【程序员的自我修养01】编译流程概述
绪论
大家好,欢迎来到【程序员的自我修养】专栏。正如其专栏名,本专栏主要分享学习《程序员的自我修养——链接、装载与库》的知识点以及结合自己的工作经验以及思考。编译原理相关知识本身就比较有难度,我会尽自己最大的努力,争取深入浅出。若你希望与一群志同道合的朋友一起学习,也希望加入到我们的学习群中。文末有加入方式。
简介
本文主要介绍我们熟悉的编译四大流程:预处理,编译,汇编,链接。因为是我们经常会讨论的话题,因此会尽可能详细讨论一下其中的细节。不会太难,大家要跟上脚步哦。
本文讨论的示例代码如下:
//helloworld.h
extern int printf(const char *format, ...);
#if 1
#define HELLOWORLD "hello world 1\n"
#else
#define HELLOWORLD "hello world 2\n"
#endif
//helloworld.c
#include
int main()
{
printf(HELLOWORLD);
return 0;
} 预处理
命令:gcc -E helloworld.c -I. -o helloworld.i。其中-I.表示头文件搜索路径。
预处理主要处理哪些源代码文件中的以"#"开始的预编译指令。比如"#define"、"#include"等。主要的规则有:
- 处理所有条件预编译指令,比如"#if"、"#ifdef"、"#elif"、"#else"、"#endif"等。
- 将所有的"#define"删除,并展开所有的宏定义。
- 处理"#include"预编译指令,将被包含的文件插入到该预编译指令的位置(可以代码中利用这个特性)。注意,这个过程是递归进行的。
- 删除所有的注释"//"和"/* */"。这也就是说明,详细的代码注释,并不会造成目标文件变大。
- 添加行号和文件名标识,比如#2 “hello world.c” 2,以便于编译时编译器产生调试用的行号信息、编译错误或编译警告时显示行号。
- 保留所有的#pragma 编译器指令,因为编译器需要使用它们。
helleworld.i 内容如下,请根据上面规则,仔细对比一下。
# 1 "helloworld.c"
# 1 ""
# 1 ""
# 31 ""
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 32 "" 2
# 1 "helloworld.c"
# 1 "./helloworld.h" 1
extern int printf(const char *format, ...);
# 2 "helloworld.c" 2
int main()
{
printf("hello world 1\n");
return 0;
} 注:工作中经常会遇到类似fatal error: xxxxxx.h: No such file or directory错误,就是在预编译阶段体现的。
但是预编译阶段不会进行语法校验,类似如下的编码,并不会提示错误。
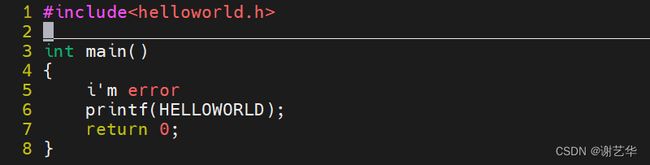
编译
编译阶段是整个程序构建的核心部分,也是最复杂的部分。它主要对文件进行词法分析、语法分析、语义分析及优化生成的汇编代码文件。
命令:gcc -S helloworld.i -o helloworld.s 或者 /usr/lib/gcc/x86_64-linux-gnu/9/cc1 helloworld.i。其中cc1文件的路径,不同的操作系统可能不一致。我的虚拟机是ubunt 18.04 版本。
helloworld.s 内容如下:
.file "helloworld.i"
.text
.section .rodata
.LC0:
.string "hello world 1"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~18.04) 9.4.0"
