多篇论文介绍-可变形卷积

01 具有双层路由注意力的 YOLOv8 道路场景目标检测方法
01 摘要:
随着机动车的数量不断增加,道路交通环境变得更复杂,尤其是光照变化以及复杂背景都会干扰目标检测算法的准确性和精度,同时道路场景下多变形态的目标也会给检测任务造成干扰,针对这一系列问题,提出了一种YOLOv8n_T方法,在YOLOv8的基础上首先针对骨干网络构建了基于可变形卷积的D_C2f块,强化了特征提取网络对复杂背景下目标的特征学习,更好地适应道路目标复杂多变的情形;其次增加了双层路由注意力模块,以查询自适应的方式去除不相关的区域,留下相关度最高的区域;最后针对道路上行人、交通灯等小目标增加小目标检测层,实验表明,提出的 YOLOv8n_T有效提高了模型在道路场景下的目标检测精度,在BDD100K数据集上的平均精度比原始YOLOv8n提升了6.8个百分点,比YOLOv5n提升了11.2个百分点。
关键词:可变形卷积;道路场景;目标检测;YOLO;注意力机制
02 模块介绍
在传统卷积中,每个卷积核都是固定形状的,因此无法处理物体形变的情况。而可变形卷积中,每个卷积核不再是一个固定的矩形,而是由一个基础网格和一组偏移量共同组成的可变形矩形。在进行卷积操作时,可以根据形状偏移量动态地调整卷积核的形态,从而更好地适应物体的形变。


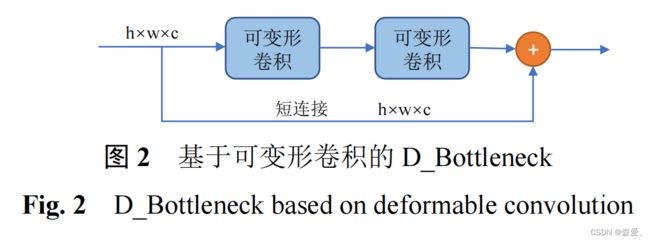
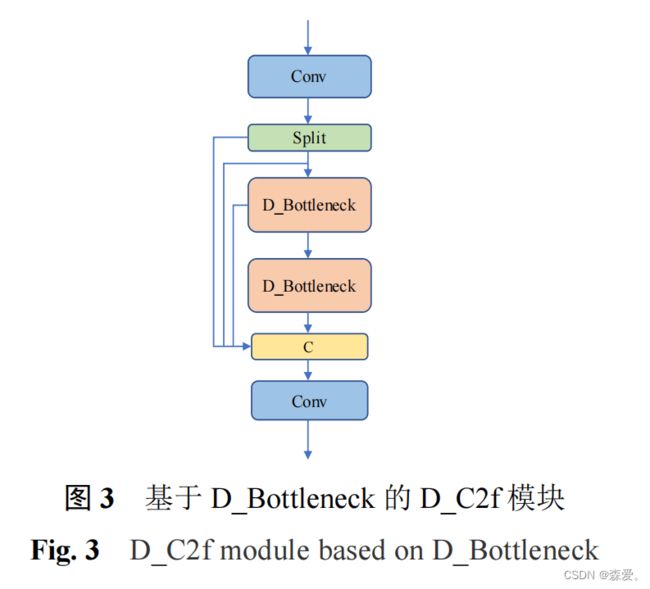
02 基于空间注意力和可变形卷积的田间障碍物检测方法
01 摘要
摘要:为了解决传统田间障碍物识别方法依赖人工提取特征,计算耗时较长,难以实现在非结构化田间环境下实时作业识别的问题,提出一种优化的Mask R-CNN模型的非结构化农田障碍物实例分割方法。以ResNet50残差网络为基础,将空间注意力(Spatial attention, SA)引入残差结构,聚焦跟踪目标的显著性表观特征并主动抑制噪声等无用特征的影响;引入可变形卷积(Deformable convolution, DCN),通过加入偏移量,增大感受野,提高模型的鲁棒性。构建包含农田典型障碍物的数据集,通过对比实验研究在ResNet残差网络结构中的不同阶段中加入空间注意力和可变形卷积时的模型性能差异。结果表明,与Mask R-CNN原型网络相比,在ResNet的阶段2、阶段3、阶段5加入空间注意力和可变形卷积后,改进Mask R-CNN的边界框(Bbox)和掩膜(Mask)的平均精度均值(mAP)分别从、64.5%、56.9%提高到71.3%、62.3%。本文提出的改进Mask R-CNN可以很好地实现农田障碍物检测,可为植保无人机在非结构化农田环境下安全高效工作提供技术支撑。
关键词:田间障碍物;Mask R-CNN;空间注意力;可变形卷积
02 模块介绍
由于非结构化田间障碍物形态各异,面积大小不一,这给障碍物识别任务带来了很大的困难,而且以往的卷积神经网络对整体特征的提取是依靠其固定的卷积结构,对于形态各异的目标特征提取的适应、调节能力较弱,目标识别能力不强,泛化能力差。实际上,传统的神经网络的卷积核通常是固定尺寸、固定大小的(3×3、5×5),难以自适应目标的形状变化[25]。为了解决限制传统卷积神经网络识别能力的这一难题,DAI等126提出了一种可变形卷积网络,替代传统的标准卷积,经研究表明,通过可变形卷积网络增加可训练的偏移量,从而适应目标形状的变化,有利于提高目标检测的鲁棒性[34-36]
二维卷积的操作步骤为:①在输入特征图x上使用规则网格 R 进行采样;②用 加权的采样值进行求和。 一个 3×3 的卷积为

