DFS序和欧拉序的降维打击
1. DFS 序和时间戳
1.1 DFS 序
定义:树的每一个节点在深度优先遍历中进、出栈的时间序列。
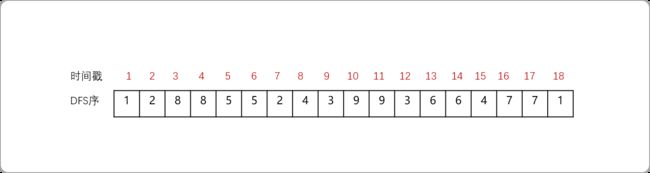
如下树的 dfs 序就是[1,2,8,8,5,5,2,4,3,9,9,3,6,6,4,7,7,1]。
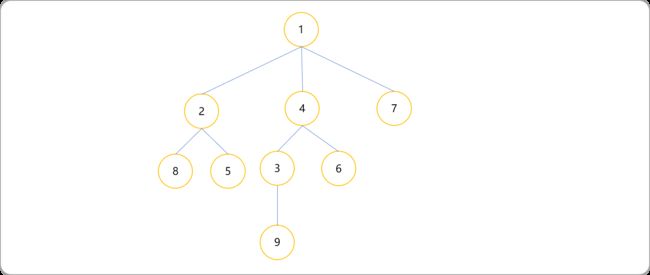
下图为生成DFS的过程。对于一棵树进行DFS序,除了进入当前节点时对此节点进行记录,同时在回溯到当前节点时对其也记录一下,所以DFS序中一个节点的信息会出现两次。
Tips: 因为在树上深度搜索时可以选择从任一节点开始,所以
DFS序不是唯一的。
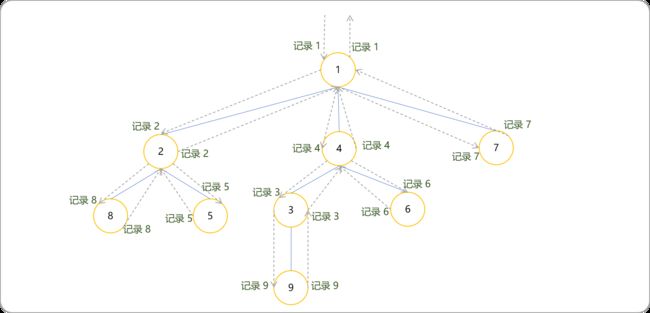
DFS序的特点:
-
可以把树数据结构转换为线性数据结构,从而可以把基于线性数据的算法间接用于处理树上的问题。堪称降维打击。
-
相同编号之间的节点编号为以此编号为根节点的子树上的所有节点编号。
[2,8,8,5,5,2]表示编号2为根节点的子树中所有节点为8,5。[4,3,9,9,3,6,6,4]表示编号4为根节点的子树中所有节点为3,9,6。 -
如果一个节点的编号连续相同,则此节点为叶节点。
-
树的
DFS序的长度是2N(N表示节点的数量)。
求DFS序的代码:
#include
using namespace std;
const int maxn=1e5+10;
int n;
int tot,to[maxn<<1],nxt[maxn<<1],head[maxn];
int id[maxn],cnt;
void add(int x,int y)
{
to[++tot]=y;
nxt[tot]=head[x];
head[x]=tot;
}
void dfs(int x,int f)
{
id[++cnt]=x;
for(int i=head[x];i;i=nxt[i])
{
int y=to[i];
if(y==f)
continue;
dfs(y,x);
}
id[++cnt]=x;
}
int main()
{
scanf("%d",&n);
for(int i=1;i 测试数据:
9
1 2
1 4
1 7
2 8
2 5
4 3
4 6
3 9
1.2 时间戳
