痤疮分级实验笔记-ResNet
组织数据集
方式1:根据txt文件分类的数据集组织形式(放弃)


你可以使用Python来读取txt文件中的训练集图片信息,并将这些图片从原始文件夹复制到目标文件夹中。
当程序无法找到标签对应的图片或者目标文件夹中已经存在同名图片时,你可以使用异常处理来跳过这些情况并继续复制粘贴其他满足要求的图片。以下是经过优化的代码示例:
import os
import shutil
# 定义原始文件夹和目标文件夹的路径
original_dir = '原始文件夹路径'
target_dir = '目标文件夹路径'
# 定义包含训练集图片信息的txt文件路径
txt_file = '训练集图片信息的txt文件路径'
# 读取txt文件
with open(txt_file, 'r') as f:
lines = f.readlines()
# 遍历每一行图片信息
for line in lines:
# 去除换行符
line = line.strip()
# 根据空格分割图片名称和其他文字内容
image_name, _ = line.split(' ', 1)
# 构建图片的完整路径
image_path = os.path.join(original_dir, image_name)
# 检查图片是否存在于原始文件夹中
if not os.path.exists(image_path):
print(f"图片 {image_name} 不存在于原始文件夹中,跳过该图片")
continue
# 构建目标文件夹中图片的完整路径
target_image_path = os.path.join(target_dir, image_name)
# 检查目标文件夹中是否已经存在同名图片
if os.path.exists(target_image_path):
print(f"目标文件夹中已存在同名图片 {image_name},跳过该图片")
continue
# 复制图片到目标文件夹
shutil.copy(image_path, target_dir)
方式2:文件名作为分类标签
分类1-8:当前文件夹有一个放有很多图片的文件夹和一个其对应的标签txt文件(txt文件中的每一行是图片文件夹中的文件名+一个空格+该图片对应的类:1到8)。在当前文件夹下建立名为“1”到“8”的八个文件夹。请写一个python文件,在当前文件夹下根据txt文件中的每一行的信息以及将图片文件夹里的图片分类,分别放入新建立的八类文件夹下:
import os
import shutil
# 图片文件夹路径
image_folder = './train_image'
# 标签文件路径
label_file = './train.txt'
# 创建八个类别文件夹
for i in range(1, 9):
folder_path = str(i)
os.makedirs(folder_path, exist_ok=True)
# 读取标签文件
with open(label_file, 'r',encoding='utf-8') as file:
lines = file.readlines()
# 遍历每一行,将图片分类到对应的文件夹
for line in lines:
line = line.strip()
filename, label = line.split(' ')
src_path = os.path.join(image_folder, filename)
dst_path = os.path.join(label, filename)
shutil.move(src_path, dst_path)
print('分类完成!')
模型加载与保存(参数)
本次实验保存成功的方式:
加载预训练模型
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))模型保存
训练前:
save_path = './resNet34.pth'
训练时:
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)加载训练好的模型
# create model
model = resnet34(num_classes=8).to(device)
# load model weights
weights_path = "./resNet34.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))模型训练
深度学习模型训练时,model.train()个别模型可调用,是什么意思?
在深度学习模型训练过程中,调用
model.train()是为了将模型设置为训练模式。这个方法主要用于区分模型在训练和评估(推理)阶段的行为。当调用
model.train()时,模型的行为会发生变化,具体包括:
Batch Normalization 和 Dropout 层会处于训练模式:Batch Normalization 层在训练和推理阶段有不同的行为,训练时会计算每个批次的均值和方差,并使用批次统计信息进行标准化。Dropout 层在训练时会随机丢弃一部分神经元,以减少过拟合。
梯度计算和参数更新:在训练模式下,模型会计算损失函数关于参数的梯度,并使用优化算法(如随机梯度下降)更新模型的参数,以最小化损失函数。
相反,当调用
model.eval()时,模型会被设置为评估模式。在评估模式下,模型的行为会发生以下变化:
Batch Normalization 和 Dropout 层会处于评估模式:Batch Normalization 层使用保存的移动平均值和方差进行标准化,而不是使用当前批次的统计信息。Dropout 层在评估时不会丢弃神经元,以保留所有的特征。
梯度计算和参数更新被禁用:在评估模式下,模型不会计算梯度,也不会更新参数。这是因为在评估阶段我们只关心模型的预测结果,而不需要进行反向传播和参数更新。
总结起来,调用
model.train()将模型设置为训练模式,启用了一些训练特定的行为,如 Batch Normalization 和 Dropout 的训练行为以及参数更新。而调用model.eval()将模型设置为评估模式,禁用了一些训练特定的行为,以保证在评估阶段的一致性和稳定性
终端命令
Linux命令
autodl使用的Linux系统
ls
-l:以列表的方式去显示
-a:显示隐藏文件
-h: 显示文件大小的单位
-al:显示隐藏文件并且以列表方式显示
-lh:以列表的方式去显示并且显示文件的大小
tree:以目录树方式显示当前文件夹信息
tree /:以目录树方式显示指定路径的文件信息
cd:切换目录
cd 目录名:切换到指定目录
cd .:切换到当前目录
cd …:切换到上一级目录
绝对目录:从根目录算起的路径叫做绝对路径,比如:/home/python
自动补全:两次tab键
pwd:相看目录所在的路径
Window命令
DIR [目录名或文件名]
参数:
/s 查找子目录
/w 只显示文件名
/p 分页
/a 显示隐藏文件
python命令
os.getcwd() 返回当前进程的工作目录,并非当前文件所在的目录 
python使用seedir查看文件目录结构
import seedir as sd
path = './Test5_resnet'
sd.seedir(path, style='lines',itemlimit=10,depthlimit=2,exclude_folders='.git')
一些Bug
pycharm中ctrl+左键进入不了源码
python解释器可以进入源码,Anoconda解释器点击无效
Found no valid file for the classes .ipynb_checkpoints。
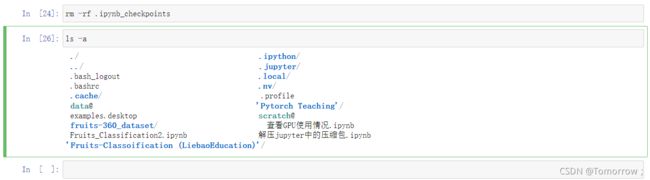
遇到这个问题只需要删除掉隐藏文件.ipynb_checkpoints即可,步骤如下
1.先通过 cd 到主目录下![]()
2.通过ls -a列出目录下所有文件
3.通过rm -rf .ipynb_checkpoints删除掉该隐藏文件,再通过ls -a检查