linux-centos-shell-正则表达式(grep,egrep.sed,awk,sort,tr,uniq工具使用)
文章目录
- 前言
- 一、正则表达式
-
- 1.1 正则表达式的定义
- 1.2 正则表达式用途
- 二、基础正则表达式——grep
-
- 2.1 查找特定字符
- 2.2 利用中括号“[]”来查找集合字符
- 2.3 查找行首“^”与行尾字符“$”
- 2.4 查找任意一个字符“.”与重复字符“*”
- 2.5 查找连续字符范围“{}”
- 三、元字符总结
- 四、扩展正则表达式——egrep
-
- 4.1 常见元字符
- 五、sed工具
-
- 5.1 sed 命令常见用法
- 5.2 用法示例
-
- 5.2.1 输出符合条件的文本
- 5.2.2 删除符合条件的文本
- 5.2.3 替换符合条件的文本
- 5.2.4 迁移符合条件的文本
- 5.2.5 使用脚本编辑文件
- 5.2.6 sed 直接操作文件示例
- 六、awk工具
-
- 6.1 awk常见用法
- 6.2 作用示例
-
- 6.2.1 按行输出文本
- 6.2.2 按字段输出文本
- 七、sort 工具
- 八、uniq 工具
- 九、tr工具
前言
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串
一、正则表达式
1.1 正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为 regex、regexp 或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说, 是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹 配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进 行匹配。其中普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指 那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符 前面的字符)在目标对象中的出现模式。
正则表达式一般用于脚本编程与文本编辑器中。很多文本处理器与程序设计语言均支持正则表达式,例如 Linux 系统中常见的文本处理器(grep、egrep、sed、awk)以及应用比较广泛的 Python 语言。正则表达式具备很强大的文本匹配功能,能够在文本海洋中快速高效地处理文本。
1.2 正则表达式用途
对于一般计算机用户来说,由于使用到正则表达式的机会不多,所以无法体会正则表达式的魅力,而对于系统管理员来说,正则表达式则是必备技能之一。
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便。
目前很多软件也支持正则表达式,最常见的就是邮件服务器。在 Internet 中,垃圾/广告邮件经常会造成网络塞车,如果在服务器端就将这些问题邮件提前剔除的话,客户端就会 减少很多不必要的带宽消耗。而目前常用的邮件服务器 postfix 以及支持邮件服务器的相关分析软件都支持正则表达式的对比功能。将来信的标题、内容与特殊字符串进行对比,发现 问题邮件就过滤掉。
除邮件服务器之外,很多服务器软件都支持正则表达式。虽然这些软件都支持正则表达 式,不过字符串的对比规则还需要系统管理员来添加,因此正则表达式是系统管理员必须掌 握的技能之一。
二、基础正则表达式——grep
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用正则表达式最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式。掌握基础正则表达式的使用方法,首先必须了解基本正则表达式所包含元字符的含义,下面通过grep 命令以举例的方式逐个介绍。
2.1 查找特定字符
查找特定字符非常简单,如执行以下命令即可从 httpd.conf 文件中查找出特定字符“the”所在位置。其中“-n”表示显示行号、“-i”表示不区分大小写。命令执行后,符合匹配标准的字符, 字体颜色会变为红色(本章中全部通过加粗显示代替)。
[root@localhost mnt]# grep -n 'the' httpd.conf
[root@shanan opt]# vi httpd.conf
[root@shanan opt]# grep -n "the" httpd.conf
2:# This is the main Apache HTTP server configuration file. It contains the
3:# configuration directives that give the server its instructions.
若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-v”选项实现,并配合“-n”一起使用显示行号。
[root@shanan opt]# grep -nv "the" httpd.conf
1:#
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
5:# In particular, see
6:# <URL:http://httpd.apache.org/docs/2.4/mod/directives.html>
7:# for a discussion of each configuration directive.
2.2 利用中括号“[]”来查找集合字符
想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh”与“rt”。此时执行以下命令即可同时查找到“shirt”与“short”这两个字符串,其中“[]”中无论有几个字符, 都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”。
[root@shanan opt]# grep -n "sh[io]rt" httpd.conf
362:shirt
363:short
若要查找包含重复单个字符“oo”时,只需要执行以下命令即可
[root@shanan opt]# grep -n “oo” httpd.conf
16:# with “/”, the value of ServerRoot is prepended – so ‘log/access_log’
17:# with ServerRoot set to ‘/www’ will be interpreted by the
若查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]”来实现该目的。例如执行“grep -n‘[^w]oo’httpd.conf ”命令表示在 httpd.conf文本中查找“oo”前面不是“w”的字符串。
[root@shanan opt]# grep -n "[^w]oo" httpd.conf
16:# with "/", the value of ServerRoot is prepended -- so 'log/access_log'
17:# with ServerRoot set to '/www' will be interpreted by the
22:# ServerRoot: The top of the directory tree under which the server's
26:# ServerRoot at a non-local disk, be sure to specify a local disk on the
........