按照深度优先遍历的过程,按每个节点第一次被访问的顺序,依次给予这些节点1−N的标记,这个标记就是时间戳。如果一个点的起始时间和终结时间被另一个点包括,这个点肯定是另一个点的子节点(简称括号化定理)。每棵子树 x 在 DFS 序列中一定是连续的一段,结点 x 一定在这段的开头。
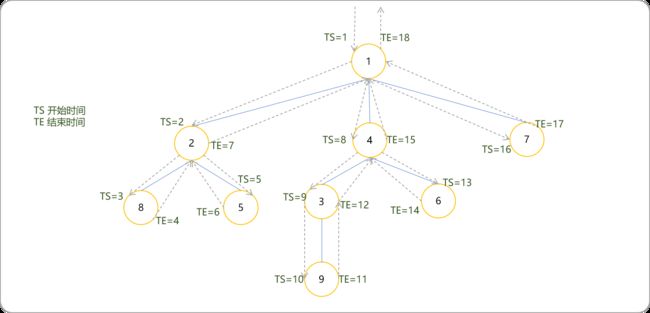
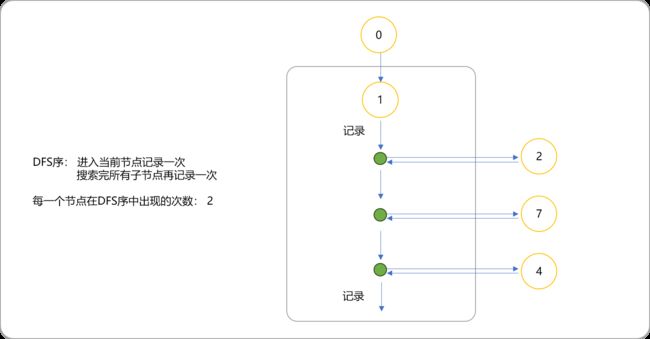
dfs与时间戳的关系,对应列表中索引号和值的关系。
在dfs代码中添加进入节点时的顺序和离开节点时的顺序。
//……
//in 开始时间 out 结束时间
int in[maxn],out[maxn];
//……
void dfs(int x,int f) {
//节点的 dfs 序
id[++cnt]=x;
//开始时间
in[x]=cnt;
for(int i=head[x]; i; i=nxt[i]) {
int y=to[i];
if(y==f)
continue;
dfs(y,x);
}
id[++cnt]=x;
//结束时间
out[x]=cnt;
}
//……
3. DFS 序的应用
3.1 割点
什么是割点?
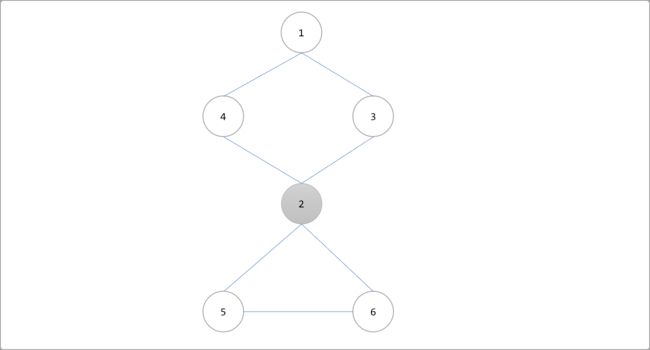
如果去掉一个节点以及与它连接的边,该点原来所在的图被分成两部分,则称该点为割点。如下图所示,删除 2号节点,剩下的节点之间就不能两两相互到达了。例如 4号不能到5号,6号也不能到达1号等等。一个连通分量变成两个连通分量!
怎么判断图是否存在割点以及如何找出图的割点?
Tarjan 算法是图论中非常实用且常用的算法之一,能解决强连通分量、双连通分量、割点和割边(桥)、求最近公共祖先(LCA)等问题。
Tarjan算法求解割点的核心理念:
- 在深度优先遍历算法访问到
k点时,此时图会被k点分割成已经被访问过的点和没有被访问过的点。 - 如果
k点是割点,则没有被访问过的点中至少会有一个点在不经过k点的情况下,是无论如何再也回不到已访问过的点了。则可证明k点是割点。
下图是深度优先遍历访问到2号顶点的时候。没有被访问到的顶点有4、5、6号顶点。
Tips: 节点边上的数字表示时间戳。
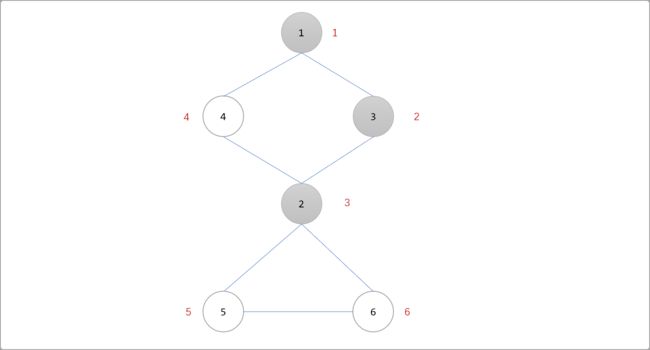
其中5和6号顶点都不可能在不经过2号顶点的情况下,再次回到已被访问过的顶点(1和3号顶点),因此2号顶点是割点。
问题变成如何在深度搜索到 k点时判断,没有被访问过的点是否能通过此k或者不能通过此k点回到曾经访问过的点。
