内存管理源码分析1-ARMV8-AARCH64 MMU 及 linux页表映射过程
MMU的作用,主要是完成地址的翻译,无论是main-memory地址(DDR地址),还是IO地址(设备device地址),在开启了MMU的系统中,CPU发起的指令读取、数据读写都是虚拟地址,在ARM Core内部,会先经过MMU将该虚拟地址自动转换成物理地址,然后在将物理地址发送到AXI总线上,完成真正的物理内存、物理设备的读写访问
1、MMU/TLB/Cache 概述
MMU:完成的工作就是虚拟地址到物理地址的转换,可以让系统中的多个程序跑在自己独立的虚拟地址空间中,相互不会影响。程序可以对底层的物理内存一无所知,物理地址可以是不连续的,但是不妨碍映射连续的虚拟地址空间。TLB:MMU工作的过程就是查询页表的过程,页表放置在内存中时查询开销太大,因此专门有一小片访问更快的区域用于存放地址转换条目,用于提高查找效率。当页表内容有变化的时候,需要清除TLB,以防止地址映射出错。
原则上,每次虚存访问都可能会引起两段物理访问:一段取相应的页表项,另一段取需要的数据。
为克服这个问题,使用一个高速缓存,通常称为转换检测缓冲区(Translation Lookaside Buffer,TLB
Cache:处理器和存储器之间的缓存机制,用于提高访问速率,在ARMv8上会存在多级Cache,其中L1 Cache分为指令Cache和数据Cache,在CPU Core的内部,支持虚拟地址寻址;L2 Cache容量更大,同时存储指令和数据,为多个CPU Core共用,这多个CPU Core也就组成了一个Cluster。

上图没有体现L1和L2 cache 和 MMU的关系,再来张图:

那具体是怎么访问的?见下图:

2 虚拟地址到物理地址的转换
虚拟地址到物理地址的映射通过查表的机制来实现,ARMv8中,Kernel Space的页表基地址存放在TTBR1_EL1寄存器中,User Space页表基地址存放在TTBR0_EL0寄存器中,其中内核地址空间的高位为全1,(0xFFFF0000_00000000 ~ 0xFFFFFFFF_FFFFFFFF),用户地址空间的高位为全0,(0x00000000_00000000 ~ 0x0000FFFF_FFFFFFFF)
为什么高16位可以用来区分内核空间和用户空间虚拟地址:
64位系统的地址线有64位,但是在具体实现上,并没有使用这么多,一般来说,48位的地址线就够了
TTBR寄存器:Translation Table Base Register


TTBRx_ELx 中存放的是物理地址还是虚拟地址:
寄存器TTBR1_EL1存放内核的页全局目录的物理地址,寄存器TTBR0_EL1存放进程的页全局目录的物理地址
armv8 中的特权级别:
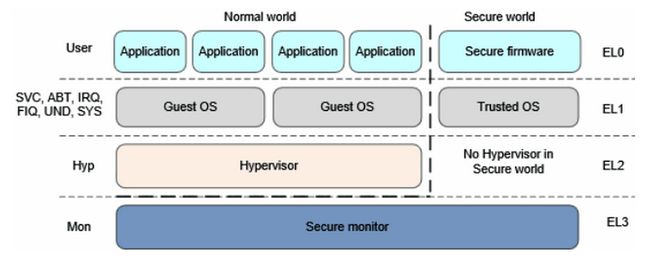
Exception Level:
EL0 : 用户模式,运行普通用户程序,非特权级别,有执行权限,访问受限的内存 (Armv8中linux用户程序运行在EL0级别,linux内核EL1级别。)
EL1 : 系统特权,运行操作系统内核。如果系统是能了虚拟扩展,运行虚拟机操作系统内核。
EL2 : 运行虚拟机扩展的虚拟机监控器(hypervisor)
EL3 : 运行安全管理
然后就是EL3,这个比较厉害,权限比较大,基本上可以访问所有寄存器,而且电源管理,也在里面。另外这个就类似于一个电梯,打通了安全与非安全的通道。
ARMv8中,引入了两种安全状态:
secure state
non-secure state
这里的安全状态,主要是影响资源的访问,比如memory,系统寄存器等。
对于memory,有时候需要做数据隔离,用于保护数据的安全性。因此就可以将memory分成两个区域,secure区域和non-secure区域。对于secure的memory区域,只允许secure状态去访问,而对于non-secure的memory区域,允许secure状态和non-secure状态都可访问。这样可以保护数据的安全。
对于EL1和EL0,可以是non-secure状态,也可以是secure状态。
对于EL2,只能是non-secure状态。据说最新的ARMv8.4,EL2可以是secure状态。
对于EL3,只能是secure状态。
secure和non-secure状态的切换,只能通过EL3进行切换,也就是如果想从non-secure的EL0切换到secure的EL0,首先要先从non-secure的EL0,通过异常切换到EL3,然后再通过异常,返回到secure的EL0。
具体参考armv8架构
ARMv8中:
-
虚拟地址支持
64位虚拟地址中,并不是所有位都用上,除了高16位用于区分内核空间和用户空间外,有效位的配置可以是:36, 39, 42, 47。这可决定Linux内核中地址空间的大小。比如我使用的内核中有效位配置为CONFIG_ARM64_VA_BITS=39,用户空间地址范围:0x00000000_00000000 ~ 0x0000007f_ffffffff,大小为512G,内核空间地址范围:0xffffff80_00000000 ~ 0xffffffff_ffffffff,大小为512G,512G=2^39。 -
页面大小支持
支持3种页面大小:4KB, 16KB, 64KB。 -
页表支持
支持至少两级页表,至多四级页表,Level 0 ~ Level 3。
虚拟地址查表过程如下:
可参考的4级页表模型:

39位有效位,4KB大小页面,3级页表,所以我会以这个组合来介绍
4K:2^12
4096/8bytes = 512 entrys=2^9

- 虚拟地址[63:39]用于区分内核空间与用户空间,从而选择不同的
TTBRn寄存器来获取Level 1页表基地址; - 虚拟地址[38:30]放置
Level 1页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取Level 2页表基地址; - 虚拟地址[29:21]
Level 2页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取Level 3页表基地址; - 虚拟地址[20:12]
Level 3页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取物理地址的高36位,以4K地址对齐;获取目的页帧。 - 虚拟地址[11:0]放置的是物理地址的偏移,结合获取的物理地址高位,最终得到物理地址。