357:woood
358:wooood
359:wooooood
360:wooooooood
361:wooooooooood
在上述命令的执行结果中发现“woood”与“wooooood”也符合匹配规则,二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符变红显示,而上述结果中可以得知, “#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood #”也符合匹配规则。
若不希望“oo”前面存在小写字母,可以使用“grep -n‘[^a-z]oo’httpd.conf”命令实现,其中
“a-z”表示小写字母,大写字母则通过“A-Z”表示。
root@shanan opt]# grep -n "[^a-z]oo" httpd.conf
16:# with "/", the value of ServerRoot is prepended -- so 'log/access_log'
17:# with ServerRoot set to '/www' will be interpreted by the
22:# ServerRoot: The top of the directory tree under which the server's
查找包含数字的行可以通过“grep -n‘[0-9]’httpd.conf”命令来实现。
[root@shanan opt]# grep -n "[0-9]" httpd.conf
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
6:# <URL:http://httpd.apache.org/docs/2.4/mod/directives.html>
14:# of the server's control files begin with "/" (or "drive:/" for Win32), the
41:#Listen 12.34.56.78:80
2.3 查找行首“^”与行尾字符“$”
基础正则表达式包含两个定位元字符:“^”(行首)与“$”(行尾)。在上面的示例中, 查询“the”字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为行首的行,则可以通过“^”元字符来实现。
[root@shanan opt]# grep -n "^the" httpd.conf
368:the pig
查询以小写字母开头的行可以通过’^ [a-z]'规则来过滤,查询大写字母开头的行则使用
'^ [A-Z]‘规则,若查询不以字母开头的行则使用’[a-zA-Z]'规则。
[root@shanan opt]# grep -n "^[a-z]" httpd.conf
354:wd
355:wod
356:wood
[root@shanan opt]# grep -n "^[A-Z]" httpd.conf
31:ServerRoot "/etc/httpd"
42:Listen 80
56:Include conf.modules.d/*.conf
66:User apache
67:Group apache
[root@shanan opt]# grep -n "[^A-Za-z]" httpd.conf
1:#
2:# This is the main Apache HTTP server configuration file. It contains the
3:# configuration directives that give the server its instructions.
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information
“^”符号在元字符集合“[ ]”符号内外的作用是不一样的,在“[ ]”符号内表示反向选择,在“[ ]” 符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。例如,执行以下命令即可实现查询以小数点(.)结尾的行。因为小数点(.)在正则表达式中也是一个元字符(后面会讲到),所以在这里需要用转义字符“\”将具有特殊意义的字符转化成普通字符。
[root@shanan opt]# grep -n "\.$" httpd.conf
3:# configuration directives that give the server its instructions.
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
7:# for a discussion of each configuration directive.
当查询空白行时,执行“grep -n‘^$’httpd.conf”命令即可。
[root@shanan opt]# grep -n "^$" httpd.conf
20:
32:
43:
2.4 查找任意一个字符“.”与重复字符“*”
前面提到,在正则表达式中小数点(.)也是一个元字符,代表任意一个字符,除了/n换行。例如执行以下命令就可以查找“w??d”的字符串,即共有四个字符,以 w 开头 d 结尾。
[
root@shanan opt]# grep -n "w..d" httpd.conf
108:# Note that from this point forward you must specifically allow
148: # It can be "All", "None", or any combination of the keywords:
356:wood
在上述结果中,“wood”字符串“w…d”匹配规则。若想要查询 oo、ooo、ooooo 等资料, 则需要使用星号(* )元字符。但需要注意的是,“ * ”代表的是重复零个或多个前面的单字符。 “o*”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符,所以执行“grep -n ‘o*’ httpd.conf”命令会将文本中所有的内容都输出打印。如果是“oo*”,则第一个 o 必须存在, 第二个 o 则是零个或多个 o,所以凡是包含 o、oo、ooo、ooo,等的资料都符合标准。同理,若查询包含至少两个 o 以上的字符串,则执行“grep -n ‘ooo*’ httpd.conf”命令即可。
[root@shanan opt]# grep -n "ooo" httpd.conf
357:woood
358:wooood
359:wooooood
360:wooooooood
361:wooooooooood
查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串,执行以下命令即可实现。
[root@shanan opt]# grep -n "woo*d" httpd.conf
355:wod
356:wood
357:woood
358:wooood
359:wooooood
360:wooooooood
361:wooooooooood
执行以下命令即可查询以 w 开头 d 结尾,中间的字符可有可无的字符串。
[root@shanan opt]# grep -n "w.*d" httpd.conf
9:# Do NOT simply read the instructions in here without understanding
10:# what they do. They're here only as hints or reminders. If you are unsure
11:# consult the online docs. You have been warned.
