Spring 声明式事务
参考文章:
Spring事务管理(详解+实例)
事务管理是企业级应用程序开发中必备技术,用来确保数据的完整性和一致性。
1、何为事务?
事务就是把一系列的动作当成一个独立的工作单元,这些动作要么全部完成,要么全部不起作用。就是把一系列的操作当成原子性去执行。
事务四个属性ACID
1、原子性(atomicity)
事务是原子性操作,由一系列动作组成,事务的原子性确保动作要么全部完成,要么完全不起作用
2、一致性(consistency)
一旦所有事务动作完成,事务就要被提交。数据和资源处于一种满足业务规则的一致性状态中
3、隔离性(isolation)
可能多个事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏
4、持久性(durability)
事务一旦完成,无论系统发生什么错误,结果都不会受到影响。通常情况下,事务的结果被写到持久化存储器中
2、Spring中的事务管理
Spring在不同的事务管理API之上定义了一个抽象层,使得开发人员不必了解底层的事务管理API就可以使用Spring的事务管理机制。Spring支持编程式事务管理和声明式的事务管理。
在事务控制方面,主要有两个分类:
编程式事务:在代码中直接加入处理事务的逻辑,可能需要在代码中显式调用beginTransaction()、commit()、rollback()等事务管理相关的方法
connetion.autoCommit(false);
------
----
---
connction.commint()
catch(){
connction.rollback();
}
缺点:必须在每个事务操作业务逻辑中包含额外的事务管理代码
声明式事务:在方法的外部添加注解或者直接在配置文件中定义,将事务管理代码从业务方法中分离出来,以声明的方式来实现事务管理。spring的AOP恰好可以完成此功能:事务管理代码的固定模式作为一种横切关注点,通过AOP方法模块化,进而实现声明式事务。
3、事务管理器
Spring从不同的事务管理API中抽象出了一整套事务管理机制,让事务管理代码从特定的事务技术中独立出来。开发人员通过配置的方式进行事务管理,而不必了解其底层是如何实现的。
Spring的核心事务管理抽象是PlatformTransactionManager,管理封装了一组独立于技术的方法,无论使用Spring的哪种事务管理策略(编程式或者声明式)事务管理器都是必须的。
Public interface PlatformTransactionManager()...{
// 由TransactionDefinition得到TransactionStatus对象
TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException;
// 提交
Void commit(TransactionStatus status) throws TransactionException;
// 回滚
Void rollback(TransactionStatus status) throws TransactionException;
} 
JDBC事务:如果应用程序中直接使用JDBC来进行持久化,DataSourceTransactionManager会为你处理事务边界。为了使用DataSourceTransactionManager,你需要使用如下的XML将其装配到应用程序的上下文定义中:
实际上,DataSourceTransactionManager是通过调用java.sql.Connection来管理事务,而后者是通过DataSource获取到的。通过调用连接的commit()方法来提交事务,同样,事务失败则通过调用rollback()方法进行回滚。
Hibernate事务
sessionFactory属性需要装配一个Hibernate的session工厂,HibernateTransactionManager的实现细节是它将事务管理的职责委托给org.hibernate.Transaction对象,而后者是从Hibernate Session中获取到的。当事务成功完成时,HibernateTransactionManager将会调用Transaction对象的commit()方法,反之,将会调用rollback()方法。
JPA事务
JpaTransactionManager只需要装配一个JPA实体管理工厂(javax.persistence.EntityManagerFactory接口的任意实现)。JpaTransactionManager将与由工厂所产生的JPA EntityManager合作来构建事务。
Java原生API事务
通常用于跨越多个事务管理源(多数据源),则需要使用下面的内容
JtaTransactionManager将事务管理的责任委托给javax.transaction.UserTransaction和javax.transaction.TransactionManager对象,其中事务成功完成通过UserTransaction.commit()方法提交,事务失败通过UserTransaction.rollback()方法回滚。
4、声明式事务的简单配置
4.1、在配置文件中添加事务管理器
spring.xml
现在以一个简单例子,转账,张三给李四转200元
首先建一张简单的表
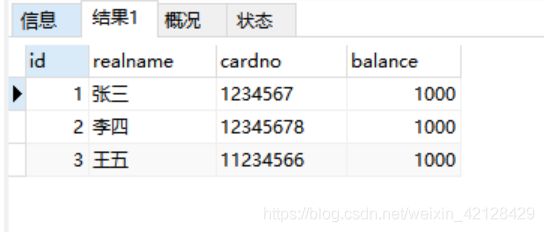
UserServiceImpl.java
package com.tuling.service.impl;
import com.tuling.dao.IUserDao;
import com.tuling.entity.User;
import com.tuling.service.IUserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author fanzitianxing
* @title: UserServiceImpl
* @projectName spring_transaction
