YOLOv8改进 | 2023 |CARAFE既减少参数又提高精度的上采样方法

论文地址:官方论文地址点击即可跳转
代码地址:官方代码地址点击即可跳转

一、本文介绍
本文给大家带来的CARAFE(Content-Aware ReAssembly of FEatures)是一种用于增强卷积神经网络特征图的上采样方法。其主要旨在改进传统的上采样方法(就是我们的Upsample)的性能。CARAFE的核心思想是:使用输入特征本身的内容来指导上采样过程,从而实现更精准和高效的特征重建。CARAFE是一种即插即用的上采样机制其本身并没有任何的使用限制,特别是在需要精细上采样的场景中,如图像超分辨率、语义分割等。这种方法改善了上采样过程中的细节保留和重建质量,使网络能够生成更清晰、更准确的输出。所以在YOLOv8的改进中其也可以做到一个减少计算量提高精度的改进方法 (我替换了YOLOv8中的两处上采样方法计算量由8.9降到了8.5)。
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
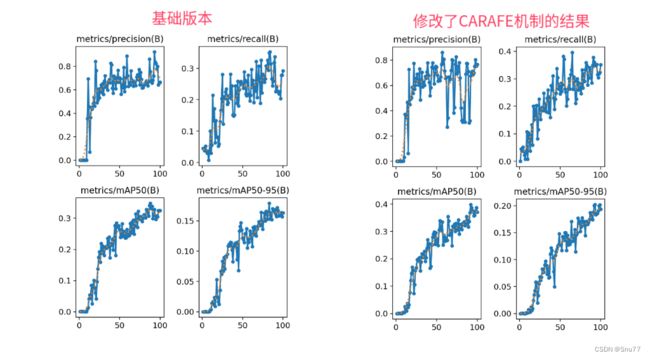
实验效果图如下所示->
本次实验我只用了一百张图片检测的是安全帽训练了一百个epoch,该结果只能展示出该机制有效,但是并不能产生决定性结果,因为具体的效果还要看你的数据集和实验环境所影响。
目录
一、本文介绍
编辑
二、CARAFE的机制原理
2.1 CARAFE的基本原理
2.2 图解CARAFE原理
2.3 CARAFE的效果图
三、CARAFE的复现源码
四、添加CARAFE到模型中
4.1 CARAFE的添加教程
4.2 CARAFE的yaml文件和训练截图
4.2.1 CARAFE的yaml文件
4.2.2 CARAFE的训练过程截图
五、全文总结
二、CARAFE的机制原理
2.1 CARAFE的基本原理
CARAFE(Content-Aware ReAssembly of FEatures)是一种用于增强卷积神经网络特征图的上采样方法。这种方法首次在论文《CARAFE: Content-Aware ReAssembly of FEatures》中提出,旨在改进传统的上采样方法(如双线性插值和转置卷积)的性能。
CARAFE通过在每个位置利用底层内容信息来预测重组核,并在预定义的附近区域内重组特征。由于内容信息的引入,CARAFE可以在不同位置使用自适应和优化的重组核,从而比主流的上采样操作符(如插值或反卷积)表现更好。
CARAFE包括两个步骤:首先预测每个目标位置的重组核,然后用预测的核重组特征。给定一个尺寸为 H×W×C 的特征图和一个上采样比率 U,CARAFE将产生一个新的尺寸为 UH×UW×C 的特征图。其次CARAFE的核预测模块根据输入特征的内容生成位置特定的核,然后内容感知重组模块使用这些核来重组特征。
CARAFE可以无缝集成到需要上采样操作的现有框架中。在主流的密集预测任务中,CARAFE对高级和低级任务(如对象检测、实例分割、语义分割和图像修复)都有益处,且额外的参数微不足道。
2.2 图解CARAFE原理
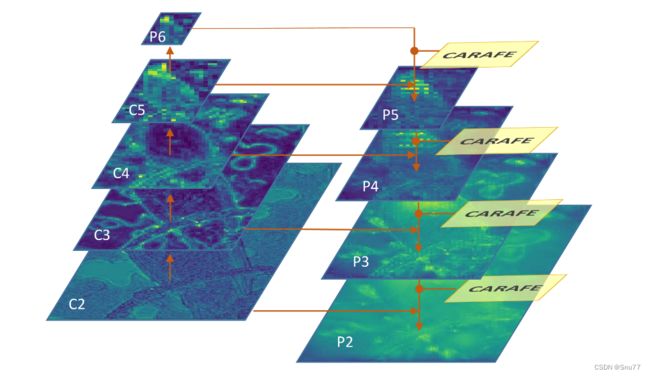
下图是CARAFE工作机制的示意图。左侧展示了来自Mask R-CNN的多层FPN(特征金字塔网络)特征(直至虚线左侧),右侧展示了集成了CARAFE的Mask R-CNN(直至虚线右侧)。对于采样的位置,该图显示了FPN自上而下路径中累积重组的区域。这样一个区域内的信息被重组到相应的重组中心。

下图展示了CARAFE的整体框架。CARAFE由两个关键部分组成,即核预测模块和内容感知重组模块。在这个框架中,一个尺寸为 H×W×C 的特征图被上采样因子 U(=2) 倍。

