阿里云Elasticsearch Severless 如何做到成本降低50%
阿里云检索分析服务 Elasticsearch 版云上演进之路
2017年,阿里云与Elastic 开启开源战略合作,正式发布阿里云检索分析服务 Elasticsearch 版 ,100%兼容开源Elasticsearch,开箱即用,提供开放兼容的云上检索分析服务。
2019年,阿里云实现 Elastic Stack 云上全托管,是国内首个将整个生态组件在云上做全托管的产品服务商, 提供端到端的检索分析解决方案,助力开源用户快速上云,规模化支撑万核云上用户。
2021年,面向市场推出了基于 Elasticsearch 内核引擎优化的版本,阿里内核深度优化 ,自研读写分离、存算分离架构,助力企业降本增效,并持续将版本背后的内核改进推动到 Elasticsearch 社区。
2023年,阿里云 Elasticsearch Serverless 服务正式上线。全新产品形态,基于云原生 Serverless 技术,致力于为用户打造更低成本、弹性灵活、开放兼容、开箱即用的云上 Elasticsearch 使用体验。

开源 Elasticsearch 面临的业务挑战
2017年至今,我们服务了数万企业级客户,运维了几十万个集群,总结了开源自建用户面临的常见痛点问题。
- 大促不断、游戏发版、蜂拥请求,突发读写流量,集群遇到资源瓶颈,在短时间内扩容困难
- 业务低峰期大量资源冗余,又因为某个时刻流量突增,不得不按高峰流量做容量规划
- 服务器资源成本高、研发、测试、生产预算低,又要稳定又要降本增效
- 项目团队没有专属的运维支持,集群稳定性运维难、需要随着业务发展持续优化,开发也要有运维经验

阿里云检索分析服务 Elasticsearch Serverless 版正式发布
基于上述挑战,我们推出了阿里云 Elasticsearch Serverless 服务。阿里云 Elasticsearch Serverless 是围绕 Elasticsearch 打造的云原生 Serverless 服务化产品,实现真正业务负载与资源动态匹配,用户无需管理集群及资源配置,只需根据实际资源使用按需付费;提供弹性扩缩能力,在高峰期也能满足业务需求;ES 原生态用户可以平滑切换和使用 Serverless 版本,助力业务快速上云。