14:# of the server's control files begin with "/" (or "drive:/" for Win32), the
15:# server will use that explicit path. If the filenames do *not* begin
16:# with "/", the value of ServerRoot is prepended -- so 'log/access_log'
[root@shanan opt]# grep -n "w.d" httpd.conf
169:# viewed by Web clients.
355:wod
[root@shanan opt]# grep -n "w.d" httpd.conf
169:# viewed by Web clients.
355:wod
[root@shanan opt]# grep -n "w*d" httpd.conf
3:# configuration directives that give the server its instructions.
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
6:# <URL:http://httpd.apache.org/docs/2.4/mod/directives.html>
执行以下命令即可查询任意数字所在行。
[root@shanan opt]# grep -n "[0-9][0-9]*" httpd.conf
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
6:# <URL:http://httpd.apache.org/docs/2.4/mod/directives.html>
14:# of the server's control files begin with "/" (or "drive:/" for Win32), the
41:#Listen 12.34.56.78:80
如果只匹配‘* ’号,那么* 号只作为普通字符,匹配所有带‘*’的行
[root@shanan opt]# grep -n "*" httpd.conf
15:# server will use that explicit path. If the filenames do *not* begin
56:Include conf.modules.d/*.conf
137: # Note that "MultiViews" must be named *explicitly* --- "Options All"
171:
2.5 查找连续字符范围“{}”
在上面的示例中,使用了“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?例如,查找三到五个 o 的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。因为“{}”在 Shell 中具有特殊意义,所以在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。“{}”字符的使用方法如下所示。
查询两个 o 的字符。
[
root@shanan opt]# grep -n "o\{2\}" httpd.conf
16:# with "/", the value of ServerRoot is prepended -- so 'log/access_log'
17:# with ServerRoot set to '/www' will be interpreted by the
22:# ServerRoot: The top of the directory tree under which the server's
查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串。
[root@shanan opt]# grep -n "o\{2,5\}" httpd.conf
332:#ErrorDocument 500 "The server made a boo boo."
356:wood
357:woood
358:wooood
359:wooooood
360:wooooooood
361:wooooooooood
查询以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o 的字符串。
[root@shanan opt]# grep -n "o\{2,\}" httpd.conf
16:# with "/", the value of ServerRoot is prepended -- so 'log/access_log'
17:# with ServerRoot set to '/www' will be interpreted by the
230: # access content that does not live under the DocumentRoot.
332:#ErrorDocument 500 "The server made a boo boo."