* @description: TODO
* @date 2021/7/1914:31
*/
@Service
public class UserServiceImpl implements IUserService {
@Autowired
IUserDao userDao;
/**
*功能描述 转账
* @author fanzitianxing
* @date 2021/7/21
* @param []
* @return void
*/
public void trans(){
// 张三扣钱
sub();
//张三扣完钱 报错
int i = 1/0;
//李四存钱
save();
}
/**
*功能描述 扣钱
* @author fanzitianxing
* @date 2021/7/21
* @param []
* @return void
*/
public void sub(){
userDao.sub();
}
/**
*功能描述 存钱
* @author fanzitianxing
* @date 2021/7/21
* @param []
* @return void
*/
public void save(){
userDao.save();
}
public User getUser() {
return userDao.getUser();
}
}
UserDaoImpl.java
package com.tuling.dao.impl;
import com.alibaba.druid.pool.DruidDataSource;
import com.tuling.dao.IUserDao;
import com.tuling.entity.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
/**
* @author fanzitianxing
* @title: UserDaoImpl
* @projectName spring_transaction
* @description: TODO
* @date 2021/7/1914:34
*/
@Repository
public class UserDaoImpl implements IUserDao {
private JdbcTemplate jdbcTemplate;
@Autowired
public void setDataSource(DruidDataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public User getUser() {
return jdbcTemplate.queryForObject("select * from t_user where id=1",new BeanPropertyRowMapper(User.class));
}
/**
*功能描述 张三扣钱
* @author fanzitianxing
* @date 2021/7/21
* @param []
* @return void
*/
public void sub() {
jdbcTemplate.update("update t_user set balance=balance-200 where id=1");
}
/**
*功能描述 李四加钱
* @author fanzitianxing
* @date 2021/7/21
* @param []
* @return void
*/
public void save() {
jdbcTemplate.update("update t_user set balance=balance+200 where id=2");
}
}
上面代码中,张三扣钱之后抛错,不会执行李四加钱,首先测试一下在没有添加事务管理之前,执行结果:
public class TransactionTest {
ClassPathXmlApplicationContext ioc;
@Before
public void before(){
ioc = new ClassPathXmlApplicationContext("spring.xml");
}
@Test
public void test01(){
IUserService userService = ioc.getBean(IUserService.class);
userService.trans();
}
}
执行完张三扣钱之后报错,未执行李四加钱,看一下数据库
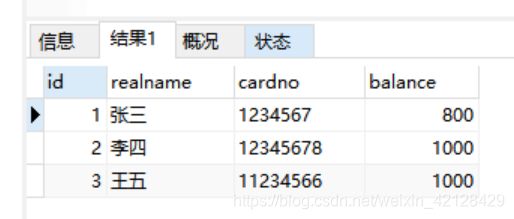
报错之后,张三扣钱的操作是没有回滚的
现在我们添加声明式事务管理:在转账方法上添加@Transactional注解
/**
*功能描述 转账
* @author fanzitianxing
* @date 2021/7/21
* @param []
* @return void
*/
@Transactional
public void trans(){
// 张三扣钱
sub();
//张三扣完钱 报错
int i = 1/0;
//李四存钱
save();
}再测试一下:
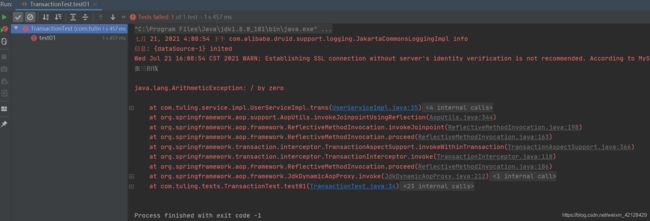
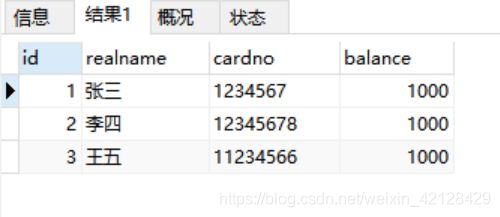
结果来看,报错之后,事务进行了回滚
@Transactional注解应该写在哪:
@Transactional 可以标记在类上面(当前类所有的方法都运用上了事务)
@Transactional 标记在方法则只是当前方法运用事务
也可以类和方法上面同时都存在, 如果类和方法都存在@Transactional会以方法的为准。如果方法上面没有@Transactional会以类上面的为准
建议:@Transactional写在方法上面,控制粒度更细, 建议@Transactional写在业务逻辑层上,因为只有业务逻辑层才会有嵌套调用的情况。
4.2事务配置的属性
