java中 自动装箱与拆箱,基本数据类型,java堆与栈,面向对象与面向过程
文章目录
-
- 自动装箱与拆箱
- 基本数据类型与包装类的区别(int 和 Integer 有什么区别)
-
- 应用场景的区别:
- 堆和栈的区别
- 重点来说一下堆和栈:
-
- 那么堆和栈是怎么联系起来的呢?
- 堆与栈的区别 很明显:
-
- 延伸:关于Integer和int的比较
- Java 为每个原始类型提供了包装类型:
- Double和double的区别
- 面向对象和面向过程的区别
今天来简单了解一下java基础的内容
自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
基本数据类型与包装类的区别(int 和 Integer 有什么区别)
1、Integer是int的包装类,int则是java的一种基本数据类型
2、Integer变量必须实例化后才能使用,而int变量不需要
3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
4、Integer的默认值是null,int的默认值是0
应用场景的区别:
比如要体现出 考试成绩为0和缺考的区别的时候 用Integer可以 int不行
比如用容器的时候 ,ArrayList等职能放对象,不能放基本数据类型。
将基本数据类型封装成对象的好处是:
1)、在对象中可以定义更多的功能方法操作该数据。例如:基本数据类型和字符串直接的转换。
2)、编码过程中只接收对象的情况,例如List中只存入对象,不能存入基本数据类型。
3、使用场景
大部分的情况下,这两种类型没有太大得区别。根据以上两点的分析,基本类型的存取速度会更快,对象中有更多功能方法来操作数据,要根据实际需要定义属性。
借鉴网上学生成绩的例子,没来考试,成绩是0还是null,如果你觉得是0就用int,如果你认为是null,就用Integer。
堆和栈的区别
那数据存放在堆中和栈中有什么区别呢?
堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处:))。
为什么不把基本类型放堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。最常见的一个问题就是,Java中参数传递时的问题。
栈:
1)栈的存取速度比堆快,仅次于直接位于CPU的寄存器。
2)栈中的数据的大小和生存周期是确定的。
3)栈中的数据可以共享。
堆:
1)堆可以动态的分配内存大小,生存期也不必告诉编译器。
2)堆在运行时动态分配内存,存取速度慢。
综上所述,可以简单的理解为,为了高效,可以把一些数值小,简单的变量存放在栈中。堆和栈
堆(Heap)与栈(Stack)是开发人员必须面对的两个概念,在理解这两个概念时,需要放到具体的场景下,因为不同场景下,堆与栈代表不同的含义。一般情况下,有两层含义:
(1)程序内存布局场景下,堆与栈表示两种内存管理方式;
(2)数据结构场景下,堆与栈表示两种常用的数据结构。
在说堆和栈之前,我们先说一下JVM(虚拟机)内存的划分:
Java程序在运行时都要开辟空间,任何软件在运行时都要在内存中开辟空间,Java虚拟机运行时也是要开辟空间的。JVM运行时在内存中开辟一片内存区域,启动时在自己的内存区域中进行更细致的划分,因为虚拟机中每一片内存处理的方式都不同,所以要单独进行管理。
JVM内存的划分有五片:
1. 寄存器;
2. 本地方法区;
3. 方法区;
4. 栈内存;
5. 堆内存。
重点来说一下堆和栈:
栈内存:栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。
堆内存:存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾,Java有垃圾回收机制不定时的收取。
下面我们通过一个图例详细讲一下堆和栈:
比如主函数里的语句 int [] arr=new int [3];在内存中是怎么被定义的:
主函数先进栈,在栈中定义一个变量arr,接下来为arr赋值,但是右边不是一个具体值,是一个实体。实体创建在堆里,在堆里首先通过new关键字开辟一个空间,内存在存储数据的时候都是通过地址来体现的,地址是一块连续的二进制,然后给这个实体分配一个内存地址。数组都是有一个索引,数组这个实体在堆内存中产生之后每一个空间都会进行默认的初始化(这是堆内存的特点,未初始化的数据是不能用的,但在堆里是可以用的,因为初始化过了,但是在栈里没有),不同的类型初始化的值不一样。所以堆和栈里就创建了变量和实体:
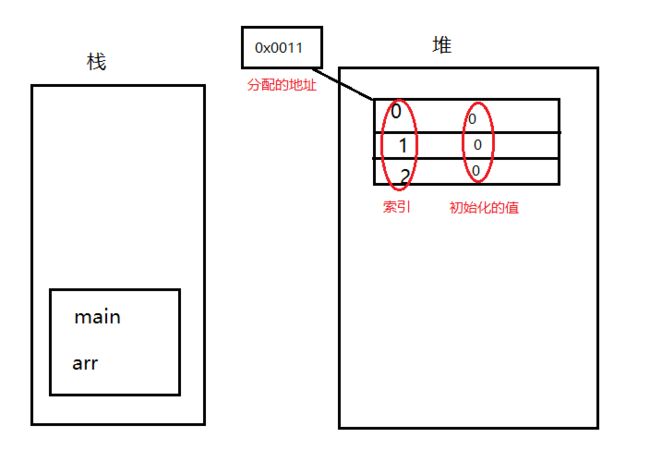
那么堆和栈是怎么联系起来的呢?
我们刚刚说过给堆分配了一个地址,把堆的地址赋给arr,arr就通过地址指向了数组。所以arr想操纵数组时,就通过地址,而不是直接把实体都赋给它。这种我们不再叫他基本数据类型,而叫引用数据类型。称为arr引用了堆内存当中的实体。(可以理解为c或c++的指针,Java成长自c++和c++很像,优化了c++)

如果当int [] arr=null;
arr不做任何指向,null的作用就是取消引用数据类型的指向。
当一个实体,没有引用数据类型指向的时候,它在堆内存中不会被释放,而被当做一个垃圾,在不定时的时间内自动回收,因为Java有一个自动回收机制,(而c++没有,需要程序员手动回收,如果不回收就越堆越多,直到撑满内存溢出,所以Java在内存管理上优于c++)。自动回收机制(程序)自动监测堆里是否有垃圾,如果有,就会自动的做垃圾回收的动作,但是什么时候收不一定。
堆与栈的区别 很明显:
1.栈内存存储的是局部变量而堆内存存储的是实体;
2.栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
3.栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
延伸:关于Integer和int的比较
1、由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
2、Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
3、非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
对于第4条的原因:
java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
Java 是一个近乎纯洁的面向对象编程语言,但是为了编程的方便还是引入了基本数据类型,但是为了能够将这些基本数据类型当成对象操作,Java 为每一个基本数据类型都引入了对应的包装类型(wrapper class),int 的包装类就是 Integer,从 Java 5 开始引入了自动装箱/拆箱机制,使得二者可以相互转换。
Java 为每个原始类型提供了包装类型:
原始类型: boolean,char,byte,short,int,long,float,double
包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
Integer a= 127 与 Integer b = 127相等吗
对于对象引用类型:==比较的是对象的内存地址。
对于基本数据类型:==比较的是值。
如果整型字面量的值在-128到127之间,那么自动装箱时不会new新的Integer对象,而是直接引用常量池中的Integer对象,超过范围 a1==b1的结果是false
Double和double的区别
1、Double是java定义的类,而double是预定义数据类型(8种中的一种)
2、Double就好比是对double类型的封装,内置很多方法可以实现String到double的转换,以及获取各种double类型的属性值(MAX_VALUE、SIZE等等)
基于上述两点,如果你在普通的定义一个浮点类型的数据,两者都可以,但是Double是类所以其对象是可以为NULL的,而double定义的不能为NULL,如果你要将一些数字字符串,那么就应该使用Double类型了,其内部帮你实现了强转。
面向对象和面向过程的区别
面向过程:
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展
面向对象:
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
缺点:性能比面向过程低