EIO;
no_block:
return p;
}
与前一个函数中的offset[]一样,这里的参数chain[]也是一个指针,指向一个Indirect结构数组,其类型定义如下:
typedef struct {
u32 *p;
u32 key;
struct buffer_head *bh;
} Indirect;根据数组offset[](参数offset指向这个数组)的指引,这个函数逐层将用于记录块号映射的记录块读入内存,并将指向缓冲区的指针保存在数组chain[]的相应元素,即Indirect结构中。同时,还要使该Indirect结构中的指针p指向本层记录块号映射表(数组)中的相应表项。并使字段key持有该表项的内容。具体Indirect结构的内容是由add_chain设置的:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_get_branch=>add_chain
static inline void add_chain(Indirect *p, struct buffer_head *bh, u32 *v)
{
p->key = *(p->p = v);
p->bh = bh;
}仍以前面所举的两个逻辑块为例。文件内块号10不需要间接映射,所以只用chain[0]一个Indirect结构。其指针bh为NULL,因为没有用于间接映射的记录块:指针p指向映射表中直接映射部分下标为10处,即&inode->u.ext2_i.i_data[10];而key则持有该表项的内容,即所映射的设备上块号。相比之下,文件内块号20需要一次间接映射,所以要用chain[0]和chain[1]两个表项。第一个表项chain[0]中的指针bh仍为NULL,因为在这一层上没有用于间接映射的记录块;指针p指向映射表中下标为12处,即&inode->u.ext2_i.i_data[12],这是用于一层间接映射的表项;而key则持有该表项的内容,即用于一层间接映射的记录块的设备上块号。第二个表项chain[1]中的指针bh则指向该记录块的缓冲区,这个缓冲区的内容就是用作映射表的一个整型数组。所以chain[1]中的指针p指向这个数组中下标为8处,而key则持有该表项的内容,即经过间接映射后的设备上块号。这样,根据具体映射的深度depth,数组chain[]中的最后一个元素,更确切的说是chain[depth-1].key,总是持有目标记录的物理块号。而从chain[]中的第一个元素chain[0]到具体映射的最后一个元素chain[depth-1],则提供了具体映射的整个路径,构成了一条映射链,这也是数组名chain的由来。如果把映射的过程看成爬树的过程,则一条映射链可看成决定着树上的一个分支,所以叫ext2_get_branch。
给定chain[]数组中的两个Indirect结构,可以通过一个函数verify_chain检查它们是否构成一条有效的映射链:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_get_branch=>verify_chain
static inline int verify_chain(Indirect *from, Indirect *to)
{
while (from <= to && from->key == *from->p)
from++;
return (from > to);
}在ext2_get_branch的代码中可以看到:从设备上逐层读入用于间接映射的记录块时,每通过bread读入一个记录块以后都要通过调用verify_chain再检查一下映射链的有效性,实质上是检查各层映射表中有关的内容是否发生改变了(见代码中的条件from->key == *from->p)。为什么有可能改变呢?这是因为从设备上读入一个记录块是费时间的操作,当前进程会进入睡眠而系统会调度其他进程运行。这样,就有可能发生冲突了。例如,被调度运行的进程可能会打开这个文件并加以截尾,即把文件原有的内容删除。所以,当因等待读入中间记录块而进入睡眠的进程恢复运行的时候,可能会发现原来有效的映射链已经变成无效了,此时ext2_get_branch返回一个出错码-EAGAIN。当然,发生这种情况的概率是很小的,但是一个软件是否健壮就在于是否考虑到了所有的可能。至于bread,那已是属于设备驱动的范畴,后面的块设备驱动博客的有关内容会讲解。
这样,ext2_get_branch深化了ext2_block_to_path所取得的结果,二者合在一起基本完成了从文件内块号到设备上块号的映射。
从ext2_get_branch返回的值有两种可能。首先,如果顺利完成了映射则返回值为NULL。其次,如果在某一层上发现映射表内的相应表项为0,则说明这个表项(记录块)原来并不存在,现在因为写操作而需要扩充文件的大小。此时返回指向该层Indirect结构的指针,表示映射在此断裂了。此外,如果映射的过程中出了错,例如读记录块失败,则通过参数err返回一个出错代码。
回到ext2_get_block的代码中。如果顺利完成了映射,就把所得的结果填入作为参数传下来的缓冲区结构bh_result中,然后把映射过程中读入的缓冲区(用于间接映射)全部释放,就最后完成了记录块号的映射。
可是,要是ext2_get_branch返回了一个非0指针(代码中的局部变量partial),那就说明映射在某一层上断裂了。根据映射的深度和断裂的位置(层次),这次记录块也许还只是个中间的、用于间接映射的记录块,也许就是最终的目标记录块。总之,在这种情况下,要在设备上为目标记录块以及可能需要的中间记录块分配空间。
首先从本文件的角度为目标记录块的分配提出一个建议块号,由ext2_find_goal确定:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_find_goal
/**
* ext2_find_goal - find a prefered place for allocation.
* @inode: owner
* @block: block we want
* @chain: chain of indirect blocks
* @partial: pointer to the last triple within a chain
* @goal: place to store the result.
*
* Normally this function find the prefered place for block allocation,
* stores it in *@goal and returns zero. If the branch had been changed
* under us we return -EAGAIN.
*/
static inline int ext2_find_goal(struct inode *inode,
long block,
Indirect chain[4],
Indirect *partial,
unsigned long *goal)
{
/* Writer: ->i_next_alloc* */
if (block == inode->u.ext2_i.i_next_alloc_block + 1) {
inode->u.ext2_i.i_next_alloc_block++;
inode->u.ext2_i.i_next_alloc_goal++;
}
/* Writer: end */
/* Reader: pointers, ->i_next_alloc* */
if (verify_chain(chain, partial)) {
/*
* try the heuristic for sequential allocation,
* failing that at least try to get decent locality.
*/
if (block == inode->u.ext2_i.i_next_alloc_block)
*goal = inode->u.ext2_i.i_next_alloc_goal;
if (!*goal)
*goal = ext2_find_near(inode, partial);
return 0;
}
/* Reader: end */
return -EAGAIN;
}
参数block文件内逻辑块号,goal则用来返回所建议的设备上目标块号。从本文件的角度,当然希望所有的记录块在设备上都紧挨在一起并且连续。为此目的,在ext2_inode_info数据结构中设置了两个字段,即i_next_alloc_block和i_next_alloc_goal。前者用来记录块下一次要分配的文件内块号,后者则用来记录希望下一次能分配的设备上块号。在正常的情况下对文件的扩充是顺利的,所以每次的文件内块号都与前一次的连续,而理想的设备上块号也是同样连续,二者平行的向前推进。当然,这只是从一个特定文件的角度提出的建议值,能否实现还要看条件是否允许,但是内核会尽量满足要求,不能满足也会尽可能靠近建议的块号分配。
可是,文件内逻辑块号也有可能不连续,也就是说对文件的扩充是跨越的,新的逻辑块号与文件原有的最后一个逻辑块号之间留下了空洞。这种情况发生在通过系统调用用lseek将已打开文件的当前读写位置推进了超出文件末尾之后,可以在文件中造成这样的空洞是lseek的一个重要性质。在这种情况下怎样确定对设备上记录块号的建议值呢?这就是调用ext2_find_near的目的:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_find_goal=>ext2_find_near
/**
* ext2_find_near - find a place for allocation with sufficient locality
* @inode: owner
* @ind: descriptor of indirect block.
*
* This function returns the prefered place for block allocation.
* It is used when heuristic for sequential allocation fails.
* Rules are:
* + if there is a block to the left of our position - allocate near it.
* + if pointer will live in indirect block - allocate near that block.
* + if pointer will live in inode - allocate in the same cylinder group.
* Caller must make sure that @ind is valid and will stay that way.
*/
static inline unsigned long ext2_find_near(struct inode *inode, Indirect *ind)
{
u32 *start = ind->bh ? (u32*) ind->bh->b_data : inode->u.ext2_i.i_data;
u32 *p;
/* Try to find previous block */
for (p = ind->p - 1; p >= start; p--)
if (*p)
return le32_to_cpu(*p);
/* No such thing, so let's try location of indirect block */
if (ind->bh)
return ind->bh->b_blocknr;
/*
* It is going to be refered from inode itself? OK, just put it into
* the same cylinder group then.
*/
return (inode->u.ext2_i.i_block_group *
EXT2_BLOCKS_PER_GROUP(inode->i_sb)) +
le32_to_cpu(inode->i_sb->u.ext2_sb.s_es->s_first_data_block);
}
首先将起点start设置成指向当前映射表(映射过程中首次发现映射断裂的那个映射表)的起点,然后在当前映射表内往回搜索。如果要分配的是空洞后面的第一个记录块,那就要往回找到空洞之前的表项所对应的物理块号,并以此为建议块号。当然,这个物理块已经在使用中,这个要求是不可能满足的。但是,内核在分配物理记录块时会在位图中从这里开始往前搜索,就近分配空间的物理记录块之前的表项,此时就以间接映射本身所在记录块作为建议块号。同样,内核在分配物理块号时也会从此开始向前搜索。最后还有一种可能,空洞就在文件的开头处,那就以索引节点所在块组的第一个数据记录块作为建议块号。
回到ext2_get_block的代码中。设备上具体记录块的分配,包括目标记录块和可能需要的用于间接映射的中间记录块,以及映射的建立,是由ext2_alloc_branch完成的。调用之前先要算出映射断裂点离终点的距离,也就是还有几层映射需要建立,有关的代码如下:sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch
/**
* ext2_alloc_branch - allocate and set up a chain of blocks.
