【Linux】进程通信 | 管道
今天让我们来认识如何使用管道来进行进程间通信
文章目录
- 1.何为管道?
-
- 1.1 管道是进程间通信的一种方式
- 1.2 进程通信
- 1.3 管道分类
- 2.匿名管道
-
- 2.0 康康源码
- 2.1 创建
- 2.2 父子通信
-
- 完整代码
- 2.3 等待
-
- 写入等待
- 读取等待
- 源码中的体现
- 2.4 控制多个子进程
- 2.5 命令行 |
- 3.命名管道
-
- 3.1 创建管道文件
- 3.2 实现两个进程之间的通信
-
- 等待
- 4.管道的特性
-
- 4.1 什么是半双工?
- 4.2 拓展:单工/半双工/双工
- 结语
1.何为管道?
在最初学习linux的基础命令时,接触过用|来连接多个命令的操作。当时便提到了这是一个管道操作,但没有详解管道到底是什么。
1.1 管道是进程间通信的一种方式
管道管道,如同其名,是一个可以让数据在内部流动的东西。创建管道,就好比在两个阀门(进程)之间搭了一根水管,我们可以自由控制管道中水的流向
不过,在Linux系统中提供的管道接口,只支持单项流动。一个管道只支持从A->B,不支持B->A
要想进行双向通信,则需要创建两个管道
1.2 进程通信
既然管道是用来进程通信的,那进程通信又是什么,它有何用呢?
进程通信的目的是让两个进程可以相互交流,包括以下几种情况:
- 数据传输,从进程A发送数据道进程B
- 资源共享,多个进程使用同一个资源
- 通知事件,进程A向进程B发送消息,告知进程B发生了什么事件
- 进程控制,父进程通过管道来控制子进程的执行,进程A控制进程B的执行等等
除了管道,我们还可以通过systemV/POSIX来实现进程通信
进程通信的核心思想:让两个进程获取到同一份资源
1.3 管道分类
管道分为两种
- 匿名管道,pipe
- 命名管道,管道文件
且听我慢慢道来
2.匿名管道
匿名管道主要用于父子进程之间的通信,其使用pipe接口来进行创建
![]()
类似于fork,我们只需要在创建了之后判断函数的返回值就可以了
其中pipefd[2]是一个输出型参数,我们要预先创建好一个2个空间的数组,传入该函数。pipe会创建一个匿名管道(可以理解为一个只属于该进程的临时文件)并将读端赋值给pipefd[0],写端赋值给pipefd[1]
- 如果我们需要父进程写,子进程读,就在父进程关闭读端,子进程关闭写端
- 如果我们需要父进程读,子进程写,就在父进程关闭写段,子进程关闭读端
通过这种方式,我们就在父子进程中打通了一个管道,可以让父子进程进行一定的交流
而fd正是我们之前学习过的Linux下文件描述符,其管道的读写操作和调用系统接口读写文件完全相同!
博客:linux文件操作
2.0 康康源码
/include/linux/pipe_fs_i.h中可以找到管道操作的源码
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
其中我们的管道文件拥有一个缓冲区,这个缓冲区有一个专门的struct pipe_buf_operations结构体用来处理它的输入输出方法,以及flags用来标识当前缓冲区的装态
2.1 创建
首先,我们需要用pipe接口创建一个匿名管道,使用并不难
// 1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) != 0)
{
cerr << "pipe error" << endl;
return 1;
}
因为pipe是通过pipefd这个输出型参数来创建管道的,所以我们并不需单独定义一个变量来接受该函数的返回值,直接在if语句中进行判断即可
void TestPipe2()
{
// 1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) != 0)
{
cerr << "pipe error" << endl;
return ;
}
cout << pipefd[0] << " " << pipefd[1] << endl;
}
先来个小测试,打印这两个值可以发现,它其实是两个不同的文件描述符。系统分别用读方法和写方法打开了同一个文件,供我们使用
[muxue@bt-7274:~/git/linux/code/22-11-04_pipe]$ ./test
3 4
[muxue@bt-7274:~/git/linux/code/22-11-04_pipe]$
我们自己打开的文件描述符是从3开始的,012对应的是stdin/stdout/stderr
2.2 父子通信
有了匿名管道,接下来就可以尝试在父子进程中进行通信了
以父写子读为例,我们需要在子进程关闭写段,父进程关闭读端
pipefd是父进程的资源,fork创建子进程之后,该资源会发生一次写时拷贝,以供父子进程共享
// 2.创建子进程
pid_t id = fork();
if(id < 0)
{
cerr << "fork error" << endl;
return 2;
}
else if (id == 0)
{
// 3.子进程管道
// 子进程读取, 关掉写端
close(pipefd[1]);
//...