上面讲到的事务管理器接口PlatformTransactionManager通过getTransaction(TransactionDefinition definition)方法来得到事务,这个方法里面的参数是TransactionDefinition类,这个类就定义了一些基本的事务属性。
那么什么是事务属性呢?事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性包含了5个方面,如图所示:
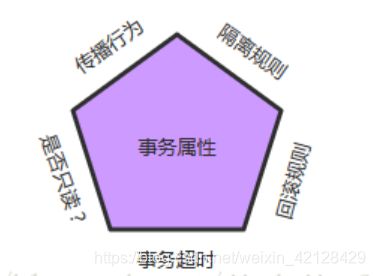
而TransactionDefinition接口内容如下:
public interface TransactionDefinition {
int getPropagationBehavior(); // 返回事务的传播行为
int getIsolationLevel(); // 返回事务的隔离级别,事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
int getTimeout(); // 返回事务必须在多少秒内完成
boolean isReadOnly(); // 事务是否只读,事务管理器能够根据这个返回值进行优化,确保事务是只读的
} 我们可以发现TransactionDefinition正好用来定义事务属性,下面详细介绍一下各个事务属性。
isolation:设置事务的隔离级别
propagation:事务的传播行为
noRollbackFor:那些异常事务可以不回滚
noRollbackForClassName:填写的参数是全类名
rollbackFor:哪些异常事务需要回滚
rollbackForClassName:填写的参数是全类名
readOnly:设置事务是否为只读事务
timeout:事务超出指定执行时长后自动终止并回滚,单位是秒
4.2.1传播行为
事务的第一个方面是传播行为(propagation behavior)。当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。Spring定义了七种传播行为:
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_REQUIRED_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
注:以下具体讲解传播行为的内容参考自Spring事务机制详解
(1)PROPAGATION_REQUIRED 如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
//事务属性 PROPAGATION_REQUIRED
methodA{
……
methodB();
……
}//事务属性 PROPAGATION_REQUIRED
methodB{
……
}使用spring声明式事务,spring使用AOP来支持声明式事务,会根据事务属性,自动在方法调用之前决定是否开启一个事务,并在方法执行之后决定事务提交或回滚事务。
单独调用methodB方法:
main{
metodB();
} 相当于
Main{
Connection con=null;
try{
con = getConnection();
con.setAutoCommit(false);
//方法调用
methodB();
//提交事务
con.commit();
} Catch(RuntimeException ex) {
//回滚事务
con.rollback();
} finally {
//释放资源
closeCon();
}
} Spring保证在methodB方法中所有的调用都获得到一个相同的连接。在调用methodB时,没有一个存在的事务,所以获得一个新的连接,开启了一个新的事务。
单独调用MethodA时,在MethodA内又会调用MethodB.
main{
Connection con = null;
try{
con = getConnection();
methodA();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
closeCon();
}
} 调用MethodA时,环境中没有事务,所以开启一个新的事务.当在MethodA中调用MethodB时,环境中已经有了一个事务,所以methodB就加入当前事务。
(2)PROPAGATION_SUPPORTS 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。但是对于事务同步的事务管理器,PROPAGATION_SUPPORTS与不使用事务有少许不同。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_SUPPORTS
methodB(){
……
}单纯的调用methodB时,methodB方法是非事务的执行的。当调用methdA时,methodB则加入了methodA的事务中,事务地执行。
(3)PROPAGATION_MANDATORY 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
//事务属性 PROPAGATION_REQUIRED
methodA(){
methodB();
}
//事务属性 PROPAGATION_MANDATORY
methodB(){
……
}当单独调用methodB时,因为当前没有一个活动的事务,则会抛出异常throw new IllegalTransactionStateException(“Transaction propagation ‘mandatory’ but no existing transaction found”);当调用methodA时,methodB则加入到methodA的事务中,事务地执行。
(4)PROPAGATION_REQUIRES_NEW 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_REQUIRES_NEW
methodB(){
……
}调用A方法:
main(){
methodA();
