Python的垃圾回收机制
Contents
- 1. Python垃圾回收机制
-
- 1.1. 内存管理
-
- 1.1.1. Block
- 1.1.2. Pool
- 1.1.3. Arena
- 1.1.4. 内存重新分配(deallocation)
-
- 1.1.4.1. 内存分配统计
- 1.2. 垃圾收集算法
- 1.3. 引用计数
-
- 1.3.1. 会增加引用计数的场景
- 1.4. 代际垃圾收集器(generational Garbage Collector)
-
- 1.4.1. 何时会触发代际垃圾收集触发器
- 1.4.2. 如何查找到循环引用
- 1.5. 性能提示
- 1.6. 如何查找并且调试循环引用
-
- 1.6.1. 结论
- 2. References
1. Python垃圾回收机制
通常情况下,在Python中并不需要进行内存管理,当对象不再被需要的时候,Python会自动回收这些对象占用的内存空间。但是了解垃圾回收器(Garbage Collector, GC)是如何工作的,有助于写出更好、运行更高效的Python程序。
1.1. 内存管理
不同于很多其它语言,Python并不是必须要将对象占用的内存释放给操作系统。取而代之的是,Python中有一个专用的对象分配器(object allocator),专门用于给小于512字节的对象分配内存,这个分配器可以将这些对象驻留在内存中,以便未来用到的时候可以快速从内存中加载出来。
Python所保持的内存容量取决于使用形式。在一些场景中,当Python进程被终结的时候,这个进程中被分配的内存都会被释放出来。
如果是长期运行的Python进程,那么随着运行时间的增加,其占用的内存也会越来越多,但这并不意味着会导致内存泄漏。这就涉及到Python的内存模型。
由于在Python中,一切皆对象。一些对象可以用于保存其他对象,比如list类型对象,tuple类型对象,dict类型对象,class类型对象等等。由于Python的动态语言特性,就要求很多个对象的少量内存分配。为了加速内存操作,并且减少内存碎片,Python在通用内存分配器(general-purpose allocator)的上层使用了一个特殊的管理器——PyMalloc。
这个分级系统的架构全貌如下图所示:
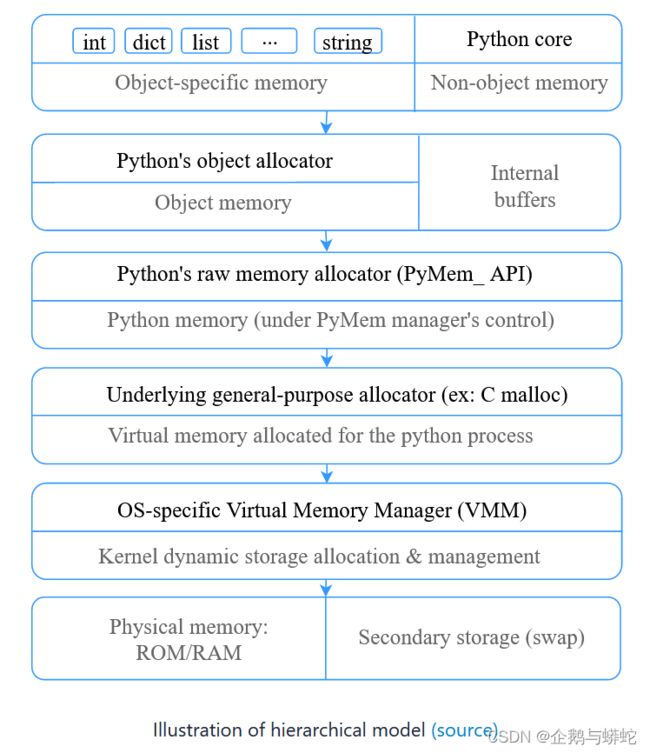 关于上述的分级架构的源代码,参见GitHub项目:source
关于上述的分级架构的源代码,参见GitHub项目:source
小对象的内存分配
为了减少小对象(即小于512字节的对象)内存占用开销,Python会通过子分配(sub-allocate)的方式分配大块的内存(big blocks of memory)。而更大对象的内存分配会被路由到标准C分配器上。对于小对象分配,Python使用了三级概念抽象——arena, pool, block。
下面从最小结构——block开始介绍。
1.1.1. Block
所谓Block,是某个大小的内存区块(chunk)。每个block中只保存一个固定大小的Python对象。Block的大小可以在8字节到512字节之间变化,为了保证8字节对齐,所以block的大小必须是8字节的整倍数。为了方便管理,通常会将这些block按照每组8个字节编组为64个类。具体如下表所示:
| Request in bytes | Size of allocated block | size class idx |
|---|---|---|
| 1-8 | 8 | 0 |
| 9-16 | 16 | 1 |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | 4 |
| 41-48 | 48 | 5 |
| … | … | … |
| 505-512 | 512 | 63 |
1.1.2. Pool
A collection of blocks of the same size is called a pool. Normally, the size of the pool is equal to the size of a memory page, i.e., 4Kb. Limiting pool to the fixed size of blocks helps with fragmentation. If an object gets destroyed, the memory manager can fill this space with a new object of the same size.