* @inode: owner
* @num: depth of the chain (number of blocks to allocate)
* @offsets: offsets (in the blocks) to store the pointers to next.
* @branch: place to store the chain in.
*
* This function allocates @num blocks, zeroes out all but the last one,
* links them into chain and (if we are synchronous) writes them to disk.
* In other words, it prepares a branch that can be spliced onto the
* inode. It stores the information about that chain in the branch[], in
* the same format as ext2_get_branch() would do. We are calling it after
* we had read the existing part of chain and partial points to the last
* triple of that (one with zero ->key). Upon the exit we have the same
* picture as after the successful ext2_get_block(), excpet that in one
* place chain is disconnected - *branch->p is still zero (we did not
* set the last link), but branch->key contains the number that should
* be placed into *branch->p to fill that gap.
*
* If allocation fails we free all blocks we've allocated (and forget
* ther buffer_heads) and return the error value the from failed
* ext2_alloc_block() (normally -ENOSPC). Otherwise we set the chain
* as described above and return 0.
*/
static int ext2_alloc_branch(struct inode *inode,
int num,
unsigned long goal,
int *offsets,
Indirect *branch)
{
int blocksize = inode->i_sb->s_blocksize;
int n = 0;
int err;
int i;
int parent = ext2_alloc_block(inode, goal, &err);
branch[0].key = cpu_to_le32(parent);
if (parent) for (n = 1; n < num; n++) {
struct buffer_head *bh;
/* Allocate the next block */
int nr = ext2_alloc_block(inode, parent, &err);
if (!nr)
break;
branch[n].key = cpu_to_le32(nr);
/*
* Get buffer_head for parent block, zero it out and set
* the pointer to new one, then send parent to disk.
*/
bh = getblk(inode->i_dev, parent, blocksize);
if (!buffer_uptodate(bh))
wait_on_buffer(bh);
memset(bh->b_data, 0, blocksize);
branch[n].bh = bh;
branch[n].p = (u32*) bh->b_data + offsets[n];
*branch[n].p = branch[n].key;
mark_buffer_uptodate(bh, 1);
mark_buffer_dirty_inode(bh, inode);
if (IS_SYNC(inode) || inode->u.ext2_i.i_osync) {
ll_rw_block (WRITE, 1, &bh);
wait_on_buffer (bh);
}
parent = nr;
}
if (n == num)
return 0;
/* Allocation failed, free what we already allocated */
for (i = 1; i < n; i++)
bforget(branch[i].bh);
for (i = 0; i < n; i++)
ext2_free_blocks(inode, le32_to_cpu(branch[i].key), 1);
return err;
}
参数num表示还有几层映射需要建立,实际上也就是一共需要分配几个记录块,指针branch指向前面的数组chain[]中从映射断裂处开始的那一部分,offsets则指向数组offsets中的相应部分。例如,假若具体的映射是三重间接映射,而在第二层间接映射表中发现相应表项为0,那么branch指向chain[2]而offset指向offset[2],num则为2,此时需要分配的是用于第三层间接映射表的记录块以及目标记录块。从某种意义上,分配记录块和建立映射的过程可以看作是对这两个数组的修复,是在完成ext2_get_branch和ext2_block_to_path未竟的事业。注意代码中的branch[0]表示断裂点的Indirect结构,所以是顺着映射的路线自顶向下逐层地通过ext2_alloc_block在设备上分配记录块和建立映射。
除最底层的记录块,即目标记录块以外,其他的记录块(见代码中的for循环)都要通过getblk为其在内存中分配缓冲区,并通过memset将其缓冲区清成全0,然后在缓冲区建立起本层的映射(403-405行),再把它标志成脏。如果要求同步操作的话,还要立即调用ll_rw_block把它写回到设备上。注意代码中的for循环里面为之分配缓冲区的是parent,这都是用于间接映射的记录块,而不是位于最底层的目标记录块。
那么为什么目标记录块是个例外,不需要为其分配缓冲区呢?因为它的缓冲区在调用ext2_get_block之前就已经存在了,并且在调用ext2_get_block时把指向这个buffer_head结构的指针作为参数传了下来;而ext2_get_block需要做的就是找到记录块的块号,把它设置到这个buffer_head结构的b_blocknr字段中。前面,对于成功的映射,即ext2_get_branch返回NULL时,ext2_get_block已经在其标号got_it(525行)这样做了,可以回过去看看。另一方面,在目标记录块的缓冲区中当然不需要再建立什么映射。
还要注意到,在顶层,即原来映射开始断开的那一层上(代码中的branch[0]),所分配的记录块号只是记入了这一层Indirect结构中的key字段,却并未写入相应的映射表项中(由指针p所指之处)。就好像我们有了一根树枝,但是还没有使它长在树上。
函数ext2_alloc_block的代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>ext2_alloc_block
static int ext2_alloc_block (struct inode * inode, unsigned long goal, int *err)
{
#ifdef EXT2FS_DEBUG
static unsigned long alloc_hits = 0, alloc_attempts = 0;
#endif
unsigned long result;
#ifdef EXT2_PREALLOCATE
/* Writer: ->i_prealloc* */
if (inode->u.ext2_i.i_prealloc_count &&
(goal == inode->u.ext2_i.i_prealloc_block ||
goal + 1 == inode->u.ext2_i.i_prealloc_block))
{
result = inode->u.ext2_i.i_prealloc_block++;
inode->u.ext2_i.i_prealloc_count--;
/* Writer: end */
#ifdef EXT2FS_DEBUG
ext2_debug ("preallocation hit (%lu/%lu).\n",
++alloc_hits, ++alloc_attempts);
#endif
} else {
ext2_discard_prealloc (inode);
#ifdef EXT2FS_DEBUG
ext2_debug ("preallocation miss (%lu/%lu).\n",
alloc_hits, ++alloc_attempts);
#endif
if (S_ISREG(inode->i_mode))
result = ext2_new_block (inode, goal,
&inode->u.ext2_i.i_prealloc_count,
&inode->u.ext2_i.i_prealloc_block, err);
else
result = ext2_new_block (inode, goal, 0, 0, err);
}
#else
result = ext2_new_block (inode, goal, 0, 0, err);
#endif
return result;
}
参数goal表示建议分配的(或要求分配的)设备上记录块号,函数的返回值则为实际分配的块号。内核在编译时有个选项EXT2_PREALLOCATE,使文件系统可以预分配若干记录块,ext2_inode_info结构中的i_prealloc_block和i_prealloc_count两个字段即用于这个目的。我们假定并不采用这个选项,所以就只剩下对ext2_new_block的调用,这个函数的代码很长,而逻辑却不复杂,所以我们把它留给读者,这里只给出一些简短的说明。
分配时首先试图满足顾客的要求,如果所建议的记录块还空闲着就把它分配出去。否则,如果所建议的记录块已经分配掉了,就试图在它附近32个记录块的范围内分配。还不行就向前在本块组的位图中搜索。最后,如果实在找不到,就在整个设备的范围内寻找和分配。
前面说过,除目标记录块以外,对分配的其余记录块都要通过getblk为其在内存中分配缓冲区,这个函数的代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk
/*
* Ok, this is getblk, and it isn't very clear, again to hinder
* race-conditions. Most of the code is seldom used, (ie repeating),
* so it should be much more efficient than it looks.
*
* The algorithm is changed: hopefully better, and an elusive bug removed.
*
* 14.02.92: changed it to sync dirty buffers a bit: better performance
* when the filesystem starts to get full of dirty blocks (I hope).
*/
struct buffer_head * getblk(kdev_t dev, int block, int size)
{
struct buffer_head * bh;
int isize;
repeat:
spin_lock(&lru_list_lock);
write_lock(&hash_table_lock);
bh = __get_hash_table(dev, block, size);
if (bh)
goto out;
isize = BUFSIZE_INDEX(size);
spin_lock(&free_list[isize].lock);
bh = free_list[isize].list;
if (bh) {
__remove_from_free_list(bh, isize);
atomic_set(&bh->b_count, 1);
}
spin_unlock(&free_list[isize].lock);
/*
* OK, FINALLY we know that this buffer is the only one of
* its kind, we hold a reference (b_count>0), it is unlocked,
* and it is clean.
*/
if (bh) {
init_buffer(bh, NULL, NULL);
bh->b_dev = dev;
bh->b_blocknr = block;
bh->b_state = 1 << BH_Mapped;
/* Insert the buffer into the regular lists */
__insert_into_queues(bh);
out:
write_unlock(&hash_table_lock);
spin_unlock(&lru_list_lock);
touch_buffer(bh);
return bh;
}
/*
* If we block while refilling the free list, somebody may
* create the buffer first ... search the hashes again.
