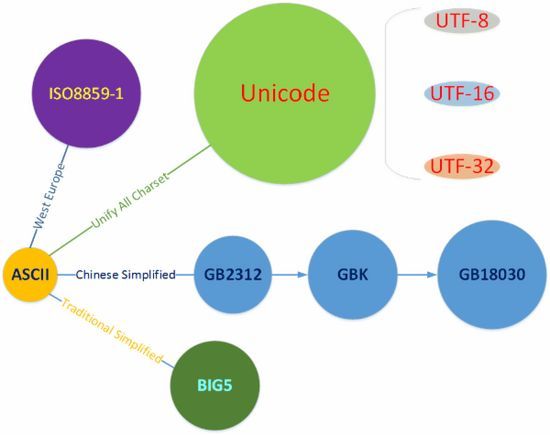
常用字符集(ASCII,ISO8859-1,GB2312,GBK,Unicode)和字符编码(UTF-8,UTF-16)
转自:https://blog.csdn.net/wn084/article/details/80363792
参考:https://blog.csdn.net/halchan/article/details/78353947
https://blog.csdn.net/he_and/article/details/80380084
下面介绍几种常见字符集:
ASCII:

由来:
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套,而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
包含哪些字符:
一共包含128个字符。其中有33个控制字符(不可显示字符),52个英文字母(包括大小写),0~9十个阿拉伯数字,其余为一些特殊符号。因为ASCII全称叫做"American Standard Code for Information Interchange,美国信息交换标准代码",是用来通信美国字符的,所以不包含中文。
采用哪种(些)字符编码,它(们)是如何编码的?
前面提到过,ASCII字符集在制定的之后也同时指定了编码的标准,所以它的字符编码就是ASCII字符编码。
ASCII码使用1个字节的后7位(位,也称作bit,比特)来表示一个字符,总共表示128个字符(2^7 = 128,二进制编码为0000 0000 ~ 0111 1111,对应的十进制就是0~127)。剩下最高位的那一个bit一般为0,但有时也被用作一些通讯系统的奇偶校验位。每个字符对应的二进制字节流就是自身在字符集中的字符编号转换成二进制。比如大写字母'A'的字符编号是65,所以字母'A'在计算机中就是以'01000001'这样的二进制字节流存储的。
每个字符占几个字节?
在ASCII字符集中,每一个字符占一个字节。
ISO8859-1:

注:图中的绿色区域并不是没有定义字符,它们都是不可显示的控制字符。
由来:
当计算机开始发展起来的时候,人们逐渐发现,ASCII字符集里那可怜的128个字符已经不能再满足他们的需求了。人们就在想一个字节能够表示的数字(或者说字符编号更准确)有256个,而ASCII字符只用到了0x00~0x7F,也就是占用了前128个,后面128个数字不用白不用,因此很多人打起了后面这128个数字的主意。可是问题在于,很多人同时有这样的想法,但是大家对于0x80-0xFF这后面的128个数字分别对应什么样的字符,却有各自的想法。因此出现了很多不同的字符集,比如:ISO8859-1,ISO8859-3等。。。这些字符集的前128个字符都与ASCII中相同,也就是兼容ASCII字符集,但后128位却各不相同。ISO8859-1就是属于西欧语系中的一个字符集,比如支持表达阿尔巴尼亚语、巴斯克语、布列塔尼语、加泰罗尼亚语、丹麦语、等,目前使用的最普遍。ISO8859-1有个熟悉的别名:Latin1.
包含哪些字符:
包含了256个字符。前128个字符与ASCII中完全相同。后128个包括了西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
采用哪种(些)字符编码,它(们)是如何编码的?
同ASCII一样,也是使用默认的字符编码。字符编号转换成二进制后即是字符使用ISO88959-1编码后在计算机中存储的形式。
每个字符占几个字节?