而相同大小的block的集合被称为pool。正常来说,pool的大小等于内存页的大小,即占用4KB。将pool限定为固定大小的block可以帮助减少内存碎片。如果一个对象被销毁了,那么内存管理器会使用相同大小的新对象填充这个被销毁对象占用的空间。
每个pool都有一个特定的结构头,具体如下所示:
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
block *freeblock; /* pool's free list head */
struct pool_header *nextpool; /* next pool of this size class */
struct pool_header *prevpool; /* previous pool "" */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
相同大小的block会通过双端链表链接在一起(上述的结构体nextpool和prevpool),szidx域记录了类索引大小,而ref.count记录了已经被使用的block。arenaindex存储了哪个pool中创建了多少arena。
所以,如果block是空的,它里面通常会存储下一个空的block的地址。这个方式可以节省很多内存和计算。
每个pool都有三种状态:
- used — 部分占用,既不空,也没有处于完全占用的状态
- full — pool的所有block都已经被分配完了。
- empty — pool的所有block当前均为被分配给特定的对象,均处于可分配的状态。
为了高效的管理pool,Python使用了一个名为usedpools的额外数组。这个数组中存储了指向按类别分组的多个pool。正如我们已经知道的,所有具有相同block大小的pool会通过双向链表被链接到一起,为了迭代这些pool,只需要知道链表的开始位置即可。如果没有这样大小的pool,那么就会在第一个内存请求的时候创建一个新的pool。
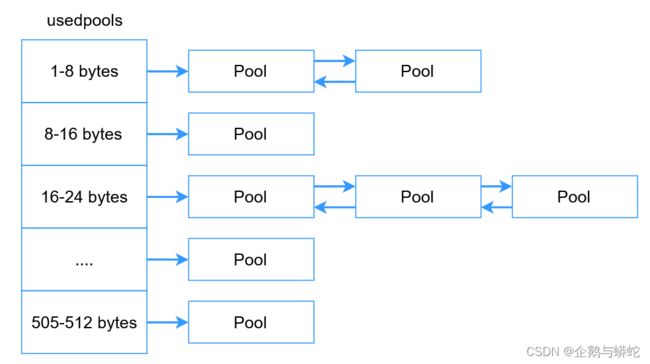 注意,pool和block并不是直接对内存进行分配,相反,他们使用arenas中已经分配的内存空间。
注意,pool和block并不是直接对内存进行分配,相反,他们使用arenas中已经分配的内存空间。
1.1.3. Arena
Arena是在堆(heap)上分配的256KB大小的内存区域,1个Arena可以为64个pool提供所需要的内存空间。
 Arena对象的结构如下所示:
Arena对象的结构如下所示:
struct arena_object {
uintptr_t address;
block* pool_address;
uint nfreepools;
uint ntotalpools;
struct pool_header* freepools;
struct arena_object* nextarena;
struct arena_object* prevarena;
};
所有的arenas也是通过双端链表链接起来的(nextarena以及prevarena两个字段),通过双端链表可以帮助管理arenas。ntotalpools以及nfreepools用于存储当前可用pool的信息。
freepools字段(结构体指针)指向可用pool的链接列表。
Arena的实现并没有什么复杂的,只需要将其考虑为容器列表即可,在需要的时候,可以自动为pool分配内存空间。
1.1.4. 内存重新分配(deallocation)
Python的小对象管理器几乎不会将其占用的内存空间返回给操作系统。
只有当Arena中的所有pool都未被占用的时候,才会完全释放Arena占用的内存空间。比如这种情况可能发生在很短的周期内使用了大量的临时对象的时候。
而对于长期运行的Python进程而言,由于这种行为方式,会持续占用很多未使用的内存空间。
1.1.4.1. 内存分配统计
要查看内存分配的统计信息,可以调用函数sys._debugmallocstats()。
由于绝大多数对象都是小对象,所以自定义内存分配器在分配内存的时候会节省很多时间。即便是简单如导入第三方库的程序,也可以在程序生命周期内分配数百万个对象。
1.2. 垃圾收集算法
由于在Python中一切皆对象,即便是整数。要知道何时给这些对象分配内存很容易。当你需要创建新对象的时候Python就会完成内存分配的操作。不同于内存分配的操作,已分配内存的重新分配(deallocation)有一些不一样。当重新分配的时候,Python需要知道你何时不再需要该对象。永久的移除对象将会导致程序运行崩溃。
而垃圾收集算法会追踪对象所占用的内存空间何时可以被重新分配,并且选择最优时机对其进行重新分配。标注的CPython垃圾收集器有两个组件:引用计数收集器(reference counting)以及代际垃圾收集器(generational garbage collection, gc)。