}相当于
main(){
TransactionManager tm = null;
try{
//获得一个JTA事务管理器
tm = getTransactionManager();
tm.begin();//开启一个新的事务
Transaction ts1 = tm.getTransaction();
doSomeThing();
tm.suspend();//挂起当前事务
try{
tm.begin();//重新开启第二个事务
Transaction ts2 = tm.getTransaction();
methodB();
ts2.commit();//提交第二个事务
} Catch(RunTimeException ex) {
ts2.rollback();//回滚第二个事务
} finally {
//释放资源
}
//methodB执行完后,恢复第一个事务
tm.resume(ts1);
doSomeThingB();
ts1.commit();//提交第一个事务
} catch(RunTimeException ex) {
ts1.rollback();//回滚第一个事务
} finally {
//释放资源
}
}在这里,我把ts1称为外层事务,ts2称为内层事务。从上面的代码可以看出,ts2与ts1是两个独立的事务,互不相干。Ts2是否成功并不依赖于 ts1。如果methodA方法在调用methodB方法后的doSomeThingB方法失败了,而methodB方法所做的结果依然被提交。而除了 methodB之外的其它代码导致的结果却被回滚了。使用PROPAGATION_REQUIRES_NEW,需要使用 JtaTransactionManager作为事务管理器。
(5)PROPAGATION_NOT_SUPPORTED 总是非事务地执行,并挂起任何存在的事务。使用PROPAGATION_NOT_SUPPORTED,也需要使用JtaTransactionManager作为事务管理器。(代码示例同上,可同理推出)
(6)PROPAGATION_NEVER 总是非事务地执行,如果存在一个活动事务,则抛出异常。
(7)PROPAGATION_NESTED如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行。这是一个嵌套事务,使用JDBC 3.0驱动时,仅仅支持DataSourceTransactionManager作为事务管理器。需要JDBC 驱动的java.sql.Savepoint类。有一些JTA的事务管理器实现可能也提供了同样的功能。使用PROPAGATION_NESTED,还需要把PlatformTransactionManager的nestedTransactionAllowed属性设为true;而 nestedTransactionAllowed属性值默认为false。
//事务属性 PROPAGATION_REQUIRED
methodA(){
doSomeThingA();
methodB();
doSomeThingB();
}
//事务属性 PROPAGATION_NESTED
methodB(){
……
}如果单独调用methodB方法,则按REQUIRED属性执行。如果调用methodA方法,相当于下面的效果:
main(){
Connection con = null;
Savepoint savepoint = null;
try{
con = getConnection();
con.setAutoCommit(false);
doSomeThingA();
savepoint = con2.setSavepoint();
try{
methodB();
} catch(RuntimeException ex) {
con.rollback(savepoint);
} finally {
//释放资源
}
doSomeThingB();
con.commit();
} catch(RuntimeException ex) {
con.rollback();
} finally {
//释放资源
}
}当methodB方法调用之前,调用setSavepoint方法,保存当前的状态到savepoint。如果methodB方法调用失败,则恢复到之前保存的状态。但是需要注意的是,这时的事务并没有进行提交,如果后续的代码(doSomeThingB()方法)调用失败,则回滚包括methodB方法的所有操作。
嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:它们非常类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。使用 PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。同时它需要JTA事务管理器的支持。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。DataSourceTransactionManager使用savepoint支持PROPAGATION_NESTED时,需要JDBC 3.0以上驱动及1.4以上的JDK版本支持。其它的JTA TrasactionManager实现可能有不同的支持方式。
PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 “内部” 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行。
另一方面, PROPAGATION_NESTED 开始一个 “嵌套的” 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交。
由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于, PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 嵌套事务也会被 commit, 这个规则同样适用于 roll back.