356:wood
357:woood
358:wooood
359:wooooood
360:wooooooood
361:wooooooooood
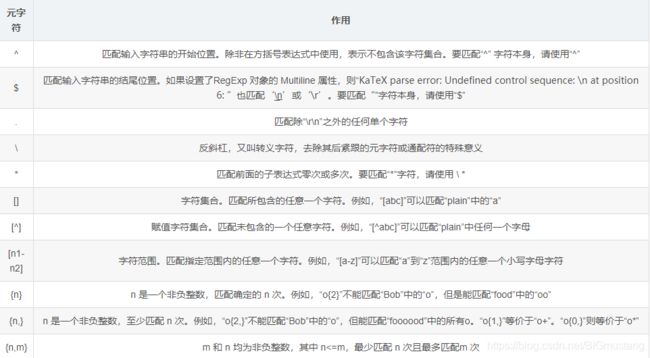
三、元字符总结
通过上面几个简单的示例,可以了解到常见的基础正则表达式的元字符主要包括以下几 个:
四、扩展正则表达式——egrep
通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令,需要使用范围更广的扩展正则表达式。例如,使用基础正则表达式查询除文件中空白行与行首为“#”之外的行(通常用于查看生效的配置文件),执行“grep -v‘^$ ’ httpd.conf | grep -v‘^#’”即可实现。这里需要使用管道命令来搜索两次。如果使用扩展正则表达式, 可以简化为“egrep
-v ‘^$ | ^#’httpd.conf”,其中,单引号内的管道符号表示或者(or)。
此外,grep 命令仅支持基础正则表达式,如果使用扩展正则表达式,需要使用 egrep 或 awk 命令。这里我们直接使用 egrep 命令。egrep 命令与 grep 命令的用法基本相似。egrep 命令是一个搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以搜索一个或多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字或一个句子。
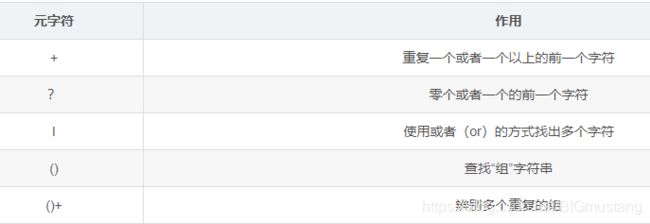
4.1 常见元字符
4.2 egrep用法示例
执行“egrep -n ‘wo+d’ httpd.conf”命令,即可查询"wood" “woood” "woooooood"等字符串
[root@shanan opt]# egrep -n "wo+d" httpd.conf
355:wod
356:wood
357:woood
358:wooood
359:wooooood
360:wooooooood
361:wooooooooood
执行“egrep -n ‘wo?d’ httpd.conf”命令,即可查询“wd”“wod”这两个字符串
[root@shanan opt]# egrep -n "wo?d" httpd.conf
168:# The following lines prevent .htaccess and .htpasswd files from being
354:wd
355:wod
执行“egrep -n ‘of|is|on’ httpd.conf”命令即可查询"of"或者"if"或者"on"字符串
[root@shanan opt]# egrep -n "of|is|on" httpd.conf
2:# This is the main Apache HTTP server configuration file. It contains the
3:# configuration directives that give the server its instructions.
4:# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
7:# for a discussion of each configuration directive.
“egrep -n ‘sh(o|i)rt’ httpd.conf ”。“short”与“shirt”因为这两个单词的“sh”与“rt”是重复的,所以将“o”与“i”列于“()”符号当中,并以“|”分隔,即可查询"short"或者"shirt"字符串
[root@shanan opt]# egrep -n 'sh(o|i)rt' httpd.conf
362:shirt
363:short
“egrep -n ‘A(xyz)+C’ httpd.conf”。该命令是查询开头的"A"结尾是"C",中间有一个以上的"xyz"字符串的意思
(XYZ)是一个整体,整体匹配
[root@shanan opt]# egrep -n "A(xyz)+B" httpd.conf
365:AxyzB
366:AxyzxyzB
五、sed工具
sed(Stream EDitor)是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等),最后输出所有行或者仅输出处理的某些行。sed 也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于 Shell 脚本中,用以完成各种自动化处理任务。
sed 的工作流程主要包括读取、执行和显示三个过程
读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。
在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
注意:默认情况下所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
5.1 sed 命令常见用法
通常情况下调用 sed 命令有两种格式。其中,“参数”是指操作的目标文件, 当存在多个操作对象时用,文件之间用逗号“,”分隔;而 scriptfile 表示脚本文件,需要用“-f” 选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。
sed [选项] '操作' 参数
sed [选项] -f scriptfile 参数
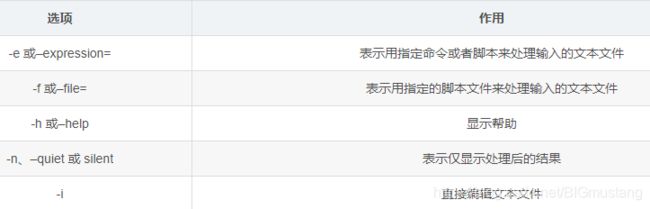
常见的 sed 命令选项主要包含以下几种