算法中引入了回溯值概念。
回溯值表示从当前节点能回访到时间戳最小的祖先,回溯值一般使用名为 low的数组存储,low[i]表示节点 i的回溯值。
如下演示如何初始化以及更新节点的 low值。
-
定义
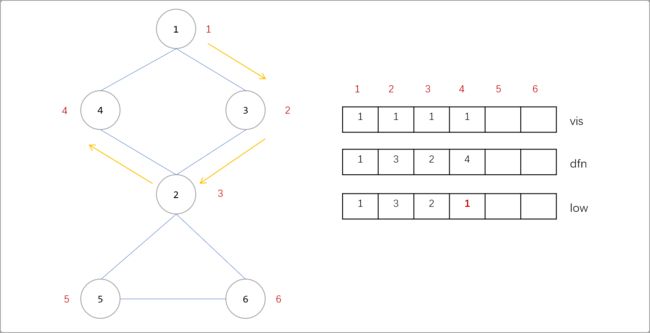
3个数组。vis[i]记录节点是否访问过、dfn[i]记录节点的时间戳、low[i]记录节点的回溯值。如下图所示,从1号节点开始深搜,搜索到4号节点时,3个数组中的值的变化如下。也就是说,初始,节点的low值和dfn值相同。或者说此时,回溯值还不能确定。Tips:注意一个细节,由
1->3,认为1是3的父节点。
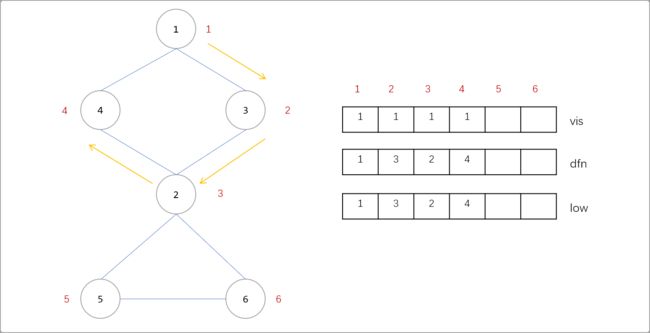
- 搜索到
4号时,与4号相连的边有4->1,4->1是没有访问过的边,且1号节点已经标记过访问过,也就是说通过4号点又回到了1号点。所以说4->1是一条回边,或者说1-……-4之间存在一个环。则4号点的low[4]=min( low[4],dfn[1] )=1
- 因为
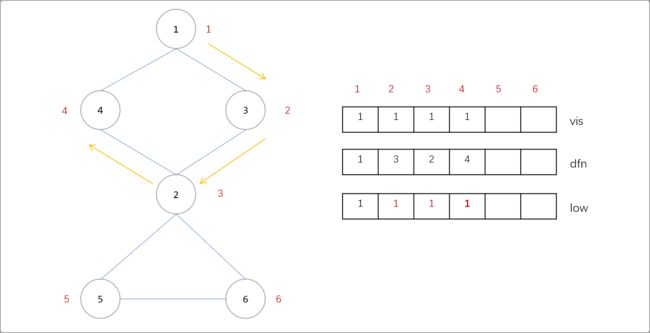
2是4的父节点,显然也是能通过4号点回到1号点,所以也需要更新其low值,更新表达式为low[2]=min(low[2],low[4])。同理3号点是2号点的父节点,也能通过3->2->4->1回到1号点。所以3号点的low也需要更新。low[3]=min(low[2],low[3])。
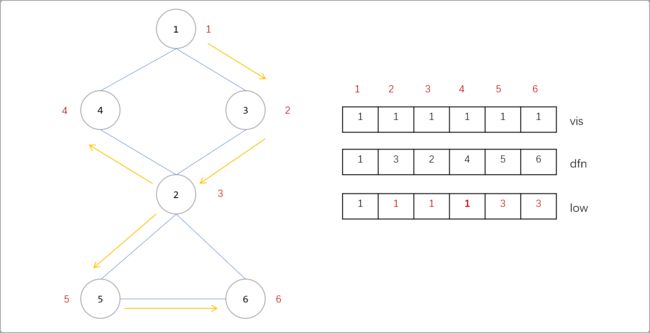
- 继续更新
5、6号节点的low值。
根据这些信息,如何判断割点。
- 如果当前点为根节点时,若子树数量大于一,则说明该点为割点(子树数量不等于与该点连接的边数)。
- 如果当前点不为根节点,若存在一个儿子节点的
low值大于或等于该点的dfn值时(low[子节点] >= dfn[父节点]),该点为割点(即子节点,无法通过回边,到达某一部分节点(这些节点的dfn值小于父亲节点))。这个道理是很好理解的,说明子节点想重回树的根节点是无法绕开父节点。
3.2 割边
定义:即在一个无向连通图中,如果删除某条边后,图不再连通。如下图删除2-5和5-6后,图不再具有连通性。
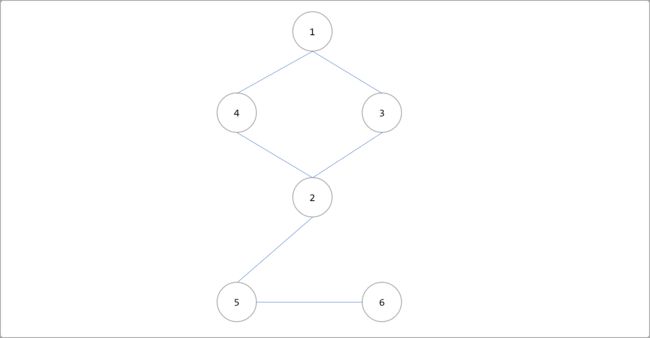
删除2-5和5-6边后。
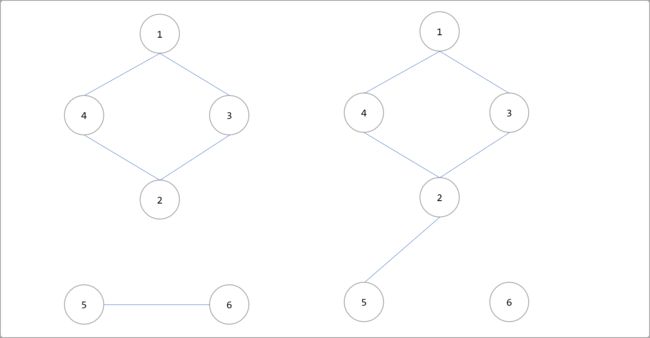