下图展示了集成了CARAFE的特征金字塔网络(FPN)架构。在这个架构中,CARAFE在FPN的自上而下路径中将特征图的尺寸上采样2倍。CARAFE通过无缝替换最近邻插值而整合到FPN中,从而优化了特征上采样的过程。
2.3 CARAFE的效果图
下图比较了COCO 2017验证集上基线(上面)和CARAFE(下面)在实例分割结果方面的差异。
总结:我个人觉得其实其效果提升比较一般甚至某些数据集上提点很微弱,但是它主要的作用是减少计算量是一个更加轻量化的上采样方法。

三、CARAFE的复现源码
我们将在“ultralytics/nn/modules”目录下面创建一个文件将其复制进去,使用方法在后面会讲。
import torch
import torch.nn as nn
from ultralytics.nn.modules import Conv
class CARAFE(nn.Module):
def __init__(self, c, k_enc=3, k_up=5, c_mid=64, scale=2):
""" The unofficial implementation of the CARAFE module.
The details are in "https://arxiv.org/abs/1905.02188".
Args:
c: The channel number of the input and the output.
c_mid: The channel number after compression.
scale: The expected upsample scale.
k_up: The size of the reassembly kernel.
k_enc: The kernel size of the encoder.
Returns:
X: The upsampled feature map.
"""
super(CARAFE, self).__init__()
self.scale = scale
self.comp = Conv(c, c_mid)
self.enc = Conv(c_mid, (scale * k_up) ** 2, k=k_enc, act=False)
self.pix_shf = nn.PixelShuffle(scale)
self.upsmp = nn.Upsample(scale_factor=scale, mode='nearest')
self.unfold = nn.Unfold(kernel_size=k_up, dilation=scale,
padding=k_up // 2 * scale)
def forward(self, X):
b, c, h, w = X.size()
h_, w_ = h * self.scale, w * self.scale
W = self.comp(X) # b * m * h * w
W = self.enc(W) # b * 100 * h * w
W = self.pix_shf(W) # b * 25 * h_ * w_
W = torch.softmax(W, dim=1) # b * 25 * h_ * w_
X = self.upsmp(X) # b * c * h_ * w_
X = self.unfold(X) # b * 25c * h_ * w_
X = X.view(b, c, -1, h_, w_) # b * 25 * c * h_ * w_
X = torch.einsum('bkhw,bckhw->bchw', [W, X]) # b * c * h_ * w_
return X
四、添加CARAFE到模型中
4.1 CARAFE的添加教程
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
需要注意的是本文的task.py配置的代码如下(你现在不知道其是干什么用的可以看添加教程)->
elif m is CARAFE:
args = [ch[f], *args]4.2 CARAFE的yaml文件和训练截图
4.2.1 CARAFE的yaml文件
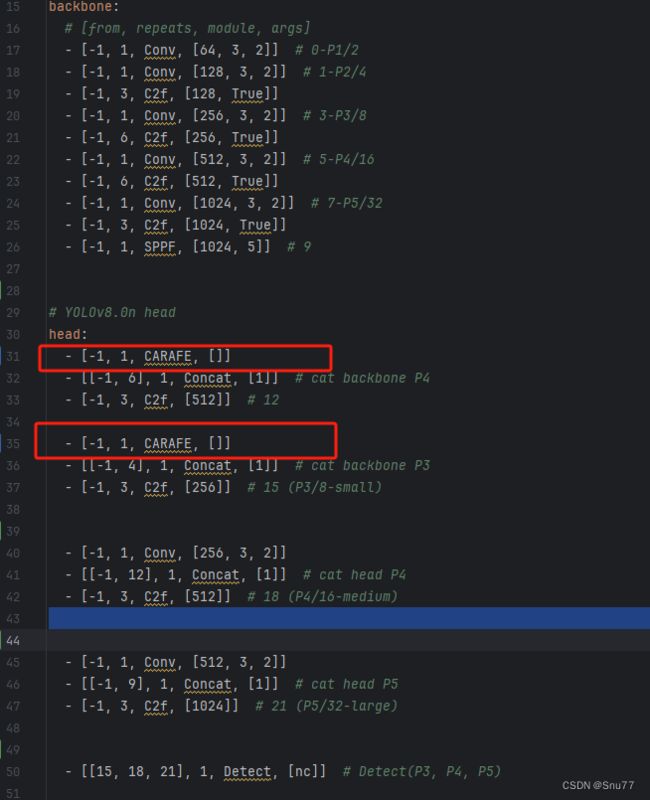
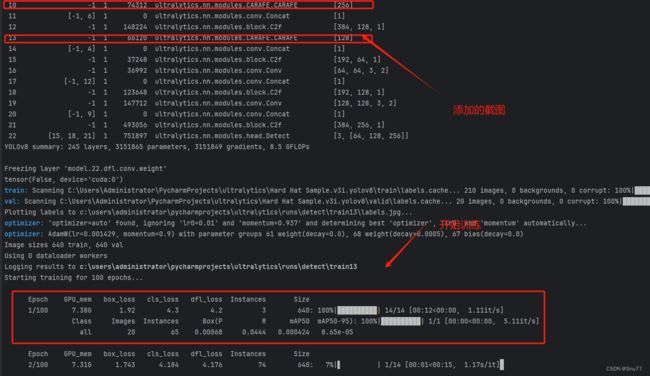
4.2.2 CARAFE的训练过程截图
下面是我添加了CARAFE的训练截图。
五、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备