Spark on yarn——Spark提交任务到yarn集群源码分析
目录
一、入口类—— SparkSubmit
二、SparkApplication 启动—— JavaMainApplication、YarnClusterApplication
三、SparkContext 初始化
四、YarnClientSchedulerBackend 和 YarnClusterSchedulerBackend 初始化
五、ApplicationMaster 启动
六、Spark on Yarn 任务提交流程总结
一、入口类—— SparkSubmit
当使用下面的命令提交 spark 任务到 yarn 集群时:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 2g \
--executor-memory 5g \
--executor-cores 10 \
examples/target/scala-2.11/jars/spark-examples*.jar 10spark-submit 命令最终调用的java 类是SparkSubmit,它的main 方法代码如下:
object SparkSubmit extends CommandLineUtils with Logging {
override def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
val (childArgs, childClasspath, sparkConf, childMainClass) =
prepareSubmitEnvironment(args)
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
}main() 方法先实例化了 SparkSubmitArguments 对象来转换命令行参数,当判断其 action 为 SUBMIT 时,调用 sumbit() 方法提交任务。
prepareSubmitEnvironment()方法用于准备环境,它会根据提交命令行里的 --master 和 --deploy-mode参数来找到找到运行application的主类(返回结果里面的childMainClass):
- 当提交参数--master=yarn, --deploy-mode=client时,运行主类是其指定的 --class 参数的值,或者读取提交jar包的META-INFO信息,获取其运行主类,即我们编写的程序的入口类。
- 当提交参数--master=yarn, --deploy-mode=cluster时,运行主类是org.apache.spark.deploy.yarn.YarnClusterApplication
sumbit() 方法最后调用 runMain() 方法,其传入的参数 childMainClass 便由上面的方法得到, 代码如下:
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
mainClass = Utils.classForName(childMainClass)
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
app.start(childArgs.toArray, sparkConf)
}runMain() 方法会根据传入的mainClass类型来创建一个app对象,它判断如果该 mainClass 是 SparkApplication 的子类,则直接创建该对象,否则创建 JavaMainApplication 对象。然后调用app 对象的 start 方法。
二、SparkApplication 启动—— JavaMainApplication、YarnClusterApplication
通过上面代码分析得知:当 mainClass 的值为 YarnClusterApplication 时,会直接创建该对象并调用其 start 方法,YarnClusterApplication 类的 start 方法核心源码如下:
private[spark] class YarnClusterApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
// SparkSubmit would use yarn cache to distribute files & jars in yarn mode,
// so remove them from sparkConf here for yarn mode.
conf.remove("spark.jars")
conf.remove("spark.files")
new Client(new ClientArguments(args), conf).run()
}
}start() 方法会去new Client 对象,调用其 run() 方法向 yarn 集群提交任务。至于run() 方法的源码留在后面分析。
当 mainClass 是 --class 参数指定的值(即 deployMode 为 client)时,会创建一个JavaMainApplication 对象:
private[deploy] class JavaMainApplication(klass: Class[_]) extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
val sysProps = conf.getAll.toMap
sysProps.foreach { case (k, v) =>
sys.props(k) = v
}
mainMethod.invoke(null, args)
}
}该类的start 方法会去调用我们提交命令时指定的main class,然后调用其 main 方法。
经过上面的代码分析,我们得出结论:当deploy mode 是 cluster 时,会创建YarnClusterApplication 对象,该对象会去new Client 对象,调用其 run() 方法,直接向 yarn 集群提交任务。当deploy mode 是 client 时,会运行我们指定的main class 类。
那么 client 模式下任务是什么时候被提交到 yarn 的呢?答案是:在我们编写的程序代码中创建 SparkContext 对象时:
val sparkContext = new SparkContext(conf)接下来就分析下SparkContext 类初始化时会干些什么(由于cluster 模式下调用Client类的 run 方法提交任务,client 模式下最后也会调用该类的方法,所以Client 类的方法留在后面分析)。
此阶段,可以对spark代码运行过程做一个初步的总结:
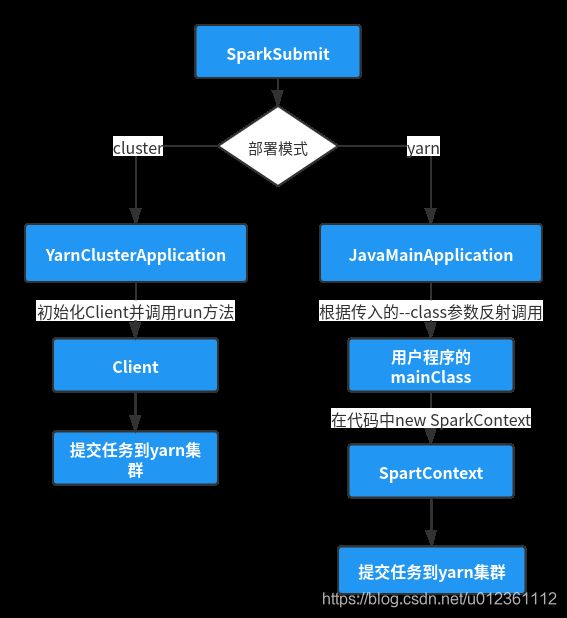
三、SparkContext 初始化
SparkContext 类初始化时,部分核心代码如下:
class SparkContext(config: SparkConf) extends Logging {
_conf = config.clone()
_conf.validateSettings()
logInfo(s"Submitted application: $appName")
_conf.set(DRIVER_HOST_ADDRESS, _conf.get(DRIVER_HOST_ADDRESS))
_conf.setIfMissing("spark.driver.port", "0")
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER)
_jars = Utils.getUserJars(_conf)
_files = _conf.getOption("spark.files").map(_.split(",")).map(_.filter(_.nonEmpty))
.toSeq.flatten
_eventLogDir =
if (isEventLogEnabled) {
val unresolvedDir = conf.get("spark.eventLog.dir", EventLoggingListener.DEFAULT_LOG_DIR)
.stripSuffix("/")
Some(Utils.resolveURI(unresolvedDir))
} else {
None
}
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
if (_conf.getBoolean("spark.ui.reverseProxy", false)) {
System.setProperty("spark.ui.proxyBase", "/proxy/" + _applicationId)
}
_ui.foreach(_.setAppId(_applicationId))
_env.blockManager.initialize(_applicationId)
}该方法会初始化一些关键信息:向_conf 对象中设置 DRIVER_HOST_ADDRESS 变量值,即 driver 进程所在的的主机和端口号(如果没有参数显示指定,会随机生成一个),设置属性 spark.executor.id 为固定值 "driver"。接着调用 createSparkEnv() 方法创建了SparkEnv 对象,该对象非常重要。该对象是 Driver 和 Executor 以及 Executor 和 Executor 之间通信的基石,底层基于netty 的 rpc 框架。
接着有段关键的代码:
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
该方法会去创建TaskScheduler 对象,方法的关键代码如下:
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
master match {
// local 运行模式
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
// spark standalone 运行模式
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
// 否则使用java spi 机制去寻找 clusterManager
case masterUrl =>
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
}
}createTaskScheduler() 方法根据其master 参数来创建 TaskSheduler 和 SchedulerBackend 实例对象,当master 是 yarn 时,不能和 local 以及 spark standalone 模式匹配上,只能进入最下面的匹配模式。它先调用getClusterManager 方法寻找 ExternalClusterManager 类的实现子类,代码如下:
private def getClusterManager(url: String): Option[ExternalClusterManager] = {
val loader = Utils.getContextOrSparkClassLoader
val serviceLoaders =
ServiceLoader.load(classOf[ExternalClusterManager], loader).asScala.filter(_.canCreate(url))
if (serviceLoaders.size > 1) {
throw new SparkException(
s"Multiple external cluster managers registered for the url $url: $serviceLoaders")
}
serviceLoaders.headOption
}getClusterManager() 方法使用了java工具包中的 ServiceLoader 类去加载ExternalClusterManager的实现类,文件定义在spark-yarn_xxx.jar包中的 MEIA-INF/services 目录下,在该文件中指定了实现类为 org.apache.spark.scheduler.cluster.YarnClusterManager 类(该类在spark 源码包中的 resource-managers/yarn 目录下)。
在YarnClusterManager 对象创建完成后,回到上面的 SparkContext.createTaskScheduler 方法中,它会调用其cm.createTaskScheduler 和 cm.createTaskSchedulerBackend 方法。