讲到这里还没有完,是时候看一下Table Descriptor了,也就是页表中存放的内容,有以下四种类型:

类型有低两位来决定,其中Level 0中的Table Descriptor只能输出Level 1页表的地址,Level 3中的Table Descriptor只能输出block addresses。
看到图中的attributes了吗,这些可以用于memory的权限控制,memory ordering,cache policy的操作等。
在ARMv8中,与页表相关的寄存器有:TCR_EL1, TTBRx_EL1.
3. Linux页表映射
3.1 Linux页表基本操作

基本上内核中关于页表的操作都会围绕着上图进行操作,似乎脱离了代码有点不太合适,那么就来一波fucking source code解析吧,主要讲讲各类page table相关的API。
pgtable定义代码路径:
arch/arm64/include/asm/pgtable-types.h:定义pgd_t, pud_t, pmd_t, pte_t等类型,调用nopmd.h nopud.h等头文件;arch/arm64/include/asm/pgtable-prot.h:针对页表中entry中的权限内容设置;arch/arm64/include/asm/pgtable-hwdef.h:主要包括虚拟地址中PGD/PMD/PUD等的划分,这个与虚拟地址的有效位及分页大小有关,此外还包括硬件页表的定义, TCR寄存器中的设置等;arch/arm64/include/asm/pgtable.h:页表设置相关;
在这些代码中可以看到,
- 当
CONFIG_PGTABLE_LEVELS=4时:pgd-->pud-->pmd-->pte; - 当
CONFIG_PGTABLE_LEVELS=3时,没有PUD页表:pgd(pud)-->pmd-->pte; - 当
CONFIG_PGTABLE_LEVELS=2时,没有PUD和PMD页表:pgd(pud, pmd)-->pte
常用的宏定义

页表处理
/*描述各级页表中的页表项*/
typedef struct { pteval_t pte; } pte_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
/* 将页表项类型转换成无符号类型 */
#define pte_val(x) ((x).pte)
#define pmd_val(x) ((x).pmd)
#define pud_val(x) ((x).pud)
#define pgd_val(x) ((x).pgd)
/* 将无符号类型转换成页表项类型 */
#define __pte(x) ((pte_t) { (x) } )
#define __pmd(x) ((pmd_t) { (x) } )
#define __pud(x) ((pud_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
/* 获取页表项的索引值 */
#define pgd_index(addr) (((addr) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1))
#define pud_index(addr) (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1))
#define pmd_index(addr) (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1))
#define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
/* 获取页表中entry的偏移值 */
#define pgd_offset(mm, addr) (pgd_offset_raw((mm)->pgd, (addr)))
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
#define pud_offset_phys(dir, addr) (pgd_page_paddr(*(dir)) + pud_index(addr) * sizeof(pud_t))
#define pud_offset(dir, addr) ((pud_t *)__va(pud_offset_phys((dir), (addr))))
#define pmd_offset_phys(dir, addr) (pud_page_paddr(*(dir)) + pmd_index(addr) * sizeof(pmd_t))
#define pmd_offset(dir, addr) ((pmd_t *)__va(pmd_offset_phys((dir), (addr))))
#define pte_offset_phys(dir,addr) (pmd_page_paddr(READ_ONCE(*(dir))) + pte_index(addr) * sizeof(pte_t))
#define pte_offset_kernel(dir,addr) ((pte_t *)__va(pte_offset_phys((dir), (addr))))
一条线性地址可能被切割为多个部分形成多级页表和页内偏移。为了帮助线性地址的切割,为每一级也定义了一个宏:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))
如何使用页表项(Using Page Table Entries)
为了遍历页目录,下面三个宏被定义用来将一个线性地址快速分离出其内部组成部分。
- pgd_offset():输入线性地址和mm_struct,返回线性地址中对应的PGD项。
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address))
#define pgd_index(address) (((address) >> PGDIR_SHIFT) & (PTRS_PER_PGD-1))pmd_offset():输入一个PGD项(找到页框地址)和一个线性地址(找到pmd的偏移),返回一个对应的PMD
#define pmd_offset(dir, address) ((pmd_t *) pgd_page(*(dir)) + pmd_index(address))