03 改进 YOLOv5 的高精度跌倒检测算法
01 摘要
摘要:针对原始YOLOv5在人体跌倒检测任务中无法有效应对复杂细节捕捉、变形处理、不同尺度目标适应和遮挡检测的困境,提出了一种基于C2D改进YOLOv5模型的新型高精度跌倒检测算法C2D-YOLO。首先,提出了一种名为C2D的新型特征提取模块,通过融合可变形卷积、标准卷积和通道空间混合注意机制,将其添加到主干网络中,旨在增强特征表征能力、更好地捕捉复杂细节和处理变形。其次,在颈部网络中,采用了Swin Transformer Block替代C3模块的瓶颈层,旨在最大限度地保留特征信息,以提升对不同尺度目标的检测精度并改善遮挡情况下的性能。最后,在借鉴YOLOX解耦结构的基础上对Yolov5的Head模块进行改进,旨在优化分类和回归性能。实验结果表明,相比现有的YOLOv5s,该方法的mAPO.5和mAP0.5:0.95分别提高了3.2%和6.5%,明显提升了检测精度,减少了误检率。
关键词: YOLOv5;跌倒检测; C2D; Swim Transformer Block;解耦结构
02 模块介绍
跌倒检测任务场景具备独特且复杂的特征,包括广泛的姿态变化、丰富的细节以及目标形变。因此,在特征提取阶段仅使用标准卷积会导致一系列问题。首先,仅采用标准卷积( Standard Convolution, sC137)可能未能有效捕捉目标的细粒度细节,尤其是在涉及姿态较大的跌倒动作时,其感受野调整能力有限,导致细节信息的丢失或模糊。其次,标准卷积无法适应目标的形变,无法自适应地调整卷积核的采样位置,导致目标的定位准确性下降,容易产生误检。
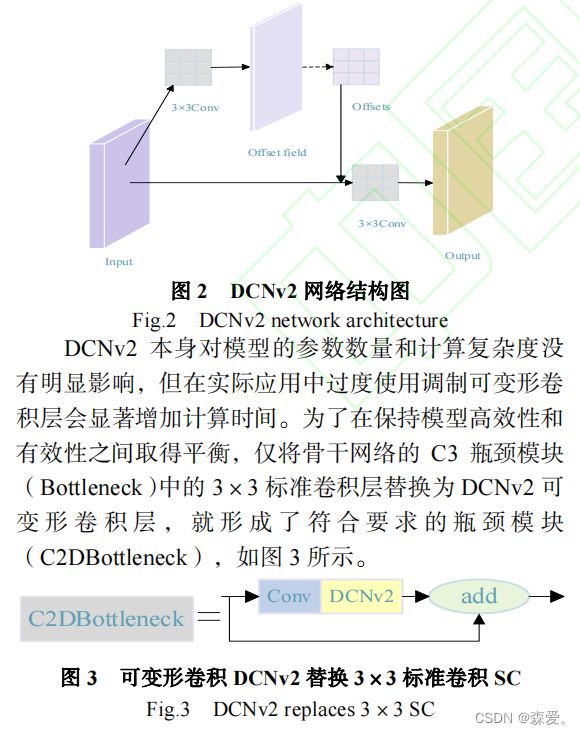
为了适应跌倒检测场景的特点并弥补仅使用标准卷积的不足,在特征提取阶段引入了可变形卷积第二版(Deformable ConvNets version 2,DCNv2[38] ) 。
DCNv2通过引入可学习的形变参数,具备更强的感受野调整能力,能够更好地捕捉目标的细粒度细节并适应目标的形变。这种模块的引入填补了标准卷积在跌倒检测中的局限性,提升了特征表示能力和目标定位准确性,从而有效提升跌倒检测系统的性能和鲁棒性。这种优化方法能够更准确地检测和识别跌倒事件,提高整个系统在复杂场景下的可靠性。
可变形卷积DCN是一种改进的卷积操作,通过引入偏移量来调整卷积核的形状,以更好地提取输入特征。DCNv2是对可变形卷积的改进,通过学习偏移和加权,提高了模型从变形物体中提取特征的能力。如图2所示,DCNv2包含两个步骤。首先是偏移量生成:通过卷积操作生成卷积核在输入特征图上沿着x和y方向的采样点偏移量。其次是采样和卷积:利用输入特征图和计算得到的偏移量进行双线性插值,确定卷积核在输入特征图上的采样点位置。最后,利用这些采样点进行卷积操作。
04 改进 YOLOv8 算法的遥感图像目标检测
01 摘要
摘要:针对遥感图像目标检测算法漏检和误检率高、目标定位不精确、无法准确识别目标类别等问题,提出一种改进YOLOv8的目标检测算法。为提高模型的损失函数对梯度分配的灵活性,适应各种形状和尺寸的物体,设计了非单调聚焦机制与边界框几何因素相结合的边界框回归损失函数;为扩大模型的感受野并削弱遥感图像背景对检测目标的影响,采用全局注意力机制与残差块结合的方式,设计了残差全局注意力机制;为使模型适应遥感图像中目标物体的形变与不规则排列,对YOLOv8模型中的C2f模块进行改进,融入可变形卷积与可变形RoI池化层。实验结果表明,在 DOTA数据集和RSOD数据集上,改进YOLOv8算法的[email protected]达到72.1%和94.6%,优于其它对比主流算法,提高了遥感图像目标检测的精度,为遥感图像识别提供了新的手段。
关键词目标检测;YOLOv8;WloU;GAM注意力机制;可变形卷积
02 模块介绍
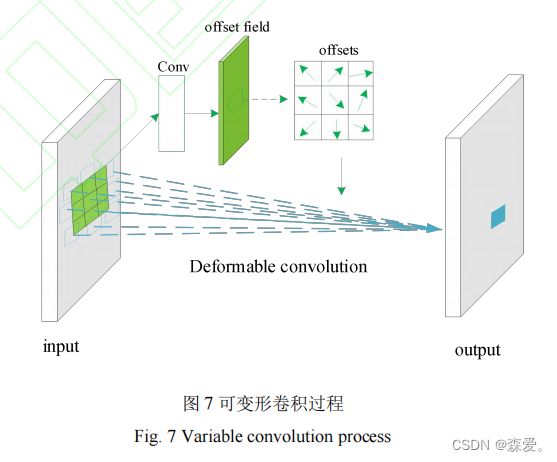
传统的卷积操作中,卷积核具有固定的像素点的位置,对输入图像的每个位置应用相同的卷积核。而在实际上,不同位置的图像可能具有不同的形变,常规卷积无法适应遥感图像的不规则布局与非刚性形变,因此可能导致遥感目标的特征提取不准确。
以3*3卷积为例,普通卷积对于每一个输出特征图y,都要从输入特征图进行规则采样,再经过加权计算。其中采样是以中心位置向四周扩散得到的9个点,所得到的网格定义为R,如式( 16)所示