那么如何求割边呢?
只需要将求割点的算法修改一个符号就可以。只需将low[v]>=num[u]改为low[v]>num[u],取消一个等于号即可。因为low[v>=num[u]代表的是点v 是不可能在不经过父亲结点u而回到祖先(包括父亲)的,所以顶点u是割点。
如果low[y]和num[x]相等则表示还可以回到父亲,而low[v]>num[u]则表示连父亲都回不到了。倘若顶点v不能回到祖先,也没有另外一条路能回到父亲,那么 w-v这条边就是割边,
3.3 Tarjan 算法
#include
#include
#include
#include
#include
#include
using namespace std;
const int maxn = 123456;
int n, m, dfn[maxn], low[maxn], vis[maxn], ans, tim;
bool cut[maxn];
vector edge[maxn];
void cut_bri(int cur, int pop) {
vis[cur] = 1;// 1表示正在访问中
dfn[cur] = low[cur] = ++tim;
int children = 0; //子树数量
for (int i : edge[cur]) { //对于每一条边
if (i == pop || vis[cur] == 2)
continue;
if (vis[i] == 1) //遇到回边
low[cur] = min(low[cur], dfn[i]); //回边处的更新 (有环)
if (vis[i] == 0) {
cut_bri(i, cur);
children++; //记录子树数目
low[cur] = min(low[cur], low[i]); //父子节点处的回溯更新
if ((pop == -1 && children > 1) || (pop != -1 && low[i] >= dfn[cur])) { //判断割点
if (!cut[cur])
ans++; //记录割点个数
cut[cur] = true; //处理割点
}
if(low[i]>dfn[cur]) { //判断割边
edge[cur][i]=edge[i][cur]=true; //low[i]>dfn[cur]即说明(i,cur)是桥(割边);
}
}
}
vis[cur] = 2; //标记已访问
