C++ main() 函数中定义数组闪退__问题分析&解决过程
这里写自定义目录标题
- 1. 最近发现了一个问题
-
- 1.1 原因
- 1.2 解决方式:
- 2. C语言程序的内存分配方式
-
- 2.1 内存分配方式
- 2.2 程序的内存空间
- 2.3 堆与栈的比较
-
- 2.3.1申请方式
- 2.3.2申请后系统的响应
- 2.3.3申请大小的限制
- 2.3.4申请效率的比较
- 2.3.5堆和栈中的存储内容
- 2.3.6存取效率的比较
- 2.3.7 小结
- 2.4 建议
- 2.5 new/delete与malloc/free比较
- 3. 那么vector的数据是存储在堆上面还是栈上面?
- 4. vector 数组相互转化
-
- 4.1 数组转vector
- 4.2 vector转数组
- 4.3 应用建议
- 5. 反思:
- 6. ref:
1. 最近发现了一个问题
在将本地txt中的数据读取到vector以后,需要将vector转换为array类型,当程序运行至main()中定义数组的部分,程序会以异常方式退出。经过研究发现这个是c/C++内存分配方式导致的。简化代码(省去从txt中读取vector的部分)如下:
#include 运行结果:
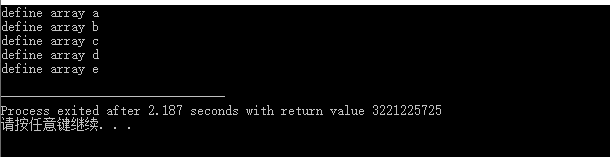
1.1 原因
在C或者C++中,在函数(包括main函数)中定义数组,对于任何程序员来说都是so easy的事,当然这通常是对于一些容量小的数据;当我们有大量的数据需要处理的时候,比如1GB大小的数据,按照常规的方式在函数中定义数组空间,往往会运行出错。如下为不同变量定义方式的区别:
-
直接定义一个数组,如a[SIZE];这个是分配的静态空间,在栈上(局部变量)或全局静态区(全局变量)上分配的,一般栈的内存是1M到2M,所以静态分配的空间不能太大,比如如果定义a[1024*1024];运行时就会报”段错误“,遇到要申请大的空间时,就需要动态申请;
-
函数内申请的变量,数组,是在栈(stack)中申请的一段连续的空间。栈的默认大小为2M或1M,开的比较小,内存为栈所分配的最大空间为4M,因此在子函数或者main函数中定义超大数组的方式是万万行不通的。
-
全局变量,全局数组,静态数组(static) 则是开在全局区(静态区)(static)。大小为2G,所以能够开的很大;
-
malloc、new出的空间,则是开在堆(heap)的一段不连续的空间。理论上则是硬盘大小;
1.2 解决方式:
-
为超大数组创建为一个全局数组。
-
有时候觉得数组使用起来不方便,可以采用定义vector的方式,但需要注意的是,vector通常只能分配出几百MB的空间。
vector <char> vec0; vector <string> vec1; vector <int> vec2; vector <double> vec3; cout<<vec0.max_size()<<endl; cout<<vec1.max_size()<<endl; cout<<vec2.max_size()<<endl; cout<<vec3.max_size()<<endl; //注意max_size()函数返回的是vector容器最大能存放的元素的个数,并不是字节数在程序运行完之后得到的数据如下(win10系统 64位 MinGW:x86_64-8.1.0-release-posix-sjlj-rt_v6-rev0):

-
由于vector在所需要的是一片连续的内存空间,有时候并不能实现,但是C++中 list 可以使用散列的空间,需要存放较大数据时可以使用 list 容器来存放数据。
2. C语言程序的内存分配方式
2.1 内存分配方式
内存分配方式有三种:
[1]从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
[2]在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
[3]从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释 放内存。动态内存的生存期由程序员决定,使用非常灵活,但如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,频繁地分配和释放不同大 小的堆空间将会产生堆内碎块。
2.2 程序的内存空间
一个程序将操作系统分配给其运行的内存块分为4个区域,如下图所示。
一个由C/C++编译的程序占用的内存分为以下几个部分,
1、栈区(stack)— 由编译器自动分配释放 ,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS(operating system)回收 。分配方式类似于链表。由程序员自己申请、自己释放,否则发生内存泄露。典型为使用new申请的堆内容
3、全局区(静态区)(static)—存放全局变量、静态数据、常量。程序结束后由系统释放。
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放。
5、程序代码区—存放函数体(类成员函数和全局函数)的二进制代码。
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b;// 栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //"123456/0"在常量区,p3在栈上。
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); //123456/0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
2.3 堆与栈的比较
2.3.1申请方式
stack: 由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间。
heap: 需要程序员自己申请,并指明大小,在C中malloc函数,C++中是new运算符。
如p1 = (char *)malloc(10); p1 = new char[10];
如p2 = (char *)malloc(10); p2 = new char[20];
但是注意p1、p2本身是在栈中的。
2.3.2申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。
由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的 ,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因 此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.3.4申请效率的比较
