Python数据分析实战三:了解你的数据集
在上一节中介绍了怎么对数据进行预处理和数据集的整合,接下来从本章开始进行数据集的探索和分析,初步了解数据集。
5.统计分析
了解一个数据集最好的方法是通过常用的统计分析方法来求出数据集的统计特征,包括数据集的大小,数值的特征,数据分布情况等等。
5.1 测试数据集
为了更好地说明问题,从本节开始引入测试数据集,以下是来自A和B两个班级5位学生的考试成绩单可以根据该成绩单进行分析。 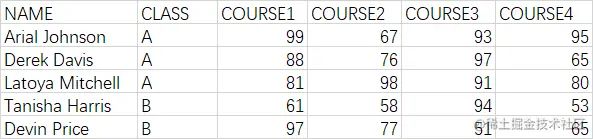
初始化数据集:
import pandas as pd
data = {
'NAME': ['Arial Johnson', 'Derek Davis', 'Latoya Mitchell', 'Tanisha Harris', 'Devin Price'],
'CLASS': ['A', 'A', 'A', 'B', 'B'],
'COURSE1': [99, 88, 81, 61, 97],
'COURSE2': [67, 76, 98, 58, 77],
'COURSE3': [93, 97, 91, 94, 51],
'COURSE4': [95, 65, 80, 53, 65]
}
df = pd.DataFrame(data)
5.2 描述性统计分析
对于一个数据集而言,其主要的统计特征有:
- 求和:数据集中所有元素的总和;
- 平均值:数据集中所有数据的总和除以数据个数;
- 中位数:将数据集从小到大排序后,位于中间的数值;
- 众数:数据集中出现次数最多的数值;
- 最大值:数据集中最大的数值;
- 最小值:数据集中最小的数值;
- 极差:最大值减去最小值的差;
- 标准差:数据集各数据与其平均值的差值平方的平均值的算术平方根,表示数据集的离散程度。
5.2.1 求和函数以及参数说明
# 求每个人的总得分
>>> df[['COURSE1', 'COURSE2', 'COURSE3', 'COURSE4']].sum(axis=1)
0 354
1 326
2 350
3 266
4 290
dtype: int64
# 求每个科目的总得分
>>> df[['COURSE1', 'COURSE2', 'COURSE3', 'COURSE4']].sum(axis=0)
COURSE1 426
COURSE2 376
COURSE3 426
COURSE4 358
dtype: int64
在数组操作中,有一个参数特别值得注意,那就是axis,其中axis=0表示按行操作,axis=1表示按列操作,axis取值不同,得出来的结果差别很大。一个 DataFrame 对象有两个轴,分别是 “axis=0" 和 “axis=1“ ,“axis=0” 代表“跨行”,“axis=1“代表“跨列。关于axis的理解可以参照:zhuanlan.zhihu.com/p/444973350
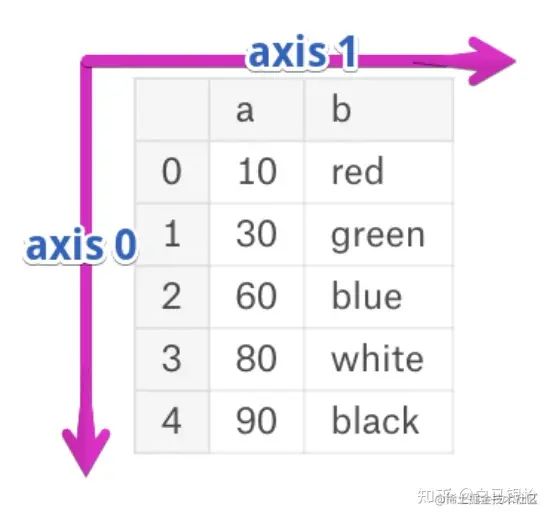
当数据的列数很多时,我们如果只想统计包含了数据的列,numeric_only参数可以解决问题,用了这个参数,就不需要单独指定含有数据的列了,使用起来更加便捷:
>>> df.sum(axis=0,numeric_only=True)
COURSE1 426
COURSE2 376
COURSE3 426
COURSE4 358
dtype: int64
>>> df.sum(axis=1,numeric_only=True)
0 708
1 652
2 700
3 532
4 580
dtype: int64
5.2.2 其他统计分析函数的使用
- count(计数)
# 计算学生人数
>>> df['NAME'].count()
5
- nunique(计算唯一值的个数)
# 计算班级数量
>>> len(df['CLASS'].unique())
2
nunique函数返回的是Array类型,即对CLASS列去重之后的结果集,想要计算唯一值的个数,还要求返回Array的大小。
- mean(平均值)
# 求班级每个人的平均分
>>> df.mean(axis=1, numeric_only=True)
0 88.5
1 81.5
2 87.5
3 66.5
4 72.5
dtype: float64
# 求每科的平均分
>>> df.mean(axis=0, numeric_only=True)
COURSE1 85.2
COURSE2 75.2
COURSE3 85.2
COURSE4 71.6
dtype: float64
- median(中位数)
# 求每科考试的中位数
>>> df.median(axis=0, numeric_only=True)
COURSE1 88.0
COURSE2 76.0
COURSE3 93.0
COURSE4 65.0
dtype: float64
- mode(众数)
# 求人数最多的班级
>>> df['CLASS'].mode()
0 A
dtype: object
- var (方差)
# 求各科目的方
>>> df.var(axis=0, numeric_only=True)
COURSE1 235.2
COURSE2 221.7
COURSE3 370.2
COURSE4 262.8
dtype: float64
- std(标准差)
>>> df.std(axis=0, numeric_only=True)
COURSE1 15.336232
COURSE2 14.889594
COURSE3 19.240582
COURSE4 16.211107
dtype: float64
- max(最大值)
# 求每门课最高分
df.max(axis=0, numeric_only=True)
