生产环境出现问题,测试人如何做工作复盘?

很多时候我们能把大部分的Bug或一些部署等问题在业务上线之前就解决了,但由于某些因素,线上问题还是时而出现,影响业务生产甚至是公司效益。
避免线上问题的发生以及线上问题及时处理是测试人员的一项重要职责,如何快速地处理,最大限度地降低影响范围,后续如何避免此类问题的发生,是我们需要复盘的重点内容。
一 为什么要复盘?
在发布上线后,对测试过程进行复盘,总结遇到的问题,对当时的解决方案进行探讨。通过复盘,从而达到指导后续工作,减少重复踩坑。并在可以在个人复盘完成后,在部门内进行信息共享。每个人负责的项目虽然不同,但是测试思想确有共通之处。通过复盘分享,可以有效提升团队整体测试经验。
从质量保障的角度来说,针对线上问题进行复盘可以发现工作中的不足并持续改进,不断提高线上的交付质量。
从团队管理的角度来说,针对线上问题进行复盘也可以发现团队短板并针对性的补齐技术体系,提高团队效率。
从业务目标的角度来说,技术团队作为成本中心,也需要不断提高自身的交付产出质量,来支撑业务目标更好的达成。
二 故障复盘的步骤
故障复盘的实施步骤通常包含以下步骤:
理解故障的技术背景
梳理故障的整体情况
识别故障的直接/间接影响
梳理故障时间线
识别和分析故障触发条件和关键环节
层层下钻故障根因
分析解决方案
归纳推演出后续的跟进措施
总结经验教训
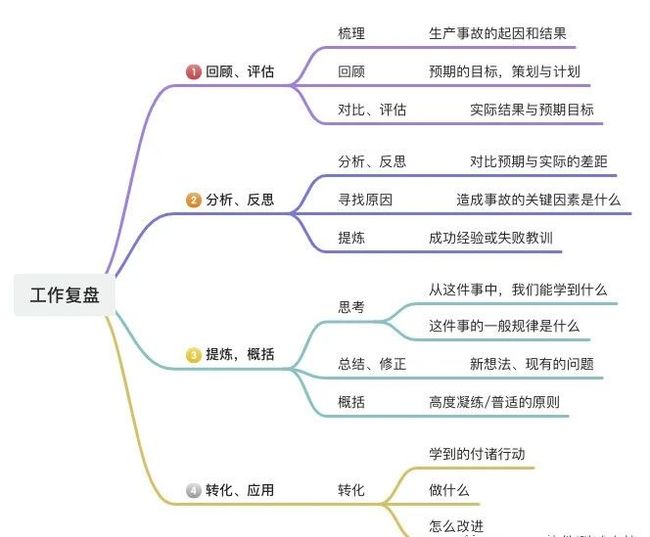
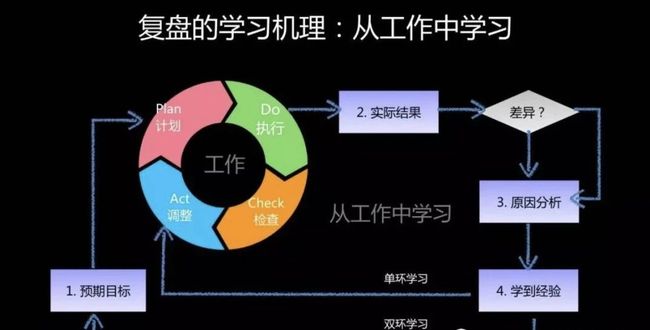
复盘的意义:
1.不是为了逃避现实,也不是为了炫耀,而是能真正解决某些问题。
2.检验完成的结果,回溯过程,总结利弊得失,做好资源沉淀。
3.为后续工作积累经验,提升个人能力。
4.作为跟领导汇报的材料用,方便未来查询。
GRAI复盘法:
G(Goal)回顾目标:回顾最初情景,列出当时的目标。
R(Rult)对比结果:列出目标完成情况,将结果和目标进行比较。
A(Analysis)分析过程:用今天的眼光和能力审视昨天的做法,学到对未来有用的信息。
I(Insight)总结规律:总结提炼出适用于类似情况的规律,合理进行模块整理。

三 问题跟进前提
进行一切线上问题跟进的活动是基于测试人员本身对业务系统的熟悉程度,业务系统,也就是指业务和系统,除了业务之外,需要测试人员对业务所在的整体系统架构具备一定的熟悉程度,这里从上到下分应用层,软件层,系统层来分析。
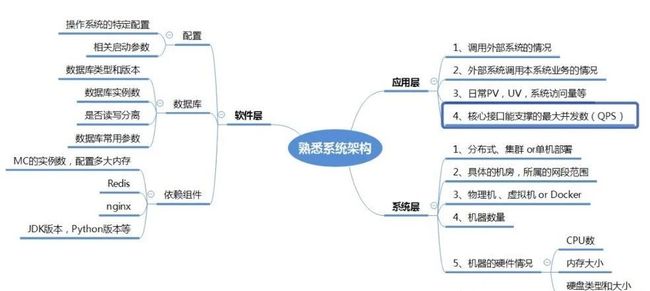
1、应用层
在应用层,我们主要关注的是我们能直接接触到的内容。首先,我们需要了解自己负责的业务系统在整体业务系统中的位置。除了了解业务系统内部的情况,我们还需要了解外部系统如何调用我们的业务系统,以及我们的业务系统如何调用外部系统。
同时,我们也需要清楚最基本的关键要素:量。这包括了业务系统的访问量,比如日访问量等。此外,我们还需要熟悉核心接口或核心功能的最大并发量,以应对突然的高流量以及网络攻击等问题。
2、软件层
在软件层,我们主要涉及到数据、配置和相关组件。数据通常指的是数据库,了解数据库的部署情况可以帮助我们解决数据读写等问题。同时,对于基础组件如nginx,涉及到负载均衡和跨域访问等业务配置,了解这些信息可以帮助我们定位问题。此外,对于缓存的合理使用情况的分析也有助于我们分析持久化和数据库使用方面的问题。还有一些相关的事项,比如JDK版本、JVM的启动参数等等,也需要了解。
3、系统层
在系统层面,与硬件相关的内容更多。这包括业务系统的部署方式,是在单台机器上还是分布式部署,具体所在的机房和网络段,以及部署时使用的是物理机还是docker等虚拟化技术。同时,还需要了解部署机器的硬件信息,比如内存大小、CPU数量和磁盘类型大小等。
要做好线上问题跟进,就得对自己所负责的业务系统了如指掌,只有知己知彼,才能百战百胜。
四 问题跟进策略
对于问题跟进的策略,可以分为四个环节,包括影响范围评估、快速恢复、定位方法和问题复盘,接下来具体介绍这四个环节的内容。
策略1:影响范围评估