Elasticsearch Serverless 服务核心能力解读
秒级弹性伸缩
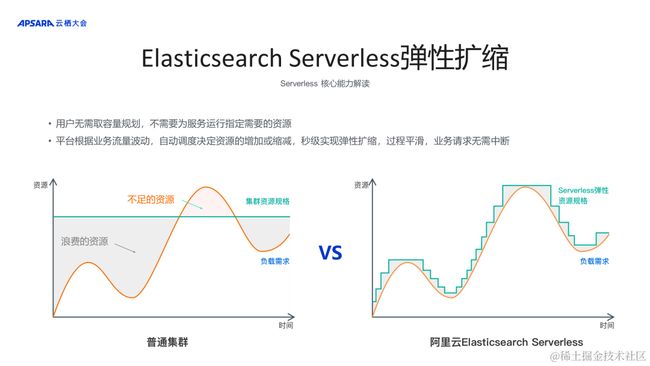
在 IDC 或者 ECS 上构建开源 Elasticsearch,需要提前规划集群规模,包括数据节点、协调节点和主节点数量以及每个节点需要配置的数据存储盘。另外在生产使用的过程中也需要基于业务流量的波动和变化调整集群规模,就会担心变更过程中集群的稳定性和安全性。
而阿里云 Elasticsearch Serverless 服务通过虚拟多租户的能力,将一个非常大的物理集群拆分成N个租户提供给用户,用户实际上拿到的是逻辑层面的单元,而非持有单个物理集群。当流量洪峰到来,资源消耗量高于设定的阈值时,就会为租户多分配一些已经存在的资源,不涉及到物理层面的扩容,灵活动态地调配给客户的资源上限和下限,实现真正意义上的弹性扩缩。另外逻辑层面单元中的扩容和缩容相对平滑,不会出现集群不稳定,业务抖动以及其他负面影响。
真正的按量付费
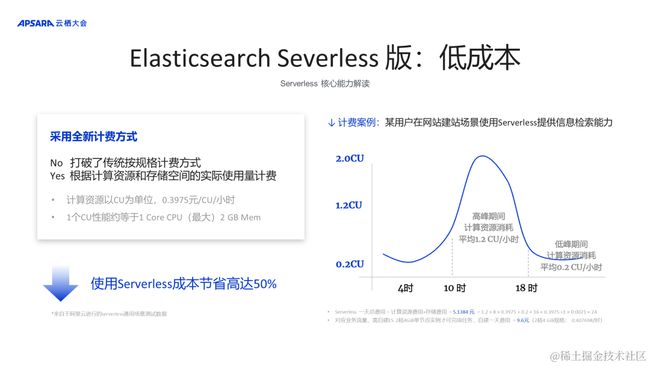
Elasticsearch 在使用的过程中有两部分的资源开销是规避不掉的,一部分是由CPU和Memory带来的计算资源;一部分是Store自带的存储资源。阿里云 Elasticsearch Serverless 服务打破传统按固定规格付费模式 、以CU为计算资源计费,1个CU性能约等于1 Core CPU(最大)2 GB Mem,按实际用量每小时出账,实现了真正意义上的按量付费。
对于CPU、Mem这些瞬时计算资源:按小时付费,将”流量的波动精确到每小时”,并且会计算一个小时周期内计算资源的平均值,进行计费,不用再担心毛刺、更不用担心预防毛刺导致的水位冗余。对于存储这样的持续占有性资源:也通过类似的手段,将“存储的波动精确到每小时”,并且会计算一个小时周期内存储资源的平均值,进行计费。虽然存储是持续性累计,但通过这样的方式,可以更灵活的使用云上 Elasticsearch 的存储,既不用担心买多了,也不用担心不够用。
举个例子,某用户有网站建站信息检索业务场景,白天有流量,晚上没有流量。
- 对应业务流量,需自建ES 2核4GiB单节点实例才可完成任务,自建一天费用 = 9.6元(2核4 GiB规格: 0.407698/时)。
- 而使用 Elasticsearch Serverless 服务一天总费用 = 计算资源费用+存储费用 = 1.2 × 8 × 0.3975 + 0.2 × 16 × 0.3975 +1 × 0.0021 × 24 = 5.1384 元
使用 Elasticsearch Serverless 服务成本节省高达50%,这还只是高峰期只有2CU的场景。真实生产环境里面,当并发 QPS 达到1000,需要的 RT 是100毫秒的时候,又需要冗余多少资源?使用阿里云 Elasticsearch Serverless 服务又能节约多少资源?
简单免运维
使用 Elasticsearch 的时候可能会面临一些复杂且不可避免的运维工作。资源准备阶段需要根据大量实际生产经验做容量规划和配置;研发部署阶段又有各种各样的环境,数以千计的参数需要配置;运维阶段还需要配置监控告警的大盘,遇到流量高峰需要盯盘,集群出现稳定性波动的时候还需要做集群恢复。
而阿里云 Elasticsearch Serverless 服务没有实体集群概念,不需要做任何形式或者种类的集群规划。基于智能化运维平台、读写分离和存算分离的引擎,基于阿里云最佳实践应用屏蔽了95%以上的运维成本,用户无需感知物理资源,1min即可快速创建。真正做到开箱即用,且无须人力干预资源水位及变配,大大提升了运维效率。

开放兼容
阿里云 Elasticsearch Serverless 服务支持 Elasticsearch 通用场景200+API、提供 Kibana、兼容各类开源组件,保留原有使用习惯,实现平滑迁移,助力业务快速上云。