PROPAGATION_REQUIRED应该是我们首先的事务传播行为。它能够满足我们大多数的事务需求。
4.2.2 隔离级别
事务的第二个维度就是隔离级别(isolation level)。隔离级别定义了一个事务可能受其他并发事务影响的程度。
(1)并发事务引起的问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务。并发虽然是必须的,但可能会导致一下的问题。
- 脏读(Dirty reads)——脏读发生在一个事务读取了另一个事务改写但尚未提交的数据时。如果改写在稍后被回滚了,那么第一个事务获取的数据就是无效的。(解决方式:@Transactional(isolation = Isolation.READ_COMMITTED) ;读已提交:READ COMMITTED)
- 不可重复读(Nonrepeatable read)——不可重复读发生在一个事务执行相同的查询两次或两次以上,但是每次都得到不同的数据时。这通常是因为另一个并发事务在两次查询期间进行了更新。(
解决方式:@Transactional(isolation = Isolation.REPEATABLE_READ)
可重复读:REPEATABLE READ
确保Transaction01可以多次从一个字段中读取到相同的值,即Transaction01执行期间禁止其它事务对这个字段进行更新。(行锁)
)- 幻读(Phantom read)——幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录。(
解决方式:@Transactional(isolation = Isolation.SERIALIZABLE)
串行化:SERIALIZABLE
确保Transaction01可以多次从一个表中读取到相同的行,在Transaction01执行期间,禁止其它事务对这个表进行添加、更新、删除操作。可以避免任何并发问题,但性能十分低下。(表锁)
)
不可重复读与幻读的区别
不可重复读的重点是修改:
同样的条件, 你读取过的数据, 再次读取出来发现值不一样了
例如:在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
con1 = getConnection();
select salary from employee empId ="Mary"; 在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
con2 = getConnection();
update employee set salary = 2000;
con2.commit(); 在事务1中,Mary 再次读取自己的工资时,工资变为了2000
//con1
select salary from employee empId ="Mary"; 在一个事务中前后两次读取的结果并不一致,导致了不可重复读。
幻读的重点在于新增或者删除:
同样的条件, 第1次和第2次读出来的记录数不一样
例如:目前工资为1000的员工有10人。事务1,读取所有工资为1000的员工。
con1 = getConnection();
Select * from employee where salary =1000; 共读取10条记录
这时另一个事务向employee表插入了一条员工记录,工资也为1000
con2 = getConnection();
Insert into employee(empId,salary) values("Lili",1000);
con2.commit(); 事务1再次读取所有工资为1000的员工
//con1
select * from employee where salary =1000; 共读取到了11条记录,这就产生了幻像读。
从总的结果来看, 似乎不可重复读和幻读都表现为两次读取的结果不一致。但如果你从控制的角度来看, 两者的区别就比较大。
对于前者, 只需要锁住满足条件的记录。
对于后者, 要锁住满足条件及其相近的记录。
(2)隔离级别
| 隔离级别 | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 |
| ISOLATION_READ_COMMITTED | 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 |
| ISOLATION_REPEATABLE_READ | 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生 |
| ISOLATION_SERIALIZABLE | 最高的隔离级别,完全服从ACID的隔离级别,确保阻止脏读、不可重复读以及幻读,也是最慢的事务隔离级别,因为它通常是通过完全锁定事务相关的数据库表来实现的 |
4.2.3 只读
事务的第三个特性是它是否为只读事务。如果事务只对后端的数据库进行该操作,数据库可以利用事务的只读特性来进行一些特定的优化。通过将事务设置为只读,你就可以给数据库一个机会,让它应用它认为合适的优化措施。
readonly:只会设置在查询的业务方法中
connection.setReadOnly(true) 通知数据库,当前数据库操作是只读,数据库就会对当前只读做相应优化
当将事务设置只读 就必须要你的业务方法里面没有增删改。
如果你一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持SQL执行期间的读一致性;
如果你一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询SQL必须保证整体的读一致性,否则,在前条SQL查询之后,后条SQL查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持(如:设置不可重复度、幻影读级别)。
对于只读事务,可以指定事务类型为readonly,即只读事务。由于只读事务不存在数据的修改,因此数据库将会为只读事务提供一些优化手段
4.2.4 事务超时
为了使应用程序很好地运行,事务不能运行太长的时间。因为事务可能涉及对后端数据库的锁定,所以长时间的事务会不必要的占用数据库资源。事务超时就是事务的一个定时器,在特定时间内事务如果没有执行完毕,那么就会自动回滚,而不是一直等待其结束。
4.2.5 回滚规则
事务五边形的最后一个方面是一组规则,这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚(这一行为与EJB的回滚行为是一致的)
但是你可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚。同样,你还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
noRollbackFor:那些异常事务可以不回滚
noRollbackForClassName:填写的参数是全类名
rollbackFor:哪些异常事务需要回滚
rollbackForClassName:填写的参数是全类名
4.2.6在实战中事务的使用方式
如果当前业务方法是一组 增、改、删 可以这样设置事务
@Transactional
如果当前业务方法是一组 查询 可以这样设置事务
@Transactionl(readOnly=true)
如果当前业务方法是单个 查询 可以这样设置事务
@Transactionl(propagation=propagation.SUPPORTS ,readOnly=true)
4.3 事务状态
上面讲到的调用PlatformTransactionManager接口的getTransaction()的方法得到的是TransactionStatus接口的一个实现,这个接口的内容如下:
public interface TransactionStatus{
boolean isNewTransaction(); // 是否是新的事物
boolean hasSavepoint(); // 是否有恢复点
void setRollbackOnly(); // 设置为只回滚
boolean isRollbackOnly(); // 是否为只回滚
boolean isCompleted; // 是否已完成
} 可以发现这个接口描述的是一些处理事务提供简单的控制事务执行和查询事务状态的方法,在回滚或提交的时候需要应用对应的事务状态。