.section .note.GNU-stack,"",@progbits因为我不是从事自然语言研究方向,编译阶段的词法分析、语法分析、语义分析就不再进一步展开。但是其中的优化还是需要略微深入一下。因为编译器优化,其中也存在一些坑。
编译器优化
编译器优化的目的:优化程序的性能和减少代码的生成。因此有时候提高编译优化等级,可以稍微提高程序的执行效率。常见的方式有以下几种:
1. 常量传播。能够直接计算出结果的变量,将被编译器由直接结果来替代。例如:
{
int x = 10;
printf("x = %d\n",x);
}
优化后:
{
printf("x = %d\n",10);
}2. 常量折叠。如果有可能,多个变量的计算可以最终替换成为一个变量的计算。例如:
{
int a = 1;
int b = 2;
int c = a + b;
printf("c = %d\n",c);
}
优化后:
{
int c = 1 + 2;
printf("c = %d\n",c);
}
再结合 1.优化方式,得
{
printf("c = %d\n",3);
}3. 复写传播。用一个变量替换两个或多个相同的变量。例如:
{
int a = 1;
int b = a;
printf("b = %d\n",b);
}
优化后:
{
int b = 1;
printf("b = %d\n",b);
}4. 公共表达式消除。如果一个表达式已经计算过了,并且从先前的计算到现在的E中的变量都没有发生变化,那么E的此次出现就成为了公共表达式,编译器不需要再次进行计算浪费性能。例如:
{
int a = 1;
int b = 2;
int c = (a+b) * 2 + (b+a) * 6;
}
优化后:
{
int a = 1;
int b = 2;
int E = a + b;
int c = E * 2 + E * 6;
}5. 无用代码消除。将永远不能执行到的代码或没有任何意义的代码清除。比如return 之后的代码、未使用的变量、变量给自己赋值等。
6. 数组范围检查消除。Java这种动态类型安全型的,那在访问数组时比如array[ ]时,Java不会像C/C++那样只是纯粹的裸指针访问,而是会在运行时访问数组元素前进行一次是否越界检查,这将会带来许多开销,如果即时编译器能根据数据流分析出变量的取值范围在[0,array.length]之间,那么在循环期间就可以把数组的上下边界检查消除,以减少不必要的性能损耗。
7. 方法内联。将比较简短的函数或方法直接粘贴到其调用者中,以减少函数调用时的开销。例如:
int test()
{
printf("i'm test\n");
}
{
int a = 1;
test();
int b = 2;
}
优化后:
{
int a = 1;
printf("i'm test\n");
int b = 2;
}8. 逃逸分析。逃逸分析的基本原理就是分析对象动态作用域。如果确定一个方法不会逃逸出方法之外,那让整个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧而销毁。在一般应用中,不会逃逸的局部对象所占用的比例很大,如果能在编译器优化时,为其在栈上分配内存空间,那大量的对象就会随着方法结束而自动销毁了,不用依赖前面讲的GC或者记忆力,系统的压力将会小很多。
编译器优化的坑
编译器优化带来的问题有很多场景,在网上搜索的话,应该有很多实际案例。可以参看这两个案例:
不同优化选项对ARM下C语言编译的影响 - 守夜者 - 博客园
关于O2编译选项的一个过优化问题及其解决方法_o2优化-CSDN博客
汇编
汇编过程就是将汇编文件转换为机器可以执行的指令。因此它的内部逻辑比较单一,仅需要将汇编语句对照表格一一翻译即可。
命令:gcc -c helloworld.s -o helloworld.o或 as helloworld.s -o helloworld.o亦或gcc -c helloworld.c -o helloworld.o。
问题:x86环境的虚拟机为什么想反汇编(objdump -d *.so)arm 平台的动态库,失败呢?