Elasticsearch Serverless 服务技术架构
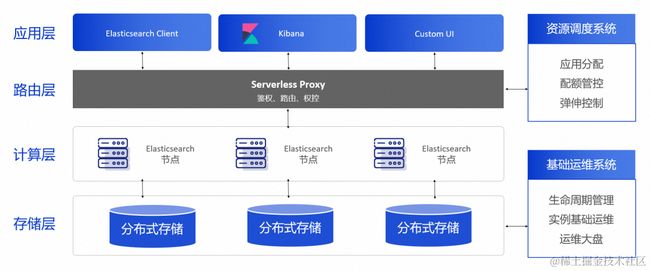
上图是 Elasticsearch Serverless 服务的技术架构图。最底下是存储层,这里写的是分布式存储,是多存储介质集联专门为搜索提供的存储服务,背后有 EBS 快存储、本地盘、高性能稳健存储和对象存储。在这个多级集联背后还有数据调度策略,什么样的数据查询密度高会放到本地盘里,什么样的数据查询密度低会放到对象存储里,在成本和性能中间博弈平衡,为用户带来性价比最高的面向搜索场景的存储体验。
再上一层是计算层,我们把 Elasticsearch 写数据的集群和查询索引的集群分开,就可以让资源在扩缩容的过程中更好、更精准地服务业务,也是实现真正意义上的按量付费和弹性扩缩的原因。
再往上一层是路由层,是 Elasticsearch Serverless 服务非常核心的环节,提供鉴权、路由、权控等相关能力。
最上面是和开源 API、开源组件以及客户业务场景相结合的应用层。
基于这样的四层架构, Elasticsearch Serverless 服务提供了免运维、弹性伸缩、低成本和开放兼容的产品能力。
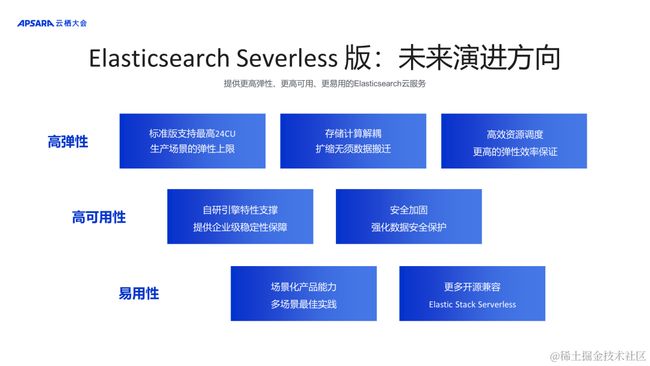
Elasticsearch Serverless 服务未来演进方向
持续提升产品能力
提供更高弹性、更高可用、更易用的 Elasticsearch 云服务:
- 高弹性
提高生产场景弹性上限;存储计算解耦;更高的弹性效率保证
- 高可用性
自研引擎特性支撑 、提供企业级稳定性保障;安全加固 、强化数据安全保护
- 易用性
场景化产品能力 、提供多场景最佳实践;提供更多开源兼容 、实现 Elastic Stack Serverless
持续提供解决方案
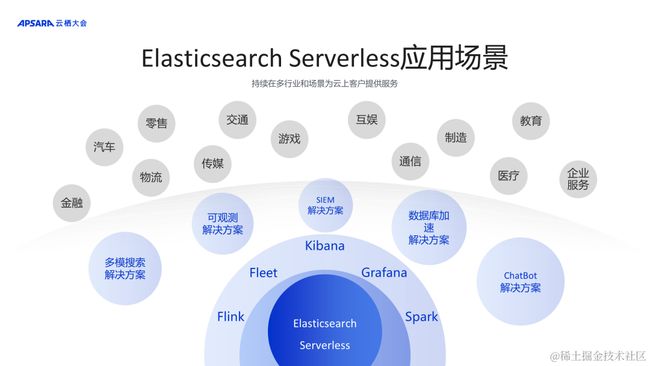
持续在多行业和场景为云上客户提供服务 :
我们希望拥抱各个垂直场景,围绕 Elasticsearch 生态,借助解决方案封装来服务更多的场景需求。在云上构建更多诸如多模态搜索、可观测、SIEM、数据库加速、ChatBot 问答交互等的解决方案。同时与各个场景的合作伙伴一起,打造中国搜索的应用级市场,借助阿里云的 PaaS 产品、技术的沉淀,以及云上客户和业务的积累,为中国市场提供更优质的产品、解决方案等诸多的服务能力。