COURSE1 99
COURSE2 98
COURSE3 97
COURSE4 95
dtype: int64
- min(最小值)
# 求每门课最低分
df.min(axis=0, numeric_only=True)
COURSE1 61
COURSE2 58
COURSE3 51
COURSE4 53
dtype: int64
- 极差 计算极差没有现成的函数,可以根据绝对值的最大值减去最小值求得,绝对值可用
abs求得。
# 求每门课最高分和最低分的差距
>>> df[['COURSE1', 'COURSE2','COURSE3','COURSE4']].abs().max() - df[['COURSE1', 'COURSE2','COURSE3','COURSE4']].abs().min()
COURSE1 38
COURSE2 40
COURSE3 46
COURSE4 42
dtype: int64
5.2.3 一次性获取描述性信息
除了以上方法,当我们遇到一个数据集时,分别去计算其统计特征还是比较繁琐的,pandas提供了describe()可以帮助你快速了解数据集,这是Pandas库中用于计算数据集基本描述性统计信息的函数。它可以计算数据集中的数值型列的均值、标准差、最小值、四分位数和最大值等统计信息。
>>> df.describe()
COURSE1 COURSE2 COURSE3 COURSE4
count 5.000000 5.000000 5.000000 5.000000
mean 85.200000 75.200000 85.200000 71.600000
std 15.336232 14.889594 19.240582 16.211107
min 61.000000 58.000000 51.000000 53.000000
25% 81.000000 67.000000 91.000000 65.000000
50% 88.000000 76.000000 93.000000 65.000000
75% 97.000000 77.000000 94.000000 80.000000
max 99.000000 98.000000 97.000000 95.000000
>>> type(df.describe())
其返回值也是一个DataFrame类型,可以用于进一步分析。
5.3 分组和聚合
5.3.1 分组
Pandas的GroupBy类是用于执行聚合操作的类。它允许用户基于一列或多列数据对数据进行分组,然后对每个组执行一些统计操作。
# 按班级分组统计
>>> groupby = df.groupby('CLASS')
>>> type(groupby)
>>> groupby.count()
NAME COURSE1 COURSE2 COURSE3 COURSE4
CLASS
A 3 3 3 3 3
B 2 2 2 2 2
# 统计每个班级的人数(按姓名维度)
>>> groupby = df.groupby('CLASS')['NAME']
>>> type(groupby)
>>> groupby.count()
CLASS
A 3
B 2
Name: NAME, dtype: int64
从以上代码中,可以看出GroupBy类分为DataFrameGroupBy和SeriesGroupBy,分别对应多个维度的分组结果和单一维度的分组结果。
groupby方案还有以下参数:
by:用于指定按照哪些列进行分组的参数;可以是单个列名的字符串,或多个列名组成的列表。也可以是一个函数,用该函数的返回值来进行分组。
单个列名分组:
grouped = df.groupby('CLASS')
多个列名分组:
grouped = df.groupby(['Name', 'CLASS'])
使用函数进行分组:
grouped = df.groupby(lambda x: x % 2)
axis:按照列轴(axis=0)还是行轴(axis=1)进行分组,默认是按照列轴进行分组。level:用于分组的层级的数值或层级名称。sort:是否对分组结果进行排序,默认是对分组结果进行排序。as_index:指定是否重置分组后的索引,默认是将分组的列作为索引。group_keys:指定是否在结果中包含分组键,默认是在结果中包含分组键。squeeze:指定是否对只有一个组的情况下进行降维。
5.3.2 聚合
聚合函数:上一章节中,介绍的求和、平均值、中位数、众数、最大值、最小值、计数、标准差、方差,都是一些常用的聚合函数,结合groupby方法一起使用,则可以实现分组聚合的效果。
- 单个聚合函数的使用
groupby = df.groupby('CLASS')
# 求班级中每门课考试的最高分
>>> groupby.max(numeric_only=True)
COURSE1 COURSE2 COURSE3 COURSE4
CLASS
A 99 98 97 95
B 97 77 94 65
# 求班级中每门课考试的平均值
groupby.mean(numeric_only=True)
COURSE1 COURSE2 COURSE3 COURSE4
CLASS
A 89.333333 80.333333 93.666667 80.0
B 79.000000 67.500000 72.500000 59.0
- 多个聚合函数的使用 当使用多个聚合函数时,需要agg函数,关于agg
# 使用agg函数,可以同时求最大值、最小值和平均值
>>> groupby.agg(['max', 'min', 'mean'])
COURSE1 COURSE2 ... COURSE3 COURSE4
max min mean max min ... min mean max min mean
CLASS ...
