Zookeeper+Hadoop+Hbase+Hive+Kylin+Nginx集群搭建
Zookeeper+Hadoop+Hbase+Hive+Kylin+Nginx集群搭建
- 一、虚拟机安装Centos7
-
- 1.准备工作
- 2.centos7安装过程
- 3.关闭防火墙(关键)
- 二、安装jdk
-
- 1.卸载镜像自带jdk
- 2.安装自己的jdk
- 3.配置多机器间免密登录
- 三、搭建Hadoop集群
-
- 1.hadoop安装
- 2.配置修改
- 3.克隆并配置其他虚拟机
- 4.启动测试
- 5.可能遇到的问题
- 四、Zookeeper集群搭建
-
- 1.下载安装zookeeper安装包
- 2.文件配置
- 3.启动测试
- 五、Hbase集群搭建
-
- 1.准备工作(下载与时间同步)
- 2.安装解压
- 3.环境变量配置
- 4.文件配置
- 六、启动Hbase
-
- 1.启动zookeeper
- 2.启动Hadoop
-
- 2.1格式化HDFS
- 2.2启动HDFS
- 2.3启动YARN
- 2.4Hadoop启动校验
- 3.Hbase启动
- 4.问题
- 七、Hive安装配置
-
- 1.准备工作
- 2.安装hive
- 八、Kylin搭建
-
- 1.安装
- 2.配置环境变量
- 3.配置kylin
- 4.启动使用
- 5.问题
- 九、Hadoop集群动态扩容、缩容
-
- 1.动态扩容
-
- 1.1准备工作
- 1.2添加datanode
- 1.3datanode负载均衡服务
- 1.4添加nodemanager
- 2.动态缩容
-
- 2.1添加退役节点
- 2.2刷新集群
- 2.3停止进程
- 十、hadoop集群客户端节点
-
- 1.问题的提出
- 2.如何配置集群和户端?
- 3.具体实现:
- 十一、Hive拓展客户端
-
- 1.准备工作
- 2.配置变量
- 3.验证
- 十二、kylin集群搭建
-
- 1.配置
- 2.启动验证
-
- 2.1启动
- 2.2验证
- 3.文档叙述
-
- 3.1Kylin 集群模式部署
- 3.2任务引擎高可用
- 3.3配置CuratorScheculer进行任务调度
- 4.帮助理解
-
- 4.1 Job Scheduler
-
- 4.1.1 为什么需要Job Scheduler ?
- 4.1.2 kylin中有哪些调度程序?
- 4.1.3 不同的作业调度程序有什么区别?
- 十三、Nginx负载均衡
-
- 1.Nginx安装环境
- 2.编译
- 3.启动测试
- 4.nginx实现kylin集群的负载均衡
- 5.问题
大数据集群搭建安装包:https://download.csdn.net/download/tktttt/12879318
大数据集群搭建安装包2:https://download.csdn.net/download/tktttt/12879355
一、虚拟机安装Centos7
1.准备工作
使用软件:VMware Workstation;该软件的安装一直下一步就行。
下面开始阐述镜像的安装:
可以直接去官网下载一个需要的镜像,本文操作时选择的是CentOS-7-x86_64-DVD-2003.iso,可以点击此处下载
2.centos7安装过程
打开VMware,点击创建新的虚拟机
选择自定义,点击下一步

点击下一步
选择稍后安装操作系统,点击下一步

客户机操作系统选择Linux,版本选择Centos 7 64位,点击下一步
虚拟机名称随意定义(自己记得住该虚拟机用来干嘛即可),建议取名有标识度,位置最好放在C盘之外的其他盘,点击下一步
之后可以按默认参数,一直点击下一步,到网络连接时,选择NAT

之后继续一直按默认参数点击下一步,可以看到Centos已经创建到我的计算机中,即图中的Hadoop-node

右键该创建的虚拟机,点击设置,进入设置页面,点击CD/DVD,选择使用ISO镜像文件,选择之前下载的镜像文件即可,点击确定
开启虚拟机,选择语言中文-简体中文,当然其他语言也可,点击继续;
点击安装源,进入之后选择done;
软件选择:GNOME桌面,图形化界面;
分区自动分区也可,自定义配置分区也可;
配置完成后开始安装系统,安装过程中会出现用户设置,自行设置好Root的密码,以及用户账户和密码;
安装完成后点击重启;
重启后,出现初始设置界面,若未接受许可证,点击进去选择接受许可;
并设置一下网络,打开连接开关;
好了之后,点击完成配置,等待即可登录
打开终端,可以通过命令ifconfig查看自身IP信息;
ping一下宿主机ip,若ping通,则说明安装设置正常;也可以在虚拟机打开自带的浏览器,打开一个网页看看访问外网是否成功
3.关闭防火墙(关键)
1.在root账户下(若登录时不是root账户则切换成root账户),检查防火墙状态
#firewall-cmd --state
2.需要关闭防火墙
#systemctl stop firewalld.service
3.再次查看防火墙状态,查看是否状态已经是not running
#firewall-cmd --state
4.禁止开机启动防火墙
#systemctl disable firewalld.service
二、安装jdk
1.卸载镜像自带jdk
1.通过xshell工具,连接虚拟机(root账户、虚拟机IP通过终端ifconfig查看)
2.通过命令下面命令查看系统自带jdk
rpm -qa | grep Java
3.通过下面命令删除系统自带的jdk,删除的是类似java-1.*-opejdk-**的文件(一般为四个)
rpm -e --nodeps 系统自带的jdk名
如:
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
4.删完后,再重复步骤2查看是否删除
2.安装自己的jdk
通过 cd /usr/local/ 进入local目录;
通过 ls 查看当前目录已有的非隐藏文件;
之后通过 mkdir java 创建Java目录,用于存放自己的jdk;
创建好之后,通过 cd java 进入Java目录;
通过 yum -y install lrzsz 命令安装:在线导入安装包的插件;
成功后输入rz 并回车,就会弹出文件选择窗口,选择自己jdk安装包,打开,就会进入文件传输的界面;
传输成功后,ls 命令查看Java目录下的是否有安装包了;
有了之后通过 tar -zxvf 安装包名 命令解压jdk,如:
tar -zxvf jdk-8u11-linux-x64.tar.gz
解压之后,通过 ls 命令查看会发现java目录下出现了jdk的文件夹,这里可以通过命令rm -f jdk-8u11-linux-x64.tar.gz 删除安装包 ,也可以不删;
之后配置环境变量:
通过命令 vim /etc/profile 打开profile文件配置环境变量,打开之后按 i 进入insert(插入模式),在文件末尾加上以下内容(位置和名称按你实际安装的来):
export JAVA_HOME=/usr/local/java/jdk1.8.0_11
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
添加完成后,按Esc退出到非插入模式,再按Shift + :,之后输入wq 并回车,即保存成功;
保存完后,输入 source /etc/profile回车,使得刚才的配置生效;
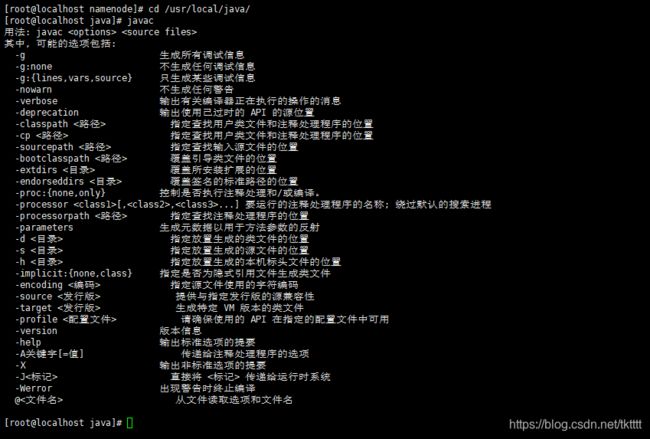
测试是否安装成功,输入 Javac 命令回车,如果返回如下信息则说明编辑成功
再通过命令 Java -version 查看Java版本信息,如果出现下图信息则说明安装成功

3.配置多机器间免密登录
配置目的是在配置hadoop一主多从的分布式环境时,主从之间能够无障碍通信,输入以下命令,按回车
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #生成密钥对
会在/root/.ssh文件夹下生成一对密钥,即公钥和私钥,如下图:
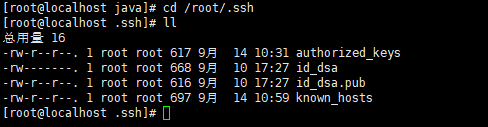
公钥相当于锁,私钥相当于钥匙,只要我们将公钥(锁)写入别的机器上authorized_keys文件中,我们就能用私钥(钥匙)进行免密登陆别的机器了,接着输入以下命令,将公钥写入authorized_keys文件中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #将公钥写入authorized_keys文件
这样一来,当后续我们使用VMware虚拟机克隆功能克隆生成其他节点时,这几个虚拟机中authorized_keys文件中写入相同的公钥,并且都与公钥(锁)对应的相同的私钥(钥匙),自然能够进行相互的免密登陆了
三、搭建Hadoop集群
此处集群搭建我们不按host映射来,直接使用的ip
1.hadoop安装
首先,在/usr/local目录下创建hadoop文件夹,之后将hadoop安装到这里,安装之后进入hadoop文件夹:
cd /root #进入/root文件夹
mkdir hadoop #创建hadoop文件夹
cd software #进入hadoop文件夹
之后,使用rz命令从本地将Hadoop安装包(本文使用的是hadoop-2.7.4.tar.gz)上传到该目录,与安装jdk时一样,传输完成之后进行解压:
tar -zvxf hadoop-2.7.4.tar.gz #解压hadoop到当前目录
同时将hadoop加入环境变量,打开/root/.bash_profile文件:
vi /root/.bash_profile #打开文件
如同安装jdk配置环境变量时一样进行操作,添加如下内容(路径按实际安装来):
export JAVA_HOME=/usr/local/java/jdk1.8.0_261
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.4
保存后,执行以下命令使其生效:
source /root/.bash_profile
然后执行hadoop version来检查是否配置成功,若出现如下图这样的信息说明配置成功:

2.配置修改
- 配置JAVA_HOME
hadoop-env.sh
mapred-env.sh
yarn-env.sh
对上述三个文件(位置都在Hadoop安装目录下的etc/hadoop下)都加入:
export JAVA_HOME=JAVA_HOME=/usr/local/java/jdk1.8.0_261
- 修改hdfs-site.xml文件
hdfs-site.xml文件位置如下:hadoop安装目录下的etc/hadoop目录下,打开该文件:
cd /usr/local/hadoop/hadoop-2.7.4/etc/hadoop/ #进入到该目录下