}
else
{
// 4.父进程管道
// 父进程写入,关掉读端
close(pipefd[0]);
//...
}
处理完之后,后续的操作便是linux的文件操作了
完整代码
以下是完整代码,通过文件接口对pipefd进行read/write,就能让父进程发送的字符串被子进程读取道
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
#define NUM 1024
//匿名管道
int TestPipe()
{
// 1.创建管道
int pipefd[2] = {0};
if(pipe(pipefd) != 0)
{
cerr << "pipe error" << endl;
return 1;
}
// 2.创建子进程
pid_t id = fork();
if(id < 0)
{
cerr << "fork error" << endl;
return 2;
}
else if (id == 0)
{
// 3.子进程管道
// 子进程来进行读取, 子进程就应该关掉写端
close(pipefd[1]);
char buffer[NUM];
while(1)
{
cout << "time_stamp: " << (size_t)time(nullptr) << endl;
// 子进程没有带sleep,为什么子进程你也会休眠呢??
memset(buffer, 0, sizeof(buffer));
ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1);
if(s > 0)
{
//读取成功
buffer[s] = '\0';
cout << "子进程收到消息,内容是: " << buffer << endl;
}
else if(s == 0)
{
cout << "父进程写完了,我也退出啦" << endl;
break;
}
else{
cerr << "err while chlid read pipe" << endl;
}
}
close(pipefd[0]);
exit(0);
}
else
{
// 4.父进程管道
// 父进程来进行写入,就应该关掉读端
close(pipefd[0]);
const char *msg = "你好子进程,我是父进程, 这次发送的信息编号是";
int cnt = 0;
while(cnt < 10)
{
char sendBuffer[1024];
sprintf(sendBuffer, "%s : %d", msg, cnt);//格式化控制字符串
write(pipefd[1], sendBuffer, strlen(sendBuffer));
cnt++;
cout << "cnt: " << cnt << endl;
sleep(1);
}
close(pipefd[1]);
cout << "父进程写完了" << endl;
}
// 父进程等待子进程结束
pid_t res = waitpid(id, nullptr, 0);
if(res > 0)
{
cout << "等待子进程成功" << endl;
}
cout << "父进程退出" < 运行成功,可以看到父进程每次写入之后,子进程读取

父进程休眠的时候,子进程看起来啥事没有做
实际上,子进程是在等待父进程对管道的写入
2.3 等待
之前我们学习过进程等待相关的知识点,其中提到了进程有时候需要等待另外一个进程的执行。比如父进程等待子进程执行完成(上面的代码也用了waitpid等待)
而管道,就是进程需要等待的资源之一
- 如果管道为空,读端必须要等待写端写入,否则无法执行后面的代码
- 如果管道满了,写段必须等待读端取走数据,否则不能写入。因为此时写入会覆盖之前的数据
那么,进程是在执行到什么函数的时候开始等待的呢?
答案是:进程将在read/write中进行阻塞等待!
