【读点论文】FMViT: A multiple-frequency mixing Vision Transformer-期待源码
FMViT: A multiple-frequency mixing Vision Transformer
Abstract
-
transformer模型近年来在计算机视觉任务中得到了广泛的应用。然而,由于自关注的时间和内存复杂度是二次的,并且与输入token的数量成正比,大多数现有的(Vision transformer, vit)在实际工业部署场景中难以实现高效的性能,例如传统cnn所具有的TensorRT和CoreML。尽管最近有人尝试设计CNN-Transformer混合架构来解决这个问题,但它们的整体性能并没有达到预期。为了应对这些挑战,我们提出了一种高效的混合ViT架构,称为FMViT。该方法通过混合高频特征和低频特征来增强模型的表达能力,使其能够有效地捕获局部和全局信息。此外,我们引入了卷积多组重参数化(gMLP)、轻量级多头自关注(RLMHSA)和卷积融合块(CFB)等部署友好机制,以进一步提高模型的性能并减少计算开销。
-
我们的实验表明,在各种视觉任务的延迟/精度权衡方面,FMViT超越了现有的cnn, ViTs和CNNTransformer混合架构。在TensorRT平台上,FMViT在ImageNet数据集的top-1准确率上比Resnet101高出2.5%(83.3%对80.8%),同时保持相似的推理延迟。此外,FMViT达到了与EfficientNet-B5相当的性能,但在推理速度上提高了43%。在CoreML上,FMViT在ImageNet数据集的前1精度上比MobileOne高出2.6%,推理延迟与MobileOne相当(78.5%对75.9%)。我们的代码可以在 https://github.com/tany0699/FMViT 上找到。
Introduction
-
近年来,(Vision transformer, ViTs)在图像分类、目标检测、语义分割等多种计算机视觉应用中取得了成功,受到了业界和学术界的广泛关注。尽管如此,卷积神经网络(cnn)仍然是现实世界视觉任务的首选,主要是因为卷积神经网络通常比传统的cnn(如ResNets)表现得更慢。Transformer模型的推理速度受到诸如多头自关注(MHSA)机制、非熔合的LayerNorm和GELU层等元素以及频繁的内存访问的限制。
-
已经进行了大量的努力来将vit从高延迟问题中解放出来。例如,Swin 、PoolFormer、Reformer 、MaxViT 、SepViT 和MobileViT等模型努力开发更有效的空间注意力方法,并缓解MHSA计算复杂性的二次激增。同时,包括EfficientFormer 和MobileViT 在内的其他项目正在探索构建CNN-Transformer混合架构的方法,以平衡准确性和延迟。这是通过将有效的卷积块与有效的Transformer块集成来实现的。值得注意的是,目前大多数最先进的(SOTA)模型都被设计成CNN-Transformer的混合结构。这些模型主要在初始阶段使用卷积块,并在最后阶段保留Transformer块的堆叠。
-
目前,在现有的工作中,无论是卷积块还是transformer块都无法同时实现效率和性能。尽管多年来精度和延迟之间的权衡得到了改善,但现代混合系统的整体性能仍然需要改进。本研究介绍了设计有效的视觉transformer网络以应对这些挑战的四个关键组件。首先,受NextViT 高频特征和低频特征混合的启发,引入了一种强大的多频融合块(Multi-Frequency Fusion Block, FMB),将多个高频和低频特征融合在一起,增强模型的信息流和表达能力。其次,提出了一种轻量级的卷积融合块(CFB),将卷积的局部建模能力与卷积多组重参数化有效地融合在一起,进一步提高了建模性能;第三,提出了卷积多群重参数化方法。它在训练阶段对不同子信道的空间信息进行整合。在推理阶段将它们融合成一个卷积,在保持推理速度的同时提高了模型的精度。最后,开发了一个轻量级的自我注意块,称为RLMHSA。它采用轻量级和重参数化设计来增强建模能力并加快推理阶段。
