第七章 查找(下)【散列查找及其性能分析】

1. 散列表的基本概念

1.1 散列表的基本概念
- 散列函数(哈希函数):Addr=H(key) 建⽴了“关键字”→“存储地址”的映射关系
- 散列表(哈希表,Hash Table):是⼀种数据结构。特点是:可以根据数据元素的关键字 计算出它在散列表中的存储地址
- 冲突(碰撞):在散列表中插⼊⼀个数据元素时,需要根据关键字的值确定其存储地址,若 该地址已经存储了其他元素,则称这种情况为“冲突(碰撞)
- ” 同义词:若不同的关键字通过散列函数映射到同⼀个存储地址,则称它们为“同义词”
- 装填因子:表中记录个数/散列表表长
- 哈希表的存储效率:哈希表的存储效率可以通过装填因子来表示。
- 通常情况下,哈希表的存储效率一般不超过50%。这是因为当装填因子过高时,哈希表中会出现大量的冲突,导致查找效率降低。因此,在设计哈希表时,需要根据实际情况选择合适的哈希函数和哈希表容量,以保证哈希表的存储效率和查找效率的平衡。
 如何减少“冲突”?
如何减少“冲突”?
构造更适合的散列函数,让各个关键字尽可能地映射 到不同的存储位置,从⽽减少“冲突”
2. 如何 构造散列函数?


1. 直接定址法:直接取关键字的某个线性函数值为散列地址,散列函数为 H ( k e y ) = k e y 或 H ( k e y ) = a × k e y + b 。这种方法计算简单,不会产生冲突。缺点是空位较多,会造成存储空间浪费。适⽤场景:关键字分布基本连续

2. 除留余数法:假定散列表表长 m,取一个不大于但最接近 m 的质数 p,利用散列函数 H ( k e y ) = k e y % p将关键字转换为散列地址。p取质数是因为对质数取余,可以分布 更均匀,从⽽减少冲突,这样可以使关键字通过散列函数转换后等概率地映射到散列空间上的任一地址。适⽤场景:较为通⽤,只要关键字是整数即可
注:质数⼜称素数。指除了1和此整数⾃身外,不能被其他⾃然数整除的数
3. 数字分析法:假设关键字是 r进制数,而r个数码在个位上出现的频率不一定相同,可能在某些位上分布的均匀一些,而在某些位分布的不均匀。此时应选数码分布均匀的若干位作为散列地址。
适⽤场景:关键字集合已知,且关键字的某⼏个数码位分布均匀
例:要求将⼿机⽤户的信息存⼊⻓度为 10000 的散列表。以“⼿机号码”作为关键字设计散列函数
以⼿机号后四位作为散列地址
4. 平方取中法:这种方法取关键字平方值的中间几位作为散列地址,具体取多少位视具体情况而定。这种方法得到的散列地址与关键字的每一位都有关系,因此使得散列地址分布比较均匀。
适用于关键字每位取值都不够均匀或均小于散列地址所需的位数。

3. 处理冲突的 ⽅法 ——拉链法

散列表通常不考代码,着重掌握⼿算分析⽅法
拉链法(⼜称链接法、链地址法):把所有“同义词”存储在⼀个链表中
3.1 如何在散列表(拉链法解决冲突)中插⼊⼀个新元素?
Step 1:结合散列函数计算新元素的散列地址
Step 2:将新元素插⼊散列地址对应的链表(可⽤头插法,也可⽤尾插法)

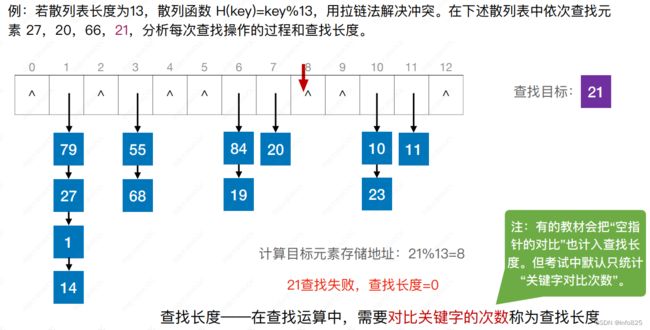
3.2 散列表的查找操作
衡量散列表查找效率的度量——平均查找长度(ASL)
平均查找长度(ASL):散列表查找成功的平均查找长度即找到表中已有表项(关键字)的平均比较次数;散列表查找失败的平均查找长度即找不到待查的表项但能找到插入位置(空)的平均比较次数。
查找效率取决于因素——散列函数,处理冲突的方法,装填因子
装填因子:表中记录个数n/散列表表长m,
平均查找长度依赖于装填因子,而不直接依赖m,n,装填因子越大,装填的越满,冲突可能性就越大
3.2.1 查找成功