- 执行到read的时候,操作系统判断匿名管道中没有有效数据,让执行read的进程等待管道写入
- 执行到write的时候,操作系统判断管道已经满了,就让执行write的进程等待管道被读取(而且需要管道被清空了才能继续写入)
- 这个判断机制是管道文件中自带的,是一种同步和互斥机制
- 相比之下,我们向显示器输出的时候,就没有访问控制,父子进程向显示器输出内容的顺序是完全随机的
本质就是将该进程的task_strcut放入等待队列中,并将状态从R设置为S/D/T
写入等待
对第二点进行一个测试,我们把父进程改成死循环,子进程每休眠3s读取一次管道

执行后会发现,父进程几乎是在一瞬间写入了1226次数据,随后子进程开始读取,此时我们会发现,尽管子进程已经开始读取了,但是父进程却米有动静。
子进程需要将管道内的数据读取一部分,父进程才能继续执行写入。
此时父进程就是在
write里面进行等待的
进一步观察会发现,当子进程读取到77次消息的时候,父进程又开始往管道里面写入了
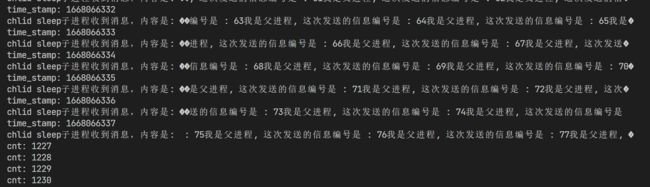
嘿,你猜怎么着?父进程刚好写入了74次消息!而子进程继续读取之前的管道信息
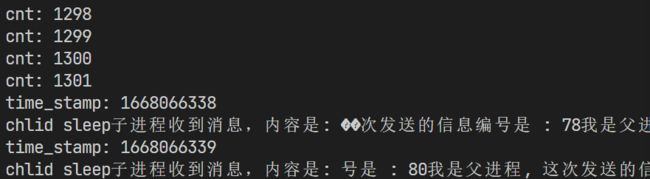
这便告诉我们,父进程需要等待子进程将管道内容读取一部分(清理掉一部分)之后,才能继续往管道内部写入。
但在读端,这一切都不一样了
读取等待
我们让父进程直接睡上20s在进行写入,可以看到,子进程是执行到read开始等待的
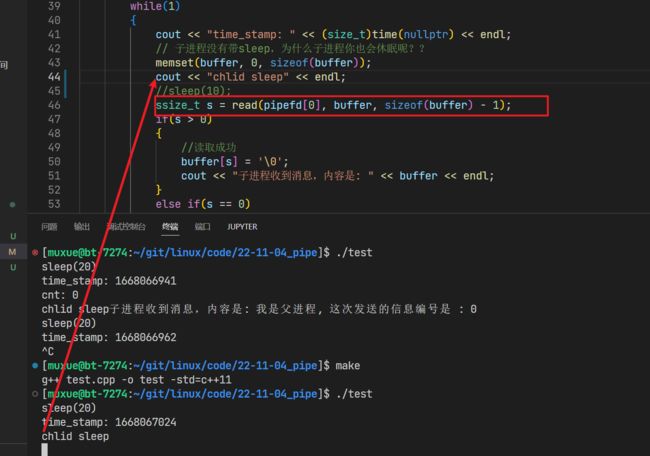
当父进程第一次写入之后,子进程立马打印出了消息的内容。随后父进程又进入了休眠,子进程开始了新一次等待

简而言之,就是只要你不往管道里面写东西,子进程就需要一直等下去!
源码中的体现
源码中有一个单独的结构体,用来标识管道文件。其中inode便是Linux下的文件描述符
struct pipe_inode_info {
wait_queue_head_t wait;
unsigned int nrbufs, curbuf;
struct page *tmp_page;
unsigned int readers;
unsigned int writers;
unsigned int waiting_writers;
unsigned int r_counter;
unsigned int w_counter;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct inode *inode;
struct pipe_buffer bufs[PIPE_BUFFERS];
};
在这里我们可以看到一个wait结构体,其为一个等待队列,维护写入和读取的等待
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
spinlock是何方神圣我们暂且不知,但list_head结构体告诉我们,这是一个等待队列的链表
struct list_head {
struct list_head *next, *prev;
};
2.4 控制多个子进程
上面只是实现了父进程和一个子进程的通信,在实际场景中这远远不够用。接下来就来实现一个父进程和多个子进程之间的通信,通过管道给子进程分配不同的任务!
具体的操作在注释中有所标明,如果有什么问题欢迎评论提出!