-
基于上述方法,提出了一种CNN-Transformer混合架构FMViT。与nextvit类似, TensorRT和CoreML的使用分别表示服务器端和移动设备中实际部署的架构,其推理延迟代表行业中的实际时间消耗。
-
如下图所示,FMViT在ImageNet-1K分类任务中实现了延迟和准确性之间的最佳平衡。在TensorRT上,FMViT在ImageNet数据集上的前1精度超过Resnet101 2.5%,保持了相当的推理延迟。同时,它的性能与EfficientNet-B5相当,推理速度提高了43%。在CoreML上,ImageNet数据集的top-1精度比MobileOne高出2.6%,同时保持相似的推理延迟。
-
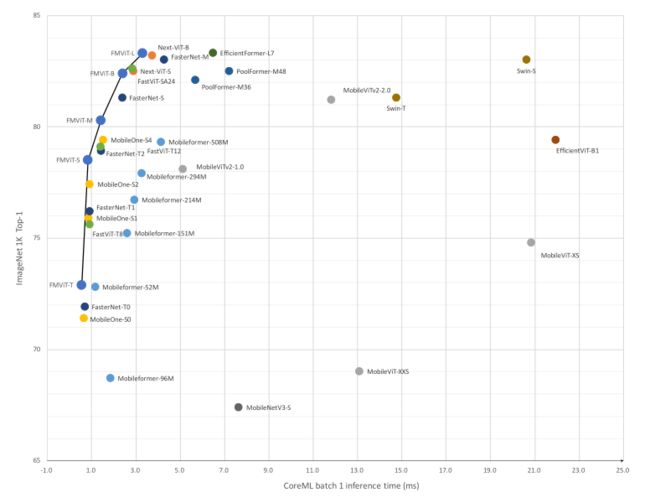
-
Speed-performance trade-off on ImageNet1K
-
-
我们的主要贡献概述如下:
-
提出了一种高效的多频融合块(FMB),将多组高频和低频特征结合起来,增强模型的信息流,增强模型的表达能力。
-
提出了一种轻量级的卷积融合块(CFB),它有效地融合了卷积的局部建模能力,并使用卷积多组重参数化来进一步提高建模性能。
-
提出了卷积多组重参数化方法,在训练阶段将不同子通道的空间信息融合到一个卷积中,在推理阶段将其融合到一个卷积中,从而在保持推理速度不变的情况下提高模型的精度。
-
提出了多组多层感知器层(Multilayer Perceptron Layer, gMPL)块来融合全局信号和局部信息,增强模型的表达能力。
-
提出了一种轻量级自关注模块(RLMHSA),该模块采用轻量化和重参数化设计,增强了模块的全局建模能力,提高了推理阶段的速度。
-
Related Work
Convolutional Networks
- 自2012年以来,卷积神经网络(cnn)已经成为各种计算机视觉应用的事实上的视觉架构标准,例如语义分割,对象识别和图像分类。ResNet 使用残差连接来阻止网络退化,保持网络深度并能够捕获高级抽象。另一方面,DenseNet 促进了特征映射的连接和特征的重用。卷积是由MobileNets按点和深度引入的创建内存使用更少、响应时间更快的模型。通过使用群逐点卷积和信道变换,ShuffleNet 大大降低了计算费用。根据ShuffleNetv2 ,网络架构设计应该优先考虑直接指标,如速度,而不是间接指标,如FLOPs。ConvNeXt 探索了视觉transformer的结构,并提出了一个纯CNN模型,该模型在保留传统CNN的简单性和效率的同时,可以在一系列计算机视觉基准中有效地与最先进的分层视觉transformer竞争。
Vision Transformers
- Transformer的概念最初是在自然语言处理(NLP)领域中引入的。ViT 在实现自我注意时,将图像分割成小块,并将这些小块视为单词,从而证明了Transformer在各种视觉相关任务中的功效。DeiT 提出的知识蒸馏教师学生方法是专门为transformer设计的。T2T-ViT 引入了一种独特的令牌到令牌过程,将图像逐步令牌化为令牌,并在结构上进行聚合。Swin Transformer 引入了一个通用主干,该主干构建分层特征,其计算成本与图像大小成线性比例。同时,PiT 在ViT中加入了池化层,并通过实验验证了其有效性。
Hybrid Models