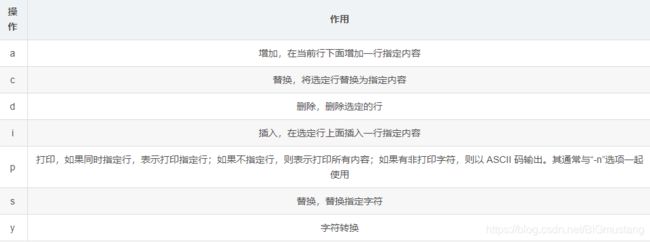
“操作”用于指定对文件操作的动作行为,也就是 sed 的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,代表选择进行操作的行数,如操作需要在 5~ 20 行之间进行,则表示为“5,20 动作行为”。常见的操作包括以下几种
5.2 用法示例
5.2.1 输出符合条件的文本
[root@shanan opt]# sed -n 'p' httpd.conf '输出所有内容,等同于 cat httpd.conf'
[root@shanan opt]# sed -n '3p' httpd.conf '输出第3行'
[root@shanan opt]# sed -n '3,5p' httpd.conf '输出 3~5 行'
[root@shanan opt]# sed -n 'p;n' httpd.conf '输出所有奇数行,n 表示读入下一行资料'
[root@shanan opt]# sed -n 'n;p' httpd.conf '输出所有偶数行,n 表示读入下一行资料'
[root@shanan opt]# sed -n '1,5{p;n}' httpd.conf '输出第 1~5 行之间的奇数行(第 1、3、5'
[root@shanan opt]# sed -n '10,${n;p}' httpd.conf '输出第 10 行至文件尾之间的偶数行'
在执行“sed -n‘10,${n;p}’httpd.conf”命令时,读取的第 1 行是文件的第 10 行,读取的第 2
行是文件的第 11 行,依此类推,所以输出的偶数行是文件的第 11 行、13 行直至文件结尾, 其中包括空行。
以上是 sed 命令的基本用法,sed 命令结合正则表达式时,格式略有不同,正则表达式以“/”包围。例如,以下操作是 sed 命令与正则表达式结合使用的示例。
[root@shanan opt]# sed -n '/the/p' httpd.conf '输出包含the 的行'
[root@shanan opt]# sed -n '4,/the/p' httpd.conf '输出从第 4 行至第一个包含 the 的行'
[root@shanan opt]# sed -n '/the/=' httpd.conf'输出包含the 的行所在的行号,等号(=)用来输出行号'
[root@shanan opt]# sed -n '/^PI/p' httpd.conf '输出以PI 开头的行'
[root@shanan opt]# sed -n '/[0-9]$/p' httpd.conf '输出以数字结尾的行'
[root@shanan opt]# sed -n '/\/p' httpd.conf'输出包含单词wood 的行,\<、\>代表单词边界'
5.2.2 删除符合条件的文本
下面命令中 nl 命令用于计算文件的行数,结合该命令可以更加直观地查看到命令执行的结果。
[root@shanan opt]# nl httpd.conf | sed '3d' '删除第 3 行'
[root@shanan opt]# nl httpd.conf | sed '3,5d' '删除第 3~5 行'
[root@shanan opt]# nl httpd.conf |sed '/cross/d' '删除包含 cross 的行,原本的第 8 行被删除'
[root@shanan opt]# nl httpd.conf |sed '/cross/! d' '删除不包含 cross 的行'
[root@shanan opt]# sed '/^[a-z]/d' httpd.conf '删除以小写字母开头的行'
[root@shanan opt]# sed '/\.$/d' httpd.conf '删除以"."结尾的行'
[root@shanan opt]# sed '/^$/d' httpd.conf '删除所有空行'
[root@shanan opt]# sed -e '/^$/{n;/^S/d}' httpd.conf '删除重复的空行,即连续的空行只保留一个'
5.2.3 替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y
(字符转换)命令选项,常见的用法如下所示
[root@shanan opt]# sed 's/the/THE/' httpd.conf '将每行中的第一个the 替换为THE'
[root@shanan opt]# sed 's/l/L/2' httpd.conf '将每行中的第2个l替换为L'
[root@shanan opt]# sed 's/the/THE/g' httpd.conf '将文件中的所有the替换为THE'
[root@shanan opt]# sed 's/o//g' httpd.conf '将文件中的所有o删除(替换为空串)'
[root@shanan opt]# sed 's/^/#/' httpd.conf '在每行行首插入#号'
[root@shanan opt]# sed '/the/s/^/#/' httpd.conf '在包含the 的每行行首插入#号'
[root@shanan opt]# sed 's/$/EoF/' httpd.conf '在每行行尾插入字符串EoF'
[root@shanan opt]# sed '3,5s/the/THE/g' httpd.conf'将第3~5行中的所有the替换为THE'
[root@shanan opt]# sed '/the/s/o/O/g' httpd.conf '将包含the的所有行中的o都替换为O'