*/
write_unlock(&hash_table_lock);
spin_unlock(&lru_list_lock);
refill_freelist(size);
goto repeat;
}
这里的参数block为设备上块号。首先在杂凑表队列中查找,因为整个记录块虽然是新分配的,以前为其分配的缓冲区却有可能还在。如不成功则试图从free_list的相应队列中分配。如果分配成功就加以初始化并通过__insert_into_queues链入相应的杂凑表队列和LRU队列:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>__insert_into_queues
static void __insert_into_queues(struct buffer_head *bh)
{
struct buffer_head **head = &hash(bh->b_dev, bh->b_blocknr);
__hash_link(bh, head);
__insert_into_lru_list(bh, bh->b_list);
}
当然,从free_list分配缓冲区有可能失败,那就要通过refill_freelist再添加一些或者回收一些缓冲区以供周转,其代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>refill_freelist
/*
* We used to try various strange things. Let's not.
* We'll just try to balance dirty buffers, and possibly
* launder some pages.
*/
static void refill_freelist(int size)
{
balance_dirty(NODEV);
if (free_shortage())
page_launder(GFP_BUFFER, 0);
grow_buffers(size);
}
我们会看到,对文件的写操作是分两步到位的。第一步是将内容写入缓冲页面中,使缓冲页面成为脏页面,然后就把脏页面链入一个LRU队列,把它提交给内核线程bdflush;第二步是由bdflush将已经变脏的页面写入文件所在的设备。然后,如果有必要,这些内存页面就可以回收了。内核线程bdflush的主体是一个无限循环,平时总在睡眠,每次被唤醒就冲刷一次脏页面,然后又进入睡眠。但是,为了提交效率,并不是只要有了一个脏页面就唤醒bdflush,而是要积累到一定数量的脏页面时,或者每过一段时间才唤醒它。函数balance_dirty的作用就是检查是否已经积累了太多的脏页面了,如果积累太多了,就把bdflush唤醒,其代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>refill_freelist=>balance_dirty
/*
* if a new dirty buffer is created we need to balance bdflush.
*
* in the future we might want to make bdflush aware of different
* pressures on different devices - thus the (currently unused)
* 'dev' parameter.
*/
void balance_dirty(kdev_t dev)
{
int state = balance_dirty_state(dev);
if (state < 0)
return;
wakeup_bdflush(state);
}
先通过balance_dirty_state检查是否因为已经积累起太多脏页面而应该唤醒bdflush。
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>refill_freelist=>balance_dirty=>balance_dirty_state
/* -1 -> no need to flush
0 -> async flush
1 -> sync flush (wait for I/O completation) */
int balance_dirty_state(kdev_t dev)
{
unsigned long dirty, tot, hard_dirty_limit, soft_dirty_limit;
int shortage;
dirty = size_buffers_type[BUF_DIRTY] >> PAGE_SHIFT;
tot = nr_free_buffer_pages();
dirty *= 100;
soft_dirty_limit = tot * bdf_prm.b_un.nfract;
hard_dirty_limit = tot * bdf_prm.b_un.nfract_sync;
/* First, check for the "real" dirty limit. */
if (dirty > soft_dirty_limit) {
if (dirty > hard_dirty_limit)
return 1;
return 0;
}
/*
* If we are about to get low on free pages and
* cleaning the inactive_dirty pages would help
* fix this, wake up bdflush.
*/
shortage = free_shortage();
if (shortage && nr_inactive_dirty_pages > shortage &&
nr_inactive_dirty_pages > freepages.high)
return 0;
return -1;
}
如代码中注释所述,函数的返回值表明可分配页面的短缺程度。返回-1,表示脏页面的数量还不多,因而不需要唤醒bdflush;返回0,表示虽然已经积累起相当数量的脏页面,但还不是很多,可以让bdflush异步地冲刷而不需要停下来等待;返回1,则表示脏页面的数量已经很多,不但要唤醒bdflush,而且当前进程需要停下来等待其完成,因为此时即使继续往前也多半分配不成功。不过在具体实现的时候有做了一些优化。一来不知道bdflush与当前进程的优先级谁高谁低,如果bdflush的优先级比当前进程的低则即使唤醒了也调度不上;二来既然急着要用空闲页面,需求量又不大,还不如自己动手、丰衣足食,先直接冲刷出若干脏页面,然后再让bdflush继续慢慢冲刷。这样,将这个函数的返回值用用作调用wakeup_bdflush的参数,就决定了在唤醒bdflush以后是否直接调用flush_dirty_buffers。
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>refill_freelist=>balance_dirty=>wakeup_bdflush
struct task_struct *bdflush_tsk = 0;
void wakeup_bdflush(int block)
{
if (current != bdflush_tsk) {
wake_up_process(bdflush_tsk);
if (block)
flush_dirty_buffers(0);
}
}
这里的全局变量指针bdflush_tsk在初始化时设置成指向bdflush的task_struct结构。这里的wake_up_process是个inline函数,它将目标进程唤醒,并通过reschedule_idle比较目标进程和当前进程的综合权值,如果目标进程的权值更高就把当前进程的need_resched字段设成1,请求一次调度。然后就根据参数的值决定是否直接调用flush_dirty_buffers,其代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>refill_freelist=>balance_dirty=>wakeup_bdflush=>flush_dirty_buffers
/* ====================== bdflush support =================== */
/* This is a simple kernel daemon, whose job it is to provide a dynamic
* response to dirty buffers. Once this process is activated, we write back
* a limited number of buffers to the disks and then go back to sleep again.
*/
/* This is the _only_ function that deals with flushing async writes
to disk.
NOTENOTENOTENOTE: we _only_ need to browse the DIRTY lru list
as all dirty buffers lives _only_ in the DIRTY lru list.
As we never browse the LOCKED and CLEAN lru lists they are infact
completly useless. */
static int flush_dirty_buffers(int check_flushtime)
{
struct buffer_head * bh, *next;
int flushed = 0, i;
restart:
spin_lock(&lru_list_lock);
bh = lru_list[BUF_DIRTY];
if (!bh)
goto out_unlock;
for (i = nr_buffers_type[BUF_DIRTY]; i-- > 0; bh = next) {
next = bh->b_next_free;
if (!buffer_dirty(bh)) {
__refile_buffer(bh);
continue;
}
if (buffer_locked(bh))
continue;
if (check_flushtime) {
/* The dirty lru list is chronologically ordered so
if the current bh is not yet timed out,
then also all the following bhs
will be too young. */
if (time_before(jiffies, bh->b_flushtime))
goto out_unlock;
} else {
if (++flushed > bdf_prm.b_un.ndirty)
goto out_unlock;
}
/* OK, now we are committed to write it out. */
atomic_inc(&bh->b_count);
spin_unlock(&lru_list_lock);
ll_rw_block(WRITE, 1, &bh);
atomic_dec(&bh->b_count);
if (current->need_resched)
schedule();
goto restart;
}
out_unlock:
spin_unlock(&lru_list_lock);
return flushed;
}
为了不至于扯得太远,我们不分析这段代码,注意2581行的current->need_resched是前面wake_up_process中根据bdflush和当前进程的优先级相对大小而设置的。
冲刷一个脏页面的结果把它的内容写回到文件中,为内存页面的回收创造了条件,但是并不等于已经回收了页面。另一方面,只要内存页面不是很短缺,则保留这些页面的内容为可能发生的进一步读写提供了缓冲,有利于提高效率。所以,回到refill_freelist的代码中以后,接着(见前面的763行-764行)就根据系统中页面短缺的程度决定是否调用page_launder,后面的内存管理会讲解。
最后通过grow_buffers再分配若干页面,制造出一些缓冲区来,现在条件已经具备了。我们把grow_buffers的列出来,大家有兴趣可以自己阅读:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_alloc_branch=>getblk=>refill_freelist=>grow_buffers
/*
* Try to increase the number of buffers available: the size argument
* is used to determine what kind of buffers we want.
*/
static int grow_buffers(int size)
{
struct page * page;
struct buffer_head *bh, *tmp;
struct buffer_head * insert_point;
int isize;
if ((size & 511) || (size > PAGE_SIZE)) {
printk("VFS: grow_buffers: size = %d\n",size);
return 0;
}
page = alloc_page(GFP_BUFFER);
if (!page)
goto out;
LockPage(page);
bh = create_buffers(page, size, 0);
if (!bh)
goto no_buffer_head;
isize = BUFSIZE_INDEX(size);
spin_lock(&free_list[isize].lock);
insert_point = free_list[isize].list;
tmp = bh;
while (1) {
if (insert_point) {
tmp->b_next_free = insert_point->b_next_free;
tmp->b_prev_free = insert_point;
insert_point->b_next_free->b_prev_free = tmp;
insert_point->b_next_free = tmp;
} else {
tmp->b_prev_free = tmp;
tmp->b_next_free = tmp;
}
insert_point = tmp;
if (tmp->b_this_page)
tmp = tmp->b_this_page;
else
break;
}
tmp->b_this_page = bh;
free_list[isize].list = bh;
spin_unlock(&free_list[isize].lock);
page->buffers = bh;
page->flags &= ~(1 << PG_referenced);
lru_cache_add(page);
UnlockPage(page);
atomic_inc(&buffermem_pages);
return 1;
no_buffer_head:
UnlockPage(page);
page_cache_release(page);
out:
return 0;
}
结束了ext2_alloc_branch的执行,回到ext2_get_block中时,我们已经在设备上分配了所需的记录块,包括用于间接映射的中间记录块,但是原先映射开始断开的最高层上所分配的记录块号只是记入了其Indirect结构中的key字段,却并未写入相应的映射表中。现在就要把树枝接在树上(将来,随着文件内容的扩展,这树枝会长成子树)。同时,还需要对所属inode结构中的有关内容做一些调整。这些都是由ext2_splice_branch完成的。其代码如下:
sys_write=>generic_file_write=>ext2_prepare_write=>block_prepare_write=>__block_prepare_write=>ext2_get_block=>ext2_splice_branch
/**
* ext2_splice_branch - splice the allocated branch onto inode.