3.2.2 查找失败
 注:有的教材会把“空指针的对⽐”也计⼊查找⻓度。但考试中默认只统计“关键字对⽐次数”。
注:有的教材会把“空指针的对⽐”也计⼊查找⻓度。但考试中默认只统计“关键字对⽐次数”。
3.3 散列表的删除操作
先查找再删除
3.3.1 删除成功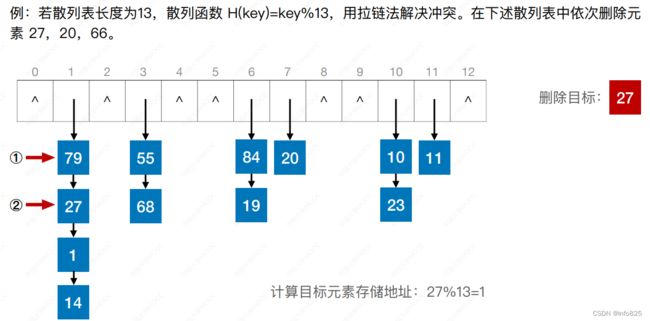

3.3.2 删除失败

4. 处理冲突的⽅法 ——开放定址法

开放定址法:如果发⽣“冲突”,就给新元素找另⼀个空闲位置
为什么叫“开放定址”?—— ⼀个散列地址,既对同义词开放,也对⾮同义词开放
根据散列函数 H(key),求得初始散列地址。若发⽣冲突,如何找到“另⼀个空闲位置”?
思路:需确定⼀个“探测的顺序”,从初始散列地址出发,去寻找下⼀个空闲位置
eg:d0=0, d1=1, d2=-1, d3=2, d4=-2, ……
注:di 表示第 i 次发⽣冲突时,下⼀个探测地址与初始散列地址的相对偏移量


4.1 线性探测法(插⼊、查找操作)
查找操作原理类似,根据探测序列依次对⽐各存储单元内的关键字。若探测到⽬标关键字,则查找成功。若探测到空单元,则查找失败。

4.2 平⽅探测法⼜称“⼆次探测法”(插⼊、查找操作)

4.3 双散列法

4.4 伪随机序列法

4.5 如何删除⼀个元素?
先查找再删除
4.5.1 删除流程
Step 1:先根据散列函数算出散列地址,并对⽐关键字是否匹配。若匹配,则“查找成功”
Step 2:若关键字不匹配,则根据“探测序列”对⽐下⼀个地址的关键字,直到“查找成功”或“查 找失败”
Step 3:若“查找成功”,则删除找到的元素
注:题⽬⼀定会说明具体是采⽤哪种 探测序列(线性探测法、平⽅探测 法、双散列法、伪随机序列法)
4.5.2 只能逻辑删除
采⽤“开放定址法”时,删除元素不能简单地将被删元素的空间置为空,否则将截断在它之后的探 测路径,可以做⼀个“已删除”标记,进⾏逻辑删除。
错误示范,删除15后,1也不能正常查询了

 注:⽆论线性探测法、 平⽅探测法、双散列 法、伪随机序列法原理 都⼀样。删除元素时, 只能逻辑删除
注:⽆论线性探测法、 平⽅探测法、双散列 法、伪随机序列法原理 都⼀样。删除元素时, 只能逻辑删除
正确示范:删除15,然后查找元素1


注:新元素也可 以插⼊到已被“逻 辑删除”的地址
4.5.3 带来的问题:
查找效率低下,散列表看起来很满,实则很空。

Tips:可以不定期整理散列表内的数据。

4.6 “探测覆盖率”

4.6.1 线性探测法的“探测覆盖率”

4.6.2 平⽅探测法的“探测覆盖率”

若散列表⻓度 m 是⼀个可以表示成4j + 3的素数(如 7、11、19),平⽅探测法就能探测到所有位置
4.6.3 双散列法的“探测覆盖率

4.6.4 伪随机序列法的“探测覆盖率”