引用计数算法极其高效、直接,但它无法探测到循环引用。这就是为什么Python中还有补充的额外算法——代际循环(generational cyclic, gc),这个代际循环算法只是用于解决循环引用的问题。
引用计数模块是Python的必要模块,是无法被禁用的,而代际循环算法(generational cyclic)算法则是可选的,并且可以被手动触发。
1.3. 引用计数
引用计数是一个简单的技术,当一个程序中的对象没有被引用的时候,该对象就会被占用的内存空间就会被撤销分配的内存空间。
Python中的每个变量都是到对象的引用(即指针),而并不是实际的值本身。比如,赋值语句仅仅是给等号右边的值增加了一个新的引用。单一对象可以有多个引用(即多个变量名指向同一个对象)。
下面的代码对于同一个对象创建了两个引用,分别为a, b,指向相同的对象——列表[1, 2, 3]:
a = [1, 2, 3]
b = a
赋值语句本身永远不会拷贝或者创建新的数据。
要对引用保持追踪,每个对象(甚至是整数)都有一个额外的字段——引用计数,引用计数会随着指向该对象的指针的创建或删除而增加或者减少。关于引用计数更详细的介绍,参见官方文档Objects, Types and Reference Counts。
1.3.1. 会增加引用计数的场景
- 赋值操作符
- 参数传递
- 向列表中追加对象(将会增加对象的引用计数)
如果引用计数这个字段值为0,CPython会自动调用特定对象内存的解除分配函数,将该内存标记为可回收。如果对象中包含其他对象的引用,随后其他对象的引用计数器会被自动减1。随意其他对象也可能会被依次进行解除内存分配。比如,当列表对象被删除的时候,列表中所有对象的引用计数就全部会缩减。如果其他变量引用了列表中的某个对象,那么这个项目将不会被解除内存分配。
在函数、类之外声明的变量,被称为全局变量。通常来说,这样的变量会持续存在直到Python进程终结。所以,被全局变量引用的对象,其引用计数器的值就不会缩减为0。要保持全局变量存活,Python将全局变量都存储在一个字典中。可以在Python中调用globals()函数查看全局变量。
在函数或者类内部定义的变量,具有局部作用域(作用范围是定义该变量的函数或者类内部)。当Python解释器从函数或者类中退出的时候,会销毁局部变量以及它们的引用,换句话说,也就是仅销毁了变量名而已。
理解这一点是很重要的,Python解释器假定函数或者类中的所有变量都是处于使用状态的,要从内存中移除,要么给变量分配新的值,要么解释器从函数或者类中退出(即执行完成)。在Python中,用的最多的代码块是函数,所以函数中也是垃圾收集最常发生的地方。所以这也是为什么要尽可能保持函数精简的原因所在。
You can always check the number of current references using sys.getrefcount function.
通过调用sys.getrefcount()函数可以检查当前的引用计数情况。具体示例如下所示:
import sys
foo = []
# 2 references, 1 from the foo var and 1 from getrefcount
print(sys.getrefcount(foo))
def bar(a):
# 4 references
# from the foo var, function argument, getrefcount and Python's function stack
print(sys.getrefcount(a))
bar(foo)
# 2 references, the function scope is destroyed
print(sys.getrefcount(foo))
在上面的示例中,将会看到在Python执行完成的时候,会销毁函数的引用。
有时需要永远移除全局变量或者局部变量,为此,就需要使用del语句移除变量以及其引用(而不是移除对象本身)。这种操作在使用Jupyther notebook的时候是很有用的,因为在Jupyther notebook中所有单元变量(cell variable)都是全局变量。
CPython之所以使用引用计数主要是因为一些历史原因。关于这项技术的弱点现今有很多争论。一些人声称,现代垃圾收集算法可以摒弃引用计数从而使得垃圾收集更高效。引用计数算法有很多问题,比如循环引用,线程锁,以及垃圾收集过程中带来的内存和性能开销等。引用计数是导致Python无法避免全局解释器锁(GIL)的主要原因。
当然,引用计数的一个主要优势就是当对象不再被需要的时候,可以很容易地被立即销毁。
1.4. 代际垃圾收集器(generational Garbage Collector)
为什么我们在有了引用计数器之后,还需要额外的垃圾收集器呢?