- 最近的研究表明混合设计集成了卷积和Transformer,有效地利用了这两种架构的优势。BoTNet 采用全局自关注来取代ResNet中最后三个瓶颈块的空间卷积。同时,轻量级和高效的vit,如MobileViT 和MobileViTv2 ,已经为移动设备推出。MobileFormer 与提出的轻量级交叉注意模型的融合提高了计算效率并提高了表征能力。 EfficientFormer和EfficientFormerV2 坚持尺寸一致的设计,无缝地采用硬件友好的4D MetaBlocks和强大的3D MHSA块,通过NAS进行关节尺寸和速度搜索。ToMe提出了一种无需训练即可加速的ViT模型。BiFormer通过双向注意力路由建立了高效的金字塔网络架构。NextViT 分别捕获网络中的一个高频特征和一个低频特征,然后将其混合以增强模型的建模能力。
Structural Reparameterization
- 在训练阶段,重参数化采用复杂模块来提高模型性能。它遵循卷积算子的线性原理,在推理阶段将这些复杂模块合并为更简单的模块。这个过程旨在在不影响性能的情况下提高模型的推理速度。ACNet 率先采用重参数化将3x3个卷积合并为1x1个卷积,而RepVGG 采用重参数化跳过连接,从而降低了内存访问成本。DBB 进一步扩展了六种流行的再参数化方法。引入线性训练时间过参数化的概念来增强这类模型的能力。MobileOne 采用过参数化来提高移动设备视觉转换器的性能。
Methods
- 本节介绍了所提出的FMViT架构,然后讨论和分析了其关键设计。其中包括卷积融合模块(CFB)、多频混合模块(FMB)、轻量级多头注意模块(RLMHSA)、卷积多组重参数化方法(gMLP)以及使用该方法构建的MLP模块。
Overview
-
下图说明了全面的FMViT体系结构。FMViT采用传统的金字塔结构,每个级包括一个下采样模块和一个仅带卷积的卷积融合模块(CFB)或带transformer的多频混合模块(FMB)。该干将空间分辨率降低到原始输入图像的四分之一,并且每个后续阶段逐步将空间分辨率减半,同时逐渐增加通道数量。我们探索了信息交互模块,并受到MetaFormer 的启发,引入了卷积融合模块(CFB)来解决短期数据依赖关系。提出了一种多频混合模块(FMB),通过对多个频段进行分解,进一步融合本地和全局数据。
-
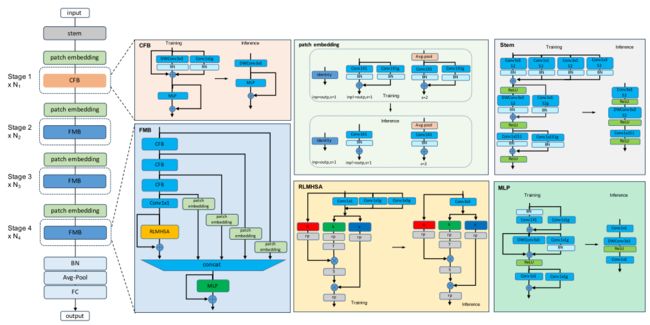
-
如图所示为FMViT的整体结构。它主要包括卷积融合模块(CFB)、多频融合模块(FMB)、轻量级多头注意模块(RLMHSA)和参数化多层感知器模块(gMLP)。
-
-
这种多通道频率融合增强了模型的建模能力。为了降低多头注意力(MHSA)的计算复杂度,提出了一种轻量级的RLMHSA模块。通过参数共享和重新参数化,在不影响模型精度的前提下,提高了模型的推理速度。这些核心模块开发了一系列CNN-Transformer混合架构,在移动端cpu和服务器端gpu上实现了精度和延迟之间的最佳平衡,超越了最先进的模型。
Convolutional multi-group reparameterization
-
1x1卷积是一种具有全局建模能力的线性融合或通道转换机制。利用kxk卷积的平移不变性特征来描述局部空间。缺乏特定相邻信道特征之间的局部建模限制了非分组卷积算子有效的信息融合能力。在训练阶段,我们建议对kxk个卷积进行组重参数化,最初将卷积操作定义为CONV(Kh,Kw,G),其中Kh和Kw表示卷积核大小,G表示卷积群大小。
-
假设将原始卷积定义为CONV A=CONV(Kh,Kw,G),在训练阶段,将不同群大小的多个卷积并行连接:
-