A 99 81 89.333333 98 67 ... 91 93.666667 95 65 80
B 97 61 79.000000 77 58 ... 51 72.500000 65 53 59
关于agg函数,将在之后的章节中继续介绍。
5.4 排序
5.4.1 数据集的排序
sort_index()按照索引进行排序。
# 默认按索引的正序排序
df
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4
0 Arial Johnson A 99 67 93 95
1 Derek Davis A 88 76 97 65
2 Latoya Mitchell A 81 98 91 80
3 Tanisha Harris B 61 58 94 53
4 Devin Price B 97 77 51 65
df.sort_index(ascending=False)
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4
4 Devin Price B 97 77 51 65
3 Tanisha Harris B 61 58 94 53
2 Latoya Mitchell A 81 98 91 80
1 Derek Davis A 88 76 97 65
0 Arial Johnson A 99 67 93 95
sort_values()按数值排序 按照指定的列或多个列的值进行排序。
# 按总分排序
>>> df['TotalScore'] = df.sum(numeric_only=True, axis=1)
>>> df.sort_values(['TotalScore'], ascending=False)
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4 TotalScore
0 Arial Johnson A 99 67 93 95 354
2 Latoya Mitchell A 81 98 91 80 350
1 Derek Davis A 88 76 97 65 326
4 Devin Price B 97 77 51 65 290
3 Tanisha Harris B 61 58 94 53 266
# 按班级正序,按总分倒序排列
>>> df.sort_values(['CLASS', 'TotalScore'], ascending=[True, False])
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4 TotalScore
0 Arial Johnson A 99 67 93 95 354
2 Latoya Mitchell A 81 98 91 80 350
1 Derek Davis A 88 76 97 65 326
4 Devin Price B 97 77 51 65 290
3 Tanisha Harris B 61 58 94 53 266
以上排序并不会改变原始数据集的排序方式,若想在数据集中生效,需要设置参数:preserve=True。
5.4.3 计算排名
# 所有列都进行排名
>>> df.rank()
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4 TotalScore
0 1.0 2.0 5.0 2.0 3.0 5.0 5.0
1 2.0 2.0 3.0 3.0 5.0 2.5 3.0
2 4.0 2.0 2.0 5.0 2.0 4.0 4.0
3 5.0 4.5 1.0 1.0 4.0 1.0 1.0
4 3.0 4.5 4.0 4.0 1.0 2.5 2.0
# 按总分从高到低排名
>>> df['TotalScore'].rank(ascending=False)
0 1.0
1 3.0
2 2.0
3 5.0
4 4.0
Name: TotalScore, dtype: float64
注意事项:相同值和空值的处理
当出现相同值和空值时,可以参考rank()函数中的method和na_option参数,根据实际需要进行设置。
-
method:指定计算排名时的方法。常用的方法包括:- average:默认方法,平均排名,相同的值会分配相同的排名,并根据下个排名的位置调整。
- min:最小排名,相同的值都会有相同的最小排名。
- max:最大排名,相同的值都会有相同的最大排名。
- first:首次出现的顺序排名。
-
na_option:指定处理缺失值的方式。常用的选项包括:- keep:保留缺失值,将其排名提高到非缺失值排名的后面。
- top:缺失值排在前面,非缺失值按照正常的方式排名。
- bottom:缺失值排在后面,非缺失值按照正常的方式排名。
5.4.3 取Top_N
- 取数据集中最大的N个值
# 取总分最高的前三名
>>> df.nlargest(3, 'TotalScore')
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4 TotalScore
0 Arial Johnson A 99 67 93 95 354
2 Latoya Mitchell A 81 98 91 80 350
1 Derek Davis A 88 76 97 65 326
- 取数据集中最小的N个值
# 取总分最低的后两名
>>> df.nsmallest(2, 'TotalScore')
NAME CLASS COURSE1 COURSE2 COURSE3 COURSE4 TotalScore
3 Tanisha Harris B 61 58 94 53 266
4 Devin Price B 97 77 51 65 290
题外话

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
若有侵权,请联系删除