不幸的是,经典引用计数算法有一个根本问题——它无法探测到循环引用的情况。当一个或者多个对象彼此相互引用的时候,就会发生循环引用的情况。下面是两个示例:
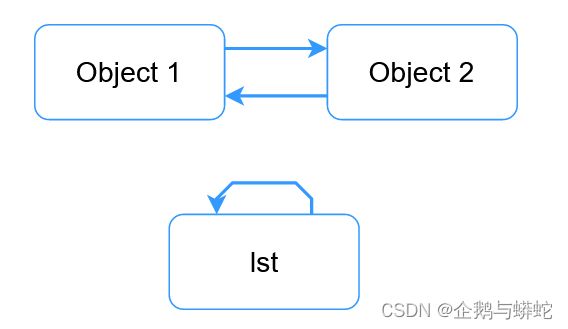 如上图所示,
如上图所示,lst对象引用其自身,此外,object 1和object 2彼此相互引用。上图中的这两种情况下,引用计数值将总是1。为了更好的揭示这一点,需要运行下面的简单代码:
import gc
import ctypes
# We use ctypes moule to access our unreachable objects by memory address.
class PyObject(ctypes.Structure):
_fields_ = [("refcnt", ctypes.c_long)]
gc.disable() # Disable generational gc
lst = []
lst.append(lst)
# Store address of the list
lst_address = id(lst)
# Destroy the lst reference
del lst
object_1 = {}
object_2 = {}
object_1['obj2'] = object_2
object_2['obj1'] = object_1
obj_address = id(object_1)
# Destroy references
del object_1, object_2
# Uncomment if you want to manually run garbage collection process
# gc.collect()
# Check the reference count
print(PyObject.from_address(obj_address).refcnt) # print 1
print(PyObject.from_address(lst_address).refcnt) # print 1
在上面的示例中,del语句会移除对相关对象的引用(也就是将对象的引用计数减1)。在Python执行了del语句之后,就无法在Python代码中访问该对象了。不过,对象仍然存留在内存中,之所以这样,是因为对象之间存在着相互引用,即循环引用。所以此时对象的引用计数仍然为1。要图示化这样的引用关系,可以使用 objgraph 这个模块。
要解决这个问题,于是在Python-1.5版本开始引入了循环引用探测算法。而这个gc模块就是负责进行循环引用探测的,并且只只为处理这个问题而存在。
循环引用只能发生在容器类型的对象(能容纳其他数据类型对象的对象)上面,比如list类型对象,dict类型对象,class类型对象,tuple类型对象等。垃圾收集算法并不会追踪tuple类型之外的其他不可变类型的对象。tuple类型对象和dict类型对象中包含的是不可变类型对象,在一些情况下也可以是未追踪状态。所以,引用计数可以用于处理所有的非循环引用的情况。
1.4.1. 何时会触发代际垃圾收集触发器
不同于引用计数,周期性的垃圾收集器(cyclic GC,下面将垃圾收集器简称为GC)并不是实时工作的,而是周期性运行的。为了减少频繁的GC调用和微暂停,CPython使用了多种启发形式。
GC将容器类型的对象分为3代,每个新的对象都是从第一代开始。如果一个对象在一轮垃圾收集操作中幸存下来,那么它就会被移到更老(higher)的一代上。而更低的代会比更老的(或者更高的代)先回收。因为最新创建的对象在年轻态就死掉了,所以提升了GC的性能,并且减少了GC的暂停时间。
为了决定何时运行,每一代都有一个独立的计数器以及阈值。计数器中存储对象被分配的次数减去最后一次垃圾收集之后内存解除分配的差值。每次给一个新的容器对象分配内存的时候,CPython就会检查第一代的计数器何时会超过指定的阈值。如果超过阈值,Python会立即启动垃圾收集进程。
如果现在有2个或者更多代超过了指定的阈值,GC会选择最老的一代进行垃圾收集。这是因为最老的一代通常也会将其前面的所有年轻代一并回收了。为了降低对长期存活对象的性能影响,对第三代有额外的要求以便能够将第三代选择上。