* @inode: owner
* @block: (logical) number of block we are adding
* @chain: chain of indirect blocks (with a missing link - see
* ext2_alloc_branch)
* @where: location of missing link
* @num: number of blocks we are adding
*
* This function verifies that chain (up to the missing link) had not
* changed, fills the missing link and does all housekeeping needed in
* inode (->i_blocks, etc.). In case of success we end up with the full
* chain to new block and return 0. Otherwise (== chain had been changed)
* we free the new blocks (forgetting their buffer_heads, indeed) and
* return -EAGAIN.
*/
static inline int ext2_splice_branch(struct inode *inode,
long block,
Indirect chain[4],
Indirect *where,
int num)
{
int i;
/* Verify that place we are splicing to is still there and vacant */
/* Writer: pointers, ->i_next_alloc*, ->i_blocks */
if (!verify_chain(chain, where-1) || *where->p)
/* Writer: end */
goto changed;
/* That's it */
*where->p = where->key;
inode->u.ext2_i.i_next_alloc_block = block;
inode->u.ext2_i.i_next_alloc_goal = le32_to_cpu(where[num-1].key);
inode->i_blocks += num * inode->i_sb->s_blocksize/512;
/* Writer: end */
/* We are done with atomic stuff, now do the rest of housekeeping */
inode->i_ctime = CURRENT_TIME;
/* had we spliced it onto indirect block? */
if (where->bh) {
mark_buffer_dirty_inode(where->bh, inode);
if (IS_SYNC(inode) || inode->u.ext2_i.i_osync) {
ll_rw_block (WRITE, 1, &where->bh);
wait_on_buffer(where->bh);
}
}
if (IS_SYNC(inode) || inode->u.ext2_i.i_osync)
ext2_sync_inode (inode);
else
mark_inode_dirty(inode);
return 0;
changed:
for (i = 1; i < num; i++)
bforget(where[i].bh);
for (i = 0; i < num; i++)
ext2_free_blocks(inode, le32_to_cpu(where[i].key), 1);
return -EAGAIN;
}
这里的第459行将原来映射开始断开的那一层所分配的记录块号写入相应的映射表中。这个映射表也许就是inode结构中(确切地说是ext2_inode_info结构中)的数组i_data,也许是一个用于间接映射的记录块。如果相应Indirect结构中的指针bh为0(必定是chain[0]),则映射表就在inode结构中。否则,就一定是个间接映射表,因此在改变了其内容以后要将其标志成脏。如果要求同步写,则还要立即把它写回设备。
又回到ext2_get_block中,现在已经万事俱备了。转到标号got_it处,把映射后的记录块号连同设备号置入bh_result所指的缓冲区结构中,就完成了任务。有了这些信息,将来就可以把缓冲区的内容写到设备上了。
从ext2_get_block返回,就回到了__block_prepare_write中的第1586行。对于__block_prepare_write而言,ext2_get_block为其完成了从文件内块号到设备上块号的映射,这个目标记录块也许是新的,也许原来就存在。如果目标记录块是一个新分配的记录块,就不存在缓冲区的内容与设备上的内容是否一致的问题。但是如果内存中的某一个其他缓冲区仍持有该记录块以前的内容,并且还在杂凑表的某个队列中,则要将那个缓冲区从杂凑队列中脱链并释放。这是通过unmap_underlying_metadata完成的。反之,如果目标记录块是原已存在记录块,则仍有的内容是否一致的问题,如果不一致就要先通过ll_rw_block从设备上读入。这样,当__block_prepare_write中的for循环结束时,所有涉及本次写操作的物理记录块(缓冲区)都已找到,需要从设备上读入的则已经向设备驱动层发出读入记录的命令。通过wait_on_buffer等待这些命令执行完毕(见1616行-1621行)以后,写操作的准备工作就完成了。
由于__block_prepare_write是block_prepare_write的主体,一旦从前者返回,后者也就结束了,而后者又实际上就是ext2_prepare_write,所以就返回到了generic_file_write。
在generic_file_write中是在一个while循环中通过由具体文件系统所提供的函数为写文件操作做准备的,准备好了以后就可以从用户空间把待写的内容复制到缓冲区中,实际上是缓冲页面中。为方便分析,我们再把while循环体中的一个片段列出来:
sys_write=>generic_file_write
status = mapping->a_ops->prepare_write(file, page, offset, offset+bytes);
if (status)
goto unlock;
kaddr = page_address(page);
status = copy_from_user(kaddr+offset, buf, bytes);
flush_dcache_page(page);
if (status)
goto fail_write;
status = mapping->a_ops->commit_write(file, page, offset, offset+bytes);为写操作做好了准备以后,从缓冲发过去(缓冲页面)到设备上的记录块这条路就畅通了。这样才可以从用户空间把待写的内容复制过来。
如前所述,目标记录块的缓冲区在文件层是作为缓冲页面的一部分而存在的,所以这是从用户空间到缓冲页面的拷贝,具体通过copy_from_user完成。这里buf指向用户空间的缓冲区,而(kaddr+offset)为缓冲页面中的起始地址,bytes则为该页面中待拷贝的长度,这些都是在while循环的开头计算好了的。对于i386结构的处理器,flush_dcache_page是空操作。
写入缓冲页面以后,还要把这些缓冲页面提交给内核线程bdflushd,这样写操作才算完成。至于kflushd是否来得及马上将这些记录块写回设备上,那是另一回事了。这个将缓冲页面提交给kflushd的操作也是因文件系统而异的,由具体文件系统通过其address_space_operations结构中的commit_write提供,对于ext2文件系统,这个函数是generic_commit_write,其代码如下:
sys_write=>generic_file_write=>generic_commit_write
int generic_commit_write(struct file *file, struct page *page,
unsigned from, unsigned to)
{
struct inode *inode = page->mapping->host;
loff_t pos = ((loff_t)page->index << PAGE_CACHE_SHIFT) + to;
__block_commit_write(inode,page,from,to);
kunmap(page);
if (pos > inode->i_size) {
inode->i_size = pos;
mark_inode_dirty(inode);
}
return 0;
}
其主体__block_commit_write的代码也在同一个文件中,而kunmap对于i386结构的处理器为空操作。
sys_write=>generic_file_write=>generic_commit_write=>__block_commit_write
static int __block_commit_write(struct inode *inode, struct page *page,
unsigned from, unsigned to)
{
unsigned block_start, block_end;
int partial = 0, need_balance_dirty = 0;
unsigned blocksize;
struct buffer_head *bh, *head;
blocksize = inode->i_sb->s_blocksize;
for(bh = head = page->buffers, block_start = 0;
bh != head || !block_start;
block_start=block_end, bh = bh->b_this_page) {
block_end = block_start + blocksize;
if (block_end <= from || block_start >= to) {
if (!buffer_uptodate(bh))
partial = 1;
} else {
set_bit(BH_Uptodate, &bh->b_state);
if (!atomic_set_buffer_dirty(bh)) {
__mark_dirty(bh);
buffer_insert_inode_queue(bh, inode);
need_balance_dirty = 1;
}
}
}
if (need_balance_dirty)
balance_dirty(bh->b_dev);
/*
* is this a partial write that happened to make all buffers
* uptodate then we can optimize away a bogus readpage() for
* the next read(). Here we 'discover' wether the page went
* uptodate as a result of this (potentially partial) write.