#define pgd_page(pgd) ((unsigned long) __va(pgd_val(pgd) & PAGE_MASK))pte_offset_kernel():输入一个PMD(找到页框地址)和一个线性地址(找到页内偏移):
#define pte_offset_kernel(pmd, address) ((pte_t *) pmd_page_kernel(*(pmd)) + pte_index(address))
#define pmd_page_kernel(pmd) ((unsigned long) __va(pmd_val(pmd) & PAGE_MASK))
#define pte_index(address) (((address) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))第二轮的宏函数是用来检查页表项是否存在或者是否有人在使用:
- pte_none(), pmd_none() and pgd_none():如果对应的项不存在,返回1
- pte_present(), pmd_present() and pgd_present():如果对应项的PRESENT为被置位,返回1
- pte_clear(), pmd_clear() and pgd_clear():将会清除对应的项
- pmd_bad() and pgd_bad() :用来检查页表项是否符合要求
上述的几组宏的使用例程:
pgd_t *pgd;
pmd_t *pmd;
pte_t *ptep, pte;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || pgd_bad(*pgd))
goto out;
pmd = pmd_offset(pgd, address);
if (pmd_none(*pmd) || pmd_bad(*pmd))
goto out;
ptep = pte_offset(pmd, address);
if (!ptep)
goto out;
pte = *ptep;第三轮的宏是用来检查页表项的权限和设置页表项的权限。这些权限决定了一个用户空间的进程在一个page上能干什么不能干什么。举例:内核页表项永远不能被用户进程读取。
- pte_read():用来测试pte的读权限,pte_mkread() 设置读权限,pte_rdprotect()取消读权限
- pte_write():用来测试pte的写权限,pte_mkwrite() 设置读权限,pte_wrprotect()取消读权限
- pte_dirty():用来测试是否有被写过,pte_mkdirty()设置dirty位,pte_mkclean()清除dirty位
- pte_young():用来测试是否是新页,pte_mkyoung()设置新页,pte_old()设置位旧页(检查access位)
转换和设置页表项(Translating and Setting Page Table Entries)
- mk_pte():输入一个struct page和保护位组合形成pte_t。
#define page_to_pfn(page) ((unsigned long)((page) - mem_map)) //mem_map中的偏移就是PFN
#define pfn_pte(pfn, prot) __pte(((pfn) << PAGE_SHIFT) | pgprot_val(prot)) //将PFN与权限bit为合并形成pte_t
#define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))- set_pte():输入一个PDM页框内的地址,然后将pte_t赋值在这个地址中。
#define set_pte(pteptr, pteval) (*(pteptr) = pteval)- pte_page():将pte_t转换为struct page
分配释放页表(Allocating and Freeing Page Tables)
分配函数: pgd_alloc(), pmd_alloc() and pte_alloc()
释放函数:pgd_free(), pmd_free() and pte_free()
4 head.S中的页表映射
4.1 idmap_pg_dir和swapper_pg_dir临时页表
是时候来个实例分析了,看看页表的创建过程,代码路径:arch/arm64/kernel/head.S。
内核启动过程中,在真正的物理内存尚未添加进系统,以及页表还未初始化之前,为了保证系统能正常运行,需要建立两个临时全局页表:idmap_pg_dir和swapper_pg_dir
为什么需要临时页表
- idmap_pg_dir是identity mapping使用的页表,也就是物理地址和虚拟地址是相等的,主要是解决打开MMU后,从物理地址转换成虚拟地址,防止MMU开启后,无法获取页表
- swapper_pg_dir是kernel image mapping初始阶段使用的页表,swapper_pg_dir Linux内核编译后,kernel image是需要进行映射的,包括text,data等各种。请注意,这里的内存是一段连续内存。也就是说页表(PGD/PUD/PMD)都是连在一起的,地址相差PAGE_SIZE(4k)
idmap_pg_dir
turn on MMU相关的代码被放入到一个特别的section,名字是.idmap.text,实际上对应上图中物理地址空间的IDMAP_TEXT这个block。这个区域的代码被mapping了两次,做为kernel image的一部分,它被映射到了__idmap_text_start开始的虚拟地址上去(kernel image映射地址),开启MMU可以正常执行
此外,假设IDMAP_TEXT block的物理地址是A地址,那么它还被映射到了A地址开始的虚拟地址上去(恒等地址),也即:VA:PA=(9000:9000),执行虚拟地址时,会得到物理地址上的数据。
通过System.map就可以查看哪些函数被放在".idmap.text"段。
section mapping
ARM64_SWAPPER_USES_SECTION_MAPS宏定义了swapper/idpmap是否使用section map;什么是section mapping?