在ISO8859-1字符集中,每一个字符占一个字节。
GB2312:
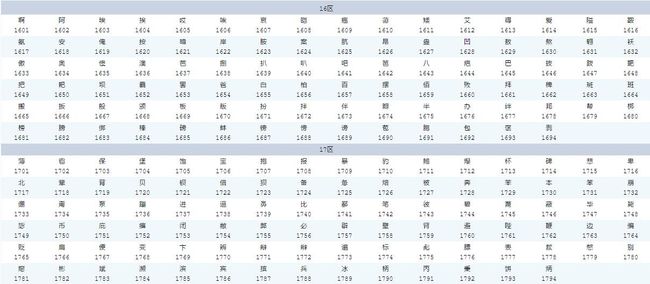
由来:
GB2312:中国国家标准简体中文字符集。当中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存,于是想到把那些ASCII码中127号之后的奇异符号们直接取消掉。但这也只能多出来128个字符,离6000还差得远。所以只好使用两个字节来表示汉字。所以规定:一个小于127(指一个字节表示的十进制数值)的字节的意义与原来相同,但两个大于127的字节连在一起时,就表示一个汉字。前面的一个字节(称之为高字节)使用0xA1~0xF7这个区间,后面一个字节(低字节)使用0xA1~0xFE这个区间,这样我们就可以组合出大约7000多个简体汉字了。
在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。这种汉字方案叫做 "GB2312"。GB2312 是对 ASCII 的中文扩展。兼容ASCII。GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
包含哪些字符:
GB2312编码大约包含6000多汉字(不包括特殊字符),编码范围为第一位b0-f7,第二位编码范围为a1-fe(第一位为cf时,第二位为a1-d3),计算一下汉字个数为6762个汉字。当然还有其他的字符。包括控制键和其他字符大约7583个字符编码。
GB2312对任意一个图形字符都采用两个字节表示,并对所收汉字进行了“分区”处理,每区含有 94 个汉字/符号,分别对应第一字节和第二字节。这种表示方式也称为区位码。
(关于区位码的解释,请先看"彻底解决乱码问题(附一)-简体中文编码中区位码、国标码、内码、外码、字形码的区别及关系",否则对下面GB2312字符编码的解释在理解上可能会很困难。)
● 01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
● 10~15区:空区,留待扩展;
● 16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
● 56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
● 88~94区:空区,留待扩展。
采用哪种(些)字符编码,它(们)是如何编码的?
GB2312采用基于区位码的字符编码方案。区位码其实就是GB2312的字符编号,编码的方式就是将区码加上160(20H+80H),转换为内码后,再转为二进制就是存储在计算机中的二进制字节流。详情见“彻底解决乱码问题(附一)-简体中文编码中区位码、国标码、内码、外码、字形码的区别及关系”。
每个字符占几个字节?
汉字,日文等占两个字节。英文字母等其他ASCII中的字符依然占一个字节。因为计算机会根据高字节的最高位是1和0判断是中文字符还是英文字符,若是1,则截取两个字节来解码。若是0,代表该字符为英文字符,直接使用ASCII来解码。
GBK:

由来:
虽然GB2312基本满足了我国人在计算机上对汉字的需求。但是中国的汉字太多了,对于人名、古汉语等方面出现的罕用字,GB2312不能处理。不得不继续把GB2312没有用到的码位找出来用上(GB2312编码中,高字节的编码范围是0xA1~0xF7,也就是161~247,而不是128~255,这就造成了浪费)。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始。这个编码方案被称为 “GBK” 标准,GBK包括了GB2312的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
所以GBK是GB2312的扩展,(“K”就是“扩”字拼音的首字母),因此完全兼容GB2312。
包含哪些字符:
GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。
全部编码分为三大部分:
1. 汉字区。包括:
a. GB2312 汉字区。即 GBK/2: B0A1-F7FE。收录 GB 2312 汉字 6763 个,按原顺序排列。
b. GB 13000.1 扩充汉字区。包括:
(1) GBK/3: 8140-A0FE。收录 GB 13000.1 中的 CJK 汉字 6080 个。
(2) GBK/4: AA40-FEA0。收录 CJK 汉字和增补的汉字 8160 个。CJK 汉字在前,按 UCS 代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列。
(3) 汉字“〇”安排在图形符号区GBK/5:A996。
2. 图形符号区。包括:
a. GB2312 非汉字符号区。即GBK/1: A1A1-A9FE。其中除GB2312的符号外,还有10个小写罗马数字和GB12345增补的符号。计符号 717 个。
b. GB13000.1扩充非汉字区。即GBK/5: A840-A9A0。BIG-5 非汉字符号、结构符和“〇”排列在此区。计符号 166 个。
3. 用户自定义区:分为(1)(2)(3)三个小区。
(1) AAA1-AFFE,码位 564 个。
(2) F8A1-FEFE,码位 658 个。
(3) A140-A7A0,码位 672 个。
第(3)区尽管对用户开放,但限制使用,因为不排除未来在此区域增补新字符的可能性。
采用哪种(些)字符编码,它(们)是如何编码的?