标准阈值分别被设置为(700,10,10),对于这个值,总是可以通过gc.get_threshold(threshold0, threshold1, threshold2)函数进行查看。也可以通过调用gc.set_threshold(threshold0[, threshold1[, threshold2]])函数调整这些阈值以便适应你特定负载。将threshold0设置为0,表示禁用垃圾收集功能。新创建的对象会被放在最年轻一代中,即generation 0这一代中。如果对象能够在垃圾收集操作中幸存下来,那么该对象就会被移动到更老的下一代中。由于此时第二代是最老的一代,所以这一代对象在经历了垃圾收集操作之后仍然被保留下来。为了确定何时执行垃圾手机操作,垃圾收集器会持续追踪最后一次垃圾收集操作之后已经分配的对象和解除分配的对象数量。当已经分配对象的数量减去解除分配对象的数量的差值超过了指定的阈值threshold0的时候,就启动垃圾收集操作。起初只会检查最年青一代,即generation 0这一代。如果最年青一代的generation 0已经被检查完成,并且其结果超过了generations 1(第二代,更老的一代)这一代此前检查之后的阈值threshold1的倍数,那么随后也会对generation 1这一代进行重新检查。
对于第三代(最老的一代),事情会更复杂一些。
1.4.2. 如何查找到循环引用
很难在有限的段落中将循环引用探测算法讲解清楚。基本上来说,GC会迭代每个容器类型对象,并且暂时性的移除到所有容器对象的所有引用。在完全迭代之后,所有引用计数低于2的对象将无法从Python代码中访问到,所以也就可以被垃圾回收了。
要完全理解循环引用探测算法,建议你读CPython源码中的original proposal from Neil Schemenauer以及collect函数。另外,Quora answers和The Garbage Collector blog post中的问答也会起到一些帮助作用。
另外,finalizer的问题已经在起初的建议中描述过了,并且从Python-3.4开始已经修复了该问题。具体可以参阅PEP 442。
1.5. 性能提示
在现实生活中,很容易发生循环的情况。比较典型的是在图、链接列表或者在结构体中,你需要追踪对象之间的关系的时候。如果程序负载较重,同时要求低延迟,此时就需要尽可能避免循环引用发生的可能行了。
要在你自己的代码中避免循环引用,可以在代码中使用弱引用(weak references),弱引用是在weakref模块中实现的。不同于通常的引用,弱引用weakref.ref并不会增加引用计数,所以如果一个对象被销毁,那么返回值为None。关于更多weakref模块的介绍和示例,参见官方库手册weakref。
在一些情况中,是很需要禁用GC的自动垃圾收集功能的,改为手动管理的方式。此时可以通过调用gc.disable()函数禁用GC的垃圾自动收集功能。如果需要手动方式运行垃圾收集进程,可以调用gc.collect()函数完成垃圾回收操作。
1.6. 如何查找并且调试循环引用
调试循环引用有的时候是非常让人沮丧的事情,尤其是当你在程序中使用了大量第三方库的时候。
标准的gc模块就提供了许多有用的助手功能可以用于帮助调试循环引用。如果将调试标记设置为DEBUG_SAVEALL,那么所有无法访问道德对象都会被追加到gc.garbage列表中。
import gc
gc.set_debug(gc.DEBUG_SAVEALL)
print(gc.get_count())
lst = []
lst.append(lst)
list_id = id(lst)
del lst
gc.collect()
for item in gc.garbage:
print(item)
assert list_id == id(item)
Once you have identified a problematic spot in your code you can visually explore object’s relations using objgraph.

1.6.1. 结论
绝大多数垃圾收集操作都是通过引用计数算法完成的,是我们根本无法调整的。所以,意识到实现的希捷,但不用过度担心潜在的GC问题。
Python的每个实现都有其相对应的垃圾收集器。比如Jython使用标准的Java垃圾回收器(因为Jython的代码是运行在JVM虚拟机中的),PyPy使用标记&擦除算法(Mark and Sweep Algorithm)。PyPy的GC比CPython的GC实现的更加复杂,同时也进行了额外的优化,参见http://doc.pypy.org/en/release-2.4.x/garbage_collection.html。
对于IPython而言,我没有感觉到有任何改变,因为它只是CPython的交互式shell。
关于内存管理,在PEP索引中已经给出了几十个建议,但其中只有少量在未来可能会被接受。
2. References
[1]. Python Garbage Collector
[2]. Memory management in Python