05 基于 SimAM 注意力机制的 DCN-YOLOv5 水下目标检测
01 摘要
摘要:【目的】针对水下环境复杂,水下目标因光线折射等问题导致的目标边界模糊或外观、形状可能会发生非刚性形变,使水下目标检测困难,提出了一种基于SimAM注意力机制的 DCN-YOLOv5水下目标检测方法。【方法】首先,采用YOLOv5所使用的双向金字塔网络(BiFPN, Bi-directional Feature Pyramid Network)在多个尺度上提取和融合特征信息,从而提高目标辨别的准确度;其次,针对水下目标的外观、形状的变化问题,将C3模块中的CBS模块结合可变形卷积(DCN, Deformable Convolution),提出DBS模块并组成D3模块替换部分C3模块,以适应水下目标的外观、形状的变化;同时,融入加权注意力机制(SimAM自适应地调节模型的关注度,进一步在复杂场景下增强特征表达能力;最后,考虑目标边界模糊,为改善目标定位精度,采用WIloU(Wise-loU)损失函数来替换交叉嫡损失,能够更好地适应不同目标类型和尺寸的特点,提高算法鲁棒性。【结果】实验结果表明,DCN-YOLOv5可以达到87.57%的平均精度(mAP),检测效果优于YOLOv5网络和其他经典网络,平均每张图像的识别时间仅为24.5ms。【结论】通过实验结果可以证明模型在检测精度明显提升的同时兼顾检测的实时性,对水下目标检测用于实际用途有着一定的参考价值。
关键词:水下目标检测; SimAM注意力机制;可变形卷积; WloU
02 模块介绍
深度学习领域中,为了更好地捕捉和建模非刚性形态,Dai等[16提出了可变形卷积(DCN),DCN 通过添加可学习的偏移量的卷积层和全连接层,改进了传统的固定卷积核。这种改进使得模型能够根据不同物体或结构的形状变化来调整卷积核的大小和形状。通过降低模型的复杂性,DCN能够更好地适应图像中的目标,并提高对非刚性变形和遮挡等复杂情况的处理能力。Zhu等[17提出的DCNv2通过更全面地整合可变形卷积的特性,并引入了扩展可变形建模范围的调节机制,进一步提高了可变形卷积模型的建模能力。相比于DCN,DCNv2不仅能够调整感知输入特征的偏移量,还可以调节来自不同空间位置的输入特征的幅度,使得DCNv2在处理自适应能力有限问题方面表现出更好的性能。DCNv2的计算公式如式(2)一式(4)所示。