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++) {
int x, y;
scanf("%d%d", &x, &y);
edge[x].push_back(y);
edge[y].push_back(x);
}
for (int i = 1; i <= n; i++) {
if (vis[i] == 0)
cut_bri(i, -1); //防止原来的图并不是一个连通块
//对于每个连通块调用一次cut_bri
}
printf("%d\n", ans);
for (int i = 1; i <= n; i++) //输出割点
if (cut[i])
printf("%d ", i);
return 0;
}
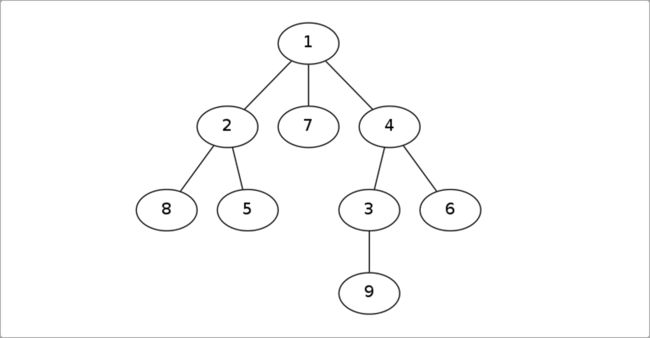
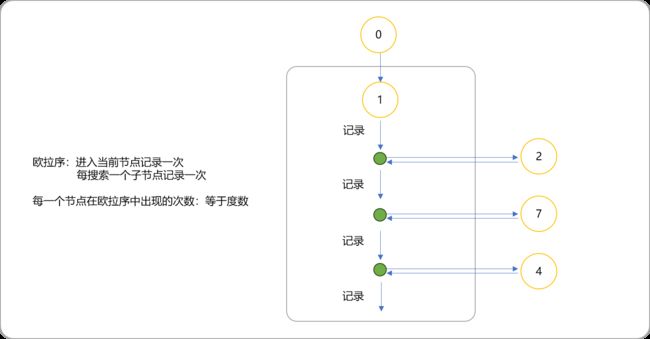
4.欧拉序
定义:进入节点时记录,每次遍历完一个子节点时,返回到此节点记录,得到的 2 ∗ N − 1 长的序列;
欧拉序和DFS序的区别,前者在每一个子节点访问后都要记录自己,后者只需要访问完所有子节点后再记录一次。如下图的欧拉序就是:
1 2 8 2 5 2 1 7 1 4 3 9 3 4 6 4 1。每个点在欧拉序中出现的次数等于这个点的度数,因为DFS到的时候加进一次,回去的时候也加进。
性质:
-
节点
x第一次出现与最后一次出现的位置之间的节点均为x的子节点; -
任意两个节点的
LCA是欧拉序中两节点第一次出现位置中深度最小的节点。两个节点第一次出现的位置之间一定有它们的LCA,并且,这个LCA一定是这个区间中深度最小的点。
根据欧拉序的性质,可以用来求解CLA。如上图,求解 LCA(9,6)。
- 在欧拉序中找到
9和6第一次出现的位置。
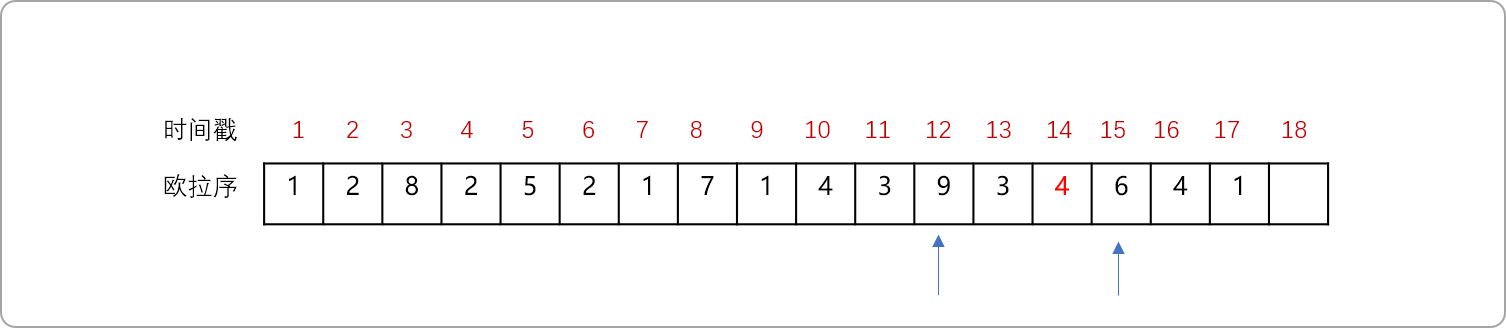
- 直观比较,知道
4号节点是其LCA,特征是9和6之间深度最小的节点。
欧拉序求LCA,先求图的欧拉序、时间戳(可以记录进入和离开节点的时间)以及节点深度。有了这些信息,理论上足以求出任意两点的LCA。变成了典型的RMQ问题。
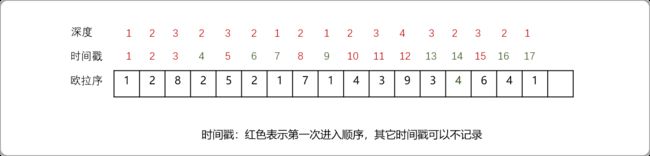
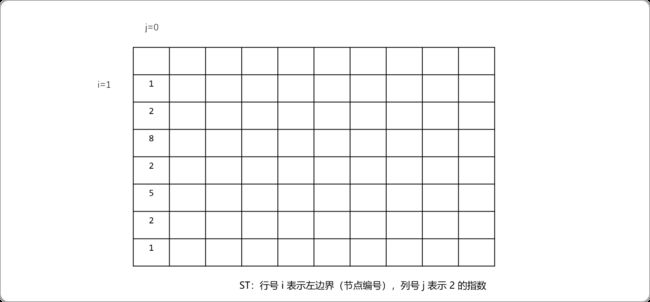
为了提升多次查询性能,可以使用ST表根据节点的深度缓存节点的信息。j=0时如下图所示。