在进一步查看源码之前,应该先了解下TaskSchduler 和 SchedulerBackend的关系。在spark 的各组件(Driver、Executor、ApplicationMaster)的网络通信中,如果是大量的数据传输(数据shuffle),则使用netty的 http 服务,如果是小规模的数据通信(组件之间传递命令或者信息),则使用 netty 的 rpc 框架。
TaskScudeler 负责任务调度,它要将rdd 任务发送给 Executor 执行时,并不是它直接和Executor 通信,而是转交给SchedulerBackend 来处理。
ok,继续往下看, YarnClusterManager 类的核心代码如下:
private[spark] class YarnClusterManager extends ExternalClusterManager {
override def canCreate(masterURL: String): Boolean = {
masterURL == "yarn"
}
override def createTaskScheduler(sc: SparkContext, masterURL: String): TaskScheduler = {
sc.deployMode match {
case "cluster" => new YarnClusterScheduler(sc)
case "client" => new YarnScheduler(sc)
case _ => throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn")
}
}
override def createSchedulerBackend(sc: SparkContext,
masterURL: String,
scheduler: TaskScheduler): SchedulerBackend = {
sc.deployMode match {
case "cluster" =>
new YarnClusterSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc)
case "client" =>
new YarnClientSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc)
case _ =>
throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn")
}
}
override def initialize(scheduler: TaskScheduler, backend: SchedulerBackend): Unit = {
scheduler.asInstanceOf[TaskSchedulerImpl].initialize(backend)
}
}
createTaskScheduler 方法会根据 deployMode 创建 不同的 TaskScheduler 实现类,它们的类继承关系如下图所示:

YarnScheduler 类 和 YarnClusterScheduler 类并没有什么额外的核心功能,所有功能全部在 TaskSchedulerImpl 类里面实现,所以这里不做分析。
而createTaskSchedulerBackend 方法会根据 deployMode 创建不同的 SchedulerBackend 实现类,类关系如下图所示:
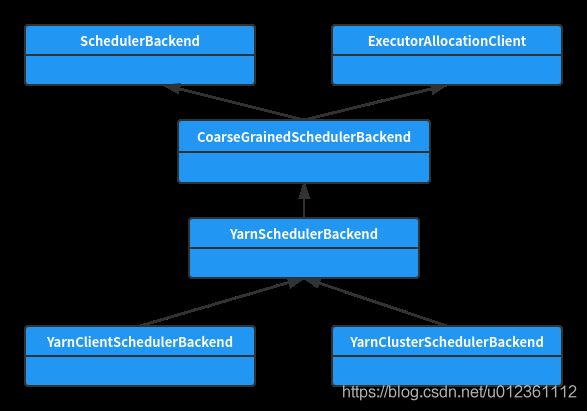
四、YarnClientSchedulerBackend 和 YarnClusterSchedulerBackend 初始化
分析完SparkContext.createTaskScheduler() 方法后,再回到SparkContext 初始化流程代码:
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
_taskScheduler.start()该方法创建了DAGScheduler 对象,该对象用于生成任务DAG图。接着调用了taskScheduler.start() 方法。根据上面代码分析得知,TaskScheduler 的实现子类为 YarnScheduler 和 YarnClusterScheduler 类,这两个类都没有重新父类的start 方法,start 方法具体实现在TaskShedulerImpl 类中:
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging {
var backend: SchedulerBackend = null
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleWithFixedDelay(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
}其backend 变量在 TaskSchedulerImpl.initialize(backend: SchedulerBackend) 方法中被赋值,而通过上面分析得知SchedulerBackend 的具体实现类为 YarnClientSchedulerBackend 和 YarnClusterSchedulerBackend 类。调用其start 方法则是调用这两个类的start 方法,接下来就来分析下这两个类的start 方法。
YarnClientSchedulerBackend 类的start() 方法代码如下:
private[spark] class YarnClientSchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext)
extends YarnSchedulerBackend(scheduler, sc)
with Logging {
private var client: Client = null
private var monitorThread: MonitorThread = null
/**
* Create a Yarn client to submit an application to the ResourceManager.
* This waits until the application is running.