我们用一个实际的例子来描述。假设VA是48 bit,page size是4K,levels=4 那么,在地址映射过程中,地址被分成9(level 0) + 9(level 1) + 9(level 2) + 9(level 3) + 12(page offset),对于kernel image这样的big block memory region,使用4K的page来mapping有点得不偿失,在这种情况下,可以考虑最后一级页表(level 2的Translation table entry)指向一个2M 的memory region,而不是下一级的Translation table。所谓的section map就是指使用2M的为单位进行映射。
主要的原因是:如果使用二级页表,就需要为二级页表项的 block(level 2) 申请内存,这时候还没有任何的内存管理手段,因此直接使用 section map 是最方便的。
当然,不是什么情况都是可以使用section map,对于kernel image,其起始地址是2M对齐的,因此block size是2M的情况下才OK,对于PAGE SIZE是16K,其Block descriptor指向了一个32M的内存块,PAGE SIZE是64K的时候,Block descriptor指向了一个512M的内存块,因此,只有4K page size的情况下,才可以启用section map。
说明:PAGE_SIZE=16K 4 levels
16K /8 bytes = 4*4k/8bytes=4*512=2048= 2^11
11+11+11+15 PMD->2^15=32M
页表映射过程我们描述 了虚拟地址到物理地址的映射过程,我们仍然以虚拟地址宽度为39bit,页大小为4K来描述,有3级页表。PGD–>PMD–>PTE,PTE映射的大小是4K。但是在启动阶段,系统并不会以4K为单位进行映射,因为在启动阶段的目的就是能尽快的读取到kernel image,而以4K进行映射,假如kernel的大小为16M,映射kernel image就需要4096次。所以在启动流程中会使用section map,页表减少一级,变为PGD–>PMD–>offset,PMD映射大小是2M(对于VA_BIT=39,offset=21bits),对于16M大小的kernel image,最少只需要8次就能映射完成。
现在已经明确在启动阶段需要两级页表,PGD和PMD,并且需要identify mapping和kernel mapping两份页表,也就是需要4个页大小来存储启动阶段的页表,这块地址空间是什么分配的呢?是在链接脚本中vmlinux.lds.S
说明:VA_BIT=48bit 9+9+9+9+12 2^21=2M,只需要3级页表,就能满足kernel image的映射需求512*512*2M
以48bit(9+9+9+9+12),Page size为4K为例,如果是seciton map, PGD(Level 0)、PUD(Level 1)、PMD(Level 2)的translation table中的entry都是512项,每个描述符是8个byte,因此这些translation table都是4KB,恰好是一个page size; 共3page size
其中两个全局页表的定义在arch/arm64/kernel/vmlinux.lds.S中,放置在BSS段之后:
1. BSS_SECTION(0, 0, 0)
2.
3. . = ALIGN(PAGE_SIZE);
4. idmap_pg_dir = .;
5. . += IDMAP_DIR_SIZE;
6. swapper_pg_dir = .;
7. . += SWAPPER_DIR_SIZE;
8. idmap_full_pg_dir = .;
9. . += IDMAP_FULL_DIR_SIZE;
/* 定义了连续的几个页,分别存放PGD,PUD,PMD等,连续在一起,这个也是head.S中填充的 */
#define SWAPPER_DIR_SIZE (SWAPPER_PGTABLE_LEVELS * PAGE_SIZE)
#define IDMAP_DIR_SIZE (IDMAP_PGTABLE_LEVELS * PAGE_SIZE)对于section map:
#define SWAPPER_PGTABLE_LEVELS (CONFIG_PGTABLE_LEVELS - 1)
4.2 源码分析
在head.S中,创建页表相关的有三个宏:

1.ARM64 __create_page_tables分析
前提:
CONFIG_ARM64_PAGE_SHIFT=12
CONFIG_ARM64_VA_BITS=48
CONFIG_ARM64_PA_BITS=48
CONFIG_PGTABLE_LEVELS=4
2^32 = 4GB
2^48 = 256TB
2^47 = 128TB
__create_page_tables
1)准备阶段
__create_page_tables:
adrp x25, idmap_pg_dir------------------------(1)
adrp x26, swapper_pg_dir
mov x27, lrmov x0, x25-----------------------------(2)
add x1, x26, #SWAPPER_DIR_SIZE
bl __inval_cache_rangemov x0, x25-----------------------------(3)
add x6, x26, #SWAPPER_DIR_SIZE
1: stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
cmp x0, x6
b.lo 1bldr x7, =SWAPPER_MM_MMUFLAGS-----------------(4)
(1)取idmap_pg_dir这个符号的物理地址,保存到x25。取swapper_pg_dir这个符号的物理地址,保存到x26。这段代码没有什么特别要说明的,除了adrp这条指令。adrp是计算指定的符号地址到run time PC值的相对偏移(不过,这个offset没有那么精确,是以4K为单位,或者说,低12个bit是0)。在指令编码的时候,立即数(也就是 offset)占据21个bit,此外,由于偏移计算是按照4K进行的,因此最后计算出来的符号地址必须要在该指令的-4G和4G之间。由于执行该指令的 时候,还没有打开MMU,因此通过adrp获取的都是物理地址,当然该物理地址的低12个bit是全零的。此外,由于在链接脚本中 idmap_pg_dir和swapper_pg_dir是page size aligned,因此使用adrp指令也是OK的。