答:我们在工作中,经常会遇到一些问题,需要查看动态库的信息,比如查看依赖库,反汇编,甚至是gdb调试。但是嵌入式平台的资源有限,一般是不会集成相关工具的。常见的方式就是将目标文件copy到本地虚拟环境中,进行调试。但是我们往往用objdump,gdb等工具时,提示如下失败:

其原因:.o、.so、可执行程序都已经是二进制文件,是对应机器可识别的指令。而嵌入式平台一般都是arm架构,开发电脑是x86,两套架构识别的指令不一致,所以不能解析对方的机器码。若想在虚拟机中调试其他平台的动态库或可执行程序,需要使用交叉编译工具链中的对应工具。
链接
链接才是我们整个过程中最为复杂的过程,这个阶段做了很多很多事情。因此出现异常的概率也高。大致可以分为两个范围。
- 静态链接过程。主要指生成动态库或可执行文件的过程。比如:工作中,我们经常遇到工程编译提示错误,大部分都是在链接阶段提示的。
- 动态链接过程。就是程序运行过程。我们知道若程序依赖动态库,那么程序在真正运行前,需要找到对应的动态库并加载。常见的问题就是找不到对应动态库,或对应符号找不到;有时会出现匪夷所思的现象。有兴趣的可以了解我遇到的一个案例:坑惨啦!!!——符号冲突案例分析-CSDN博客
为了不打击大家的信心,本篇文章不会再进一步展开讨论。后续我会慢慢揭开链接过程的面纱,其实也就那么一回事。
不过大家可以先思考以下几个问题,尝试猜测链接做了哪些事情。
一、helloworld.o 中引用了printf方法,程序运行时,它是怎么知道符号地址的呢?该跳转到哪里,继续执行程序呢?
二、程序正真运行前,需要做哪些事情呢?动态库加载、符号重定位?其大致逻辑如何呢?
技巧分享
本章节主要和大家分享一下,我工作中用到的小技巧,也欢迎大家在评论区补充,我会更新到文章中。
一、利用"#include",更好的维护代码。
我们知道#include是预处理过程中将文件内容加载到对应位置的操作。那么我们可以将一些可变的信息保存在文件中,那么就不会更改我们的.c 源文件。
比如:做过单片机LCD显示的朋友,肯定知道每一张照片信息,其实就是一个超大的整型数组。常见的方式如下:
//picture.c
int picture_data[] = {
*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,
*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,
}每当图片信息变化时,则需要更新picture_data数组里面的信息,也就要更改picture.c源文件。我觉得这样并不友好。优化如下:
//picture_data.h
{
*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,
*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,
}
//picture_data.c
int picture_data[] =
#include
; 这样每次图片更新,仅需要替换picture_data.h文件即可。
二、如何快速确认"#if"、"#ifdef"、"#elif"、"#else"、"#endif" 的实际分支。
在大型的工程项目中,随着需求的迭代代码分支也比较多,经常会用到类似"if"、"#ifdef"、"#elif"、"#else"、"#endif" 等分支控制方式。这就导致我们有时不知道实际代码编译的是哪一部分。我的快速定位的方式就是在对应的分支中加上乱码。比如:

亦或者加上错误提示:
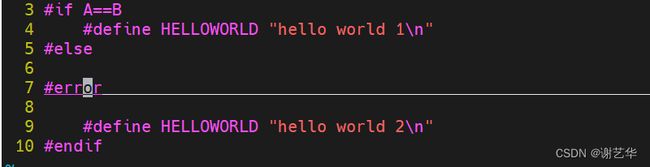
再多问一下,大家知道上面两种方式的不同吗?(提示一下,不同的阶段。)
总结
以上便是本文的内容,我们回顾了编译的四大过程:预处理,编译,汇编,链接。以及每个过程大致做了哪些事,可能会遇到的问题;也知道了编译器优化带来的可能弊端,因此编译器的优化选项我们要慎重,如果对效率要求不高,建议开启O1即可;链接阶段是一大难点,本文没有展开叙述,但是通过案例和抛出的问题,我相信,大家对链接肯定产生了莫大的兴趣。请别着急,关注专栏,后续一定会娓娓道来。
有任何相关问题欢迎留言讨论,我会尽快回复。
若您正遇到相关问题,苦于没有一群志同道合的朋友交流,探讨。也欢迎加入我们的讨论组群。可通过私聊我,我会尽快拉你进群。