doris实现数据聚合的三种方式--多明细聚合、物化视图与rollup
doris实现数据聚合的三种方式
假设以
①ds、hour为维度计算pv
②ds为维度计算pv
1、三种聚合方式
(1)聚合模型+数据源多次写入
flink写入kafka代码
insert into log_exp_pv
select ds
hour,
device_id
from
dwd_kafka_log
;
insert into log_exp_pv
select ds
'ALL' hour,
device_id
from
dwd_kafka_log
;
doris建表语句
create table log_exp_pv(
ds date,
hour varchar(1000),
pv bigint sum DEFAULT '0'
)
AGGREGATE KEY(ds,hour)
partition by range(ds)
(start('20220514') end ('20220520') every (INTERVAL 1 day))
distributed by hash(platform) buckets 32
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "7",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32",
"replication_num" = "1"
)
;
routine load 从kafka导入数据到doris
CREATE ROUTINE LOAD routine_load_log_exp_pv ON log_exp_pv
COLUMNS TERMINATED BY ",",
COLUMNS (
ds
,hour
,pv = 1
)
PROPERTIES
(
"desired_concurrent_number"="3",
"max_error_number"="0",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list"= "",
"kafka_topic" = "log_exp_pv",
"property.group.id"="routine_load_log_exp_pv"
);
(2)明细模型 + 物化视图
flink写入kafka代码
insert into log_exp_pv
select ds
hour,
device_id
from
dwd_kafka_log
;
doris建表语句
create table log_exp_detail(
ds date,
hour varchar(1000),
user_id bigint
)
duplicate key(ds,hour)
partition by range(ds)
(start('20220512') end ('20220520') every (INTERVAL 1 day))
distributed by hash(channel) buckets 32
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "7",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32",
"replication_num" = "1"
);
routine load 从kafka导入数据到doris
CREATE ROUTINE LOAD routine_load_log_exp_detail ON log_exp_detail
COLUMNS TERMINATED BY ",",
COLUMNS (
ds
,hour
,user_id
)
PROPERTIES
(
"desired_concurrent_number"="3",
"max_error_number"="0",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list"= "",
"kafka_topic" = "log_exp_detail",
"property.group.id"="routine_load_log_exp_detail"
);
创建物化视图
##ds维度
CREATE MATERIALIZED VIEW mv_ds AS
SELECT ds
,count(user_id) pv
FROM log_exp_detail
GROUP BY ds;
##ds、hour维度
CREATE MATERIALIZED VIEW mv_ds_hour AS
SELECT ds
,hour
,count(user_id) pv
FROM log_exp_detail
GROUP BY ds
,hour;
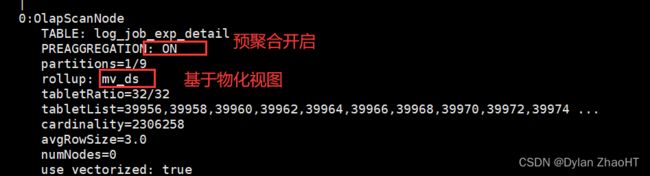
查询计划
explain
SELECT ds
,count(user_id) pv
FROM log_job_exp_detail
GROUP BY ds;
(3)聚合模型 + rollup
doris建表语句
create table log_exp_pv(
ds date,
hour varchar(1000),
pv bigint sum DEFAULT '0'
)
AGGREGATE KEY(ds,hour)
partition by range(ds)
(start('20220514') end ('20220520') every (INTERVAL 1 day))
distributed by hash(platform) buckets 32
rollup (
r1(ds)
,r2(ds,hour)
)
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "7",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32",
"replication_num" = "1"
)
;
routine load 从kafka导入数据到doris
CREATE ROUTINE LOAD routine_load_log_exp_pv ON log_exp_pv
COLUMNS TERMINATED BY ",",
COLUMNS (
ds
,hour
,user_id
)
PROPERTIES
(
"desired_concurrent_number"="3",
"max_error_number"="0",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list"= "",
"kafka_topic" = "log_exp_pv",
"property.group.id"="routine_load_log_exp_pv"
);
查询计划
explain
SELECT ds
,count(user_id) pv
FROM log_exp_pv
GROUP BY ds;

2、三种导入方式对比
(1)聚合模型+数据源多次写入
优点:
①只需关心聚合模型即可
②存储为聚合模型,降低了数据量
缺点:
①假设维度为n,则数据量会膨胀2^n倍,导致数据导入压力增大
②维度过多时,明细数据开发复杂度增加
(2)明细模型 + 物化视图
优点:
①明细数据只需一份
②明细模型保留原始数据
缺点:
①存储为明细数据,导致存储数据量较大
②多维度时,物化视图需要建立多次
③物化视图语法有严格限制
(3)聚合模型 + rollup
优点:
①存储为聚合模型,降低了数据量
②建表时即可指定rollup,降低了开发复杂性
缺点:
①明细数据无法保留