*/
if (!partial)
SetPageUptodate(page);
return 0;
}
函数中的for循环扫描缓冲页面中的每个记录块,如果一个记录块与写入的范围(从from到to)相交,就把该记录块的缓冲区设成up to date,即与设备上记录块相一致,并将其标志成dirty,下面的事就交给kflushd了。值得注意的是这里已经将缓冲区的BH_Uptodate标志设成1,表示缓冲区的内容已经与设备一致了。可是,实际上此时缓冲区的内容尚未写回设备,所以从物理上说显然是不一致的。但是,由于写操作本身已经接近完成,涉及的缓冲区即将提交给kflushd,从逻辑的角度上缓冲区中的内容与设备上的内容已经一致了。所以所谓一致或者不一致只是一个逻辑上的概念,而非物理上的概念。只要写入的内容已经提交(commit),就认为已经一致了。而不一致的状态只发生在写操作的中途,即改变了缓冲区(或部分缓冲区)的内容而尚未提交之前。在写入的准备阶段,遇到有不一致的缓冲区就要从设备上重新读入,就是因为有未完成的写操作存在而破坏了缓冲区的内容。此外,在将缓冲区设置成dirty时,如果该缓冲区原来是干净的,那么一来要调用__mark_dirty,二来要将need_balance_dirty设成1。调用__mark_dirty的目的是将缓冲区根据具体情况转移到合理的LRU队列中,有关的代码如下:
sys_write=>generic_file_write=>generic_commit_write=>__block_commit_write=>__mark_dirty
static __inline__ void __mark_dirty(struct buffer_head *bh)
{
bh->b_flushtime = jiffies + bdf_prm.b_un.age_buffer;
refile_buffer(bh);
}
sys_write=>generic_file_write=>generic_commit_write=>__block_commit_write=>__mark_dirty=>refile_buffer
void refile_buffer(struct buffer_head *bh)
{
spin_lock(&lru_list_lock);
__refile_buffer(bh);
spin_unlock(&lru_list_lock);
}
sys_write=>generic_file_write=>generic_commit_write=>__block_commit_write=>__mark_dirty=>refile_buffer=>__refile_buffer
/*
* A buffer may need to be moved from one buffer list to another
* (e.g. in case it is not shared any more). Handle this.
*/
static void __refile_buffer(struct buffer_head *bh)
{
int dispose = BUF_CLEAN;
if (buffer_locked(bh))
dispose = BUF_LOCKED;
if (buffer_dirty(bh))
dispose = BUF_DIRTY;
if (buffer_protected(bh))
dispose = BUF_PROTECTED;
if (dispose != bh->b_list) {
__remove_from_lru_list(bh, bh->b_list);
bh->b_list = dispose;
if (dispose == BUF_CLEAN)
remove_inode_queue(bh);
__insert_into_lru_list(bh, dispose);
}
}
数据结构buffer_head通过其指针b_next_free和b_prev_free链入到空闲缓冲区队列或某个LRU队列中,而作为记录块缓冲区LRU队列头部的lru_list则是一个指针数组。其定义如下:
static struct buffer_head *lru_list[NR_LIST];
这个数组时以记录块缓冲区的状态为下标的:
#define BUF_CLEAN 0
#define BUF_LOCKED 1 /* Buffers scheduled for write */
#define BUF_DIRTY 2 /* Dirty buffers, not yet scheduled for write */
#define BUF_PROTECTED 3 /* Ramdisk persistent storage */
#define NR_LIST 4这样,对处于各种不同的状态的记录块缓冲区,就各自有个LRU队列,而bdflush就只扫描lru_list[BUF_DIRTY]队列。
最后,只要有记录块缓冲区从干净状态变成脏状态,也就是如果need_balance_dirty为1,就要通过balance_dirty看看这样的记录块是否已经积累到了一定的数量,如果是,就唤醒bdflush进行一次冲刷。这个函数的代码已经在前面看到过了。
不管是否立即唤醒bdflush,总之此后的事情就交给它了。我们将在设备驱动的博客中回到这个话题上来。
完成了generic_commit_write以后,generic_file_write中一轮循环,也就是对一个缓冲页面的写入就完成了。从而对该页面的使用也结束了,所以要通过page_cache_release递减对该页面的使用计数。
总结对一个缓冲页面的写文件操作,大致可以分成三个阶段。第一是准备阶段,第二是缓冲页面的写入阶段,最后是提交阶段。完成了对所涉及的所有页面的循环,整个写文件操作的主体generic_file_write就告结束,并且sys_write也随着结束了。
理解了sys_write,再看sys_read就容易一些了。这两个函数几乎是一样的,只是在sys_write中要验证用户空间的缓冲区可读,并且使用file_operations结构中的函数指针write,而在sys_read中则要验证用户空间的缓冲区可写,并且使用file_operations结构中的函数指针read。就ext2文件系统的读操作而言,这个函数指针指向generic_file_read,其代码如下:
sys_read=>generic_file_read
/*
* This is the "read()" routine for all filesystems
* that can use the page cache directly.
*/
ssize_t generic_file_read(struct file * filp, char * buf, size_t count, loff_t *ppos)
{
ssize_t retval;
retval = -EFAULT;
if (access_ok(VERIFY_WRITE, buf, count)) {
retval = 0;
if (count) {
read_descriptor_t desc;
desc.written = 0;
desc.count = count;
desc.buf = buf;
desc.error = 0;
do_generic_file_read(filp, ppos, &desc, file_read_actor);
retval = desc.written;
if (!retval)
retval = desc.error;
}
}
return retval;
}
显然,这个函数只是do_generic_file_read的包装。其目的在于检查对用户空间缓冲区的写访问权限,并为读文件操作准备下一个读操作描述结构,即read_descriptor_t数据结构,以减少在调用do_generic_file_read时传递参数的个数。
由于do_generic_file_read的代码比较长,我们还是分段阅读:
sys_read=>generic_file_read=>do_generic_file_read
/*
* This is a generic file read routine, and uses the
* inode->i_op->readpage() function for the actual low-level
* stuff.
*
* This is really ugly. But the goto's actually try to clarify some
* of the logic when it comes to error handling etc.
*/
void do_generic_file_read(struct file * filp, loff_t *ppos, read_descriptor_t * desc, read_actor_t actor)
{
struct inode *inode = filp->f_dentry->d_inode;
struct address_space *mapping = inode->i_mapping;
unsigned long index, offset;
struct page *cached_page;
int reada_ok;
int error;
int max_readahead = get_max_readahead(inode);
cached_page = NULL;
index = *ppos >> PAGE_CACHE_SHIFT;
offset = *ppos & ~PAGE_CACHE_MASK;
/*
* If the current position is outside the previous read-ahead window,
* we reset the current read-ahead context and set read ahead max to zero
* (will be set to just needed value later),
* otherwise, we assume that the file accesses are sequential enough to
* continue read-ahead.
*/
if (index > filp->f_raend || index + filp->f_rawin < filp->f_raend) {
reada_ok = 0;
filp->f_raend = 0;
filp->f_ralen = 0;
filp->f_ramax = 0;
filp->f_rawin = 0;
} else {
reada_ok = 1;
}
/*
* Adjust the current value of read-ahead max.
* If the read operation stay in the first half page, force no readahead.
* Otherwise try to increase read ahead max just enough to do the read request.
* Then, at least MIN_READAHEAD if read ahead is ok,
* and at most MAX_READAHEAD in all cases.
*/
if (!index && offset + desc->count <= (PAGE_CACHE_SIZE >> 1)) {
filp->f_ramax = 0;
} else {
unsigned long needed;
needed = ((offset + desc->count) >> PAGE_CACHE_SHIFT) + 1;
if (filp->f_ramax < needed)
filp->f_ramax = needed;
if (reada_ok && filp->f_ramax < MIN_READAHEAD)
filp->f_ramax = MIN_READAHEAD;
if (filp->f_ramax > max_readahead)
filp->f_ramax = max_readahead;
}参数actor是一个函数指针,这里的实际参数就是file_read_actor,这个函数的作用就是将文件的内容从缓冲页面拷贝到用户空间的缓冲区中。
文件的读操作有一个比写操作更复杂之处,那就是预读。我们在开头时曾谈到过预读,现在就要涉及具体的代码了。预读量的大小是与具体设备有关的,内核中设置了一个以主设备号为下标的数组max_readahead,定义如下:
/*
* The following tunes the read-ahead algorithm in mm/filemap.c
*/
int * max_readahead[MAX_BLKDEV];数组中的每个元素都是指针,指向以次设备号为下标的另一个整数数组,那个数组中的元素就是每个具体设备的最大预读量。同时,内核中还提供了一个inline函数get_max_readahead,利用这个函数根据inode结构中的设备号就可确定对特定文件的最大预读量。这个函数的定义如下:
sys_read=>generic_file_read=>do_generic_file_read=>get_max_readahead
/*
* Read-ahead context:
* -------------------
* The read ahead context fields of the "struct file" are the following:
* - f_raend : position of the first byte after the last page we tried to
* read ahead.
* - f_ramax : current read-ahead maximum size.
* - f_ralen : length of the current IO read block we tried to read-ahead.
* - f_rawin : length of the current read-ahead window.
* if last read-ahead was synchronous then
* f_rawin = f_ralen
* otherwise (was asynchronous)
* f_rawin = previous value of f_ralen + f_ralen
*
* Read-ahead limits:
* ------------------
* MIN_READAHEAD : minimum read-ahead size when read-ahead.
* MAX_READAHEAD : maximum read-ahead size when read-ahead.
*
* Synchronous read-ahead benefits:
* --------------------------------
* Using reasonable IO xfer length from peripheral devices increase system
* performances.
* Reasonable means, in this context, not too large but not too small.
* The actual maximum value is:
* MAX_READAHEAD + PAGE_CACHE_SIZE = 76k is CONFIG_READA_SMALL is undefined
* and 32K if defined (4K page size assumed).
*
* Asynchronous read-ahead benefits:
* ---------------------------------
* Overlapping next read request and user process execution increase system
* performance.
*
* Read-ahead risks:
* -----------------
* We have to guess which further data are needed by the user process.
