Android runtime层是如何通过缩减代码来缩减内存的
文章目录
- 前言:Android 在设备上改进内存的秘密
- 优化编译器101
- 代码大小改进
- 消除写入障碍
- 隐式暂停检查
- 合并回调
- 其他优化改进
- 代码下沉
- 循环优化
- 消除死代码 – SimplifyAlwaysThrows
- 加载存储消除 – 使用 try catch 块
- 加载存储消除 – 使用释放/获取操作
- 新的内联启发式
- 不断折叠
- 把它们放在一起
- 进一步阅读
前言:Android 在设备上改进内存的秘密

Android 运行时 (ART) 执行由 Java 或 Kotlin 语言编写的应用程序和系统服务生成的Dalvik字节码。我们不断改进 ART 以生成更小、性能更高的代码。改进 ART 可以使系统和用户体验整体上更好,因为它是 Android 应用程序的共同点。在这篇博文中,我们将讨论在不影响性能的情况下减少代码大小的优化。
代码大小是我们关注的关键指标之一,因为生成的文件越小,对内存(RAM 和存储)越有利。通过新版本的 ART,我们估计每台设备可为用户节省约 50-100MB 的空间。这可能正是您更新您喜爱的应用程序或下载新应用程序所需要的。由于 ART 可从 Android 12 开始更新,这些优化适用于1B+ 设备,谷歌在全球范围内为这些设备节省了47-95 PB(47-95 百万 GB!)!
本博文中提到的所有改进都是开源的。它们可以通过 ART 主线更新获得,因此您甚至不需要完整的操作系统更新即可获得好处。我们可以把蛋糕倒过来吃!
优化编译器101
ART使用设备上的 dex2oat 工具将应用程序从DEX 格式编译为本机代码。第一步是解析 DEX 代码并生成中间表示(IR)。使用 IR,dex2oat 执行许多代码优化。管道的最后一步是代码生成阶段,其中 dex2oat 将 IR 转换为本机代码(例如,AArch64 汇编)。
优化管道具有执行的阶段,以便每个阶段专注于一组特定的优化。例如,常量折叠是一种优化,尝试用常量值替换指令,例如将加法运算2 + 3折叠为5。
IR 可以打印和可视化,但与 Kotlin 语言代码相比非常冗长。出于本博文的目的,我们将展示使用 Kotlin 语言代码进行的优化,但要知道它们正在发生在 IR 代码上。
代码大小改进
对于所有代码大小优化,我们对 Google Play 商店中超过 50 万个 APK 进行了测试,并汇总了结果。
消除写入障碍
我们有一个新的优化过程,称为“写入障碍消除”。写屏障会跟踪自垃圾收集器 (GC) 上次检查以来已修改的对象,以便 GC 可以重新访问它们。例如,如果我们有:

以前,我们会为每个对象修改发出一个写屏障,但我们只需要一个写屏障,因为:1)标记将在o本身中设置(而不是在内部对象中),2)垃圾收集不能与这些集合之间的线程进行了交互。
如果指令可能触发 GC(例如 Invokes 和 SuspendChecks),我们将无法消除写入障碍。在下面的示例中,我们不能保证 GC 不需要检查或修改修改之间的跟踪信息:

实施这一新通道有助于减少 0.8% 的代码大小。
隐式暂停检查
假设我们有几个线程正在运行。挂起检查是安全点(由下图中的房屋表示),我们可以在其中暂停线程执行。使用安全点的原因有很多,其中最重要的是垃圾收集。当发出安全点调用时,线程必须进入安全点并被阻塞,直到它们被释放。
以前的实现是显式布尔检查。我们将加载该值,对其进行测试,并在需要时分支到安全点。