栈由系统自动分配,速度较快,但是容量有限。但程序员是无法控制的。
堆:一般速度比较慢,内存使用new进行分配,使用delete或delete[]释放。如果未能对内存进行正确的释放,会造成内存泄漏。但在程序结束时,会由操作系统自动回收。用起来最方便。
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是栈,而是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.3.5堆和栈中的存储内容
栈:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.3.6存取效率的比较
char s1[] = "a";
char *s2 = "b";
a是在运行时刻赋值的;而b是在编译时就确定的;但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。 比如:
int main(){
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return 0;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,再根据edx读取字符,显然慢了。
2.3.7 小结
堆和栈的主要区别由以下几点:
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
- 管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
- 空间大小:一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M。当然,这个值可以修改。
- 碎片问题:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问 题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详 细的可以参考数据结构。
- 生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
- 分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由malloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
- 分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效 率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统) 在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机 会分 到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
2.4 建议
从这里我们可以看到,堆和栈相比,由于大量new/delete的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用 户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址, EBP和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生以想不到的结果。
2.5 new/delete与malloc/free比较
从C++角度上说,使用new分配堆空间可以调用类的构造函数,而malloc()函数仅仅是一个函数调用,它不会调用构造函数,它所接受的参数是一个unsigned long类型。同样,delete在释放堆空间之前会调用析构函数,而free函数则不会。
3. 那么vector的数据是存储在堆上面还是栈上面?
vector本身并不一定占用动态内存,vector只是管理了一片动态内存。std::vector的默认实现是把内部数据分配在堆上,所以vector对象本身不需要再用new。vector对象本身不大。
- vector vs用栈上的vector管理一片动态内存。
- new vector用动态内存里的一个vector管理另一片动态内存。

4. vector 数组相互转化
4.1 数组转vector
float arrHeight[] = { 1.68,1.72,1.83,2.05,2.35,1.78,2.1,1.96 };
vector<float> vecHeight(arrHeight, arrHeight+sizeof(arrHeight)/sizeof(float));
4.2 vector转数组
由于vector内部的数据是存放在连续的存储空间,vector转数组事实上只需要获取vector中第一个数据的地址和数据的长度即可。如果仅仅是传参,无需任何操作,直接传地址即可,如果要进行数据复制,可以借用内存拷贝函数“memcpy”。例如:
直接传递地址
template <typename T>
T * vec_2_arr_new(vector<T> &vec_acc_ori){
return &vec_acc_ori[0];
}
int main(){
vector<int16_t> vec = read_vec_from_data("./data/data.txt")
int16_t * arr = vec_2_arr_new(vec)
}
数据复制
float *buffer = new float[sizeof(arrHeight)];
if (!vecHeight.empty())
{
memcpy(buffer, &vecHeight[0], vecHeight.size()*sizeof(float));
}
4.3 应用建议
1,vector作为动态数组,它的实现方法是:预先分配一个内存块,当感觉不够用的时候,再分配一个更大的内存块,然后自动将之前的数据拷贝到新的内存块中。
所以,出于效率考虑,如果实现知道待存储的数据长度,可以使用resize函数开辟足够的内存,避免后续的内存拷贝。
2,如果数组的元素是字符,建议使用string,而不是vector。
5. 反思:
这个问题反映了自己对于C/C++的内存管理很不熟悉,后面需要加强这方面的积累。
6. ref:
https://blog.csdn.net/ei1990/article/details/80175610
https://www.cnblogs.com/python-zkp/p/10747520.html
https://www.zhihu.com/question/36773826
https://blog.csdn.net/zfjBIT/article/details/88638547
https://blog.csdn.net/czy47/article/details/80943740