vi hdfs-site.xml #打开该文件
在hdfs-site.xml文件configuration标签内,添加如下内容:
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/data/hadoop/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/data/hadoop/datanodevalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/usr/data/hadoop/journalnodevalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-checkname>
<value>falsevalue>
property>
configuration>
创建上述的目录文件:
cd /usr
mkdir data
cd data
mkdir hadoop
cd hadoop
mkdir namenode datanode journalnode
- 修改core-site.xml文件
该文件在相同的目录下,将core-site.xml文件中configuration标签修改为下述内容(其中IP为自己实际虚拟机IP,前面咱们一直没有将虚拟机IP设为静态IP,用的自有分配的IP,之后下文设置,原因就不说了):
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://192.168.88.129:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/data/hadoop/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>192.168.88.129:2181,192.168.88.130:2181,192.168.88.131:2181value>
property>>
configuration>
- 修改mapred-site.xml文件
也在同目录下,如果没有,则创建:
cp mapred-site.xml.template mapred-site.xml
编辑:
vi mapred-site.xml
在文件标签configuration中输入:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
- 修改yarn-site.xml文件,将yarn-site.xml文件中configuration标签中内容修改为下述内容,IP应与core-site.xml中的一致:
<property>
<name>yarn.resourcemanager.addressname>
<value>192.168.88.129:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>192.168.88.129:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>192.168.88.129:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>192.168.88.129:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>192.168.88.129:8088value>
property>
- 修改slaves文件,指定datanode
该slaves文件在相同的目录下,将文件修改为下述内容(看实际需要,自由添加配置IP,有几个说明有几个datanode):
192.168.88.129 #主节点IP(最好加上,让主节点启动datanode)
#当然此处是节省虚拟机资源,实际应用另说
#不加的话最好多配一台子节点
#(即去掉129主节点这台,添加192.168.88.132,下文也自行进行相应更改)
#(所以是一台主节点namenode三台子节点datanode,即总共四台虚拟机)
#(本文是加上了主节点处的datanode和两台子节点的datanode,共三台)
#此处配置三台datanode是为了符合上述hdfs-site.xml配置中设置的副本数
#同时,也是为了之后的Hadoop集群动态缩容作准备
#当副本数为3,且服役的节点datanode小于等于3时,
#缩容的时候,节点是无法退役成功的,需要修改副本数后才能退役
192.168.88.130
192.168.88.131
此处可以设置一下系统快照做个备份,点击其中图标拍摄此虚拟机的快照(设置快照时,虚拟机要求处于关机状态),具体步骤这里就不赘述,可以查看设置快照和克隆
![]()
完成快照后,会在虚拟机系统桌面形成一个光盘,即上文中系统桌面里的图标
3.克隆并配置其他虚拟机
1.关闭虚拟机
克隆虚拟机前,需要将克隆原虚拟机关闭,选择VMware菜单下:虚拟机->电源->关闭虚拟机,将虚拟机关闭
2.开始克隆
克隆节点1,选择VMware菜单下:虚拟机->管理->克隆,启动虚拟机克隆向导

点击下一步:
可以按照虚拟机中的当前状态,也可以按现有快照,点击下一步:
选择创建完整克隆,下一步:

自定义名称和位置,位置最好是与原虚拟机别放同一个目录,避免冲突,点击完成,等待克隆完成,之后会在会在VMware主界面生成克隆的虚拟机实例,如下图所示:

3.重复克隆
按之前配置的slaves文件中的个数,进行反复克隆
4.配置
此处将原虚拟机称为node,后来克隆的两台虚拟机分别称为node1、node2(只配置了两台),单纯为了之后书写方便,无实际意义;
VMware中通过用户账号进入node的系统界面,点击图中的有线设置:
点击下图中有线中齿轮图标:
打开后,点击IPv4,选择手动,配置好自己的IP,如下图:
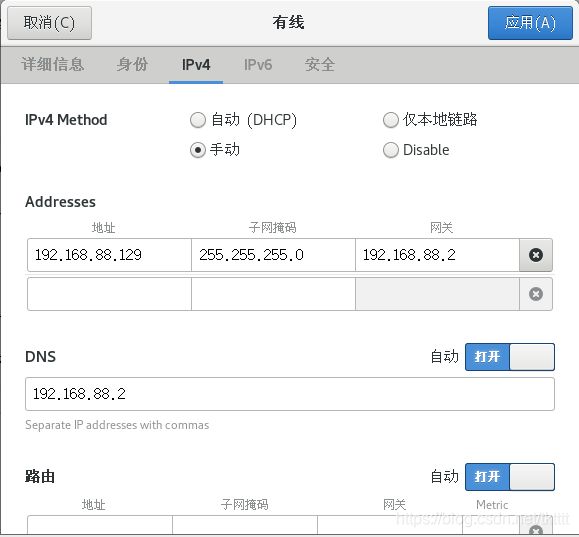
IP应与core-site.xml中配置的一致,且应遵循以下配置范围:192.168.88.129-192.168.88.254之间,该范围由以下图中得来:
点击VMware菜单栏中的编辑中的虚拟网络编辑器,打开DHCP设置,查看到起始IP与结束IP
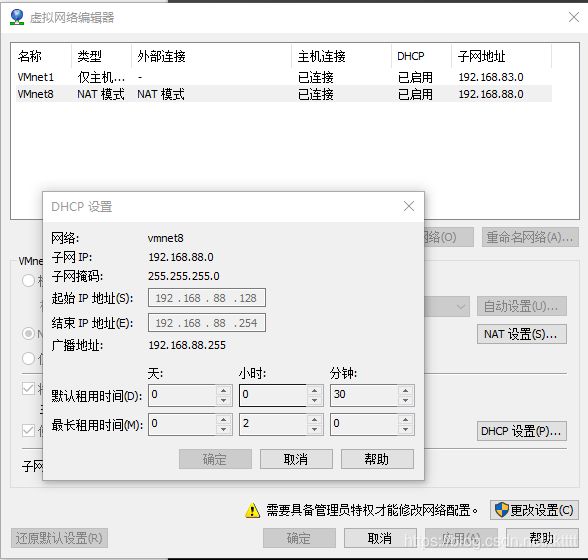
node设置好后,node1与node2(即克隆出来的两台虚拟机)也是同理设置IP,IP分别应与slaves文件中配置的IP一致,即下图:(之后将129称为node,130为node1,131为node2)

4.启动测试
1.格式化
在node(原虚拟机)上,用root账户格式化namenode
hadoop namenode –format
2.启动测试
命令启动hdfs:start-dfs.sh #启动hdfs
命令启动yarn:start-yarn.sh #启动yarn
也可以直接运行:start-all.sh #启动全部
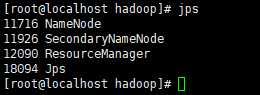
测试是否启动成功:在各个虚拟机上使用jps命令;
node上应该如图:
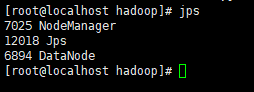
node1和node2(即其他虚拟机上)应该如图:
打开浏览器,分别输入192.168.88.129:50070,192.168.88.129:8088(此处IP应为实际设置的node的IP)进行查看,分别如图:
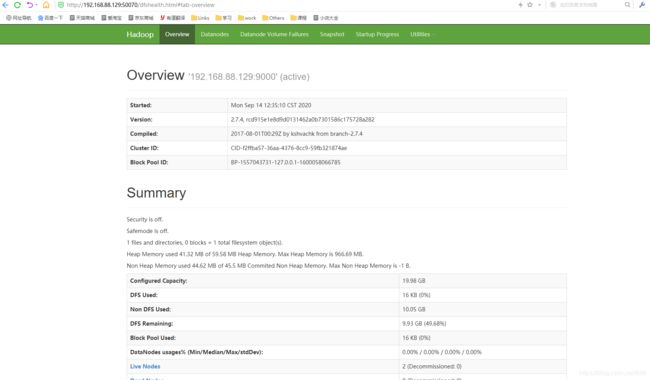
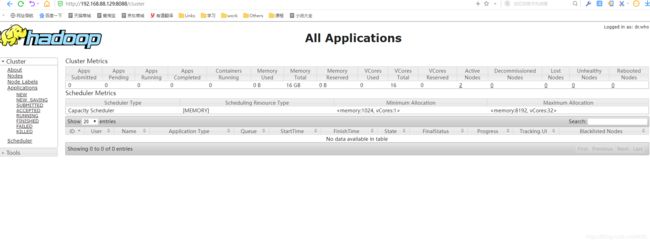
成功访问,且192.168.88.129:50070的页面处live nodes应为slaves中配置的个数(即克隆次数),本文此处为2,说明配置成功。
5.可能遇到的问题
1.启动hadoop,报错Error JAVA_HOME is not set and could not be found:
解决办法:
(1)检查JAVA_HOME是否配置正确(伪分布式环境)
输入java –version,查看jdk是否安装成功;
输入export,查看jdk环境变量是否设置成功;
(2)在集群环境下,即使各结点都正确地配置了JAVA_HOME,也会报该错误
解决办法:
在hadoop-env.sh(文件位置:hadoop安装目录下的etc/hadoop下)中,再显示地重新声明一遍JAVA_HOME,将文件中的原本的JAVA_HOME注释掉改为下图中的(路径按实际jdk安装位置来):
# export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/java/jdk1.8.0_261
将各虚拟机上的该文件均更改保存后,停止Hadoop(命令stop-all.sh),在node上进入到/usr/data/hadoop/namenode/中将产生的current文件夹删除,若是没有产生则省略这操作;
分别在node1和node2上进入/usr/data/hadoop/datanode/中将current文件夹删除,没有则省略这操作,然后重新进行4.启动测试中的步骤
2.启动hadoop时遇到Host key verification failed:
可以参考此处
3.hadoop搭建好,启动服务后,无法从web界面访问50070:
其实是防火墙未关闭,参考上文的关闭防火墙步骤
4.hadoop 不使用hostname,使用ip遇到的问题(Datanode denied communication with namenode because hostname cann)及解决方案:
也就是说在namenode的hdfs-site.xml 里面添加下文代码即可:
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-checkname>
<value>falsevalue>
property>
参考此处
将各虚拟机上的该文件均更改保存后,停止Hadoop(命令stop-all.sh),在node上进入到/usr/data/hadoop/namenode/中将产生的current文件夹删除,若是没有产生则省略这操作;
分别在node1和node2上进入/usr/data/hadoop/datanode/中将current文件夹删除,没有则省略这操作,然后重新进行4.启动测试中的步骤
四、Zookeeper集群搭建
1.下载安装zookeeper安装包
zookeeper版本需要能与Hadoop版本兼容
创建文件夹,将安装包上传至此并解压:
mkdir /usr/local/zookeeper
tar -zxvf 安装包名
如tar -zxvf zookeeper-3.4.14.tar.gz