adrp指令根据PC的偏移地址计算目标页地址。首先adrp将一个21位有符号立即数左移12位,得到一个33位的有符号数(最高位为符号位),接着将PC地址的低12位清零,这样就得到了当前PC地址所在页的地址,然后将当前PC地址所在页的地址加上33位的有符号数,就得到了目标页地址,最后将目标页地址写入通用寄存器。此处页大小为4KB,只是为了得到更大的地址范围,和虚拟内存的页大小没有关系。通过adrp指令,可以获取当前PC地址±4GB范围内的地址。通常的使用场景是先通过adrp获取一个基地址,然后再通过基地址的偏移地址获取具体变量的地址。
下面是adrp指令的编码格式。立即数占用21位,在运行的时候,会将21位立即数扩展为33位有符号数。最高位为1,表示这是一个aarch64指令。adrp 为什么获取物理地址,MMU未开启前,CPU取指或数据访问,都是访问的物理地址内存
ARM工作模式:
usr(用户模式)
sys (系统模式)
svc (管理模式,保护模式)
大部分程序运行在usr模式,uboot 需要很高权限,运行在系统模式
(2)这段代码是要进行invalid cache的操作了,具体要操作的范围就是identity mapping和kernel image mapping所对应的页表区域,起始地址是idmap_pg_dir,结束地址是swapper_pg_dir+SWAPPER_DIR_SIZE。
为什么要调用__inval_cache_range来invalidate idmap_pg_dir和swapper_pg_dir对应页表空间的cache呢?根据boot protocol,代码执行到此,对于cache的要求是kernel image对应的那段空间的cache line是clean到PoC的,不过idmap_pg_dir和swapper_pg_dir对应页表空间不属于kernel image的一部分,因此其对应的cacheline很可能有一些旧的,无效的数据,必须要清理掉。
(3)将idmap和swapper页表内容设定为0是有意义的。实际上这些translation table中的大部分entry都是没有使用的,PGD和PUD都是只有一个entry是有用的,而PMD中有效的entry数目是和mapping的地 址size有关。将页表内容清零也就是意味着将页表中所有的描述符设定为invalid(描述符的bit 0指示是否有效,等于0表示无效描述符)。
(4)要创建mapping除了需要VA和PA,还需要memory attribute的参数,这个参数定义如下:
#if ARM64_SWAPPER_USES_SECTION_MAPS
#define SWAPPER_MM_MMUFLAGS (PMD_ATTRINDX(MT_NORMAL) | SWAPPER_PMD_FLAGS)
#else
#define SWAPPER_MM_MMUFLAGS (PTE_ATTRINDX(MT_NORMAL) | SWAPPER_PTE_FLAGS)
#endif
2)、建立identity mapping
mov x0, x25 -------------------------(1)
adrp x3, __idmap_text_start --------------------(2)#ifndef CONFIG_ARM64_VA_BITS_48--------------------(3)
#define EXTRA_SHIFT (PGDIR_SHIFT + PAGE_SHIFT - 3)----------(4)
#define EXTRA_PTRS (1 << (48 - EXTRA_SHIFT)) -------------(5)
#if VA_BITS != EXTRA_SHIFT-----------------------(6)
#error "Mismatch between VA_BITS and page size/number of translation levels"
#endifadrp x5, __idmap_text_end-----------------------(7)
clz x5, x5
cmp x5, TCR_T0SZ(VA_BITS) --------------------(8)
b.ge 1fadr_l x6, idmap_t0sz-------------------------(9)
str x5, [x6]
dmb sy
dc ivac, x6create_table_entry x0, x3, EXTRA_SHIFT, EXTRA_PTRS, x5, x6------(10)
1:
#endifcreate_pgd_entry x0, x3, x5, x6 //x0,tbl 物理地址;x3 虚拟地址-------(11)
mov x5, x3 // __pa(__idmap_text_start)
adr_l x6, __idmap_text_end // __pa(__idmap_text_end)
create_block_map x0, x7, x3, x5, x6-------------------(12)
(1)x0保存了idmap_pg_dir变量的物理地址,也就是identity mapping的PGD。(2)x3保存了__idmap_text_start的物理地址,对于identity mapping而言,x3也保存了虚拟地址,因为虚拟地址是等于物理地址的。
(3)基本上创建identity mapping是没有什么大问题的,但是,如果物理内存的地址位于非常高的位置,那么在进行identity mapping就有问题了,因为有可能你配置的VA_BITS不够大,超出了虚拟地址的范围。这时候,就需要扩展virtual address range了。当然,如果配置了48bits的VA_BITS就不存在这样的问题了,因为ARMv8最大支持的VA BITS就是48个,根本不可能扩展了。