GBK虽然是GB2312的扩展,但他的编码方式已经不再基于区位码。从哪里看出来的呢?
如果留意过早些年的手机(功能机),会发现人名中常见的“燊”字是打不出来的。为什么呢?因为早期的区位码表里面并没有这些字,也就是说早期的GB2312也是没有这些字的。到后来的GBK才补充了大量的汉字进去,当然现在的安卓苹果应该都是GBK字库了。再看看这些补充的汉字的字节码(也就是内码),如“燊”字在GBK中的编码是0x9F 0xF6。
和前面说到的GB2312不同,有的字的编码比0xA0 0xA0(转换为区位码是0 0,也就是区位码表的开头)还小,难道新补充的区位号还能是负的??其实不然,这次的补充只补充了计算机编码表,并没有补充区位码表。也就是说区位码表并没有更新,用区位码还是打不出这些字,而网上的反向区位码表查询也只是按照GBK的编码计算,并不代表字与区位号完全对应。时代的发展,区位码表早已经是进入博物馆的东西了。
所以GBK字符集对应的就是GBK字符编码。编码方式同上述的字符集一样,通过简单的查表(字符-字节映射)即可完成。
每个字符占几个字节?
同GB2312一样。
Unicode:

由来:
随着计算机发展到世界各地,于是各个国家和地区各自为政,搞出了很多既兼容ASCII但又互相不兼容的各种编码方案。这样一来同一个二进制编码就有可能被解释成不同的字符,导致不同的字符集在交换数据时带来极大的不便。
想象一下,如果有一种统一的字符集,将世界上所有语言字符都纳入其中,每一个字符都给予一个全球独一无二的编码,那么乱码问题就会消失。于是,全球所有国家和民族使用的所有语言字符的统一字符集诞生了,这就是Unicode字符集。Unicode的名字起的很形象:该字符集是为了给全世界所有字符一个唯一的编码,“唯一”对应的英文为Unique,而编码的英文为code,两者结合一下就产生了Unicode。平常见到的“U+0024”这样的数值,就代表Unicode字符集中的一个字符编号。
想象一下,如果有一种统一的字符集,将世界上所有语言字符都纳入其中,每一个字符都给予一个全球独一无二的编码,那么乱码问题就会消失。于是,全球所有国家和民族使用的所有语言字符的统一字符集诞生了,这就是Unicode字符集。Unicode的名字起的很形象:该字符集是为了给全世界所有字符一个唯一的编码,“唯一”对应的英文为Unique,而编码的英文为code,两者结合一下就产生了Unicode。平常见到的“U+0024”这样的数值,就代表Unicode字符集中的一个字符编号。
包含了哪些字符?
All of The Character。全世界所有存在的字符都被包括在内。是所有!所有!
采用哪种(些)字符编码,它(们)是如何编码的?