#include 先是父进程创建了5个子进程
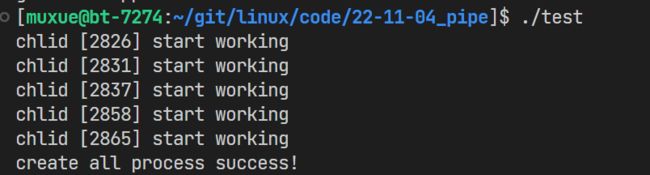
再开始用生成随机数的方式,为每一个进程指派相应的“任务”(其实就是一个函数)

15次任务指派完毕之后,以一个循环,通过管道写入-1作为停止符,让子进程停止工作。同时main函数中进行waitpid等待子进程运行成功!
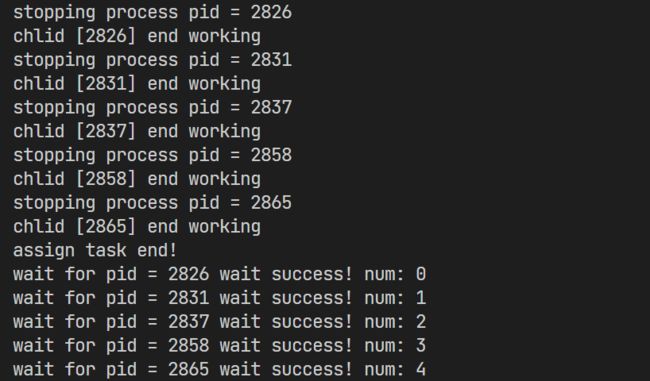
2.5 命令行 |
命令行中输入的|命令,其实就是一个匿名管道
![]()
这里我们用|运行两个sleep命令,再查看这两个进程,可以看到这两个进程是属于同一个父进程的,这说明这两个sleep进程是一对兄弟~

当父进程创建一对管道的时候,它可以创建两个子进程,并将管道交付给子进程进行使用
- 父进程创建管道,创建子进程AB
- 父进程关闭
pipefd[0]和[1] - 子进程A关闭读端,执行写入
- 子进程B关闭写段,执行读取
而|就是将信息转给两个子进程使用的一种匿名管道!这也能解释为什么我们可以先ps ajx,再用| grep在内部搜索内容并打印出来。其就是通过匿名管道实现了几个命令中的信息共享
3.命名管道
和匿名管道不同的是,命名管道是通过一个管道文件来实现的,其有一个文件的“实体”,支持多个进程打开同一个管道文件,执行读写操作,实现管道的交流
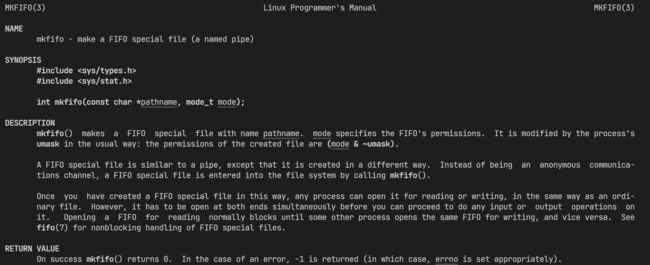
我们通过mkfifo接口创建一个FIFO(front in front out/先进先出)的管道文件,这里的注释也表明他是一个命名管道a named pipe
3.1 创建管道文件
操作方法和创建一个文件的方法是一样的,指定一个路径,并指定该文件的权限。为了避免受系统的权限掩码值的影响,我们要用umask将权限掩码值置零
umask(0);
if(mkfifo("test.pipe", 0600) != 0)
{//当返回值不为0的时候,代表出现了错误
cerr << "mkfifo error" << endl;
return 1;
}
运行之后可以看到,出现了一个新的文件。其文件权限值的开头为p,代表它是一个管道文件
之后的操作同样是文件操作,因为管道文件本质上就是一个文件
- 先使用open方法,指定用读、写方法
- 再分别在读写端
read/write操作文件 - 操作完成之后,
close文件,并删除该文件 - 因为管道文件有唯一的路径,其能够完成让两个进程看到同一份资源,也就实现了进程通信的功能!