之后自行创建一个文件夹data用于保存zookeeper产生的数据,一个文件夹logs用于输出日志,最好与Hadoop的数据文件夹放在同一个目录下,方便寻找:
cd /usr/data/zookeeper/
mkdir data logs
2.文件配置
编辑环境变量:
vi /etc/profile
追加内容:
export ZOOKEEPER_HOME=/home/bigData/zookeeper-3.4.10
修改PATH:在PATH项的$PATH前面追加:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
source /etc/profile 使之生效
配置
进入安装目录下的conf目录下进行配置:
cd /usr/local/zookeeper/zookeeper-3.4.14/conf/
cp zoo_sample.cfg zoo.cfg#默认是没有zoo.cfg的所有要将zoo_sample.cfg复制一份,改名
vim zoo.cfg#配置zoo.cfg
进行修改:
#修改data文件目录(即上面创建的文件夹)
dataDir=/usr/data/zookeeper/data
#修改log文件目录(即上面创建的文件夹)
dataLogDir=/usr/data/zookeeper/logs
#zookeeper集群的节点,添加到末尾
server.1=192.168.88.129:2888:3888
server.2=192.168.88.130:2888:3888
server.3=192.168.88.131:2888:3888
新建并编辑myid文件
在dataDir目录下新建myid文件,输入一个数字(node为1,node1为2,node2为3),对应上面的(server.1、server.2、server.3):
touch myid
vi myid
输入相应的数字并保存
然后可以使用scp命令进行远程复制,只不过要修改每个节点上myid文件中的数字;或者每个节点进行反复配置
scp -r /usr/data/zookeeper/data/myid 192.168.88.130:/usr/data/zookeeper/data
scp -r /usr/data/zookeeper/data/myid 192.168.88.131:/usr/data/zookeeper/data
然后把整个zookeeper文件发到每个节点,也可以自己在每个节点上反复重新操作
scp -r /usr/local/zookeeper/zookeeper-3.4.14 192.168.88.130:/usr/local/zookeeper
scp -r /usr/local/zookeeper/zookeeper-3.4.14 192.168.88.131:/usr/local/zookeeper
3.启动测试
在每个节点上都运行下面命令行(node、node1、node2)
zkServer.sh start
运行完后,用命令查看:
zkServer.sh status
结果为:每台节点分别为follower、follower、leader(无顺序)
五、Hbase集群搭建
1.准备工作(下载与时间同步)
官网下载合适的hbase版本,要求能与上面安装的zookeeper、hadoop版本兼容
- 安装hbase之前必须要保证的是三台服务器的时间保持同步,推荐使用ntp完成时间配置(安装ntp:yum install ntp)
方法一:在虚拟机上安装ntp服务
yum install -y ntpdate
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate -u ntp.api.bz
方法二:设置虚拟机
设置虚拟机,找到【选项】——【vmwaretools】 ——【点击将客户端时间与主机同步】——【确定】
2.安装解压
#创建安装文件夹
mkdir /usr/local/hbase
#上传文件到此位置
#解压
tar -zxvf hbase-1.4.13-bin.tar.gz
3.环境变量配置
编辑vim /etc/profile文件
vim /etc/profile
#文末添加:
export HBASE_HOME=/usr/local/hbase/hbase-1.4.13
#修改PATH项:在PATH项的$PATH 末尾添加(记住":"不能少)
:$HADOOP_HOME/bin
保存,退出,source /etc/profile使之生效。
Hbase的配置文件在conf目录下,首先复制hadoop的hdfs-site.xml到conf目录下(cp命令即可)
4.文件配置
进入conf目录:
- 修改hbase-env.sh
vim hbase-env.sh
修改内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_261 #Java安装路径
export HBASE_MANAGES_ZK=false #由HBase负责启动和关闭Zookeeper
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/usr/local/hbase/hbase-1.4.13/conf:/usr/local/hbase/hbase-1.4.13/lib:/usr/local/hadoop/hadoop-2.7.4/etc/hadoop
保存退出
- 修改hbase-site.xml
修改configuration标签内容:
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://192.168.88.129:9000/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.tmp.dirname>
<value>/usr/data/hbase/tmpvalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>192.168.88.129,192.168.88.130,192.168.88.131value>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
configuration>
其中hbase.zookeeper.quorum配置的是之前安装好的zookeeper集群,对应即可
创建上面的hbase.tmp.dir文件:
cd /usr/data
mkdir hbase
mkdir hbase/tmp
- 配置conf/regionservers
加入下面内容(即主、从节点的IP):
192.168.88.129
192.168.88.130
192.168.88.131
每个节点都需这么配置,所以也可以直接发送到其他节点,再进行相对修改即可:
scp -r /usr/local/hbase/hbase-1.4.13/ 192.168.88.130:/usr/local/hbase/
scp -r /usr/local/hbase/hbase-1.4.13/ 192.168.88.131:/usr/local/hbase/
六、启动Hbase
按顺序来:
1.启动zookeeper
在每个节点上运行:
zkServer.sh start (启动)
zkServer.sh stop (终止)
查看当前zookeeper的运行状态:(一个leader,其余follower)
zkServer.sh status
启动第一台后状态可能不对,不要紧张,当三台全启动后就好了
2.启动Hadoop
所有节点执行:
hadoop-daemon.sh start journalnode
校验命令,查看进程:
jps
2.1格式化HDFS
主节点执行命令(最好自己手敲,复制可能出错):
hdfs namenode -format
或者:
hadoop namenode -format
2.2启动HDFS
仅在主节点执行命令:
start-dfs.sh
2.3启动YARN
同样只在主节点:
start-yarn.sh
2.4Hadoop启动校验
见上文Hadoop集群搭建中的 启动测试 部分
3.Hbase启动
仅在主节点(node)执行
start-hbase.sh
在各个节点用jps查看进程是否存在:
- 主节点为HMaster/HRegionServer,从节点为HRegionServer
注意:在哪个主机执行start命令,则该主机为master
单独启动Hregionserver的命令为:
hbase-daemon.sh start regionserver
hbase默认的web界面地址为:http://master-ip:16010:
本文为:http://192.168.88.129:16010
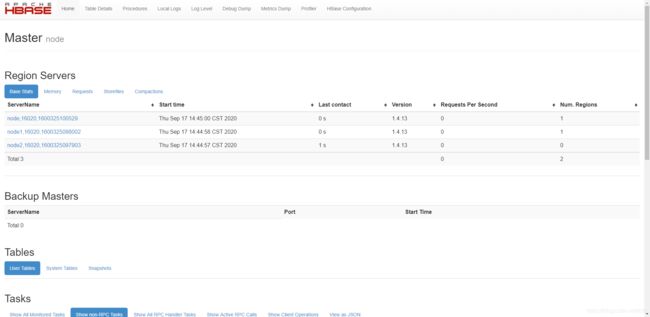
4.问题
本文一直使用的IP,前面一直没事,但启动Hbase时会出现问题
查看regionserver的log日志:
regionserver.HRegionServer:reportForDuty failed;sleeping and then retrying.
regionserver.HRegionServer:reportForDuty to master=localhost,6000,139xxxxxx with port=60020,startcode=139xxxxxx
regonserver.HRegionServer:error telling master we are up
java.net.ConnectException:Connection refused
注意到master=localhost , 但这不对,master不可能等于localhost
查看三台节点的主机名,发现都为localhost,因而猜想是否此处有问题,更改每台主机名:
通过命令行进行更改:IP是129的主机名改为node,130改为node1,131改为node2
#129上执行:
hostnamectl set-hostname node
#130上执行:
hostnamectl set-hostname node1
#131上执行:
hostnamectl set-hostname node2
在每个节点使用hostname命令查看是否改名成功
并为每个节点添加映射:
#修改文件/etc/hosts
vi /etc/hosts
加入以下内容:
192.168.88.129 node
192.168.88.130 node1
192.168.88.131 node2
之后可以测试一下ping 主机名是否可以ping通,如,在主节点尝试:ping node1
都可以之后,重新进行步骤3.Hbase启动,启动成功
七、Hive安装配置