5.2.4 迁移符合条件的文本
在使用 sed 命令迁移符合条件的文本时,常用到以下参数
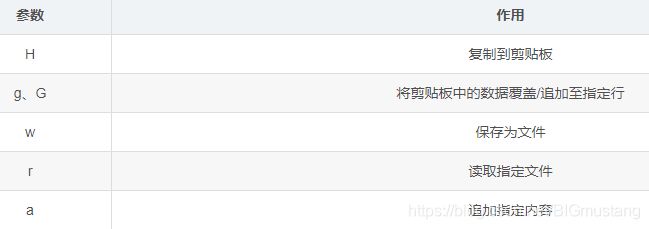
[root@shanan opt]# sed '/the/{H;d};$G' httpd.conf '将包含the的行迁移至文件末尾,{;}用于多个操作'
[root@shanan opt]# sed '1,5{H;d};17G' httpd.conf '将第1~5行内容转移至第17行后'
[root@shanan opt]# sed '/the/w out.file' httpd.conf '将包含the的行另存为文件out.file'
[root@shanan opt]# sed '/the/r /etc/hostname' httpd.conf '将文件/etc/hostname的内容添加到包含the的每行以后'
[root@shanan opt]# sed '3aNew' httpd.conf '在第3行后插入一个新行,内容为New'
[root@shanan opt]# sed '/the/aNew' httpd.conf '在包含the的每行后插入一个新行,内容为New'
[root@shanan opt]# sed '3aNew1\nNew2' httpd.conf '在第3行后插入多行内容,中间的\n表示换行'
5.2.5 使用脚本编辑文件
使用 sed 脚本将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调用
[root@shanan opt]# sed '1,5{H;d};6G' 123.txt '将第1~5行内容转移至第6行后'
6
1
2
3
4
5
7
8
9
10
11
12
以上操作可以改用脚本文件方式
[root@shanan opt]# sed -f 456.list 123.txt
6
1
2
3
4
5
7
8
9
10
11
12
[root@shanan opt]# nl 123.txt
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
11 11
12 12
5.2.6 sed 直接操作文件示例
编写一个脚本,用来调整 vsftpd 服务配置,要求禁止匿名用户,但允许本地用户(也允许写入)
[root@shanan opt]# vim local_only_ftp.sh
#!/bin/bash
# 指定样本文件路径、配置文件路径
SAMPLE="/usr/share/doc/vsftpd-3.0.2/EXAMPLE/INTERNET_SITE/vsftpd.conf " CONFIG="/etc/vsftpd/vsftpd.conf"
# 备份原来的配置文件,检测文件名为/etc/vsftpd/vsftpd.conf.bak 备份文件是否存在, 若不存在则使用 cp 命令进行文件备份
[ ! -e "$CONFIG.bak" ] && cp $CONFIG $CONFIG.bak # 基于样本配置进行调整,覆盖现有文件
sed -e '/^anonymous_enable/s/YES/NO/g' $SAMPLE > $CONFIG
sed -i -e '/^local_enable/s/NO/YES/g' -e '/^write_enable/s/NO/YES/g' $CONFIG grep "listen" $CONFIG || sed -i '$alisten=YES' $CONFIG
# 启动vsftpd 服务,并设为开机后自动运行
systemctl restart vsftpd systemctl enable vsftpd
[root@shanan opt]# chmod +x local_only_ftp.sh
六、awk工具
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
6.1 awk常见用法
通常情况下 awk 所使用的命令格式如下所示,其中,单引号加上大括号“{}”用于设置对数据进行的处理动作。awk 可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进行处理。
awk 选项 ‘模式或条件 {编辑指令}’ 文件 1 文件 2 … ‘过滤并输出文件中符合条件的内容’
awk -f 脚本文件 文件 1 文件 2 … ‘从脚本中调用编辑指令,过滤并输出内容’
前面提到 sed 命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。在使用 awk 命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||” 表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
在 Linux 系统中/etc/passwd 是一个非常典型的格式化文件,各字段间使用“:”作为分隔符隔开,Linux 系统中的大部分日志文件也是格式化文件,从这些文件中提取相关信息是运维的日常工作内容之一。
若需要查找出/etc/passwd 的用户名、用户 ID、组 ID 等列,执行以下 awk 命令即可。
[root@shanan opt]# awk -F : '{print $1,$3,$4}' /etc/passwd
root 0 0
bin 1 1
daemon 2 2
adm 3 4
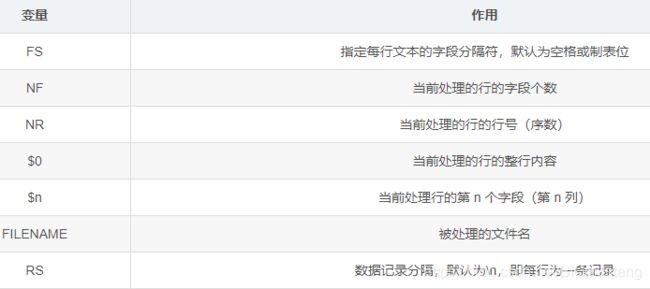