(4)在虚拟地址地址不是48 bit,而系统内存的物理地址又放到了非常非常高的位置,这时候,为了完成identity mapping,我们必须要扩展虚拟地址,那么扩展多少呢?扩展到48个bit。扩展之后,增加了一个EXTRA的level,地址映射关系是EXTRA--->PGD--->……,其中EXTRA_SHIFT等于(PGDIR_SHIFT + PAGE_SHIFT - 3)。
(5)扩展之后,地址映射多个一个level,我们称之EXTRA level,该level的Translation table中有多少个entry呢?EXTRA_PTRS给出了答案。
(6)其实现行的linux kernel中,对地址映射是有要求的,即要求PGD是满的。例如:48 bit的虚拟地址,4k的page size,对应的映射关系是PGD(9-bit)+PUD(9-bit)+PMD(9-bit)+PTE(9-bit)+page offset(12-bit),对于42bit的虚拟地址,64k的page size,对应的映射关系是PGD(13-bit)+ PTE(13-bit)+ page offset(16-bit)。这两种例子有一个共同的特点就是PGD中的entry数目都是满的,也就是说索引到PGD的bit数目都是PAGE_SIZE-3。如果不满足这个关系,linux kernel会认为你的配置是有问题的。注意:这是内核的要求,实际上ARM64的硬件没有这么要求。
正因为正确的配置下,PGD都是满的,因此扩展之后EXTRA_SHIFT一定是等于VA_BITS的,否则一定是你的配置有问题。我们延续上一个实例来说明如何扩展虚拟地址的bit数目。对于42bit的虚拟地址,64k的page size,扩展之后,虚拟地址是48个bit,地址映射关系是EXTRA(6-bit)+ PGD(13-bit)+ PTE(13-bit)+ page offset(16-bit)。
(7)x5保存了__idmap_text_end的物理地址,之所以这么做是因为需要确定identity mapping的最高的物理地址,计算该物理地址的前导0有多少个,从而可以判断该地址是否是位于物理地址空间中比较高的位置。
(8)宏定义TCR_T0SZ可以计算给定虚拟地址数目下,前导0的个数。如果虚拟地址是48的话,那么前导0是16个。如果当前物理地址的前导0的个数(x5的值)还有小于当前配置虚拟地址的前导0的个数,那么就需要扩展。
(9)OK,现在进入需要扩展的分支,当然,具体要配置虚拟地址是通过TCR_EL1寄存器中的T0SZ域进行的,现在还不是时候(具体的设定在__cpu_setup函数中),这里,我们只要设定idmap_t0sz这个变量值就OK了,在__cpu_setup函数中会从该变量取值并设定到TCR_EL1寄存器中的。代码中,x6是idmap_t0sz变量的物理地址,x5是物理地址前导0的个数,将其保存到idmap_t0sz变量中。
(10)创建extra translation table的entry。具体传递的参数如下:
x0:页表地址idmap_pg_dir
x3:准备映射的虚拟地址(虽然x3保存的是物理地址,但是identity mapping嘛,VA和PA都是一样的)
EXTRA_SHIFT:正常建立最高level mapping的时候, shift是PGDIR_SHIFT,但是,由于物理地址位置太高,需要额外的映射,因此这里需要再加上一个level的mapping,因此shift需要PGDIR_SHIFT + (PAGE_SHIFT - 3)。
EXTRA_PTRS:增加了一个level的Translation table,我们需要确定这个增加level的Translation table中包含的描述符的数目,EXTRA_PTRS给出了这个参数。
(11)create_pgd_entry这个函数上面解释过了,建立各个中间level的table描述符。
(12)创建最后一个level translation table的entry。该entry可能是page descriptor,也可能是block descriptor,具体传递的参数如下:
x0:指向最后一个level的translation table
x7:要创建映射的memory attribute
x3:物理地址
x5:虚拟地址的起始地址(其实和x3一样)
x6:虚拟地址的结束地址
3) 创建kernel direct mapping
查看以下3副图,kernel image 映射,swapper_pg_dir作为pgd table,填充PUD页表,PMD块描述符:



/* * Map the kernel image (starting with PHYS_OFFSET). */ adrp x0, swapper_pg_dir -------------------------------(1) mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text) add x5, x5, x23 // add KASLR displacement ------------(2) create_pgd_entry x0, x5, x3, x6 ------------(3) adrp x6, _end // runtime __pa(_end) ------------(4) adrp x3, _text // runtime __pa(_text) ------------(5) sub x6, x6, x3 // _end - _text ------------(6) add x6, x6, x5 // runtime __va(_end) ------------(7) create_block_map x0, x7, x3, x5, x6 ------------(8)(3)
x0 tbl (swapper_pg_dir 物理地址)
x5 kernel 起始虚拟地址
(8)
填充PMD,映射整个kernel image地址空间
x0 swapper_pg_dir 物理地址
x7 要创建映射的memory attribute
x3 _text 物理地址
x5 kernel 起始虚拟地址
x6 kernel 结束虚拟地址
2 create_pgd_entry
/*
* Macro to populate the PGD (and possibily PUD) for the corresponding
* block entry in the next level (tbl) for the given virtual address.
