python爬取网易云歌单
一、实现效果

实现一个这样的界面,输入歌单URL下载歌单到本地文件夹。
二、思路
1.搭建界面
2.爬取音乐
三、搭建界面
导入tkinter标准库,tkinter作为python的标准图形库,不需下载
from tkinter import *
1.创建窗口对象
root=Tk()
2.窗口标题
root.title("网易云音乐")
3.窗口大小与位置
大小:root.geometry("600x500") 中间是字母x
位置:root.geometry("+230+230") 距离左上角的水平距离,垂直距离
可以合写为root.geometry("600x500+230+230")
4.实现标签控件
![]()
label=Label(root,text="请输入要下载的歌单URL:",font=('宋体',10))
text:控件内容;font:字体
只加控件没办法显示,没有指定指定位置,采用网格式定位:grid()
label.grid() #默认0行0列
5.实现输入框
![]()
entry=Entry(root,font=('微软雅黑',20))
entry.grid(row=0,column=1)
6.实现列表框控件

text =Listbox(root,font=('微软雅黑',14),width=45,height=10)
text.grid(row=1,columnspan=2)
width:列表框宽,height:列表框高
7.下载按钮与退出按钮
下载按钮
button=Button(root,text="开始下载",font=('微软雅黑',15),command=downlaod_song)
button.grid(row=2,column=0,sticky=W)
command=downlaod_song:点击出发方法,这个按钮点击,我们就进行downlaod_songhan函数对歌单进行下载
sticky=W:表示对齐方式,左对齐,分别用W,N,E,S表示左对齐,上对齐,右对齐,下对齐。
退出按钮
button1=Button(root,text="退出",font=('微软雅黑',15),command=root.quit)
button1.grid(row=2,column=1,sticky=E)
root.quit:直接调用已经有的退出窗口方法。
8.窗口显示
有的编译器像pycharm需要这句语句才能显示窗口
root.mainloop()
注意:在写窗口时可能出现这种bug
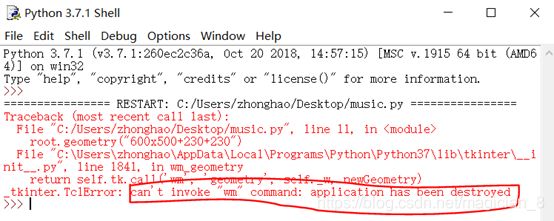
出现这种情况是因为
root.mainloop()语句没有放在窗口所定义的属性后面,解决方法只有把root.mianloop()放到窗口属性后面。
四、爬取音乐
1.了解python爬虫
什么是爬虫
爬取网页数据的程序
爬虫怎么爬取网页数据?
网页的三个特征:
(1).网页都有唯一的URL
(2).网页都是HTML来描述网页信息
(3).网页都是使用HTTP/HTTPS协议来传输HTML数据
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
2.怎么找唯一的URL
(1)先打开网易云音乐的网页版
(2)找到自己喜欢的歌单,确定URL地址
注意:打开网页之后,所看见的上面的地址并不是我们能使用的地址,这个地址具有一定的迷惑性

应该怎么找URL地址能(我是通过火狐浏览器找)
鼠标在网页空白处右键点击查看元素,点击左边的小箭头,放在某一首歌中可以看见每首歌都有自己独特的id
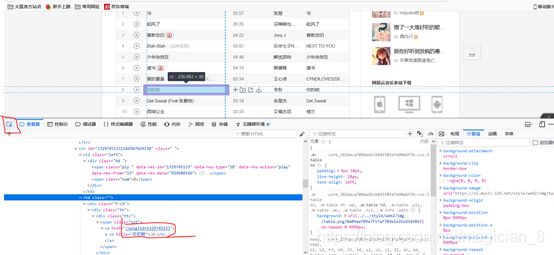
如何找到唯一的URL,右键检查元素,然后选择到网络,把现有的都删除
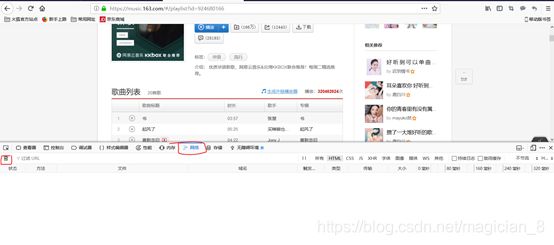
出现这样
点击重新载入
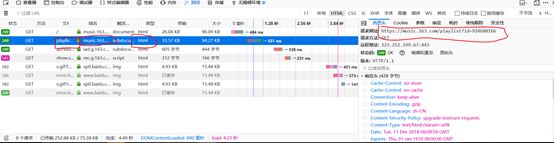
点击如同所示的,可以出现右边的请求网址就是我们要的网址
复制下来:https://music.163.com/playlist?id=924680166
和刚刚上面的地址对比可以看出上面多了"\#"
3.爬虫导入一个库
import requests
requests库并不是标准库,需要下载
打开cmd
输入pip install requests进行下载