1.准备工作
在前文基础上,继续安装MySQL
数据库包下载:官网地址
下载rpm类型安装包(注意版本选择),例如本文选择的:
mysql-community-common-5.7.31-1.el7.x86_64.rpm
mysql-community-libs-5.7.31-1.el7.x86_64.rpm
mysql-community-client-5.7.31-1.el7.x86_64.rpm
mysql-community-server-5.7.31-1.el7.x86_64.rpm
- MySQL下载安装可以参考此处:MySQL下载参考
卸载系统自带的mariadb-lib:
查看mariadb版本
rpm -qa|grep mariadb
卸载mariadb(改成自身的实际版本)
rpm -e mariadb-libs-5.5.65-2.el7.x86_64 --nodeps
安装MySQL:
mysql有依赖关系,安装顺序是 common、lib、client、server:
rpm -ivh mysql-community-common-5.7.31-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.31-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.31-1.el7.x86_64.rpm
rpm -ivh mmysql-community-server-5.7.31-1.el7.x86_64.rpm
安装完成后,启动mysql:systemctl start mysqld
设置:
查看安装时自动设置的初始密码:位置应该在/var/log/mysqld.log
之后通过初始密码登录MySQL:mysql -uroot -p初始密码
登录成功后会要求修改密码,按要求进行即可(此时要按其默认规则来),而为了设置简单的密码,如123456,之后要进行权限更改(可以查看下文参考链接),然后再修改密码为123456:
set password for root@localhost = password('123456'); // 设置root密码为123456;
此后再设置授权打开远程连接update user set host = '%' where user ='root'; //配置可远程登录
刷新授权flush privileges; //更新权限
之后重启MySQL服务ssystemctl restart mysqld
设置自启(可以不设置)systemctl enable mysqld
- MySQL安装设置可以参考此处:MySQL设置参考
2.安装hive
到官网下载相应适配版本的hive安装包,本文选择的是:apache-hive-2.3.7-bin.tar.gz
上传到/usrlocal/hive目录下(自行创建的目录),之后解压:
tar -zxvf apache-hive-2.3.7-bin.tar.gz
配置环境变量
vi /etc/profile
#hive
export HIVE_HOME=/usr/local/hive/apache-hive-2.3.7-bin
export PATH=$PATH:$HIVE_HOME/bin #在path后添加即可
使之生效:source /etc/profile
配置完成可输入hive --version 查看版本
配置hive:
- 修改hive-env.sh文件
切换到/usr/local/hive/apache-hive-2.3.7-bin/conf目录下,若没有hive-env.sh,复制hive-env.sh.template 为 hive-env.sh:
cp hive-env.sh.template hive-env.sh #复制
vi hive-env.sh #打开编辑
修改或添加:
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.4 #hadoop路径
export HIVE_CONF_DIR=/usr/local/hive/apache-hive-2.3.7-bin/conf #hive的conf路径
export HIVE_AUX_JARS_PATH=/usr/local/hive/apache-hive-2.3.7-bin/lib #hive的jar包路径
export JAVA_HOME=/usr/local/java/jdk1.8.0_261 #jdk安装路径
- 配置hive-site.xml
同目录下,初次解压发现hive-site.xml配置文件并没有,此时需要我们自己创建并配置hive-site.xml,复制hive-default.xml.template 为 hive-site.xml:
cp hive-default.xml.template hive-site.xml
编辑该文件vi hive-site.xml,加入下述内容:
<property>
<name>hive.metastore.warehouse.dirname>
<value>/opt/hive/warehousevalue>
property>
<property>
<name>hive.metastore.localname>
<value>truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://192.168.88.129:3306/hive_db?createDatabaseIfNotExist=truevalue> //数据库所在主机的IP
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
并搜索上述的每一项,将文件原有的每一项删除或者注释;
搜索derby,将含有该词的每一项都注释或者删除,注释里有的不算;
然后将配置文件中所有的${system:java.io.tmpdir}更改为 /usr/hive/tmp (如果没有该文件则创建),并将此文件夹赋予读写权限,将${system:user.name}更改为 实际用户root;
其他${...}也适当删改;
保存退出
- 复制hive-exec-log4j2.properties.template 为 hive-exec-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
- 复制hive-log4j2.properties.template为hive-log4j2.properties
cp hive-log4j2.properties.template hive-log4j2.properties
下载mysql驱动(本文为mysql-connector-java-5.1.49-bin.jar)放入/usr/local/hive/apache-hive-2.3.7-bin/lib包中
初始化(第一次启动):
schematool -initSchema -dbType mysql
若最后有下面字样,则说明成功:
schemaTool completed
且查看MySQL数据库,可以发现其中创建了hive_db库
启动:
要求:前面均已按六、启动hbase 步骤启动了所有
hive
启动顺序:
#zookeeper
#bin目录下
./zkServer.sh start
#hadoop
hadoop-daemon.sh start journalnode
start-all.sh(即:start-dfs.sh start-yarn.sh)
#hbase
#bin目录下
./start-hbase.sh
#hive
hive
nohup hiveserver2 2>/usr/data/hive/log/hiveserver2/hiveserver.err &
nohup hive --service metastore 2>/usr/data/hive/log/metastore/metastore.err &
或者
nohup hiveserver2 >/usr/data/hive/log/hiveserver2/hiveserver.log &
nohup hive --service metastore >/usr/data/hive/log/metastore/metastore.log &
关闭顺序:
#hive
jps命令找到Runjar进程kill掉
或
ps -ef | grep hive
kill -9 进程 #杀掉
#hbase
#bin目录下
./stop-hbase.sh
#hadoop
hadoop-daemon.sh stop journalnode
stop-all.sh
#zookeeper
#bin目录下
./zkServer.sh stop
测试hive:
hive #启动进入hive
show databases; #展示所有数据库
create database test_hive; #创建test_hive数据库
show databases; #展示所有数据库
use test_hive; #使用数据库test_hive
show tables; #展示当前该数据库下所有数据表
create table test_users(id int,name string); #创建test_users数据表
show tables; #展示当前该数据库下所有数据表
insert into test_users values(1,"aaa"); #插入数据
select * from test_users; #查询test_users表所有数据
若是执行语句时,卡住不动,可以将所有服务停止,然后在Hadoop安装目录下的etc/hadoop目录下,修改yarn-site.xml,添加如下内容应当会有所缓解:
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2000value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2000value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
之后依次重新启动服务,其中Hadoop最好是删除原有的重新格式化启动
八、Kylin搭建
1.安装
下载相应适配版本的安装包:官网地址
上传到新建文件目录/usr/local/kylin下,并解压:
tar -zxvf apache-kylin-3.1.0-bin-hbase1x.tar.gz
2.配置环境变量
vi /etc/profile
#加入以下内容
export KYLIN_HOME=/usr/local/kylin/apache-kylin-3.1.0-bin-hbase1x
#path后添加
export PATH=$PATH:$KYLIN_HOME/bin