C O N V B = C O N V A + ∑ i = 1 N C O N V ( K h i , K w i , G i ) CONVB=CONVA+\sum_{i=1}^NCONV(K_{h_i},K_{w_i},G_i) CONVB=CONVA+i=1∑NCONV(Khi,Kwi,Gi)
-
其中 ∀ i ∈ N , G i > = G , K h i < = K h , K w i < = K w ∀i∈N, G_i >= G, K_{hi} <= Kh, K_{wi} <= Kw ∀i∈N,Gi>=G,Khi<=Kh,Kwi<=Kw,且N是预定义常数
-
-
下图说明了在推理阶段将CONVB重新参数化为CONV A的过程。任何CONV(Khi,Kwi,Gi)卷积都等价于稀疏CONV(Kh,Kw, G)卷积,即图中虚线的权值保持恒定为零,而其他权值不变。基于可加性,可以将具有相同组数的两个卷积的推理阶段重新参数化为卷积CONV A,如下图下半部分所示。这里,左边代表训练阶段,右边代表推理阶段,两者是等价的。卷积多组重参数化在不影响主模型推理时间的前提下提高了模型性能。
-

-
上图:说明卷积多组重新参数化概念的示意图,CONV(Khi, Kwi, Gi)与稀疏CONV(Kh, Kw, G)相当。下图:通过在训练阶段重新参数化多组卷积,训练阶段的不同组卷积等于推理阶段的单个卷积。
-
-
RepMLP 提出了多层感知器(MLP)的重新参数化。RepMLP采用convKxK融合为FC,但其权值转换比较稀疏,转换后的参数变成了原来的KxK倍,不适合轻量级场景。在Transformer中,由于mlp具有全局建模功能,因此对性能有很大贡献。然而,局部建模能力的缺乏限制了它的潜力。为了帮助原始卷积进行局部通道的分组建模,在两个原始CONV(1,1,1)卷积中引入多个具有G ’ > 1的并行conv1x1卷积,重构MLP模块。该方法同时关注来自不同位置的不同表示子空间的信息,以实现高效的局部表示学习。
-
C O N V ′ X ( 1 , 1 , 1 ) = C O N V X ( 1 , 1 , 1 ) + ∑ i = 1 N C O N V ( 1 , 11 G i ) CONV'X(1,1,1)=CONVX(1,1,1)+\sum_{i=1}^NCONV(1,11G_i) CONV′X(1,1,1)=CONVX(1,1,1)+i=1∑NCONV(1,11Gi)
-
在此上下文中,X=1或X=2表示CONV1或CONV2。CONV1和CONV2表示MLP的两个预参数化卷积,而MLP的后参数化卷积也表示为CONV ’ 1和CONV ’ 2。
-
-
为了增强MLP中全局方面和局部方面的混合建模,在两个卷积之间加入了深度卷积。一个快捷连接确保了全局和局部信息流不相互干扰,并且添加的深度卷积被重新参数化。实验结果表明,在Imagenet1k上增强深度卷积的局部信息融合能力,使MLP的性能提高了1.96%。
Convolutional Fusion Block(CFB)
- Transformer模块已经在各种视觉任务中展示了显著的结果,基于注意力的令牌混合器模块和MetaFormer 范式强调了它们固有的优势。然而,Transformer块的推理速度可能更有效,特别是在多头注意力、LayerNorm和GELU计算的性能不是最优的移动设备上。我们已经证明了MetaFormer范式的成功,并在此基础上提出了一个高效的CFB模块,该模块专门使用深度可分离卷积(DWConv)作为令牌混频器。CFB保持了瓶颈块的部署优势,同时实现了与Transformer块相当的性能,如上图所示。CFB使用DWConv和MLP构建,遵循通用的MetaFormer设计。CFB确保了性能,同时显著提高了推理部署性能。此外,在训练过程中实现了重新参数化,以进一步提高CFB的性能,其中DWConv使用了标准的、广泛使用的重新参数化。MLP采用了本文提出的卷积多群重参数化方法。