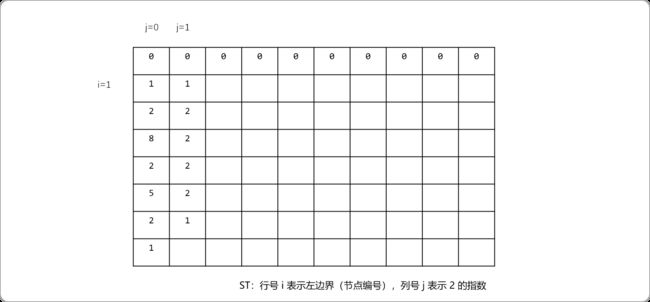
j=1表示区间长度为 2,值为区间长度为 1的两个子区间的深度值小的节点。
欧拉序求LCA
#include
#include
#include
#include
#include
#include
using namespace std;
const int maxn = 10000;
int n, m, dfn[maxn], dep[maxn], tim;
int ol[maxn];
int st[maxn][maxn],lg2[maxn];
vector edge[maxn];
void dfs(int cur, int fa) {
ol[++tim]=cur;
dfn[cur]=tim;
dep[cur]=dep[fa]+1;
for (int v : edge[cur]) { //对于每一条边
if(v==fa)continue;
dfs(v,cur);
ol[++tim]=cur;
}
}
void stPreprocess() {
lg2[0] = -1; // 预处理 lg 代替库函数 log2 来优化常数
for (int i = 1; i <= (n << 1); ++i) {
lg2[i] = lg2[i >> 1] + 1;
}
for (int i = 1; i <= (n << 1) - 1; ++i) {
st[i][0] = ol[i];
}
for (int j = 1; j <= lg2[(n << 1) - 1]; ++j) {
for (int i = 1; i + (1 << j) - 1 <= ((n << 1) - 1); ++i) {
st[i][j] = dep[ st[i] [ j - 1 ] ] < dep[ st[ i + (1 << j - 1)][j - 1 ] ] ? st[i][j - 1 ] : st[ i + (1 << j - 1)][j - 1 ];
}
cout<dfn[v])swap(u,v);
u=dfn[u],v=dfn[v];
int d=lg2[v-u+1];
int f1=st[ u ][d ];
int f2=st[v-(1<>u>>v;
int res=getlca(u,v);
cout<< res;
return 0;
}
5. 总结
DFS序和欧拉序并不难理解,正如四两拨千斤,却能解决很多复杂的问题。