使之生效:source /etc/profile
3.配置kylin
检查运行环境:
Kylin 运行在 Hadoop 集群上,对各个组件的版本、访问权限及 CLASSPATH 等都有一定的要求,为了避免遇到各种环境问题,您可以运行 $KYLIN_HOME/bin/check-env.sh脚本来进行环境检测,如果您的环境存在任何的问题,脚本将打印出详细报错信息。如果没有报错信息,代表您的环境适合 Kylin 运行(此段来自kylin官网文档)
若有问题,则按日志输出解决即可,按前文一步步来是没问题的,若出现问题,请回顾前文比对哪里有误。
HDFS 目录结构:
Kylin 会在 HDFS 上生成文件,根目录是 “/kylin/”, 然后会使用 Kylin 集群的元数据表名作为第二层目录名,默认为 “kylin_metadata” (可以在conf/kylin.properties中定制).
通常, /kylin/kylin_metadata 目录下会有这么几种子目录:cardinality, coprocessor, kylin-job_id, resources, jdbc-resources.
- cardinality: Kylin 加载 Hive 表时,会启动一个 MR 任务来计算各个列的基数,输出结果会暂存在此目录。此目录可以安全清除。
- coprocessor: Kylin 用于存放 HBase coprocessor jar 的目录;请勿删除。
- kylin-job_id: Cube 计算过程的数据存储目录,请勿删除。 如需要清理,请遵循 storage cleanup guide.
- resources: Kylin 默认会将元数据存放在 HBase,但对于太大的文件(如字典或快照),会转存到 HDFS 的该目录下,请勿删除。如需要清理,请遵循 cleanup resources from metadata
- jdbc-resources:性质同上,只在使用 MySQL 做元数据存储时候出现。
(此部分来自kylin官方文档,想详细了解的见官网)
部署 Kylin:
kylin.env.hdfs-working-dir:指定 Kylin 服务所用的 HDFS 路径,默认值为 /kylin,请确保启动 Kylin 实例的用户有读写该目录的权限
kylin.env:指定 Kylin 部署的用途,参数值可选 DEV,QA, PROD,默认值为 DEV,在 DEV 模式下一些开发者功能将被启用
kylin.env.zookeeper-base-path:指定 Kylin 服务所用的 ZooKeeper 路径,默认值为 /kylin
kylin.env.zookeeper-connect-string:指定 ZooKeeper 连接字符串,如果为空,使用 HBase 的 ZooKeeper
kylin.env.hadoop-conf-dir:指定 Hadoop 配置文件目录,如果不指定的话,获取环境中的 HADOOP_CONF_DIR
kylin.server.mode:指定 Kylin 实例的运行模式,参数值可选 all, job, query,默认值为 all,job 模式代表该服务仅用于任务调度,不用于查询;query 模式代表该服务仅用于查询,不用于构建任务的调度;all 模式代表该服务同时用于任务调度和 SQL 查询。
kylin.server.cluster-name:指定集群名称
(以上部分来自官网文档)详情:见此处
4.启动使用
使用 Kylin:
Kylin 启动后您可以通过浏览器 http://进行访问。
其中
初始用户名和密码是 ADMIN/KYLIN。
服务器启动后,您可以通过查看 $KYLIN_HOME/logs/kylin.log 获得运行时日志。
停止 Kylin:
运行 $KYLIN_HOME/bin/kylin.sh stop 脚本来停止 Kylin,界面输出如下:
Retrieving hadoop conf dir...
KYLIN_HOME is set to /usr/local/apache-kylin-2.5.0-bin-hbase1x
Stopping Kylin: 25964
Stopping in progress. Will check after 2 secs again...
Kylin with pid 25964 has been stopped.
您可以运行ps -ef | grep kylin来查看 Kylin 进程是否已停止。
(以上部分来自官方文档)
启动集群:
启动顺序:
1、启动zookeeper
./zkServer.sh start
2、启动journalnode
hadoop-daemon.sh start journalnode
3、启动HDFS
./start-dfs.sh
4、启动YARN集群
./start-yarn.sh
5、启动HBase集群
./start-hbase.sh
6、启动 metastore
nohup hive --service metastore &
或者
nohup hive --service metastore >/usr/data/hive/log/metastore/metastore.log &
7、启动 hiverserver2
nohup hive --service hiveserver2 &
或者
nohup hive --service hiveserver2 >/usr/data/hive/log/hiveserver2/hiveserver.log &
8、启动Yarn history server
mr-jobhistory-daemon.sh start historyserver
9、启动spark history server【可选,本文未装spark】
sbin/start-history-server.sh
10、启动kylin
./kylin.sh start
登录Kylin:
http://node:7070/kylin
url http://IP:7070/kylin
默认用户名:ADMIN
默认密码:KYLIN
使用:
参考另一位博主的文章:此处
为何不运行kylin自带的demo,因为虚拟机配置不够,运行耗时太长,因而最好用前文hive中自行建立的数据库与数据表等数据
5.问题
在上面使用过程中,可能遇到:
1.web页面中kylin在build报错10020拒绝链接错误
报错信息:
org.apache.kylin.engine.mr.exception.MapReduceException: Exception: java.net.ConnectException: Call From dxt102/192.168.1.102 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
java.net.ConnectException: Call From dxt102/192.168.1.102 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.kylin.engine.mr.common.MapReduceExecutable.doWork(MapReduceExecutable.java:173)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:164)
解决方法:修改Hadoop配置文件mapred-site.xml
cd /usr/local/hadoop/hadoop-2.7.4/etc/hadoop
vi mapred-site.xml
加入如下内容:
<property>
<name>mapreduce.jobhistory.addressname>
<value>192.168.88.129:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>192.168.88.129:19888value>
property>
并停止kylin,在主节点上启动jobhistory:
mr-jobhistory-daemon.sh start historyserver
再重新启动kylin,并重新运行程序,运行成功
2.其他问题:
笔者未遇到,这里放两篇其他博主的参考文章:
Kylin常见错误及解决方法
kylin安装问题记录
全文列出的参考文章,仅为提供方便,若有侵犯,请联系删除
九、Hadoop集群动态扩容、缩容
1.动态扩容
1.1准备工作
克隆一台虚拟机,也可以是全新的(只要安装了jdk即可,可以参考最初的虚拟机安装部分);
在新的虚拟机上修改hostname为node3:
#在新的虚拟机上执行
hostnamectl set-hostname node3
并为所有节点添加映射,将集群所有节点hosts配置进去,(集群所有节点保持hosts文件统一):
#修改文件/etc/hosts
vi /etc/hosts
加入以下内容:
192.168.88.129 node
192.168.88.130 node1
192.168.88.131 node2
192.168.88.132 node3
之后可以测试一下ping 主机名是否可以ping通,如,在新节点尝试:ping node1
设置NameNode到DataNode的免密码登录(ssh-copy-id命令实现)
修改主节点(node)slaves文件,添加新增节点的ip信息(集群重启时配合一键启动脚本使用),最好是修改每一台节点的slaves文件:
192.168.88.129
192.168.88.130
192.168.88.131
192.168.88.132
在node3节点上创建Hadoop安装文件夹:
cd /usr/local
mkdir hadoop
创建存储文件夹:
cd /usr
mkdir data
cd data
mkdir namenode datanode tmp journalnode
复制其他子节点上的hadoop安装文件到新节点node3上:
#在node2上执行
scp -r /usr/local/hadoop/hadoop-2.7.4/ 192.168.88.132:/usr/local/hadoop/
配置node3上的环境变量:
#打开文件
vi /etc/profile
#加入以下内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_261
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.4
#保存后运行,使之生效
source /etc/profile
1.2添加datanode
在namenode所在机器(本文即node)上,Hadoop的安装目录下的/etc/hadoop下创建dfs.hosts文件:
cd /usr/local/hadoop/hadoop-2.7.4/etc/hadoop
touch dfs.hosts
vi dfs.hosts
#加入如下内容:
192.168.88.129
192.168.88.130
192.168.88.131
192.168.88.132
#或用主机名也可
node
node1
node2
node3
同目录下,在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts属性:
vi hdfs-site.xml
加入以下内容:
<property>
<name>dfs.hostsname>
<value>/usr/local/hadoop/hadoop-2.7.4/etc/hadoop/dfs.hostsvalue>
property>
dfs.hosts属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上(node3)单独启动datanode:
hadoop-daemon.sh start datanode
然后去http://192.168.88.129:50070上刷新查看:
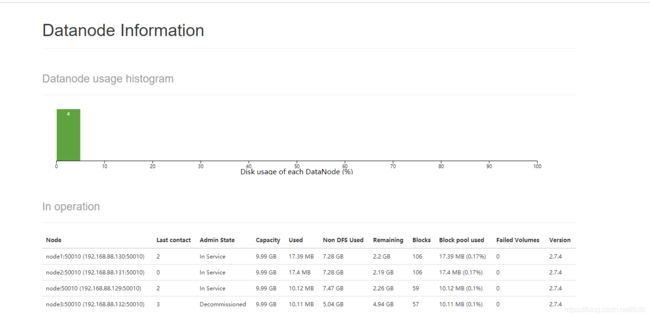
可以看到其中node3已经有了,其Admin State也应该为In Service,笔者图中为Decommissioned是因为已经操作过缩容了
1.3datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即运行:
hdfs dfsadmin -setBalancerBandwidth 67108864即可
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer:
start-balancer.sh -threshold 5,等待集群自均衡完成即可。
1.4添加nodemanager
在新的机器上(node3)单独启动nodemanager:
yarn-daemon.sh start nodemanager
然后在ResourceManager所在机器(node),通过yarn node -list查看集群情况:

2.动态缩容
2.1添加退役节点
在namenode所在服务器(node)的hadoop配置目录etc/hadoop下创建dfs.hosts.exclude文件,并添加需要退役的主机名称:
vi dfs.hosts.exclude
#加入需要退役的主机名称或者IP
#本文为:
192.168.88.132
dfs.hosts.exclude属性的意义:命名一个文件,其中包含不允许连接到namenode的主机列表。必须指定文件的完整路径名。如果值为空,则不排除任何主机。
- 修改hdfs-site.xml
在namenode机器(node)的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性:
vi hdfs-site.xml
加入以下内容:
<property>
<name>dfs.hosts.excludename>
<value>/usr/local/hadoop/hadoop-2.7.4/etc/hadoop/dfs.hosts.excludevalue>
property>
- 修改mapred-site.xml
在namenode机器(node)的mapred-site.xml配置文件中增加mapred.hosts.exclude属性
vi mapred-site.xml
加入以下内容:
<property>
<name>mapred.hosts.excludename>
<value>/usr/local/hadoop/hadoop-2.7.4/etc/hadoop/dfs.hosts.excludevalue>
<final>truefinal>
property>
2.2刷新集群
在namenode所在的机器(node)执行以下命令,刷新namenode,刷新resourceManager。
#刷新namenode
hdfs dfsadmin -refreshNodes
#刷新resourcemanager
yarn rmadmin -refreshNodes
或者:
hadoop dfsadmin -refreshNodes
然后去http://192.168.88.129:50070上刷新查看:
可以看到其中node3的Admin State为Decommissioned
也可以在node上查看node3状态:
hadoop dfsadmin -report
可以看到:
[root@node hadoop]# hdfs dfsadmin -report
Configured Capacity: 32191397888 (29.98 GB)
Present Capacity: 6933578724 (6.46 GB)
DFS Remaining: 6875751396 (6.40 GB)
DFS Used: 57827328 (55.15 MB)
DFS Used%: 0.83%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (4):
Name: 192.168.88.129:50010 (node)
Hostname: node
Decommission Status : Normal
Configured Capacity: 10726932480 (9.99 GB)
DFS Used: 10678272 (10.18 MB)
Non DFS Used: 8016035840 (7.47 GB)
DFS Remaining: 2163347788 (2.01 GB)
DFS Used%: 0.10%
DFS Remaining%: 20.17%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 9
Last contact: Wed Sep 23 16:09:05 CST 2020
Name: 192.168.88.132:50010 (node3)
Hostname: node3
Decommission Status : Decommissioned
Configured Capacity: 10726932480 (9.99 GB)
DFS Used: 10600448 (10.11 MB)
Non DFS Used: 5409497088 (5.04 GB)
DFS Remaining: 5306834944 (4.94 GB)
DFS Used%: 0.10%
DFS Remaining%: 49.47%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Sep 23 16:09:06 CST 2020
Name: 192.168.88.131:50010 (node2)
Hostname: node2
Decommission Status : Normal
Configured Capacity: 10726932480 (9.99 GB)
DFS Used: 18276352 (17.43 MB)
Non DFS Used: 7817105408 (7.28 GB)
DFS Remaining: 2354680140 (2.19 GB)
DFS Used%: 0.17%
DFS Remaining%: 21.95%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 9
Last contact: Wed Sep 23 16:09:05 CST 2020
Name: 192.168.88.130:50010 (node1)
Hostname: node1
Decommission Status : Normal
Configured Capacity: 10726932480 (9.99 GB)
DFS Used: 18272256 (17.43 MB)
Non DFS Used: 7814066176 (7.28 GB)
DFS Remaining: 2357723468 (2.20 GB)
DFS Used%: 0.17%
DFS Remaining%: 21.98%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 10
Last contact: Wed Sep 23 16:09:04 CST 2020
[root@node hadoop]#
可以看到node3的Decommission Status由Normal变为了Decommissioned(下线过程中是decomissioning状态)
等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
2.3停止进程
退役成功后,在node3上运行:
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop nodemanager
在namenode所在节点(node)上执行以下命令刷新namenode和resourceManager:
#刷新namenode
hdfs dfsadmin -refreshNodes
#刷新resourcemanager
yarn rmadmin -refreshNodes
#进行均衡负载
start-balancer.sh
之后去界面上查看:可以看到其状态为Dead;
使用hadoop dfsadmin -report也可以看到有dead的节点Dead datanodes (1)
侵删!此部分参考自:https://www.cnblogs.com/TiePiHeTao/p/11519773.html
十、hadoop集群客户端节点
1.问题的提出
为什么要配置客户端连接集群?
1.这涉及两个操作HDFS集群的方式集群内操作和集群外操作
2.其中集群内操作就是在集群内某个节点上操作
3.集群外操作就是用集群之外的client与nameNode进行通信,完成操作
但是其群内操作会造成数据倾斜问题,严重时会导致节点的宕机。
- 集群内操作,选择一台DataNode节点作为操作的对象,每次上传文件的时候根据备份机制,上传的文件会本身会上传到自己上,备份到其他的节点。
- 久而久之,此节点的磁盘和网络IO负载超过其他的节点,导致它的性能远远低于其他的节点,此时会造成数据倾斜,严重点说,它的负载很大,也就容易宕机,此时集群内还要备份它原来存储的内容,这就造成额外的磁盘和网络IO
- 还有是因为计算时间的问题,当发生数据倾斜的时候,因为某节点存放的数据量很大,所有当分布计算任务时,数据量大的节点需要的计算时间就更多,当此节点计算完毕时,这个任务才会执行完毕,所有这样很占用时间。
2.如何配置集群和户端?