*
* Preserves: tbl, next, virt
* Corrupts: tmp1, tmp2
*/
.macro create_pgd_entry, tbl, virt, tmp1, tmp2
create_table_entry \tbl, \virt, PGDIR_SHIFT, PTRS_PER_PGD, \tmp1, \tmp2
#if SWAPPER_PGTABLE_LEVELS > 3
create_table_entry \tbl, \virt, PUD_SHIFT, PTRS_PER_PUD, \tmp1, \tmp2
#endif
#if SWAPPER_PGTABLE_LEVELS > 2
create_table_entry \tbl, \virt, SWAPPER_TABLE_SHIFT, PTRS_PER_PTE, \tmp1, \tmp2
#endif
.endm
#if ARM64_SWAPPER_USES_SECTION_MAPS
#define SWAPPER_PGTABLE_LEVELS (CONFIG_PGTABLE_LEVELS - 1)
#define IDMAP_PGTABLE_LEVELS (ARM64_HW_PGTABLE_LEVELS(PHYS_MASK_SHIFT) - 1)
#else
#define SWAPPER_PGTABLE_LEVELS (CONFIG_PGTABLE_LEVELS)
#define IDMAP_PGTABLE_LEVELS (ARM64_HW_PGTABLE_LEVELS(PHYS_MASK_SHIFT))
#endif
当采用 SECTION时,SWAPPER_PGTABLE_LEVELS = (CONFIG_PGTABLE_LEVELS - 1)
上述函数主要是调用create_table_entry,由于SWAPPER_PGTABLES_LEVELS配置为3,因此相当于创建了pgd和pud两级页表,此处需要注意一点,create_table_entry函数执行后,tbl参数会自动加上PAGE_SIZE,也就是说pgd和pud两级页表是物理连续的。
(1)create_table_entry 在下一小节已经描述了,这里通过调用该函数在PGD中为虚拟地址virt创建一个table type的描述符。
(2)SWAPPER_PGTABLE_LEVELS这个宏定义和ARM64_SWAPPER_USES_SECTION_MAPS相关,这里就不说了。SWAPPER_PGTABLE_LEVELS其实定义了swapper进程地址空间的页表的级数,可能3,也可能是2,具体中间的Translation table有多少个level是和配置相关的,如果是section mapping,那么中间level包括PGD和PUD就OK了,PMD是最后一个level。如果是page mapping,那么需要PGD、PUD和PMD这三个中间level,PTE是最后一个level。当然,如果整个page level是3或者2的时候,也有可能不存在PUD或者PMD这个level。
(3)当SWAPPER_PGTABLE_LEVELS > 3的时候,需要创建PUD这一级的Translation table。
(4)当SWAPPER_PGTABLE_LEVELS > 2的时候,需要创建PMD这一级的Translation table。
上面太枯燥了,我们给出一些实例:
例子1:当虚拟地址是48个bit,4k page size,这时候page level等于4,映射关系是PGD(L0)--->PUD(L1)--->PMD(L2)--->Page table(L3)--->page,但是如果采用了section mapping(4k的page一定会采用section mapping),映射关系是PGD(L0)--->PUD(L1)--->PMD(L2)--->section。在create_pgd_entry函数中将创建PGD和PUD这两个中间level。
例子2:当虚拟地址是48个bit,16k page size(不能采用section mapping),这时候page level等于4,映射关系是PGD(L0)--->PUD(L1)--->PMD(L2)--->Page table(L3)--->page。在create_pgd_entry函数中将创建PGD、PUD和PMD这三个中间level。
例子3:当虚拟地址是39个bit,4k page size,这时候page level等于3,映射关系是PGD(L1)--->PMD(L2)--->Page table(L3)--->page。由于是4k page,因此采用section mapping,映射关系是PGD(L1)--->PMD(L2)--->section。在create_pgd_entry函数中将创建PGD这一个中间level。
2. create_table_entry
create_table_entry这个宏定义主要是用来创建一个中间level的translation table中的描述符。如果用linux的术语,就是创建PGD、PUD或者PMD的描述符。如果用ARM64术语,就是创建L0、L1或者L2的描述符。具体创建哪一个level的Translation table descriptor是由tbl参数指定的
/*
* Macro to create a table entry to the next page.
*
* tbl: page table address,页表地址
* virt: virtual address,映射的虚拟地址
* shift: #imm page table shift, 映射位在字中的偏移量
* ptrs: #imm pointers per table page,映射位宽度
*
* Preserves: virt
* Corrupts: tmp1, tmp2
* Returns: tbl -> next level table page address
*/
.macro create_table_entry, tbl, virt, shift, ptrs, tmp1, tmp2
/* virt 向右移动shift位置,准备获取也表项索引 */
lsr \tmp1, \virt, #\shift
/* table index,按位与操作,保留了tmp1中对应的ptrs-1位数据其他位清零,即获取到页表项索引 */
and \tmp1, \tmp1, #\ptrs - 1
/* tmp2 = tbl + PAGE_SIZE,idmap_pg_dir包含多级页表(每个页表占用一个page),故此处目的会获取下一级也表项入口地址 */
add \tmp2, \tbl, #PAGE_SIZE
/* address of next table and entry type, 按位或操作,设置下一页表项标志位PMD_TYPE_TABLE */
orr \tmp2, \tmp2, #PMD_TYPE_TABLE
/*
* 将下一级页表项基地址写入当前的页表项,
* 当前页表项地址 = tbl + (tmp1 << 3)
* 因每个页表项占用8byte,故对应页表相对页表基地址的偏移应为tmp1 << 3
* 偏移应为tmp1 << 3
*/
str \tmp2, [\tbl, \tmp1, lsl #3]
/* next level table page ,指向下一级页表 */
add \tbl, \tbl, #PAGE_SIZE
.endm
上述函数创建页表项,并且返回下一个Level的页表地址:
其中创建页表的核心函数create_table_entry如下,在三级页表结构中此函数主要完成PGD、PMD两级页表的创建。
以创建PGD页表过程为例,
入参说明: tbl 指需要创建页表物理地址
virt 为映射到的虚拟地址
shift 为映射PGD索引在虚拟地址中的偏移,即PGDIR_SHIFT
ptrs 为PGD索引在虚拟地址中的位宽度,即PTRS_PER_PGD
tmp1 、tmp2为临时变量
创建过程: 1) 从virt中获取 PGD 页表 index
2) 获取一下级页表的基地址,即PMD页表物理基地址
3) 给PMD页表物理地址设置有效标识,表明该地址是有效的PMD type table
4) 将PMD页表基地址写入PGD[index]
5) 将tbl指向一下级页表基地址,为下一级页表的创建做准备
参数tbl表示当前页表的物理地址,virt表示要映射的虚拟地址,shift表示这一级页表的在虚拟地址中的偏移(PGD_SHIFT),ptrs表示这一级页表是几位的(例如:PGD索引在虚拟地址中的位宽度,即PTRS_PER_PGD)。tmp1和tmp2是两个临时变量
(1)tmp1中保存virt地址对应在Translation table中的entry index。
(2)取出下一级页表的地址,初始阶段的页表(PGD/PUD/PMD/PTE)都是排列在一起的,每一个占用一个page。也就是说,如果create_table_entry当前操作的是PGD,那么tmp2这时候保存了下一个level的页表,也就是PUD了
(3)这一步是合成描述符的数值。光有下一级translation table的地址不行,还要告知该描述符是否有效(bit 0),该描述符的类型是哪一种类型(bit 1)。对于中间level的页表,该描述符不可能是block entry,只能是table type的描述符,因此该描述符的最低两位是0b11
#define PMD_TYPE_TABLE (_AT(pmdval_t, 3) << 0)(4)这是最关键的一步,将描述符写入页表中。之所以有“lsl #3”操作,是因为一个描述符占据8个Byte。
(5)结束的时候tbl会加上一个PAGE_SIZE,也就是tbl变成了下一级页表的地址
将translation table的地址移到next level,以便进行下一步设定
3.create_block_map
create_block_map的名字起得不错,该函数就是在tbl指定的Translation table中建立block descriptor以便完成address mapping。具体mapping的内容是将start 到 end这一段VA mapping到phys开始的PA上去
/*
* Macro to populate block entries in the page table for the start..end
* virtual range (inclusive).
* tbl 页表项的物理基地址
* flags 需要映射页表flag
* phys 需映射的物理地址
* start 物理地址映射到的虚拟空间的起始地址
* end 物理地址映射到的虚拟空间的结束地址
* Preserves: tbl, flags
* Corrupts: phys, start, end, pstate
*/
.macro create_block_map, tbl, flags, phys, start, end
/* 获取需要映射的物理地址对应的PFN */
lsr \phys, \phys, #SWAPPER_BLOCK_SHIFT //phys=phys>>21
/* table start-index,获取start在tbl表中起始索引 */
lsr \start, \start, #SWAPPER_BLOCK_SHIFT //start=start>>21
and \start, \start, #PTRS_PER_PTE - 1 //table index, start = start & 0x1FF // 至此start等于其初始值的[29:21]bit
/* table entry,获取物理地址所在的物理页地址,并给物理页地址设置页表flag */
orr \phys, \flags, \phys, lsl #SWAPPER_BLOCK_SHIFT table entry // phys = flags | (phys << 21)
/* table end-index,获取start在tbl表结束索引 */
lsr \end, \end, #SWAPPER_BLOCK_SHIFT //end=end>>21
and \end, \end, #PTRS_PER_PTE - 1 table end index // end = end & 0x1FF // 至此end等于其初始值的[29:21]bit
/* 将需要映射物理页地址 写入 虚拟地址对应的 tbl[index]*/
9999: str \phys, [\tbl, \start, lsl #3] // store the entry, 将phys的值存入地址tbl + start * 8的内存中,即以start的[29:21]bit为索引的以8byte为单位的页表中
add \start, \start, #1 // next entry
add \phys, \phys, #SWAPPER_BLOCK_SIZE // next block,phys = phys + 0x200000
cmp \start, \end
b.ls 9999b
.endm
上述三个孤立的函数并不直观,所以,图来了:

如下是简化后的 idmap 和 kernel 映射代码,从代码逻辑可知:
idmap_pg_dir 是 __idmap_text_start 到 __idmap_text_end 段内核代码物理地址映射到虚拟地址的页表项空间,因 x5 = x3 = __pa(__idmap_text_start) 故该页表空间映射的虚拟地址与物理地址一致。__idmap_text_start 到 __idmap_text_end内存空间保存了section ".idmap.text" 代码,该代码函数主要实现MMU的开关。
swapper_pg_dir 是 _text 到 _end 内核代码运行的物理地址创建映射的页表空间,该页表空间的虚拟起始地址为 KIMAGE_VADDR + TEXT_OFFSET,虚拟空间大小为内核空间大小(_text -_end),物理起始地址为内核加载到物理内存_text的地址。
经此地址映射并开启MMU后, CPU访问的内核代码的虚拟地址与vmlinux.lds的内核链接地址及system.map符号表地址一致(vmlinux.lds地址为虚拟地址)。
备注:1) idmap_pg_dir 、swapper_pg_dir 保存的页表怎么使用?
在enable_mmu函数中idmap_pg_dir 、swapper_pg_dir的地址分别被存进了ttbr0_el1 和 ttbr1_el1, Arm64会根据其他状态寄存来决定使用哪个ttbr(Translation Table Base Register)。
2)__idmap_text_start 到__idmap_text_end空间通过idmap_pg_dir 、swapper_pg_dir两个页表都可以访问?
个人观点:是可以,idmap_pg_dir页表对应的物理空间为__idmap_text_start 到__idmap_text_end。 swapper_pg_dir页表项对应的物理空间为整个内核段,而__idmap_text_start 到__idmap_text_end段包含在内核段。