Multi-frequency Fusion Block(FMB)
-
虽然CFB已经有效地学习了地方代表性,但处理全球信息收集的迫切需要仍然存在。transformer 块捕获低频信号,提供全局信息,如形状和结构。现有的研究表明,Transformer块可能会部分地减少高频信息,包括局部纹理细节。为了提取更多的基本和独特的特征,来自不同频段的信号必须精心整合,因为它们对人类视觉系统至关重要。
-
高频信号提供局部信息,这对于保持信息的完整性是不可或缺的。不同的频率特征提供独特的信息,使高频信号容易受到变压器块的退化。各种高频特征与低频特征的融合可以增强模型的信息流和表达能力,灵感来自图像超分辨率中的信息蒸馏和频率混合。如图所示,CFB模块最初捕获高频特征,随后以不同频率输出三组高频特征。然后采用贴片嵌入融合对轻量级多头注意力模块的输出进行拼接,从而产生高低频信号。通过MLP层,可以提取更基本、更显著的特征。下式可表示为:
-
z 1 = f 1 ( x l − 1 ) z 2 = f 2 ( z 1 ) z 3 = f 3 ( z 2 ) z 4 = f 4 ( z 3 ) z = C o n c a t ( x l − 1 , z 1 , z 2 , z 3 , z 4 ) x l = z + M L P ( z ) z_1=f_1(x^{l-1})\\ z_2=f_2(z_1)\\ z_3=f_3(z_2)\\ z_4=f_4(z_3)\\ z=Concat(x^{l-1},z_1,z_2,z_3,z_4)\\ x^l=z+MLP(z) z1=f1(xl−1)z2=f2(z1)z3=f3(z2)z4=f4(z3)z=Concat(xl−1,z1,z2,z3,z4)xl=z+MLP(z)
-
这里定义 x l − 1 x^{l−1} xl−1为第(l−1)块的输入, x l x^l xl为第lth块的输出。CONCA T是指CAT连接操作。f1-f3表示产生不同高频信号的高通滤波器,以CFB为例。f4是产生低频信号的低通滤波器,如RLMHSA所示。
-
-
与LN和GELU不同,FMB始终使用BN和ReLU作为有效规范层和激活层。这些运算符可以有效地计算,特别是在移动设备上,由于其速度友好的性质,性能损失最小。FMB可以在轻量级框架内收集和集成多频率信息,因此与传统的纯Transformer模块相比,显著提高了模型的性能。
Lightweight Multi-head Self-Attention (RLMHSA)
-
Transformer的计算需求与输入令牌维度的平方成正比,因此在处理大输入维度时计算量很大。尽管参数数量相对较少,但在移动设备上的推理时间很长,因此需要对自关注模块进行更轻量化的设计。ViT-LSLA用原始输入(X)代替了自注意的Key (K)和V值(V),实现了轻量级的自注意结构。如上图所示,我们提出了一种轻量级的多头自关注方法,该方法共享参数,然后在本研究中应用重新参数化。原始MSA的定义如下:
-
A t t e n ( Q , K , V ) = s o f t m a x ( Q K T ) V Atten(Q,K,V)=softmax(QK^T)V Atten(Q,K,V)=softmax(QKT)V
-
其中 Q = X W q , K = X W k , V = X W v Q = XW_q, K = XW_k, V = XW_v Q=XWq,K=XWk,V=XWv,分别输入 X ∈ R M × d X∈\R^{M×d} X∈RM×d, Query, Key, values矩阵 W q , W k , W v ∈ R d × d W_q, W_k, W_v∈\R^{d×d} Wq,Wk,Wv∈Rd×d, M为令牌个数,d为令牌维数。对方程3进行变形,得到:
-
A t t e n ( Q , K , V ) = S o f t m a x ( X W q ( X W k ) T ) X W v = S o f t m a x ( X W q W k T X T ) X W v = S o f t m a x ( X W q k X T ) X W v = S o f t m a x ( X ( X W q k T ) T ) X W v = A t t e n ( X , K ′ , V ) Atten(Q, K, V ) = Softmax(XW_q(XW_k)^T )XW_v\\ = Softmax(XW_qW^T_k X^T )XW_v\\ = Softmax(XW_{q^k}X^T )XW_v\\ = Softmax(X(XW^T_{q_k})^T )XW_v\\ = Atten(X, K′, V ) Atten(Q,K,V)=Softmax(XWq(XWk)T)XWv=Softmax(XWqWkTXT)XWv=Softmax(XWqkXT)XWv=Softmax(X(XWqkT)T)XWv=Atten(X,K′,V)
-
对Q和K的投影矩阵进行合并,实现参数共享,得到一个新的矩阵 W q k , K = X W q k T W_{qk}, K = XW^T_{qk} Wqk,K=XWqkT。并且,允许Wqk和Wv共享参数,它们共享一个投影卷积,记为W = W Tqk = Wv,则:
-
A t t e n ( X , K ′ , V ′ ) = S o f t m a x ( X ( X W ) T ) X W Atten(X, K′, V ′) = Sof tmax(X(XW )^T )XW Atten(X,K′,V′)=Softmax(X(XW)T)XW
-
其中K ’ = XW, V ’ = XW, RLMHSA的结构如图2所示。因此,需要一个单独的卷积来映射输入向量,K和Q向量共享相同的卷积,从而消除了两个单独的卷积的需要。在训练过程中,采用卷积多组参数化模拟RLMHSA模块的局部和全局信息融合,提高了MHSA的性能。实验结果表明,与Imagenet1k分类任务上的MHSA相比,RLMHSA减少了8M的参数计数,加速了3%,性能提高了0.5%。
-
Stem block and Patch Embedding block
- 根据FastViT 的建议,该模型的初始阶段采用具有两次降采样操作的阀杆来减少计算负荷。通过使用Conv3x3+DWConv3x3设计实现了轻量化结构。初始卷积利用Conv3x1和Conv1x3重新参数化垂直和水平边缘提取。补丁嵌入存在几种场景:如果输入和输出通道号和令牌维度相同,则不需要任何操作。当输入和输出通道号不同,但令牌维度保持不变时,使用Conv1x1进行通道号转换。如果令牌维度变化,则使用轻量级的降采样操作avg-pool进行降采样,然后使用Conv1x1卷积进行融合或转换。在训练阶段,为了提高准确率,还采用了卷积多组重参数化方法。
FMViT Architectures
-
如下表所示,本研究根据参数的数量和模型的大小,提出了五种模型结构供参考,分别是fmvitt - t、fmvits、FMViTM、fmvitb和fmvitl。这里的“Channels”是指模块内部子模块输出的通道数;“FM-Channels”表示FMB中频分信道数,“S”表示卷积步幅,即Avg-pool。每个MLP层的膨胀比设为2,RLMHSA中的头部维数固定为32。与nextit 一致标准化和激活函数采用2022a)、BatchNorm和ReLU。
-
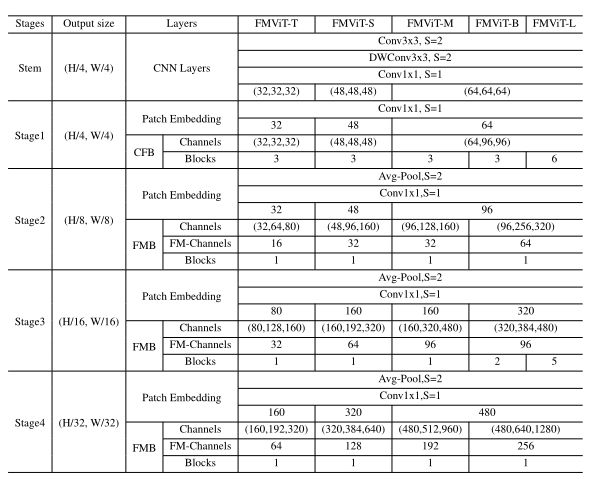
-
Architecture details of FMViT variants.