隐式挂起检查是一种优化,消除了对测试和分支指令的需要。相反,我们只有一个负载:如果线程需要挂起,该负载将捕获,并且信号处理程序会将代码重定向到挂起检查处理程序,就像该方法进行了调用一样。
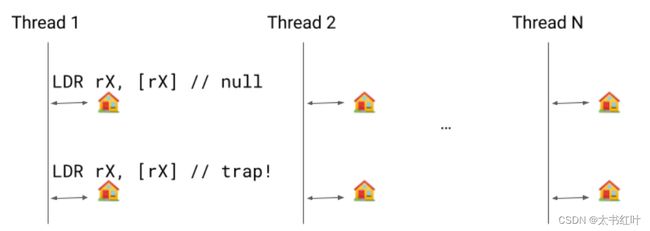
更详细地说,保留寄存器 rX 预加载了线程内的一个地址,其中我们有一个指向其自身的指针。只要我们不需要进行挂起检查,我们就保留该自指向指针。当我们需要进行挂起检查时,我们清除指针,一旦它对线程可见,第一个LDR rX, [rX]将加载 null,第二个将出现段错误。
挂起请求本质上是要求线程很快挂起一段时间,因此等待第二次加载的轻微延迟是可以接受的。
此优化将代码大小减少了 1.8%。
合并回调
已编译方法通常具有入口框架。如果它们拥有它,这些方法必须在返回时解构它,这也称为退出框架。如果一个方法有多个返回指令,它将生成多个退出帧,每个返回指令一个。
通过将返回指令合并为一条,我们能够拥有一个返回点并能够删除多余的退出帧。这对于具有多个 return 语句的 switch 情况特别有用。

合并返回可将代码大小减少 1%。
其他优化改进
我们改进了许多现有的优化过程。在这篇博文中,我们将它们分组在同一部分,但它们彼此独立。以下部分中的所有优化都有助于减少 5.7% 的代码大小。
代码下沉
代码下沉是一种优化过程,它将指令下推到不常见的分支,例如以 throw 结尾的路径。这样做是为了减少可能不会使用的指令上浪费的周期。
我们通过 try catch 改进了图中的代码下沉:现在,只要我们不将代码下沉到与它开始的尝试不同的尝试中(或者如果它不在开始的尝试中,则在任何尝试中),我们现在允许下沉代码和)。

在第一个示例中,我们可以接收对象创建,因为它只会在if(flag)路径中使用,而不会在其他路径中使用,并且它位于同一个尝试中。通过此更改,在运行时只有当flag为 true时才会运行。在不涉及太多技术细节的情况下,我们可以关注的是实际的对象创建,但加载Object类仍然保留在if之前。这很难用 Kotlin 代码来展示,因为同一条 Kotlin 行在 ART 编译器级别会变成多条指令。
在第二个示例中,我们不能下沉代码,因为我们将在另一个尝试中移动实例创建(可能会抛出异常)。
Code Sinking主要是一种运行时性能优化,但它可以帮助减轻寄存器压力。通过将指令移近其用途,在某些情况下我们可以使用更少的寄存器。使用更少的寄存器意味着更少的移动指令,这最终有助于减少代码大小。
循环优化
循环优化有助于在编译时消除循环。在下面的示例中, foo中的循环将a乘以10,10次。这与乘以100相同。我们启用循环优化以在带有 try catch 的图中工作。

在foo中,我们可以优化循环,因为 try catch 是不相关的。
然而,在bar或baz中,我们不对其进行优化。如果循环中有一个 try,或者整个循环是否在 try 内部,那么了解循环将采用的路径并不是一件容易的事。
消除死代码 – 删除不需要的 try 块
我们通过实施优化来删除不包含抛出指令的 try 块,从而改进了死代码消除阶段。我们还可以删除一些 catch 块,只要没有活动的 try 块指向它。
在下面的示例中,我们将bar内联到foo中。之后,我们知道该师不能投掷。稍后的优化过程可以利用这一点并改进代码。

只需从 try catch 中删除死代码就足够了,但更好的是,在某些情况下我们允许进行其他优化。如果您还记得的话,当循环有一个 try 或它位于一个 try 内部时,我们不会进行循环优化。通过消除这种冗余的 try/catch,我们可以循环优化,生成更小、更快的代码。