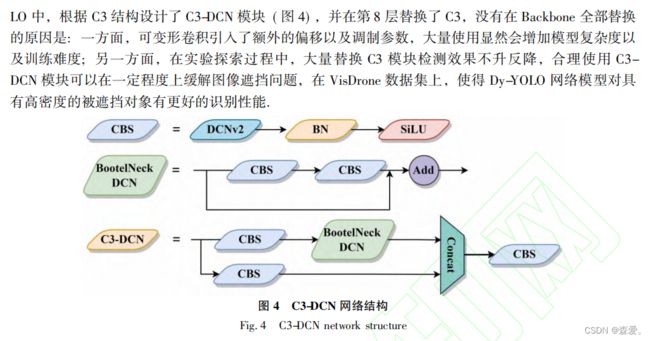
06 基于 YOLOv5 的无人机航拍改进目标检测算法 Dy-YOLO
01 摘要
摘要:由于无人机航拍具有场景复杂多样,目标尺度变化剧烈,高速低空运动模糊等诸多特性,给目标检测带来了很大的挑战.针对无人机航拍目标检测效果不佳的问题,提出了Dy-YOLO模型,在YOLOv5的基础上引入Dynamic Head注意力,从尺度感知、空间位置、多任务3个角度探索具有注意力机制的预测头潜力;设计了C3-DCN结构和Dymamic Head注意力相互配合增强特征提取能力;此外,还使用SimOTA标签分配方式来弥补小样本的损失,并使用CARAFE ( content-aware ressembly of features)上采样算子,有效增强了不同卷积特征图的融合效果.在VisDrone2019测试集上,Dy-YOLO检测的平均均值精度达到了38.2%,较基线方法YOLOv5提高了7.1%,同时与主流的检测方法相比也取得更高的检测精度.结果表明,Dy-YOLO算法对于无人机航拍检测任务具有较好的性能.
关键词:目标检测;注意力机制; 无人机航拍;YOLOv5;可变形卷积网络
02 模块介绍
Dynamic Head中提到,主干中使用可变形卷积(deformable convolutional network,DCN) [24可以与所提出的动态头部互补,传统的卷积采用固定尺寸的卷积核,在感受野内使用固定的权重进行特征提取,不能很好地适应几何形变,而可变形卷积通过引入额外的可学习参数来动态地调整感受野中不同位置的采样位置和权重,这使得可变形卷积能够在处理具有形变、遮挡或不规则形状的图像时更加有效.但是 DCN 的一大缺陷在于,其采样点经过偏移之后的新位置会超出我们理想中的采样位置,导致部分可变形卷积的卷积点可能是一些和物体内容不相关的部分;DCNv2[2$l则针对偏移干扰问题引入了一种调制机制:


07 改进DenseNet 在抽油井示功图故障诊断的研究
01 摘要
摘要:油田开采主要采用有杆抽油机。对其进行故障检查采用的主要是人工方法,不仅耗费大量的人力和财力,而且识别结果易受到经验因素影响。示功图可以反映有杆抽油机井的工作状态,可用于抽油机故障类型检测。因此,本文提出了一种基于DenseNet注重动态调整特征提取的模型来进行示功图分类,在传统卷积神经网络的基础上加入可变形卷积,使用Focal-Loss 损失函数替代交叉嫡损失函数,通过Adam优化算法加快网络的收敛速度,实现了12种工况模式的识别。关键词深度学习;图像分类;示功图;密集连接卷积网络
02 模块介绍

08 一种基于深度学习模型的无人机巡检输电线路山火检测方法
01 摘要
摘要:输电巡检图像的背景复杂,目标检测易受干扰,基于YOLOX神经网络模型,提出一种输电线路山火检测方法。首先采用YOLOX的主干特征提取网络框架,并将其中多尺度特征提取模块的常规卷积替换为可变形卷积;其次在加强特征提取阶段增加了通道注意力和空间注意力模块的融合,能够自适应火焰的外形多变特点,更加有效地提取到山火特征,从而提高目标检测的准确率。经实验验证,所提方法能够较为准确地检测到山火,满足日常巡检的需求。
关键词:输电线路巡检;山火识别;神经网络;目标检测; YOLOX