*/
override def start() {
val driverHost = conf.get("spark.driver.host")
val driverPort = conf.get("spark.driver.port")
val hostport = driverHost + ":" + driverPort
sc.ui.foreach { ui => conf.set("spark.driver.appUIAddress", ui.webUrl) }
val argsArrayBuf = new ArrayBuffer[String]()
argsArrayBuf += ("--arg", hostport)
logDebug("ClientArguments called with: " + argsArrayBuf.mkString(" "))
val args = new ClientArguments(argsArrayBuf.toArray)
totalExpectedExecutors = SchedulerBackendUtils.getInitialTargetExecutorNumber(conf)
// 初始化Client 对象
client = new Client(args, conf)
// 调用submitApplication() 方法向 yarn集群提交代码
bindToYarn(client.submitApplication(), None)
// SPARK-8687: Ensure all necessary properties have already been set before
// we initialize our driver scheduler backend, which serves these properties
// to the executors
super.start()
// 等待任务运行结束
waitForApplication()
if (conf.contains("spark.yarn.credentials.file")) {
YarnSparkHadoopUtil.startCredentialUpdater(conf)
}
monitorThread = asyncMonitorApplication()
monitorThread.start()
}
}YarnClientSchedulerBackend.start() 方法里面初始化了Client 对象,然后调用其submitApplication() 方法向集群提交任务。还记得我们前面提到的 YarnClusterApplication 类么,在该类的start 方法里面也初始化了Client 对象,然后调用了run() 方法,接下来就来分析下Client类的run 和 submitApplication 方法:
private[spark] class Client(val args: ClientArguments,
val sparkConf: SparkConf) extends Logging {
def run(): Unit = {
this.appId = submitApplication()
}
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
launcherBackend.connect()
// Setup the credentials before doing anything else,
// so we have don't have issues at any point.
setupCredentials()
// 初始化 YarnClient
yarnClient.init(hadoopConf)
// 启动 YarnClient
yarnClient.start()
logInfo("Requesting a new application from cluster with %d NodeManagers"
.format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))
// Get a new application from our RM
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
new CallerContext("CLIENT", sparkConf.get(APP_CALLER_CONTEXT),
Option(appId.toString)).setCurrentContext()
// Verify whether the cluster has enough resources for our AM
verifyClusterResources(newAppResponse)
// Set up the appropriate contexts to launch our AM
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
appId
} catch {
case e: Throwable =>
if (appId != null) {
cleanupStagingDir(appId)
}
throw e
}
}
}该方法先调用yarnClient 对象的 init 和 start 方法,接着调用yarnClient.createApplication 方法在yarn 集群上创建一个application,方法返回一个 YarnClientApplication 对象,该对象里面包含两个重要的东西:
- 1) applicationId
- 2)ApplicationSubmissionContext 对象
createrConainerLuanchContext() 方法核心代码如下:
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse)
: ContainerLaunchContext = {
logInfo("Setting up container launch context for our AM")
val appId = newAppResponse.getApplicationId
val launchEnv = setupLaunchEnv(appStagingDirPath, pySparkArchives)
val localResources = prepareLocalResources(appStagingDirPath, pySparkArchives)
val amContainer = Records.newRecord(classOf[ContainerLaunchContext])
amContainer.setLocalResources(localResources.asJava)
amContainer.setEnvironment(launchEnv.asJava)
val userClass =
if (isClusterMode) {
Seq("--class", YarnSparkHadoopUtil.escapeForShell(args.userClass))
} else {
Nil
}
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
val amArgs =
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
Seq("--properties-file", buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, SPARK_CONF_FILE))
// Command for the ApplicationMaster
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
// TODO: it would be nicer to just make sure there are no null commands here
val printableCommands = commands.map(s => if (s == null) "null" else s).toList
amContainer.setCommands(printableCommands.asJava)
amContainer
}createrConainerLuanchContext 方法用于创建抽象的 application master 容器描述,即告诉 yarn 怎么启动 am 进程。prepareLocalResources() 方法用于准备任务依赖的jar 包和资源,它会将SPARK_HOME/jars 目录下的的所有 jar 都上传到 hdfs 上,在 Executor 进程运行时再下载下来。
接着往下看,创建了几个关键参数:
- userClass:如果是cluster 部署模式,则为用户指定的 --class 参数值。如果是client模式,则为空,因为client 模式下,userClass 已经在最前面先启动了。
- amClass:即启动Application Master 进程的主类,如果是cluster 模式,则为 ApplicationMaster;如果是 client 模式,则为 ExecutorLuancher。这两个类有什么区别呢?在下文会分析到。
最后将参数拼接起来,得到一个 commands 对象,这个 commands 就是一个java 启动命令,内容大致如下:
java -server -jar xxx -Xms xxx ApplicationMaster --class xxxcreateApplicationSubmissionContext() 方法用于创建任务提交环境,包括指定appName,任务队列,appType等,其核心代码如下:
def createApplicationSubmissionContext(
newApp: YarnClientApplication,
containerContext: ContainerLaunchContext): ApplicationSubmissionContext = {
val appContext = newApp.getApplicationSubmissionContext
appContext.setApplicationName(sparkConf.get("spark.app.name", "Spark"))
appContext.setQueue(sparkConf.get(QUEUE_NAME))
appContext.setAMContainerSpec(containerContext)
appContext.setApplicationType("SPARK")
sparkConf.get(APPLICATION_TAGS).foreach { tags =>
appContext.setApplicationTags(new java.util.HashSet[String](tags.asJava))
}
sparkConf.get(MAX_APP_ATTEMPTS) match {
case Some(v) => appContext.setMaxAppAttempts(v)
case None => logDebug(s"${MAX_APP_ATTEMPTS.key} is not set. " +
"Cluster's default value will be used.")