出现下面的提示才算成功。
4.编写函数
def downlaod_song(): #上面下载按钮command=downlaod_song
5.爬虫思路
(1)获取用户输入的URL地址,地址用get()从输入框获取
url=entry.get()
(2)请求头
header={
'Host':'music.163.com',
'Referer':'https://music.163.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'
}
对于请求头的内容可以在刚刚得到URL下面获得
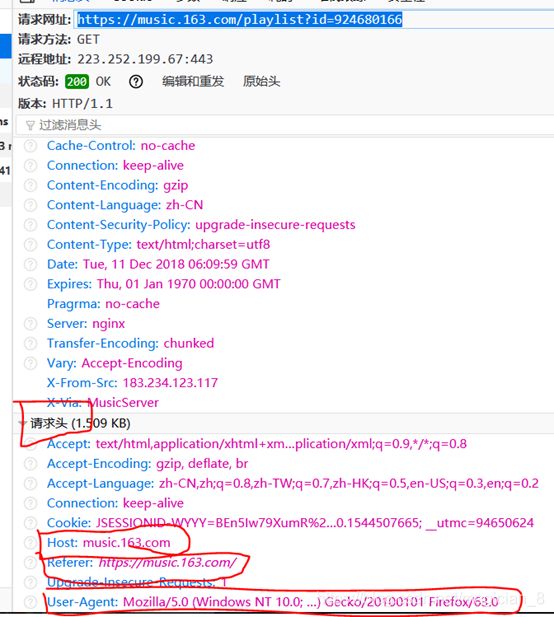
请求的第一个首部,HOST。首部HOST将指出请求的目的地。Referer表示一个来源。User-Agent是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。
如果没有请求头是说明用python代码请求,加上请求头告诉网易云服务器是通过火狐浏览器访问。
(3)获取页面代码
res=requests.get(url,headers=header).text #调用requests的get(url,headers),.text表示得到内容
可以用print(res)查看是否能得到网页的源代码
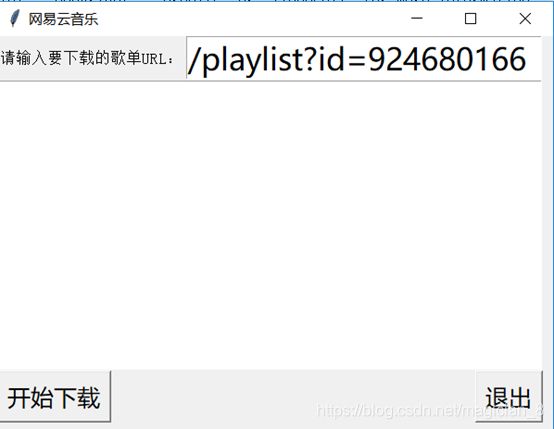
要输入上面保存的URL,点击开始下载
双击红色部分

也有的编译器直接出现源代码,把内容复制到一个文本里面(下面有用处)
(4)创建对象解析网页(只是数据类型发生改变,r变成一个对象而不是原来网页的字符串)
这里需要引入另一个库包BeautifulSoup,BeautifulSoup这个库需要下载,同样打开cmd,但下载时输入 pip install BeautifulSoup4
r=BeautifulSoup(res,"html.parser")
可以用print(r)去检测
(5)获取ID(可以用正则,但这里不是)
music_dict={} #定义一个字典
result=r.find('ul',{'class','f-hide'}).find_all('a') #找到源代码中ul,类名为f-hide,中的a标签
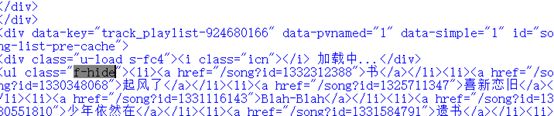
在刚刚保存的源代码中可以看见,每首歌的id都放在ul,类名为f-hide的a标签中
通过print(result)测试,可以看见得到全部歌曲的a标签