消除死代码 – SimplifyAlwaysThrows
在死代码消除阶段,我们有一个称为SimplifyAlwaysThrows 的优化。如果我们检测到调用总是会抛出异常,我们可以安全地丢弃该方法调用之后的任何代码,因为它永远不会被执行。
我们还更新了SimplifyAlwaysThrows,以便在带有 try catch 的图中工作,只要调用本身不在 try 内部。如果它在 try 内部,我们可能会跳转到 catch 块,并且很难找出将要执行的确切路径。

我们还改进了:
- 通过查看参数来检测调用何时抛出。在左边,我们将把divide(1, 0)标记为总是抛出,即使泛型方法并不总是抛出。
- SimplifyAlwaysThrows适用于所有调用。以前我们有限制,例如不要对导致if的调用执行此操作,但我们可以删除所有限制。

加载存储消除 – 使用 try catch 块
负载存储消除(LSE) 是一种删除冗余负载和存储的优化过程。
我们改进了这个过程以处理图中的 try catch。在foo中,我们可以看到,如果存储/加载不直接与 try 交互,我们可以正常执行 LSE。在bar中,我们可以看到一个示例,我们要么走正常路径而不抛出异常,在这种情况下我们返回1;或者我们抛出,抓住它并返回2。由于每条路径的值都是已知的,因此我们可以删除冗余负载。

加载存储消除 – 使用释放/获取操作
我们改进了加载存储消除过程,以在具有释放/获取操作的图表中工作。这些是易失性加载、存储和监视操作。澄清一下,这意味着我们允许 LSE 在具有这些操作的图中工作,但我们不会删除所述操作。
在示例中,i和j是常规整型,vi是易失性整型。在foo中,我们可以跳过加载值,因为集合和加载之间没有释放/获取操作。在bar中,易失性操作发生在它们之间,因此我们无法消除正常负载。请注意,不使用易失性加载结果并不重要——我们无法消除获取操作。

此优化与易失性存储和监视器操作(Kotlin 中的同步块)类似。
新的内联启发式
我们的内联传递具有广泛的启发式。有时我们决定不内联一个方法,因为它太大,或者有时我们决定强制内联一个方法,因为它太小(例如,像对象初始化这样的空方法)。
我们实现了一个新的内联启发式:不要内联调用导致抛出。如果我们知道要抛出异常,我们将跳过内联这些方法,因为抛出本身的成本足够高,以至于内联该代码路径是不值得的。
我们将跳到内联的三个方法系列:
- 在抛出之前计算并打印调试信息。
- 内联错误构造函数本身。
- 最后块在我们的优化编译器中被重复。我们有一个用于正常情况(即尝试不抛出),还有一个用于异常情况。我们这样做是因为在特殊情况下我们必须:捕获、执行finally
块并重新抛出。特殊情况下的方法现在不会内联,但正常情况下的方法会内联。

不断折叠
常量折叠是一种优化过程,如果可能的话,将操作更改为常量。我们实现了一种优化,可以传播在if防护中使用时已知为常量的变量。图中有更多常量可以让我们稍后执行更多优化。
在foo中,我们知道a在if保护中的值为2。我们可以传播该信息并推断b必须是4。同样,在bar中,我们知道cond在if情况下必须为 true ,在else情况下必须为 false (简化图表)。

把它们放在一起
如果我们考虑到本博文中的所有代码大小优化,我们的代码大小将减少 9.3%!
从长远来看,一部普通手机可以有 500MB-1GB 的优化代码(实际数字可以更高或更低,具体取决于您安装了多少应用程序,以及您安装了哪些特定应用程序),因此这些优化可以节省大约 50每台设备 -100MB。由于这些优化适用于 1B+ 设备,我们在全球范围内节省了 47-95 PB!
进一步阅读
如果您对代码更改本身感兴趣,请随时查看。本博文中提到的所有改进都是开源的。如果您想帮助全世界的 Android 用户,请考虑为 Android 开源项目做出贡献!
————————————:Santiago Aboy Solanes - 软件工程师