}
sparkConf.get(AM_ATTEMPT_FAILURE_VALIDITY_INTERVAL_MS).foreach { interval =>
appContext.setAttemptFailuresValidityInterval(interval)
}
val capability = Records.newRecord(classOf[Resource])
capability.setMemory(amMemory + amMemoryOverhead)
capability.setVirtualCores(amCores)
sparkConf.get(AM_NODE_LABEL_EXPRESSION) match {
case Some(expr) =>
val amRequest = Records.newRecord(classOf[ResourceRequest])
amRequest.setResourceName(ResourceRequest.ANY)
amRequest.setPriority(Priority.newInstance(0))
amRequest.setCapability(capability)
amRequest.setNumContainers(1)
amRequest.setNodeLabelExpression(expr)
appContext.setAMContainerResourceRequest(amRequest)
case None =>
appContext.setResource(capability)
}
appContext
}在appContext 对象创建完毕后,使用了下面的代码提交application:
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)至此、yarn任务提交功能已经完成。再回头来看一下 YarnClusterSchedulerBackend 类的 start 方法:
private[spark] class YarnClusterSchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext)
extends YarnSchedulerBackend(scheduler, sc) {
override def start() {
val attemptId = ApplicationMaster.getAttemptId
bindToYarn(attemptId.getApplicationId(), Some(attemptId))
super.start()
totalExpectedExecutors = SchedulerBackendUtils.getInitialTargetExecutorNumber(sc.conf)
}
}该方法,没有什么特别的工作,因为 cluster 模式下,已经最先调用 Client.run() 方法完成任务提交了。
五、ApplicationMaster 启动
通过前面分析代码分析,我们知道当部署模式是cluster时,启动的类是ApplicationMaster类,当模式是client时,启动的是ExecutorLauncher类,在看代码前,需要注意先了解的是,ApplicationMaster 是在 master 进程(yarn 分配给应用程序的一个容器,专门用来运行 application master)中运行的。启动指定的ApplicationMaster 类和 ExecutorLauncher 类都是 object 类型的,位于ApplicationMaster.scala 文件中,该文件里面还有一个 ApplicationMaster,是class 类型的,结构如下面所示:
private[spark] class ApplicationMaster(args: ApplicationMasterArguments) extends Logging {
}
object ApplicationMaster extends Logging {
}
object ExecutorLauncher {
}
ApplicationMaster 和 ExecutorLauncher object 的 main() 方法代码如下:
object ApplicationMaster extends Logging {
private var master: ApplicationMaster = _
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
val amArgs = new ApplicationMasterArguments(args)
master = new ApplicationMaster(amArgs)
System.exit(master.run())
}
}
/**
* This object does not provide any special functionality. It exists so that it's easy to tell
* apart the client-mode AM from the cluster-mode AM when using tools such as ps or jps.