- 把高可用的完全分布式集群配置的hadoop包发送给自己新建的一个客户端虚拟机,必须保证客户机能与集群通信。
- 更改客户机的hosts文件,配置Hadoop环境变量,方便操作集群
- 在客户端正常操作HDFS集群就行了。
(侵删!以上部分来自:https://blog.csdn.net/qq_39131779/article/details/83046057)
3.具体实现:
- 准备一台虚拟机,独立作为客户端,要求:能与其他集群正常通信,有java环境,静态IP。此处为方便之后都将客户端称为client
- 将集群Hadoop的配置文件发送复制到client的相应位置,比如/usr/local/hadoop
- 配置Hadoop环境变量:
vi /etc/profile,加入
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#Hadoop实际安装位置
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.4
使之生效source /etc/profile
- 验证
hadoop -version - 修改配置文件core-site.xml,修改 fs.default.name选项的值,使其指向集群master的地址
<property>
<name>fs.defaultFSname>
<value>hdfs://192.168.88.129:9000value>
property>
- 修改hadoop-env的jdk路径,按实际client的java路径来
- 修改client主机名,此处改为client:
#修改主机名
hostnamectl set-hostname client
#验证
hostname
- 配置client的主机名映射
vi /etc/hosts,加入集群所有的映射关系以及自身,最好也为集群所有节点添加下面client的映射关系,如:
192.168.88.129 node
192.168.88.130 node1
192.168.88.131 node2
192.168.88.132 cilent #实际client的IP
- 之后即可正常使用Hadoop命令访问操作HDFS集群
十一、Hive拓展客户端
1.准备工作
前文安装的hive只安装在了主节点node上,也就是单机模式,且服务端和客户端未分离,其实最好分离,但既然已经好了,本文也就不分离了,选择多拓展两台hive客户端节点
在前文安装的基础上将hive的安装及配置文件复制发送到另外两台节点,即node1和node2上:
#在 node1和 node2上都执行,创建hive安装的文件夹
cd /usr/local
mkdir hive
#在 node 上执行分别执行
scp -r /usr/local/hive/apache-hive-2.3.7-bin/ 192.168.88.130:/usr/local/hive/
scp -r /usr/local/hive/apache-hive-2.3.7-bin/ 192.168.88.131:/usr/local/hive/
然后在node1和node2节点上都加入hive的环境变量:
#打开
vi /etc/profile
#加入以下内容
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_HOME=/usr/local/hive/apache-hive-2.3.7-bin
#保存退出
#使之生效
source /etc/profile
2.配置变量
进入node1中hive的安装路径:
cd /usr/local/hive/apache-hive-2.3.7-bin/conf/
#打开配置文件hive-site.xml
vi hive-site.xml
删除以下内容:
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://192.168.88.129:3306/hivedb?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
修改或加入以下内容:
<property>
<name>hive.metastore.localname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://192.168.88.129:9083value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.description>
property>
在node2上同上操作配置一遍
3.验证
在node上启动服务:
按上文启动顺序:
1、启动zookeeper
./zkServer.sh start
2、启动journalnode(不启动也可)
hadoop-daemon.sh start journalnode
3、启动HDFS
./start-dfs.sh
4、启动YARN集群
./start-yarn.sh
5、启动HBase集群
./start-hbase.sh
6、启动 metastore
nohup hive --service metastore &
7、启动 hiverserver2
nohup hive --service hiveserver2 &
8、启动Yarn history server
mr-jobhistory-daemon.sh start historyserver
9、启动spark history server【可选,本文未装spark】
sbin/start-history-server.sh
10、启动kylin
./kylin.sh start
只要启动了1-6步即可,即hive --service metastore启动即可,若是原先就启动着就关掉再重新启动,
之后在node1和node2节点上输入hive命令并回车,即可进入hive操作行
十二、kylin集群搭建
1.配置
上文搭建的kylin其实也只是单节点的,这里开始集群搭建
在上文hive客户端节点之后(若是不想要客户端节点,其实只要将node上的hive安装配置文件发送到node1和node2上,再配置环境变量即可,不配其实也可以,因为hive其实不需要集群,可以说没有集群概念,kylin集群搭建需要的只是hive的环境支持,所以单纯复制发送到其他节点之后,什么也不用做也可以),
先在node节点上,修改kylin的配置文件,若是之前已经启动了kylin,先停止再修改:
cd /usr/local/kylin/apache-kylin-3.1.0-bin-hbase1x/conf
vi kylin.properties
##修改加入以下内容:
#元数据
kylin.metadata.url=kylin_metadata@hbase
#配置节点类型(kylin 主节点模式为 all,从节点的模式为 query)
kylin.server.mode=all
#kylin 集群节点配置(包括本节点,即所有kylin节点都要加入)
kylin.server.cluster-servers=192.168.88.129:7070,192.168.88.130:7070,192.168.88.131:7070
#定义 kylin 用于 MR jobs 的 job.jar 包和 hbase 的协处理 jar 包,用于提升性能(添加项)
kylin.job.jar=/usr/local/kylin/apache-kylin-3.1.0-bin-hbase1x/lib/kylin-job-3.1.0.jar
kylin.coprocessor.local.jar=/usr/local/kylin/apache-kylin-3.1.0-bin-hbase1x/lib/kylin-coprocessor-3.1.0.jar
#配置CuratorScheculer进行任务调度(基于Curator的主从模式多任务引擎调度器)
kylin.job.scheduler.default=100
kylin.server.self-discovery-enabled=true
保存退出后,将node上的kylin安装配置文件发送到node1和node2节点上:
#在node1和node2上都执行
cd /usr/local
mkdir kylin
#在node上执行
scp -r /usr/local/kylin/apache-kylin-3.1.0-bin-hbase1x/ 192.168.88.130:/usr/local/kylin/
scp -r /usr/local/kylin/apache-kylin-3.1.0-bin-hbase1x/ 192.168.88.131:/usr/local/kylin/
之后在node2上,将kylin.server.mode改为query
kylin.server.mode=query
本文两个节点node和node1为all,node2为query,组成任务引擎高可用
2.启动验证
2.1启动
在三台节点上都运行命令来启动kylin:kylin.sh start
在三台还未全部启动的时候可能会有错误,等全部启动就好了
2.2验证
在浏览器上输入IP:7070/kylin
访问地址:http://192.168.88.129:7070/kylin(其他节点也可以访问,比如http://192.168.88.130:7070/kylin)
默认秘钥:admin/KYLIN
发现都可以访问,之后点击system页面:多了instances页,并且在instances页如下:(访问其他节点的页面也是如此)
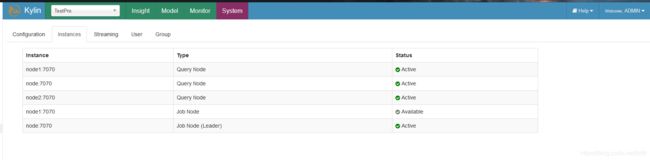
此时说明成功
3.文档叙述
此部分来自kylin官方文档
3.1Kylin 集群模式部署
如果您需要将多个 Kylin 节点组成集群,请确保他们使用同一个 Hadoop 集群、HBase 集群。然后在每个节点的配置文件 $KYLIN_HOME/conf/kylin.properties 中执行下述操作:
- 1.配置相同的 kylin.metadata.url 值,即配置所有的 Kylin 节点使用同一个 HBase metastore。
- 2.配置 Kylin 节点列表 kylin.server.cluster-servers,包括所有节点(包括当前节点),当事件变化时,接收变化的节点需要通知其他所有节点(包括当前节点)。
- 3.配置 Kylin 节点的运行模式 kylin.server.mode,参数值可选 all, job, query 中的一个,默认值为 all。
job 模式代表该服务仅用于任务调度,不用于查询;query 模式代表该服务仅用于查询,不用于构建任务的调度;all 模式代表该服务同时用于任务调度和 SQL 查询。
注意:默认情况下只有一个实例用于构建任务的调度 (即 kylin.server.mode 设置为 all 或者 job 模式)。
3.2任务引擎高可用
从 v2.0 开始, Kylin 支持多个任务引擎一起运行,相比于默认单任务引擎的配置,多引擎可以保证任务构建的高可用。
使用多任务引擎,你可以在多个 Kylin 节点上配置它的角色为 job 或 all。
为了避免它们之间产生竞争,需要在kylin.properties中配置任务调度器为分布式调度:
kylin.job.scheduler.default=2
kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock
然后将所有任务和查询节点的地址注册到 kylin.server.cluster-servers。
3.3配置CuratorScheculer进行任务调度
从 v3.0.0-alpha 开始,kylin引入基于Curator的主从模式多任务引擎调度器,用户可以修改如下配置来启用CuratorScheculer:
kylin.job.scheduler.default=100
kylin.server.self-discovery-enabled=true
4.帮助理解
此部分来自朋友收集,侵删
4.1 Job Scheduler
4.1.1 为什么需要Job Scheduler ?