也可以看出现在的result是一个列表列表
通过for music in result:
print(music)
进行测试,可以看出result的每个元素

strip("/song?id="),去掉"/song?id="
for music in result:
music_id=music.get('href').strip("/song?id=")
print(music_id) #测试
获取歌曲名字
music_name=music.text
将名字与id对应
music_dict[music_id]=music_name
for music in result:
music_id=music.get('href').strip("/song?id=")
music_name=music.text
music_dict[music_id]=music_name
(6)根据歌曲id下载歌曲
for song_id in music_dict:
#根据id下载歌曲
song_url="https://music.163.com/playlist?id=%s"%song_id
因为每首歌都有自己的id,所以每次都改变id即可
下载路径,需要新建文件夹,注意.mp3后缀
path = "C:\\Users\\zhonghao\\Desktop\\music\\%s.mp3"%music_dict[song_id]
要先有建好的文件夹
如果如果出现以下错误
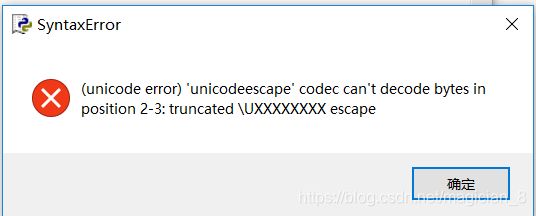
如果这个错误是因为路劲问题,把\都改成\\
显示到控件
添加数据
text.insert(END,"正在下载:%s"%music_dict[song_id])
文本框向下滚动
text.see(END)
更新
text.update()
(7)下载到本地
from urllib.request import urlretrieve
导入urlretrieve
urlretrieve(song_url,path)
最后,附上整个项目代码。
from tkinter import *
import requests
from bs4 import BeautifulSoup
#用于获取id
from urllib.request import urlretrieve
#用urlretrieve来下载到本地
#爬取音乐
def downlaod_song():
#https://music.163.com/playlist?id=924680166
#获取用户输入的URL地址
url=entry.get()
#print(url)
#请求头,如果没有请求头是说明用python代码请求,加上请求头告诉网易云服务器是通过火狐浏览器访问。
header={
'Host':'music.163.com',
'Referer':'https://music.163.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'
}
#获取页面代码get(url)获取url地址,text得到内容
res=requests.get(url,headers=header).text
#输出是测试用,
#print(res)
#创建对象解析网页(只是数据类型发生改变,r变成一个对象而不是原来网页的字符串)
r=BeautifulSoup(res,"html.parser")
#print(r)
#获取ID(可以用正则表达式)
music_dict={}
result=r.find('ul',{'class','f-hide'}).find_all('a')
#根据类名为f-hide的ul标签下的所有a标签,result就是得到所以a标签,是列表
#print(result)
for music in result:
#print(music)
#strip("/song?id="),去掉"/song?id="
music_id=music.get('href').strip("/song?id=")
#print(music_id)
music_name=music.text
music_dict[music_id]=music_name
#print(music_dict)
for song_id in music_dict:
#根据id下载歌曲
song_url="https://music.163.com/playlist?id=%s"%song_id
#下载路径,需要新建文件夹,注意.mp3后缀
path = "C:\\Users\\zhonghao\\Desktop\\music\\%s.mp3"%music_dict[song_id]
#显示到控件
#添加数据
text.insert(END,"正在下载:%s"%music_dict[song_id])
#文本框向下滚动
text.see(END)
#更新
#下载音乐
text.update()
#下载地址 下载路径 下载到本地
urlretrieve(song_url,path)
#搭建界面
#创建窗口
root = Tk()
#窗口标题
root.title("网易云音乐")
#窗口大小
#root.geometry("600x500")设置窗口大小
#root.geometry("+230+230")设置窗口与左上角的距离
#可以合写成下面的语句
root.geometry("600x500+230+230")
#标签控件
label=Label(root,text="请输入要下载的歌单URL:",font=('宋体',10))
#只写标签控件不会显示,还需定位
#采用网格式布局 grid()有默认值0行0列
label.grid()
#输入框
entry=Entry(root,font=('微软雅黑',20))
entry.grid(row=0,column=1)
#列表框控件,columnspan表示跨越两列
text =Listbox(root,font=('微软雅黑',14),width=45,height=10)
text.grid(row=1,columnspan=2)
#点击按钮 sticky表示对齐
button=Button(root,text="开始下载",font=('微软雅黑',15),command=downlaod_song)
button.grid(row=2,column=0,sticky=W)
#command 点击触发的方法
button1=Button(root,text="退出",font=('微软雅黑',15),command=root.quit)
button1.grid(row=2,column=1,sticky=E)
#在pycharm需要显示窗口才能显示
root.mainloop()