*/
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}ExecutorLauncher.main() 方法实际去调用了 ApplicationMaster.main() 方法,而该方法又去 new ApplicationMaster(amArgs),然后调用 run() 方法。那么问题来了?这个 ExecutorLauncher 存在的意义是什么呢?答案是它只是起个标记作用,方便我们在使用 ps 或者 jps 命令时,通过启动主类的不同来区分部署模式。
接下来再来看 ApplicationMaster 类的 run() 方法:
private[spark] class ApplicationMaster(args: ApplicationMasterArguments) extends Logging {
private val isClusterMode = args.userClass != null
private val sparkConf = new SparkConf()
if (args.propertiesFile != null) {
Utils.getPropertiesFromFile(args.propertiesFile).foreach { case (k, v) =>
sparkConf.set(k, v)
}
}
private val client = doAsUser { new YarnRMClient()
final def run(): Int = {
doAsUser {
runImpl()
}
exitCode
}
private def runImpl(): Unit = {
try {
val appAttemptId = client.getAttemptId()
var attemptID: Option[String] = None
if (isClusterMode) {
runDriver()
} else {
runExecutorLauncher()
}
} catch {
case e: Exception =>
// catch everything else if not specifically handled
logError("Uncaught exception: ", e)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_UNCAUGHT_EXCEPTION,
"Uncaught exception: " + e)
}
}
}run() 方法去调用了 runImpl() 方法,runImpl() 会根据 isClusterMode 变量的值来调用不同的方法,该值的判断依据为:
private val isClusterMode = args.userClass != null如果是client模式,则会调用 runExecutorLauncher 方法,如果是 cluster 模式,则会调用 runDriver 方法。先来分析下cluster 模式下的 runDriver 方法,代码如下:
private def runDriver(): Unit = {
addAmIpFilter(None)
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
logInfo("Waiting for spark context initialization...")
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
rpcEnv = sc.env.rpcEnv
val driverRef = createSchedulerRef(
sc.getConf.get("spark.driver.host"),
sc.getConf.get("spark.driver.port"))
registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.webUrl))
registered = true
} else {
// Sanity check; should never happen in normal operation, since sc should only be null
// if the user app did not create a SparkContext.
throw new IllegalStateException("User did not initialize spark context!")
}
resumeDriver()
userClassThread.join()
} catch {
case e: SparkException if e.getCause().isInstanceOf[TimeoutException] =>
logError(
s"SparkContext did not initialize after waiting for $totalWaitTime ms. " +
"Please check earlier log output for errors. Failing the application.")
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} finally {
resumeDriver()
}
}它会先去调用 startUserApplication() 方法启动用户程序,返回一个 userClassThread。费尽千辛万苦,总算找到了启动用户程序 mainClass 的入口,代码如下:
private def startUserApplication(): Thread = {
logInfo("Starting the user application in a separate Thread")
var userArgs = args.userArgs
if (args.primaryPyFile != null && args.primaryPyFile.endsWith(".py")) {
// When running pyspark, the app is run using PythonRunner. The second argument is the list
// of files to add to PYTHONPATH, which Client.scala already handles, so it's empty.
userArgs = Seq(args.primaryPyFile, "") ++ userArgs
}
if (args.primaryRFile != null && args.primaryRFile.endsWith(".R")) {
// TODO(davies): add R dependencies here
}
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
val userThread = new Thread {
override def run() {
try {
mainMethod.invoke(null, userArgs.toArray)
finish(FinalApplicationStatus.SUCCEEDED, ApplicationMaster.EXIT_SUCCESS)
logDebug("Done running users class")
} catch {
case e: InvocationTargetException =>
e.getCause match {
case _: InterruptedException =>
// Reporter thread can interrupt to stop user class
case SparkUserAppException(exitCode) =>
val msg = s"User application exited with status $exitCode"
logError(msg)
finish(FinalApplicationStatus.FAILED, exitCode, msg)
case cause: Throwable =>
logError("User class threw exception: " + cause, cause)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_EXCEPTION_USER_CLASS,
"User class threw exception: " + StringUtils.stringifyException(cause))
}
sparkContextPromise.tryFailure(e.getCause())
} finally {
// Notify the thread waiting for the SparkContext, in case the application did not
// instantiate one. This will do nothing when the user code instantiates a SparkContext
// (with the correct master), or when the user code throws an exception (due to the
// tryFailure above).
sparkContextPromise.trySuccess(null)
}
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}该方法先创建了一个单独的线程,在该线程里面使用 classloader 去加载到用户指定的mainClass,然后反射调用其main()方法。
再回到 runDriver() 方法中, 该方法接下来调用了 registerAM() 方法告诉yarn 集群现在applicationmaster 进程已启动,该方法在下面分析。
回到ApplicationMaster.runImpl() 方法,它判断如果是 client 模式,则会调用runExecutorLauncher()方法,代码如下:
private def runExecutorLauncher(): Unit = {
val hostname = Utils.localHostName
val amCores = sparkConf.get(AM_CORES)
rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr,
amCores, true)
val driverRef = waitForSparkDriver()
addAmIpFilter(Some(driverRef))
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress"))
registered = true
// In client mode the actor will stop the reporter thread.