3.2 实现两个进程之间的通信
下面通过一个服务端和客户端的代码,来演示多进程通信。
- 服务端负责创建管道文件,以读方式打开该管道文件
- 客户端以写方式打开管道文件,向服务端发送消息
完整代码如下,包含一个头文件和两个源文件
//MyPath.h
#pragma once
#include 通过头文件中的文件路径,我们能保证客户端和服务端处于同一个工作目录下,以便他们正确打开同一个管道文件
先运行server,会发现并没有出现服务器启动的打印
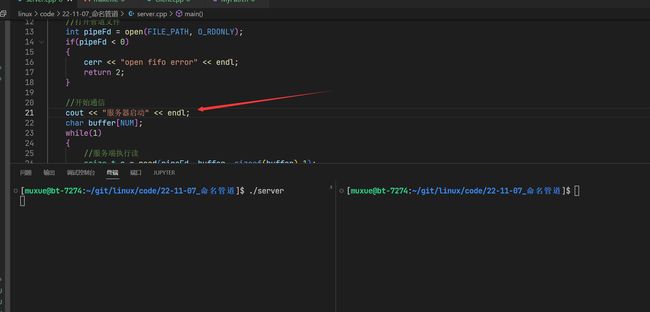
客户端启动了之后,服务器端才打印出服务器启动
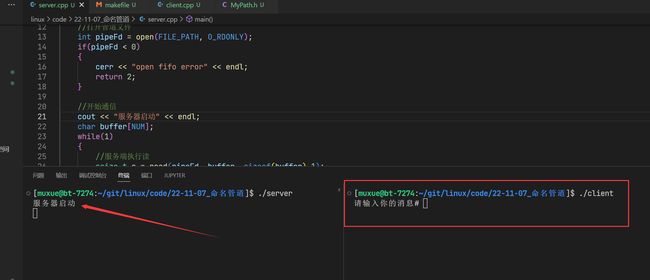
这时候,我们就可以在客户端输入消息,转到服务端读取

这就完成了两个进程之间的通信。这两个进行并非父子进程,也不是兄弟关系!
客户端CTRL+C终止的时候,服务端也会退出!

等待
前面提到了,当客户端没有启动的时候,服务端的打印没有被执行
进一步测试发现,当我们同时用写方式打开管道文件的时候,这两个进程都会在open中等待,而不执行cout

23776 31027 31027 23776 pts/23 31027 S+ 1001 0:00 ./server
23952 31043 31043 23952 pts/24 31043 S+ 1001 0:00 ./client
这说明,管道文件必须要同时以读写方式打开,才能正常执行后续代码。如果一个进程以写方式打开了一个管道,而该管道没有读端(反过来也是一样的),该进程就会进行阻塞等待
4.管道的特性
- 单个管道只支持单向通信,这是内核实现决定的。
半双工的一种特殊情况 - 管道自带同步机制,能够判断管道的状态,是否写满,是否没有写入等等
- 管道是面向字节流的,先写的字符一定是先被读取的,在
2.3中有所体现。需要用户来定义区分内容的边界(比如网络tcp协议) - 管道是一个文件,管道的生命周期跟随进程
4.1 什么是半双工?
半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信;
管道就是一种半双工的特殊情况,因为管道本身是支持任意进程读写的。对于进程A,它既可以成为管道的读端,又可以成为管道的写端。但一旦确认之后,管道的读写方向就不能被改变。
所以管道是属于半双工的一种特殊情况
4.2 拓展:单工/半双工/双工
参考资料来源:博客园
- 单工数据传输只支持数据在一个方向上传输;
- 半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信;
- 全双工数据通信允许数据同时在两个方向上传输,因此,全双工通信是两个单工通信方式的结合,它要求发送设备和接收设备都有独立的接收和发送能力。
结语
阿巴阿巴,关于管道的内容到这里就基本over了,我们通过匿名管道实现了控制多个子进程。通过命名管道实现了两个不相干进程之间的通信
下篇博客是关于共享内存的
如果有啥问题,可以在评论区提出哦!