* If these data are often not really needed, it's bad for system
* performances.
* However, we know that files are often accessed sequentially by
* application programs and it seems that it is possible to have some good
* strategy in that guessing.
* We only try to read-ahead files that seems to be read sequentially.
*
* Asynchronous read-ahead risks:
* ------------------------------
* In order to maximize overlapping, we must start some asynchronous read
* request from the device, as soon as possible.
* We must be very careful about:
* - The number of effective pending IO read requests.
* ONE seems to be the only reasonable value.
* - The total memory pool usage for the file access stream.
* This maximum memory usage is implicitly 2 IO read chunks:
* 2*(MAX_READAHEAD + PAGE_CACHE_SIZE) = 156K if CONFIG_READA_SMALL is undefined,
* 64k if defined (4K page size assumed).
*/
static inline int get_max_readahead(struct inode * inode)
{
if (!inode->i_dev || !max_readahead[MAJOR(inode->i_dev)])
return MAX_READAHEAD;
return max_readahead[MAJOR(inode->i_dev)][MINOR(inode->i_dev)];
}
这里的常数MAX_READAHEAD定义为1,则31个页面,124K字节。
所前所述,由于预读的引入,现在file结构中要维持两个上下文了。一个是以当前位置f_pos为代表的真正的读写上下文,另一个则是预读的上下文,为此目的在file结构中增设了f_reada, f_ramax, f_raend, f_ralen, f_rawin五个字段。这五个字段的名称反映了它们的用途,代码作者在注释中也作了说明。所谓预读上下文,实际上是一个窗口。窗口的末端就是f_raend,而窗口的大小则为f_rawin。与写操作相似,局部变量index为当前读写位置所在页面的序号,offset则为页面内的位移。如果读操作的起始页面落在读窗口的外面,也就是index大于预读窗口的终点页面或者小于预读窗口的起始页面,那么现在的预读窗口与当前的读操作就没什么关系了,所以要另起炉灶来一个新的预读窗口(见1034-1039行)。否则就是如何推进现有预读窗口的问题,所以先保持现有的窗口不变,而将局部变量read_ok设成1.然后,还要对file结构中的最大预读量作一些调整。如果当前所要求的读操作仅仅局限于文件的第一个页面的前半部分中进行(见1050行),那就根本不需要预读所以将file结构的f_ramax字段设成0。否则就要依据整个读操作所涉及的页面数量needed和一些常量、参数适当调整f_ramax字段的数值(见1057-1063行)。对预读操作上下文作了这些准备以后,就开始读了。继续看do_generic_file_read的代码:
sys_read=>generic_file_read=>do_generic_file_read
for (;;) {
struct page *page, **hash;
unsigned long end_index, nr;
end_index = inode->i_size >> PAGE_CACHE_SHIFT;
if (index > end_index)
break;
nr = PAGE_CACHE_SIZE;
if (index == end_index) {
nr = inode->i_size & ~PAGE_CACHE_MASK;
if (nr <= offset)
break;
}
nr = nr - offset;
/*
* Try to find the data in the page cache..
*/
hash = page_hash(mapping, index);
spin_lock(&pagecache_lock);
page = __find_page_nolock(mapping, index, *hash);
if (!page)
goto no_cached_page;
found_page:
page_cache_get(page);
spin_unlock(&pagecache_lock);
if (!Page_Uptodate(page))
goto page_not_up_to_date;
generic_file_readahead(reada_ok, filp, inode, page);
page_ok:
/* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
if (mapping->i_mmap_shared != NULL)
flush_dcache_page(page);
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*
* The actor routine returns how many bytes were actually used..
* NOTE! This may not be the same as how much of a user buffer
* we filled up (we may be padding etc), so we can only update
* "pos" here (the actor routine has to update the user buffer
* pointers and the remaining count).
*/
nr = actor(desc, page, offset, nr);
offset += nr;
index += offset >> PAGE_CACHE_SHIFT;
offset &= ~PAGE_CACHE_MASK;
page_cache_release(page);
if (nr && desc->count)
continue;
break;
不难想象,整个读操作是通过一个循环完成的,这个循环依次走过所涉及的每个缓冲区页面,完成从这些页面的读出。由于这个for循环内部的流程比较复杂,我们通过一个假象的情景来遍历这个for循环的代码,这个情景涉及对三个缓冲页面的读出。
与写操作不同,当读操作位置到达了(或超出了)文件的末尾就结束了(见1070-1078行),而不像写操作或lseek那样将文件的末尾向前推进。只要还没有到达文件的末尾,就根据页面的大小或者目标文件在其最后一个页面中的大小nr,以及读操作在当前页面中的起点offset计算出从当前页面读出的长度(见1073-1080行)。
决定了从当前页面中读操作的长度以后,就要设法找到或读入相应的缓冲页面了。首先当然是根据目标页面的杂凑值从杂凑表队列中寻找(见1085-1088行)。寻找的结果有三种可能,第一种是找不到,第二种是找到了,但是该缓冲页面的内容不一致,第三种是找到了所需的缓冲页面,页面的内容又一致。
在我们的情景里,假定第一个缓冲页面找到了,并且一致,所以就到达了第1098行的page_ok标号处。既然找到了目标页面,下面的事情就顺理成章了。如前所述,参数actor是个函数指针,这个指针实际上指向file_read_actor。它的作用就是从缓冲页面把内容复制到用户空间的缓冲区中,并且相应调整读操作描述结构中的待读出长度,最后返回已复制的长度。完成了从缓冲页面中的读出以后,就根据file_read_actor的返回值nr将index和offset两个变量的值向前推进,并将当前页面释放(递减其使用计数)。在我们这个情景中,从这个页面读出的长度nr非0,尚待读出的长度还未达到0,所以经由第1123行的continue语句开始下一轮循环(否则就经由第1124行的break语句结束循环)。
我们假定寻找第二个目标页面的结果也找到了,但是页面的内容不一致,所以在第1096行转移到标号page_not_up_to_date处:
sys_read=>generic_file_read=>do_generic_file_read
/*
* Ok, the page was not immediately readable, so let's try to read ahead while we're at it..
*/
page_not_up_to_date:
generic_file_readahead(reada_ok, filp, inode, page);
if (Page_Uptodate(page))
goto page_ok;
/* Get exclusive access to the page ... */
lock_page(page);
/* Did it get unhashed before we got the lock? */
if (!page->mapping) {
UnlockPage(page);
page_cache_release(page);
continue;
}
/* Did somebody else fill it already? */
if (Page_Uptodate(page)) {
UnlockPage(page);
goto page_ok;
}
readpage:
/* ... and start the actual read. The read will unlock the page. */
error = mapping->a_ops->readpage(filp, page);
if (!error) {
if (Page_Uptodate(page))
goto page_ok;
/* Again, try some read-ahead while waiting for the page to finish.. */
generic_file_readahead(reada_ok, filp, inode, page);
wait_on_page(page);
if (Page_Uptodate(page))
goto page_ok;
error = -EIO;
}
/* UHHUH! A synchronous read error occurred. Report it */
desc->error = error;
page_cache_release(page);
break;
由于页面的内容不一致,所以不能马上从这个页面读出。页面内容不一致是个暂时的现象,这是由于某个进程正在写包括这个页面,但尚未提交导致的,一般只要等待一会儿就行了。可既然要等待,就不如乘机预读一些页面进来,所以通过generic_file_readahead启动预读。我们把这个函数的阅读暂时放一下,在这里只要知道这个函数启动预读就行了。不过需要注意,这里说的是启动预读,而不是完成预读,实际的页面读入是异步的。
启动了预读以后,再来检查当前的目标页面是否已经一致(见第1132行)。如果已经一致了那就转到page_ok标号处(第1098行),下面就与第一个页面的情况一样了。如果还没有一致呢?那就要从设备上把这个页面读回来。读之前要先把页面锁住,注意这里的lock_page可能隐含着等待,因为这页面可能已经被别的进程锁住了。特别是这个页面还不一致,就说明有某个进程正在进行写操作,很可能就是这个进程锁住了页面。所以,lock_page的过程实际上就是睡眠等待当前锁住这个页面的进程完成其操作并且解锁的过程。当从lock_page返回时,这个页面已经被当前进程锁住了。正因为这样,就很可能当加锁成功时页面已经一致了,所以要再次加以检查,如果确已一致,就把锁解除并转向page_ok。
要是加了锁而页面仍旧没有达成一致,那就无计可施,只好从设备上把页面读出来,这就到了标号readpage处。对具体文件系统和设备的读操作是由具体的address_space_operations数据结构通过函数指针readpage提供的,对于ext2文件系统这个函数是ext2_readpage,其代码如下:
sys_read=>generic_file_read=>do_generic_file_read=>ext2_readpage
static int ext2_readpage(struct file *file, struct page *page)
{
return block_read_full_page(page,ext2_get_block);
}
这个函数通过一个通用的函数,即block_read_full_page完成操作,而以ext2_get_block作为调用的参数之一。读者应该还记得,ext2_get_block完成ext2文件系统从文件中逻辑块号到设备上块号的映射。函数block_read_full_page的代码如下:
sys_read=>generic_file_read=>do_generic_file_read=>ext2_readpage=>block_read_full_page
/*
* Generic "read page" function for block devices that have the normal
* get_block functionality. This is most of the block device filesystems.