首先声明,Unicode的产生象征着字符编码领域进入了一个新时代。为什么这么说呢?在Unicode之前所有制定的字符集都没有考虑到扩展性,所有的字符集都是和具体编码方案绑定在一起的(比如:GB2312,GBK,等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义.),都是直接将字符和最终字节流绑定死了,例如ASCII编码系统规定使用7比特来编码ASCII字符集,直接使用字符编号的二进制作为二进制字节流;GB2312基于区位码来编码,它和GBK字符集都限定了使用最多2个字节来编码所有字符,并且规定了字节序(不要求理解)。这样的编码系统通常用简单的查表,也就是通过代码页就可以直接将字符映射为存储设备上的字节流了。例如下面这个例子:
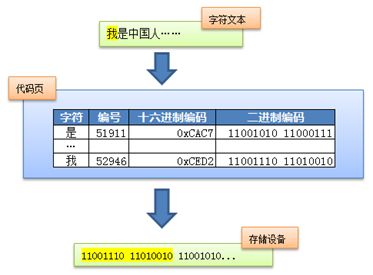
这种方式的缺点在于,字符和字节流之间耦合得太紧密了,从而限定了字符集的扩展能力。假设以后火星人入住地球了,要往现有字符集中加入火星文就变得很难甚至不可能了,而且很容易破坏现有的编码规则。
因此Unicode在设计上考虑到了这一点,将字符集和字符编码方案分离开。
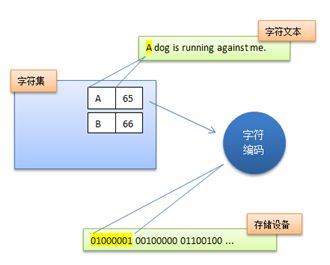
也就是说,虽然每个字符在Unicode字符集中都能找到唯一确定的编号(字符码,又称Unicode码),但是决定最终字节流的却是具体的字符编码。例如同样是对Unicode字符“A”进行编码,UTF-8字符编码得到的字节流是0x41,而UTF-16(大端模式)得到的是0x00 0x41。
因此上篇博客中说,在Unicode诞生之前可以将字符集和字符编码混为一谈,而在Unicode中必须严格区分开。例如可以说“采用GBK字符集或字符编码”,而不能说使用“UTF-8字符集”。
UTF-8、UTF-16等,它们只是Unicode字符集中所采用的具体的字符编码。这个概念要先搞清楚。
Unicode字符集采用了许多种字符编码方式。比如“UTF-8”,“UTF-16”,“UTF-32”等, 下文只着重介绍常用的“UTF-8”,“UTF-16”的介绍请看别的文章。
UTF-8:
UTF-8是一个非常惊艳的概念,它完美实现了对ASCII码的向后兼容,以保证Unicode可以被大众接受。在UTF-8中,0-127号的字符用1个字节来表示,使用和ASCII相同的编码。这意味着1980年代写的文档用UTF-8打开一点问题都没有。只有128号及以上的字符才用2个,3个或者4个字节来表示。因此,UTF-8被称作可变长度编码。下面讲解一下UTF-8的编码方式。
前面说过,字符集其实是“编号字符集”,而字符编码是定义了字符编号到实际存储的二进制字节流的映射,所以我会根据下表来分析UTF-8是如何实现字符编号到字节流的映射并做到映射出的字节流长度可变。

这个表格抽象的说明了,被UTF-8编码后得出的字节流的特征。其中x代表序号部分,把各个字节中的所有x部分拼接在一起就组成了在Unicode字符集中的字符编号:
● 如果一个字节的第一位为0,那么代表当前字符为单字节字符,占用1个字节的空间。0之后的所有部分(7个bit)代表在Unicode中的字符编号。
● 如果一个字节以110开头,那么代表当前字符为双字节字符,占用2个字节的空间。110之后的所有部分(5个bit)加上后一个字节的除10外的部分(6个bit)代表在Unicode中的字符编号。且第二个字节以10开头
● 如果一个字节以1110开头,那么代表当前字符为三字节字符,占用3个字节的空间。1110之后的所有部分(4个bit)加上后两个字节的除10外的部分(12个bit)代表在Unicode中的字符编号。且第二、第三个字节以10开头
● 如果一个字节以11110开头,那么代表当前字符为四字节字符,占用4个字节的空间。11110之后的所有部分(3个bit)加上后三个字节的除10外的部分(18个bit)代表在Unicode中的字符编号。且第二、第三、第四个字节以10开头
举个实例:

UTF-16:
请看这篇文章。
上一张图总结一下吧。