reporterThread.join()
}runExecutorLauncher() 方法代码就简单很多,它先调用 RpcEnv.create 方法创建了 rpcEnv 变量,然后调用了 waitForSparkDriver() 方法和 Driver 进程通信。接着它会去调用 registerAM()方法向 yarn 集群注册 master,该方法代码如下:
private def registerAM(
_sparkConf: SparkConf,
_rpcEnv: RpcEnv,
driverRef: RpcEndpointRef,
uiAddress: Option[String]) = {
allocator = client.register(driverUrl,
driverRef,
yarnConf,
_sparkConf,
uiAddress,
historyAddress,
securityMgr,
localResources)
// Initialize the AM endpoint *after* the allocator has been initialized. This ensures
// that when the driver sends an initial executor request (e.g. after an AM restart),
// the allocator is ready to service requests.
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
allocator.allocateResources()
reporterThread = launchReporterThread()
}方法调用 client.regsiter() (这个client 对象是 YarnRMClient 类的实例)方法,代码如下:
private[spark] class YarnRMClient extends Logging {
def register(
driverUrl: String,
driverRef: RpcEndpointRef,
conf: YarnConfiguration,
sparkConf: SparkConf,
uiAddress: Option[String],
uiHistoryAddress: String,
securityMgr: SecurityManager,
localResources: Map[String, LocalResource]
): YarnAllocator = {
amClient = AMRMClient.createAMRMClient()
amClient.init(conf)
amClient.start()
this.uiHistoryAddress = uiHistoryAddress
val trackingUrl = uiAddress.getOrElse {
if (sparkConf.get(ALLOW_HISTORY_SERVER_TRACKING_URL)) uiHistoryAddress else ""
}
logInfo("Registering the ApplicationMaster")
synchronized {
amClient.registerApplicationMaster(Utils.localHostName(), 0, trackingUrl)
registered = true
}
new YarnAllocator(driverUrl, driverRef, conf, sparkConf, amClient, getAttemptId(), securityMgr,
localResources, new SparkRackResolver())
}
}
该方法里面调用了yarn本身 AMRMClient 类的方法注册 applicationMaster,然后返回一个YarnAllocator对象。
在返回YarnAllocator对象后,先调用一次allocateResources()方法向yarn申请资源,allocateResources() 方法代码如下:
def allocateResources(): Unit = synchronized {
updateResourceRequests()
val progressIndicator = 0.1f
// Poll the ResourceManager. This doubles as a heartbeat if there are no pending container
// requests.
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
if (allocatedContainers.size > 0) {
logDebug(("Allocated containers: %d. Current executor count: %d. " +
"Launching executor count: %d. Cluster resources: %s.")
.format(
allocatedContainers.size,
runningExecutors.size,
numExecutorsStarting.get,
allocateResponse.getAvailableResources))
handleAllocatedContainers(allocatedContainers.asScala)
}
val completedContainers = allocateResponse.getCompletedContainersStatuses()
if (completedContainers.size > 0) {
logDebug("Completed %d containers".format(completedContainers.size))
processCompletedContainers(completedContainers.asScala)
logDebug("Finished processing %d completed containers. Current running executor count: %d."
.format(completedContainers.size, runningExecutors.size))
}
}allocateResources() 方法调用 AMRMClient 类的 allocate 方法向 yarn 集群申请资源(申请资源的数量由提交任务时其指定的参数 --executor-memory,--executor-cores 等参数决定)。该方法返回allocateResonse 对象,该对象里面会包含两种类型的 container,一种是新分配的 container,一种是已经完成任务的 container。但是yarn 可能不能一次性返回全部所需数量的 container,所以在registerAM() 方法最后的代码 reporterThread = launchReporterThread() 便是通过循环调用allocateResources 方法来解决这个问题的,代码如下:
private def launchReporterThread(): Thread = {
// The number of failures in a row until Reporter thread give up
val reporterMaxFailures = sparkConf.get(MAX_REPORTER_THREAD_FAILURES)
val t = new Thread {
override def run() {
var failureCount = 0
while (!finished) {
try {
if (allocator.getNumExecutorsFailed >= maxNumExecutorFailures) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_MAX_EXECUTOR_FAILURES,
s"Max number of executor failures ($maxNumExecutorFailures) reached")
} else {
logDebug("Sending progress")
allocator.allocateResources()
}
failureCount = 0
} catch {
case i: InterruptedException => // do nothing
case e: ApplicationAttemptNotFoundException =>
failureCount += 1
logError("Exception from Reporter thread.", e)
finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_REPORTER_FAILURE,
e.getMessage)
case e: Throwable =>
failureCount += 1
if (!NonFatal(e) || failureCount >= reporterMaxFailures) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_REPORTER_FAILURE, "Exception was thrown " +
s"$failureCount time(s) from Reporter thread.")