* Reads the page asynchronously --- the unlock_buffer() and
* mark_buffer_uptodate() functions propagate buffer state into the
* page struct once IO has completed.
*/
int block_read_full_page(struct page *page, get_block_t *get_block)
{
struct inode *inode = page->mapping->host;
unsigned long iblock, lblock;
struct buffer_head *bh, *head, *arr[MAX_BUF_PER_PAGE];
unsigned int blocksize, blocks;
int nr, i;
if (!PageLocked(page))
PAGE_BUG(page);
blocksize = inode->i_sb->s_blocksize;
if (!page->buffers)
create_empty_buffers(page, inode->i_dev, blocksize);
head = page->buffers;
blocks = PAGE_CACHE_SIZE >> inode->i_sb->s_blocksize_bits;
iblock = page->index << (PAGE_CACHE_SHIFT - inode->i_sb->s_blocksize_bits);
lblock = (inode->i_size+blocksize-1) >> inode->i_sb->s_blocksize_bits;
bh = head;
nr = 0;
i = 0;
do {
if (buffer_uptodate(bh))
continue;
if (!buffer_mapped(bh)) {
if (iblock < lblock) {
if (get_block(inode, iblock, bh, 0))
continue;
}
if (!buffer_mapped(bh)) {
memset(kmap(page) + i*blocksize, 0, blocksize);
flush_dcache_page(page);
kunmap(page);
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
/* get_block() might have updated the buffer synchronously */
if (buffer_uptodate(bh))
continue;
}
arr[nr] = bh;
nr++;
} while (i++, iblock++, (bh = bh->b_this_page) != head);
if (!nr) {
/*
* all buffers are uptodate - we can set the page
* uptodate as well.
*/
SetPageUptodate(page);
UnlockPage(page);
return 0;
}
/* Stage two: lock the buffers */
for (i = 0; i < nr; i++) {
struct buffer_head * bh = arr[i];
lock_buffer(bh);
bh->b_end_io = end_buffer_io_async;
atomic_inc(&bh->b_count);
}
/* Stage 3: start the IO */
for (i = 0; i < nr; i++)
submit_bh(READ, arr[i]);
return 0;
}
每个缓冲页面包含着若干记录块缓冲区,page数据结构中的buffer_head指针buffers指向这些缓冲区的buffer_head数据结构队列。如果一个缓冲页面尚未建立起这样的队列,就要通过create_empty_buffers加以创建。很自然地,然后是对构成该页面的各个记录块缓冲区的循环。以前讲过,一个页面的内容不一致并不说明构成这个页面的所有记录块都不一致。所以,如果一个记录块的内容时一致的就把它跳过(见第1698行的continue语句)。如果一个记录块缓冲区尚未与设备上的物理记录块建立起映射关系(见第1700行),并且这个记录块的起始地址并未超过文件的末尾(见第1701行和1702行),就要通过作为参数传递下来的函数建立起映射。在这里,对于ext2文件系统而言,这个函数就是ext2_get_block,我们已经在前面读过它的代码。
不过,这里对这个函数的调用与写文件时有所不同,那就是第三个参数为0,而在写操作时这个 参数为1。这个参数表示如果尚未为给定的逻辑记录块分配物理记录块的话,现在回过去看一下。该函数代码中标号cleanup前有个if(!creat...)语句;当ext2_get_branch返回了一个非0指针,表示尚未为给定的逻辑记录块分配物理记录块时,就由这个if语句决定怎么办。如果参数create为0,就表示不为之分配物理记录块,此时并不设置相应缓冲区头中的有关字段,也并不将其BH_MAPPED标志设置成1。
所以,如果在调用了ext2_get_block以后缓冲区的映射仍未建立,就表示这个逻辑记录块尚无与之对应的物理记录块。这种情况发生在通过lseek系统调用在文件中引入了空洞以后。
从空洞中读出的内容是什么呢?请看下面紧接着的几行。就是说,如果逻辑记录块落在一个空洞中,就把它清成全0,所以读出的内容也是全0。那么,什么时候才为这个逻辑记录块分配设备上的物理空间呢?要等待对这个记录块进程写操作的时候。到那时,调用ext2_get_block的第三个参数create是1,就会为之分配物理记录块了。
除这两种情况以外,那就是已经建立起映射但是内容不一致的页面了。这种页面是真正需要从设备上读入的页面,所以一方面通过init_buffer对buffer_head结构进行一些设置,主要是对函数指针b_end_io的设置,这个函数指针提供了当设备的I/O完成时要启动的操作,在这里是end_buffer_io_async。函数init_buffer的代码如下:
sys_read=>generic_file_read=>do_generic_file_read=>ext2_readpage=>block_read_full_page=>init_buffer
void init_buffer(struct buffer_head *bh, bh_end_io_t *handler, void *private)
{
bh->b_list = BUF_CLEAN;
bh->b_end_io = handler;
bh->b_private = private;
}虽然这个记录块时肯定要从设备上读入的,但是却并不立即就在循环体内启动对设备的操作,而只是先把真正需要读入的记录块缓冲区收集在一个指针数组arr[]中(见第1733行)。这个数组随后被作为参数传递给ll_rw_block,将积累起来的属于同一个页面的记录块成批地读入,而对ll_rw_block的调用则留待对记录块的循环结束以后。
记录块的读入时需要一定时间的,而ll_rw_block实际上只是启动记录块的读入,所以从ll_rw_block以及随之从ext2_readpage的返回和读入的完成(通过DMA完成)是异步的,互相平行的。
这样,当返回到do_generic_file_read中时(第1155行),页面中需要读入的记录块也许已经全部完成,从而使页面的PG_uptodate标志位已经变成了1,表明该页面的内容已经一致,但是也有可能尚未全部完成而页面的内容尚未一致。如果是前者就转入page_ok,此后的操作就与前述第一个页面的情况相同了。
可能如果尚未完成呢?那就需要等待。既然要等待,那何不干脆再多读一些记录块进来备用呢?所以这里又调用处理预读的generic_file_readahead。对于因页面内容不一致而从标号page_not_up_to_date执行下来进入readpage的路线而言,这已经是第二次调用generic_file_readahead了。但是进入readpage的路线并非只有这么一条,所以这里的预读一方面也是出于对其他情况的考虑,这一点读者以后就会看到。
虽然通过预读消耗了一些时间,目标页面的读入仍不能肯定已经完成,所以要通过wait_on_page加以检验或等待。到页面(实际上是其中的若干记录块)的读入肯定已经完成时,页面的Page_Uptodate标志位应该为1,否则就有错了。这里Page_Uptodate所作的仅仅是一种检验而不包含等待,而wait_on_page则包含了可能的睡眠等待。
目标页面的读入顺利完成以后,就转向page_ok,此后的操作就又与前述第一个页面相同了。完成了第二个缓冲页面的读出以后,由于所要求的读出尚未完成,又通过第1123行的continue语句回到了for循环的开头。
这一次,由于涉及的第三个逻辑页面没有被缓冲在内存中,__find_page_nolock返回NULL,所以就转到了no_cached_page。继续往下看:
sys_read=>generic_file_read=>do_generic_file_read
no_cached_page:
/*
* Ok, it wasn't cached, so we need to create a new
* page..
*
* We get here with the page cache lock held.
*/
if (!cached_page) {
spin_unlock(&pagecache_lock);
cached_page = page_cache_alloc();
if (!cached_page) {
desc->error = -ENOMEM;
break;
}
/*
* Somebody may have added the page while we
* dropped the page cache lock. Check for that.
*/
spin_lock(&pagecache_lock);
page = __find_page_nolock(mapping, index, *hash);
if (page)
goto found_page;
}
/*
* Ok, add the new page to the hash-queues...