awk 从输入文件或者标准输入中读入信息,与 sed 一样,信息的读入也是逐行读取的。不同的是awk将文本文件中的一行视为一个记录,而将一行中的某一部分(列)作为记录中的一个字段(域)。为了操作这些不同的字段,awk 借用 shell 中类似于位置变量的方法, 用$1、$2、$3…顺序地表示行(记录)中的不同字段。另外 awk 用$0 表示整个行(记录)。不同的字段之间是通过指定的字符分隔。awk 默认的分隔符是空格。awk 允许在命令行中用“-F 分隔符”的形式来指定分隔符。
awk 包含几个特殊的内建变量(可直接用):
6.2 作用示例
6.2.1 按行输出文本
[root@shanan opt]# awk '{print}' httpd.conf '输出所有内容,等同于 cat httpd.conf'
[root@shanan opt]# awk '{print $0}' httpd.conf '输出所有内容,等同于 cat httpd.conf'
[root@shanan opt]# awk 'NR==1,NR==3{print}' httpd.conf '输出第 1~3 行内容'
[root@shanan opt]# awk '(NR>=1)&&(NR<=3){print}' httpd.conf '输出第 1~3 行内容'
[root@shanan opt]# awk 'NR==1||NR==3{print}' httpd.conf '输出第 1 行、第 3 行内容'
[root@shanan opt]# awk '(NR%2)==1{print}' httpd.conf '输出所有奇数行的内容'
[root@shanan opt]# awk '(NR%2)==0{print}' httpd.conf '输出所有偶数行的内容'
[root@shanan opt]# awk '/^root/{print}' /etc/passwd '输出以root 开头的行'
[root@shanan opt]# awk '/nologin$/{print}' /etc/passwd '输出以nologin结尾的行'
[root@shanan opt]# awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd '统计以/bin/bash结尾的行数,等同于grep -c "/bin/bash$" /etc/passwd'
[root@shanan opt]# awk 'BEGIN{RS=""};END{print NR}'/etc/squid/squid.conf'统计以空行分隔的文本段落数'
6.2.2 按字段输出文本
[root@shanan opt]# awk '{print $3}' httpd.conf '输出每行中(以空格或制表位分隔)的第3个字段'
[root@shanan opt]# awk '{print $1,$3}' httpd.conf '输出每行中的第1、3个字段'
[root@shanan opt]# awk -F : '$2==""{print}' /etc/shadow '输出密码为空的用户的shadow记录'
[root@shanan opt]# awk 'BEGIN {FS=":"}; $2==""{print}' /etc/shadow '输出密码为空的用户的shadow 记录'
[root@shanan opt]# awk -F : '$7~"/bash"{print $1}' /etc/passwd '输出以冒号分隔且第7个字段中包含/bash的行的第1个字段'
[root@shanan opt]# awk '($1~"nfs")&&(NF==8){print $1,$2}' /etc/services '输出包含 8 个字段且第 1 个字段中包含 nfs 的行的第 1、2 个字段'
[root@shanan opt]# awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd'输出第7个字段既不为/bin/bash 也不为/sbin/nologin 的所有行'
6.2.3 通过管道、双引号调用 Shell 命令
[root@shanan opt]# awk -F: '/bash$/{print | "wc -l"}' /etc/passwd '调用wc -l 命令统计使用 bash 的用户个数',等同于 grep -c "bash$" /etc/passwd
[root@shanan opt]# awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}}' '调用w 命令,并用来统计在线用户数'
[root@shanan opt]# awk 'BEGIN { "hostname" | getline ; print $0}' '调用hostname,并输出当前的主机名'
七、sort 工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。例如数据和字符的排序就不一样。sort 命令的语法为“sort [选项] 参数”,其中常用的选项包括以下几种
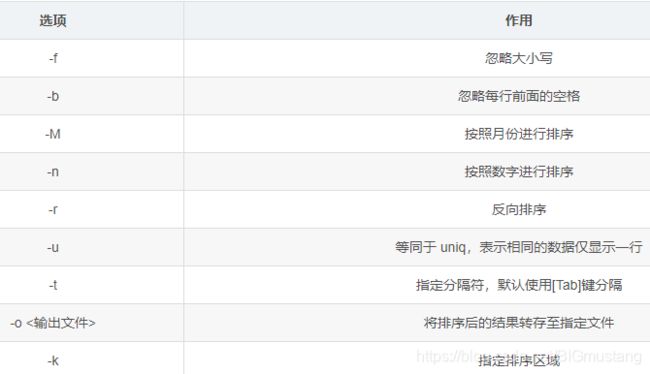
7.1 用法示例
将/etc/passwd 文件中的账号进行排序
[root@shanan opt]# sort /etc/passwd
abrt:x:173:173::/etc/abrt:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:993:988::/var/lib/chrony:/sbin/nologin
colord:x:997:994:User for colord:/var/lib/colord:/sbin/nologin
......