在跟进问题时,首要步骤是评估问题的影响范围,根据评估结果来设计应对策略和救火方案。评估过程中,首先要确定问题的类型,例如功能、性能或硬件方面的故障。例如,突然的大流量和大并发可能导致资源不足,造成许多待处理请求;内存故障可能导致资源效率下降等等。
对于功能上的故障,可以确定功能的重要性和优先级。对于核心功能的故障,需要尽快制定救火策略,减少影响范围,并确保敏感功能和信息的安全稳定。根据问题的影响范围采取相应措施。如果是面向用户的功能,应尽量避免问题功能与用户接触;如果是与上下游业务相关的功能,应及时通知相关业务方采取规避措施。
在评估和制定救火策略时,必须迅速行动,因为问题的影响范围和程度会随时间扩大。建立良好的告警反馈体系至关重要,通过线上监控、客服反馈等手段实时了解问题情况,以有效降低时间带来的影响。
策略2:快速恢复
在评估问题的影响范围后,需要快速响应并恢复系统。一般情况下,问题的定位速度可分为快速定位和无法快速定位两种情况。
对于可以快速定位问题的情况,如果是由业务功能导致的问题,通常会采取修复补丁的方式。但对于无法立即回收或发布版本的客户端应用程序(如移动应用),可以通过后台配置功能降级或关闭来处理。此外,一些问题可以通过调整配置参数来规避,也可以采取这种方式减小线上问题的影响范围。
当无法快速定位问题时,就需要果断行动,首要原则是将问题的影响范围降到最低。可以通过回滚版本来规避问题,这是最有效且首选的方法,回滚版本可以切断问题发生的原因,并保证最初的稳定业务。
当然,对于负载过高导致的问题,回滚版本并不能解决。这时通常采用重启的策略,重新启动后继续观察资源情况,通常是由于新版本的问题导致资源死锁等情况,所以有必要时回滚版本和重启策略可以同时使用。
如果问题涉及硬件方面,一般可以通过扩容来解决,例如增加硬盘、增加内存等,先提供足够的资源,然后再考虑性能优化方案。
对于已进行功能配置的情况,可以先关闭。
或降级功能,然后在测试环境中继续定位和解决问题,最后再发布修复版本。
策略3:定位方法
在处理线上问题时,降低影响范围后的下一步是定位问题的原因。无论是功能问题、性能问题还是环境问题,日志是重要的定位工具。因此,通常要求业务日志要准确记录,并及时告警错误。然而,也不能将所有内容都记录在日志中,只有精确的业务日志才能为业务系统的稳定运行提供有效依据。通过排查日志信息来定位问题的原因是最有效的方法。
功能问题通常可以在测试环境中重新出现,尽量模拟线上的情况,包括数据和配置,这样问题再次发生的概率就会增加,便于更容易地定位。
对于资源性能问题,可以通过监控告警日志和一些常用命令来获取信息,然后采取相应的解决措施。
一旦定位到问题,就要迅速制定修复和上线方案,确保业务系统在稳定状态下继续运行。
策略4:问题复盘
经过上述过程的执行,我们还需要进行总结,也就是问题复盘。我们都不希望问题再次发生,因此通过复盘来总结经验,可以提升大家规避问题和处理线上问题的能力。
在问题复盘中,我们可以分析问题的原因,是由人为因素导致的还是系统Bug,是遗漏的Bug还是新引入的Bug,以及是否由于外部系统数据流或组件不兼容等问题导致的。
处理问题的流程是否合理也是需要考虑的。有时候明明需要回滚版本却没有做,有时候又回滚了不必要的版本。在这方面需要权衡成本和方案的合理性,毕竟有时候版本很紧急,回滚会延迟进度,对业务来说并不是理想的结果。
如何避免类似问题再次发生也是问题复盘的核心环节。我们需要检查监控是否完善,是否由于监控告警不及时或信息不完善而影响了整体救火进度。同时,在系统架构上是否可以进行性能相关的优化,建立起对系统的保护措施,例如过载保护、服务降级、数据解耦等。
问题的复盘对于团队救火能力的提升是最有效果的,同时建立起相关文档,加强团队对业务以及系统的了解程度。
总结: 线上问题跟进是测试工程师的一项重要的职责,也是测试工程师的一门重要的能力,除了发现在研发测试阶段的问题,我们需要去解决线上的问题,为业务系统保驾护航,对于测试工程师来说责无旁贷。
提升自己代码能力,测试工具使用能力,写用例能力的同时,也要提升自己应对问题处理的能力,丰满自己在各个质量保证环节的能力,这样才能成为一名优秀的测试工程师。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