*/
page = cached_page;
__add_to_page_cache(page, mapping, index, hash);
spin_unlock(&pagecache_lock);
cached_page = NULL;
goto readpage;
}
*ppos = ((loff_t) index << PAGE_CACHE_SHIFT) + offset;
filp->f_reada = 1;
if (cached_page)
page_cache_free(cached_page);
UPDATE_ATIME(inode);
}
既然在内存中尚未为目标页面建立缓冲,那就不仅仅是从设备读入的问题了,在此之前还要为之分配一个页面。在前面第1023行中指针cached_page初始化NULL,表示没有已经分配但尚未使用的缓冲页面,所以这里通过page_cache_alloc分配一个页面备用。但是,在分配成功以后还要再检查一次目标页面是否已经缓冲(见第1182行),这是因为在page_cache_alloc中当前进程有可能进入睡眠,从而有可能让别的进程先为目标页面建立了缓冲。如果这种情况真发生了,那就转入found_page,此后的操作就与前述的第一和第二个页面相同了。至于分配得的页面cached_page,则成了“已经分配但尚未使用的缓冲页面”,我们不必忙着将其释放,因为也许以后还有需求,如果确实没有需要就拖延到最后在第1211行加以释放。否则,要是没有发生这样的情况,那就将分配得的页面链入到所有有关的队列中,包括由所属inode结构中的指针i_mapping所指向的address_space结构(通常是inode结构中的i_data)里面的缓冲页面队列、全局性的缓冲页面杂凑表队列以及全局性的缓冲页面LRU队列。然后就转向readpage,此后的操作就与前述第二个页面的一部分操作相同了。
由于这已经是涉及的最后一个页面,所以从这个页面的读出完成后,就通过第1124行的break语句结束for循环而到达第1208行,在这里对file结构中的f_pos字段加以调整。注意,index和offset的值在循环中每次都在向前推进(见1117-1119行),所以此时已经指向本次read操作以后的位置上。另一方面,当前的预读上下文继续有效,所以将file结构中的f_reada标志设成1。
由于generic_file_readahead是do_generic_file_read的主体,至此我们可以认为读操作已经完成。
在上面的叙述中,我们跳过了预读函数generic_file_readahead的细节,这个函数的代码如下:
sys_read=>generic_file_read=>do_generic_file_read=>generic_file_readahead
static void generic_file_readahead(int reada_ok,
struct file * filp, struct inode * inode,
struct page * page)
{
unsigned long end_index = inode->i_size >> PAGE_CACHE_SHIFT;
unsigned long index = page->index;
unsigned long max_ahead, ahead;
unsigned long raend;
int max_readahead = get_max_readahead(inode);
raend = filp->f_raend;
max_ahead = 0;
/*
* The current page is locked.
* If the current position is inside the previous read IO request, do not
* try to reread previously read ahead pages.
* Otherwise decide or not to read ahead some pages synchronously.
* If we are not going to read ahead, set the read ahead context for this
* page only.
*/
if (PageLocked(page)) {
if (!filp->f_ralen || index >= raend || index + filp->f_rawin < raend) {
raend = index;
if (raend < end_index)
max_ahead = filp->f_ramax;
filp->f_rawin = 0;
filp->f_ralen = 1;
if (!max_ahead) {
filp->f_raend = index + filp->f_ralen;
filp->f_rawin += filp->f_ralen;
}
}
}
/*
* The current page is not locked.
* If we were reading ahead and,
* if the current max read ahead size is not zero and,
* if the current position is inside the last read-ahead IO request,
* it is the moment to try to read ahead asynchronously.
* We will later force unplug device in order to force asynchronous read IO.
*/
else if (reada_ok && filp->f_ramax && raend >= 1 &&
index <= raend && index + filp->f_ralen >= raend) {
/*
* Add ONE page to max_ahead in order to try to have about the same IO max size
* as synchronous read-ahead (MAX_READAHEAD + 1)*PAGE_CACHE_SIZE.
* Compute the position of the last page we have tried to read in order to
* begin to read ahead just at the next page.
*/
raend -= 1;
if (raend < end_index)
max_ahead = filp->f_ramax + 1;
if (max_ahead) {
filp->f_rawin = filp->f_ralen;
filp->f_ralen = 0;
reada_ok = 2;
}
}
/*
* Try to read ahead pages.
* We hope that ll_rw_blk() plug/unplug, coalescence, requests sort and the
* scheduler, will work enough for us to avoid too bad actuals IO requests.
*/
ahead = 0;
while (ahead < max_ahead) {
ahead ++;
if ((raend + ahead) >= end_index)
break;
if (page_cache_read(filp, raend + ahead) < 0)
break;
}
/*
* If we tried to read ahead some pages,
* If we tried to read ahead asynchronously,
* Try to force unplug of the device in order to start an asynchronous
* read IO request.
* Update the read-ahead context.
* Store the length of the current read-ahead window.
* Double the current max read ahead size.
* That heuristic avoid to do some large IO for files that are not really
* accessed sequentially.
*/
if (ahead) {
if (reada_ok == 2) {
run_task_queue(&tq_disk);
}
filp->f_ralen += ahead;
filp->f_rawin += filp->f_ralen;
filp->f_raend = raend + ahead + 1;
filp->f_ramax += filp->f_ramax;
if (filp->f_ramax > max_readahead)
filp->f_ramax = max_readahead;
/*
* Move the pages that have already been passed
* to the inactive list.
*/
drop_behind(filp, index);
#ifdef PROFILE_READAHEAD
profile_readahead((reada_ok == 2), filp);
#endif
}
return;
}
参数reada_ok表示目标页面page是否在原来的预读窗口之内,这是在do_generic_file_read开头时就计算好了的。
首先要根据具体情况确定一个合适的预读量max_ahead,这个预读量最初时假定为0,然后根据具体情况加以修正。怎样修正呢?主要取决于当前页面page是否已经锁上,也就是对这个页面中记录块的设备层读入请求是否已经发出。如果已经发出,而当前页面又在先前的预读窗口之内,并且原来的预读窗口中已经包含了对当前页面以后若干页面的预读,那就保持max_ahead为0,最后无功而返。这种情况下generic_file_readahead只是作了一个简单的检测而并不是真正进行预读。
如果当前页面虽然已经被锁住,也就是说已经交付设备驱动层加以读入,但是原来并没有预读(file结构中的f_ralen为0),或者当前页面已经预读窗口中的最后一个页面或者超出了预读窗口的上沿(index >= raend),或者当前页面已经是预读窗口的下沿以下,那就说明要另起一个预读窗口了。这个预读窗口的大小首先取决于file结构中的f_ramax,这是最初在do_generic_file_read中的for循环开始之前与f_raend和f_rawin一起算好的;如果在for循环中已经调用过generic_file_readahead则由上一次调用遗留下来。根据具体情况的不同,这个数值仍可能为0,那就表示不要预读。不过,如果看一下generic_file_readahead中的第1050-1064行,就可以发现一般情况下这个数值都不会是0。
如果当前页面没有被锁住,设备驱动层的读入请求尚未发出呢?与前一种情况正好相反。在前一种情况下,是在如果原来没有预读窗口,或者当前页面落在原有窗口之外时才预读。而现在则是如果原来就有预读窗口(read_ok非0),并且当前页面落在原有窗口之内时才预读(见934行好835行)。此时的预读量max_ahead也来自file结构中的f_ramax,但是要增加一个页面,因为对当前页面的读入也作为预读处理了。如果比较一下在两种情况下对filp->r_ralen的初始化,就可以看到再前一种情况下将其设置成1,因为对当前页面的读入已经在进行中,而在后一种情况则将其设置成0,因为对当前页面的读入尚未开始。此外,在949行将reada_ok设置成2,表示此时的预读为“异步预读”。其区别在后面会看到。
确定了合适的预读量以后,就开始通过一个while循环依次启动对各个页面的读入。函数page_cache_read的代码如下:
sys_read=>generic_file_read=>do_generic_file_read=>generic_file_readahead=>page_cache_read
/*
* This adds the requested page to the page cache if it isn't already there,
* and schedules an I/O to read in its contents from disk.
*/
static inline int page_cache_read(struct file * file, unsigned long offset)
{
struct inode *inode = file->f_dentry->d_inode;
struct address_space *mapping = inode->i_mapping;
struct page **hash = page_hash(mapping, offset);
struct page *page;
spin_lock(&pagecache_lock);
page = __find_page_nolock(mapping, offset, *hash);
spin_unlock(&pagecache_lock);
if (page)
return 0;
page = page_cache_alloc();
if (!page)
return -ENOMEM;
if (!add_to_page_cache_unique(page, mapping, offset, hash)) {
int error = mapping->a_ops->readpage(file, page);
page_cache_release(page);
return error;
}
/*
* We arrive here in the unlikely event that someone
* raced with us and added our page to the cache first.
*/
page_cache_free(page);
return 0;
}
我们对这段代码已经不会感到陌生了,具体的读入由mapping->a_ops->readpage启动。对于ext2文件系统就是ext2_readpage,我们已经在前面看过它的代码了。这里要指出的是,如果__find_page_nolock找到了所需的页面就直接返回0而跳过了页面的读入,但是在上面的while循环中却还是将其看成已经进行了预读。当然,这么一来这个已经缓冲的页面可能与设备上不一致,但是也没什么关系,因为当读这个页面时如果发现仍不一致就会在do_generic_file_read中转入page_not_up_to_date处加以处理。
只要不在中途到达了文件的终点(end_index为最后一个逻辑记录块的序号),while循环就要到完成了由max_ahead决定的预读量才会结束。注意,在ext2_readpage中只是通过ll_rw_block完成了对各个记录块的读入请求,而真正的读入时通过DMA进行的,当前进程并不停下来等待其完成。从这个角度讲,所有的磁盘读、写其实都是异步的,而预读之所以分为同步和异步,其区别在于第978行run_task_queue的调用,即抽出时间做点别的什么,我们在设备驱动的博客中还会回到这个话题。此外,除对预读窗口的更新外,还将file结构中的最大预读量f_ramax加倍(见985行),只是这个数值不能超过由get_max_readahead取得的对于文件所在设备的最大预读量max_ahead。所以,在同一个预读上下文改变时,也就是通过lseek将当前位置改变到当前预读窗口之外以后的第一次读操作时,就会重新开始一个新的上下文而又开始积累最大预读量。
至于profile_readahead,那只是用于统计信息的收集,此处我们就对之不感兴趣了。