将/etc/passwd 文件中第三列进行反向排序
[root@shanan opt]# sort -t ':' -rk 3 /etc/passwd
nobody:x:99:99:Nobody:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
libstoragemgmt:x:998:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
colord:x:997:994:User for colord:/var/lib/colord:/sbin/nologin
gluster:x:996:993:GlusterFS daemons:/run/gluster:/sbin/nologin
saslauth:x:995:76:Saslauthd user:/run/saslauthd:/sbin/nologin
unbound:x:994:989:Unbound DNS resolver:/etc/unbound:/sbin/nologin
chrony:x:993:988::/var/lib/chrony:/sbin/nologin
geoclue:x:992:986:User for geoclue:/var/lib/geoclue:/sbin/nologin
sssd:x:991:985:User for sssd:/:/sbin/nologin
setroubleshoot:x:990:984::/var/lib/setroubleshoot:/sbin/nologin
saned:x:989:983:SANE scanner daemon user:/usr/share/sane:/sbin/nologin
gnome-initial-setup:x:988:982::/run/gnome-initial-setup/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
radvd:x:75:75:radvd user:/:/sbin/nologin
......
将/etc/passwd 文件中第三列进行排序,并将输出内容保存至 user.txt 文件中
[root@shanan opt]# sort -t ':' -k 3 /etc/passwd -o user.txt
[root@shanan opt]# cat user.txt
root:x:0:0:root:/root:/bin/bash
liu:x:1000:1000:liu:/home/liu:/bin/bash
qemu:x:107:107:qemu user:/:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
pulse:x:171:171:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
rtkit:x:172:172:RealtimeKit:/proc:/sbin/nologin
......
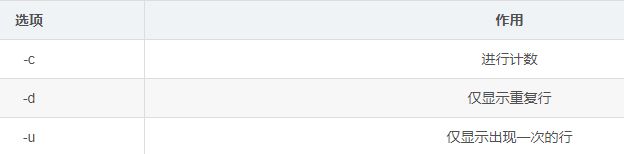
八、uniq 工具
Uniq 工具在 Linux 系统中通常与 sort 命令结合使用,用于报告或者忽略文件中的重复行。具体的命令语法格式为:uniq [选项] 参数。其中常用选项包括以下几种
8.1 用法示例
删除 test文件中的重复行
[root@shanan opt]# uniq test.txt
10
20
30
40
50
aaa
bbb
ccc
删除 test文件中的重复行,并在行首显示该行重复出现的次数
[root@shanan opt]# uniq -c test.txt
2 10
1 20
1 30
1 40
2 50
2 aaa
1 bbb
1 ccc
查找 test文件中的重复行
[root@shanan opt]# uniq -d test.txt
10
50
aaa
九、tr工具
tr 命令常用来对来自标准输入的字符进行替换、压缩和删除。可以将一组字符替换之后变成另一组字符,经常用来编写优美的单行命令,作用很强大
tr 具体的命令语法格式为:
tr [选项] [参数]
其常用选项包括以下内容

9.1用法示例
将输入字符由大写转换为小写
[root@shanan opt]# echo "CLLT" | tr 'A-Z' 'a-z'
cllt
压缩输入中重复的字符
[root@shanan ~]# echo "thissss is a text linnnnnnne." | tr -s 'sn'
this is a text line.
删除字符串中某些字符
[root@shanan ~]# echo 'hello world' | tr -d 'od'
hell wrl
[root@shanan opt]# echo "how are you"|tr -d "ow"
h are yu