} else {
logWarning(s"Reporter thread fails $failureCount time(s) in a row.", e)
}
}
try {
val numPendingAllocate = allocator.getPendingAllocate.size
var sleepStart = 0L
var sleepInterval = 200L // ms
allocatorLock.synchronized {
sleepInterval =
if (numPendingAllocate > 0 || allocator.getNumPendingLossReasonRequests > 0) {
val currentAllocationInterval =
math.min(heartbeatInterval, nextAllocationInterval)
nextAllocationInterval = currentAllocationInterval * 2 // avoid overflow
currentAllocationInterval
} else {
nextAllocationInterval = initialAllocationInterval
heartbeatInterval
}
sleepStart = System.currentTimeMillis()
allocatorLock.wait(sleepInterval)
}
val sleepDuration = System.currentTimeMillis() - sleepStart
if (sleepDuration < sleepInterval) {
// log when sleep is interrupted
logDebug(s"Number of pending allocations is $numPendingAllocate. " +
s"Slept for $sleepDuration/$sleepInterval ms.")
// if sleep was less than the minimum interval, sleep for the rest of it
val toSleep = math.max(0, initialAllocationInterval - sleepDuration)
if (toSleep > 0) {
logDebug(s"Going back to sleep for $toSleep ms")
// use Thread.sleep instead of allocatorLock.wait. there is no need to be woken up
// by the methods that signal allocatorLock because this is just finishing the min
// sleep interval, which should happen even if this is signalled again.
Thread.sleep(toSleep)
}
} else {
logDebug(s"Number of pending allocations is $numPendingAllocate. " +
s"Slept for $sleepDuration/$sleepInterval.")
}
} catch {
case e: InterruptedException =>
}
}
}
}
// setting to daemon status, though this is usually not a good idea.
t.setDaemon(true)
t.setName("Reporter")
t.start()
logInfo(s"Started progress reporter thread with (heartbeat : $heartbeatInterval, " +
s"initial allocation : $initialAllocationInterval) intervals")
t
}六、Spark on Yarn 任务提交流程总结
1. 程序入口类是 SparkSubmit,它会根据提交参数 --deploy-mode 来运行不同的主类。
2. 如果是 client 模式,则创建 JavaMainApplication 对象并调用 start 方法,start 方法通过反射调用运行 --class 参数指定的 mainClass。如果是 cluster 模式,则创建 YarnClusterApplication 对象,在 start 方法创建 Client 对象,并调用其 run 方法,该方法去调用 submitApplication 方法完成任务提交。
3. client 模式下,运行用户 mainClass,初始化 SparkContext 对象,在对象初始化过程中,会创建 TaskSchduler 的实例子类 TaskSchedulerImpl,SchedulerBackend 的实例子类 YarnClientSchedulerBackend 和 YarnClusterSchedulerBackend 类,然后调用这两个类的 start 方法。
4. YarnClientSchedulerBackend 的 start 方法会初始化 Client 对象,并调用其 sumbitApplication() 方法。
5. Client 类的 submitAppliation 方法先初始化 YarnClient 对象,然后调用其 api 完成任务提交。其中 client 模式指定 master 进程运行的主类为 ExecutorLauncher,cluster 模式的主类为 ApplicationMaster,ExecutorLauncher 只是一个标记类,实际上也是调用 ApplicationMaster 类的 run 方法。
6. ApplicationMaster 类在 master 进程中运行,它的 run 方法会判断是 client 还是 cluster 模式,如果是 client 模式,则调用 registerAm() 方法向yarn 注册自己的信息;如果是 cluster 模式,则会先启动一个单独的线程,运行用户程序 mainClass 代码,然后再调用 registerAm() 方法注册。