在构建段的过程中,kylin将产生很多要执行的任务。
为了协调这些任务的执行过程并有效,合理地利用资源,需要作业调度机制。
4.1.2 kylin中有哪些调度程序?
在当前的kylin版本(kylin v3.1.0)中,存在三种Job Scheduler,它们的实现类是 DefaultScheduler , DistributedScheduler 和 CuratorScheduler 。
用户可以通过参数kylin.job.scheduler.default 来选择要使用的调度程序 。
默认情况下, kylin.job.scheduler.default = 0 ,将DefaultScheduler用作作业调度程序。 当配置为2使用 DistributedScheduler ,当配置为100使用CuratorScheduler。
4.1.3 不同的作业调度程序有什么区别?
1.DefaultScheduler
DefaultScheduler是默认的作业调度程序。
它的核心逻辑是初始化 两个线程池 。 一个线程池 ScheduledExecutorService 用于获取kylin中的所有作业信息,而另一个线程池JobRunner 用于执行特定的作业。
ScheduledExecutorService将定期获取的所有任务的状态信息。 当任务的状态为 Ready时 ,意味着可以安排任务执行时间,并将任务移交给 JobRunner 进行执行。
DefaultScheduler 是 的独立 调度程序 版本,在同一元数据下只能有一个作业服务器。
如果 kylin.server.mode = all 或 job ,则在Kylin Server进程启动时,它将初始化 DefaultScheduler 并锁定作业服务器。 锁的实现类是 ZookeeperJobLock ,它是通过使用zookeeper的临时节点实现的。
一旦作业服务器持有该锁,在作业服务器进程完成之前,其他任何作业服务器都无法获得该锁。
2.DistributedScheduler
DistributedScheduler是Meituan提供的分布式调度器,自kylin 1.6.1版本起就支持该调度器。
使用DistributedScheduler作为作业调度器,您可以在相同的元数据下拥有多个kylin作业服务器。
与DefaultScheduler相比, DistributedScheduler 减小了锁定粒度,从锁定整个作业服务器到锁定段。实现类是 ZookeeperDistributedLock ,它通过使用zookeeper的临时节点来实现。
当提交段构建作业并计划执行作业时, jobId 将被拼写在zookeeper的临时节点路径中,并且该节点将被锁定。 当整个作业的最终状态变为SUCCEED,ERROR和DISCARDED时,锁定将被释放。
用户还可以配置 kylin.cube.schedule.assigned.servers 以指定 的 作业执行节点 多维数据集 。
3.CuratorScheduler
Curatorscheduler是由Kyligence实现的基于 器的调度程序,自 kylin v3.0.0-alpha 版本起就支持该调度器。
CuratorScheduler 是 主从模式 。 它从所有作业节点中选择一个领导者来安排任务。
leader选举有两种实现方式,即 LeaderSelector 和 LeaderLatch 。
LeaderSelector 是所有尚存的客户轮流担任领导者,而领导者在执行takeLeaderShip方法后释放者。
LeaderLatch 是一旦选出领导者,除非有客户挂断并再次触发选举,否则领导者将不会移交。
kylin默认的选举方式为LeaderSelector 。
十三、Nginx负载均衡
1.Nginx安装环境
- gcc
安装nginx需要先将官网下载的源码进行编译,编译依赖gcc环境,如果没有gcc环境,需要安装gcc:
yum install gcc-c++
- PCRE
PCRE(Perl Compatible Regular Expressions)是一个Perl库,包括 perl 兼容的正则表达式库。nginx的http模块使用pcre来解析正则表达式,所以需要在linux上安装pcre库
yum install -y pcre pcre-devel
注:pcre-devel是使用pcre开发的一个二次开发库。nginx也需要此库。
- zlib
zlib库提供了很多种压缩和解压缩的方式,nginx使用zlib对http包的内容进行gzip,所以需要在linux上安装zlib库
yum install -y zlib zlib-devel
- openssl
OpenSSL 是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其它目的使用。
nginx不仅支持http协议,还支持https(即在ssl协议上传输http),所以需要在linux安装openssl库。
yum install -y openssl openssl-devel
2.编译
- 在线安装以上4个环境
- 上传nginx安装包到
/usr/local/software/nginx - 解压 tar -zxvf 安装包名:
tar -zxvf nginx-1.17.2.tar.gz - 在/usr/local下创建文件夹nginx (下面会指定引用)
cd /usr/local
mkdir nginx
- 在/var下创建/temp/nginx文件夹 (下面会指定引用,注意是建了两个文件夹)
cd /var
mkdir temp
cd temp
mkdir nginx
- 在nginx的解压目录执行配置 (在目录下直接粘贴这段代码)
#进入目录
cd /usr/local/software/nginx/nginx-1.17.2
#执行配置
./configure \
--prefix=/usr/local/nginx \
--pid-path=/var/run/nginx/nginx.pid \
--lock-path=/var/lock/nginx.lock \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-http_gzip_static_module \
--http-client-body-temp-path=/var/temp/nginx/client \
--http-proxy-temp-path=/var/temp/nginx/proxy \
--http-fastcgi-temp-path=/var/temp/nginx/fastcgi \
--http-uwsgi-temp-path=/var/temp/nginx/uwsgi \
--http-scgi-temp-path=/var/temp/nginx/scgi \
--with-http_dav_module \
--with-http_stub_status_module \
--with-http_addition_module \
--with-http_sub_module \
--with-http_flv_module \
--with-http_mp4_module
- 等上面命令运行结束,继续同目录下运行:
make && make install
3.启动测试
启动:
cd /usr/local/nginx/sbin/
./nginx
为了方便最好配置Nginx环境变量:
#打开配置文件
vi /etc/profile
#加入以下内容
export PATH=$PATH:$NGINX_HOME/sbin
export NGINX_HOME=/usr/local/nginx
#保存后,使之生效
source /etc/profile
这样就不用进入安装目录运行命令
#停止命令
nginx -s stop
#重启命令
nginx -s reload
#查看nginx配置文件是否正确
nginx -t
#查看nginx状态
ps aux| grep nginx
验证:
在浏览器输入自己的IP查看:(即nginx安装所在机器IP):http://192.168.88.129
会出现welcome to nginx的页面
说明启动成功
以上参考自此处,侵删
4.nginx实现kylin集群的负载均衡
nginx若启动着,则停止;
进入nginx的编译目录/usr/local/nginx/conf,修改nginx.conf文件内容:
##user nobody;
#worker_processes 1;
user root;
worker_processes auto;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
error_log /var/log/nginx/error.log;
error_log /var/log/nginx/error.log notice;
error_log /var/log/nginx/error.log info;
#pid logs/nginx.pid;
pid /var/run/nginx/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
log_format main escape=json '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
access_log /var/log/nginx/access.log;
sendfile on;
#tcp_nopush on;
tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
#charset koi8-r;
charset utf-8;
#access_log logs/host.access.log main;
access_log /var/log/nginx/host.access.log main;
location / {
#root html;
#index index.html index.htm;
proxy_pass http://kylin;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
upstream kylin {
ip_hash;
server 192.168.88.129:7070;server 192.168.88.130:7070;server 192.168.88.131:7070;
}
}
为了维持session会话持久性,避免频繁刷新页面出现kylin登陆页面进行登陆,需要在nginx.conf文件内配置ip_hash
重新启动nginx,命令:nginx
将Nginx服务以及所有节点的kylin服务启动,我们可以在浏览器中输入:http://192.168.88.129,来访问我们的Kylin集群。
若要验证是否负载均衡,查看日志打印
5.问题
若是通过命令:
curl 192.168.88.129/中文
查看日志,发现中文的日志输出打印非中文,而是如:"GET /\xE4\xB8\xAD\xE6\x96\x87 HTTP/1.1",
则是未在配置文件的日志属性log_format中加入:escape=json,
然后为access_log /var/log/nginx/host.access.log main;中访问日志的最后面添加main,使之生效;
重新通过命令进行:
curl 192.168.88.129/中文
查看日志发现正常:"GET /中文 HTTP/1.1"