-
Experimental Results
- 在这个实验片段中,我们使用PyTorch 1.12.1版本进行PyTorch推理延迟,使用TensorRT-8.5.3框架进行TensorRT (TRT)推理延迟。两者都是在A10 GPU和CUDA 11.3的硬件环境中测量的。CoreML推理延迟是使用带有iOS 16.6的iPhone 13进行测量的。所有批大小都统一设置为1。
ImageNet-1K Classification
-
我们在ImageNet-1K数据集上执行了一个图像分类实验,该数据集包括1000个类别的大约128万张训练图像和5万张验证图像。为了保持公平,我们复制了最近的视觉Transformer的训练参数,并进行了轻微的调整。所有FMViT变体都在8个V100 gpu上进行了训练,总批大小为2048,迭代300次。输入图像被调整为224 x 224的分辨率。利用0.1的权重衰减,我们使用了AdamW 优化器。对于所有FMViT变体,基于余弦策略逐渐降低学习率,从4e-5开始,并使用线性预热方法进行20个epoch。
-
如下表所示,与cnn、vit和混合网络等最新技术相比,我们的方法实现了准确性和延迟的最佳平衡。当与著名的cnn如ResNet101进行基准测试时,FMViT在ImageNet数据集上的前1名准确率超过ResNet101 2.5%(83.3%对80.8%),在CoreML上快45% 。同时,它的性能与EfficientNet-B5 相当,推理速度提高了43%。在ViT的背景下,FMViT-B优于swing - t ,在CoreML和TensorRT上速度快6倍,但性能却高出1.1%。在相同的推理速度下,FMViT-S在TensorRT上比DeiT-T高出6.3%(78.5%对72.2%)。在相似的推理速度下,FMViTS比CoreML高出8.1%(80.3%对72.2%)。与混合方法相比,fmviti - l的性能与EfficientFormer-L7 相当,但在TensorRT和CoreML上的推理速度分别提高了30%和96%。与MobileOne-S1 相比,FMViTS在具有相当CoreML推理速度的情况下实现了2.6%的性能提升(78.5% vs. 75.9%), CoreML的推理性能提高了11%,准确率提高了2.9% (78.5% vs. 75.6%)。这些结果表明,所提出的FMViT设计是一个可行的和有前途的范例。
-
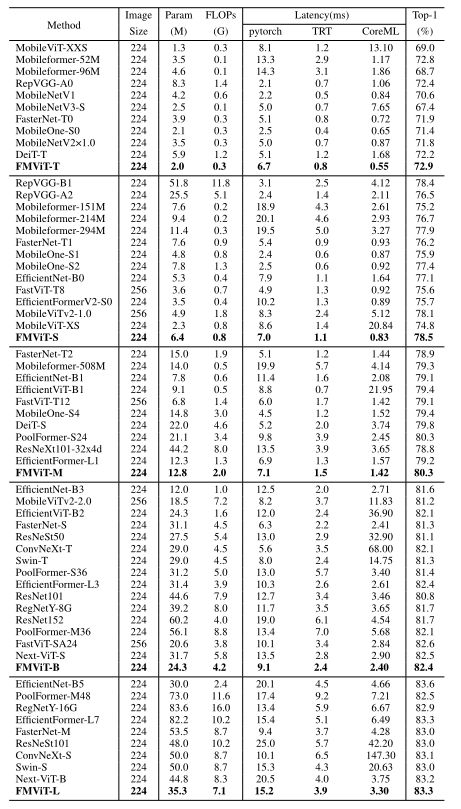
-
Comparison of different state-of-the-art classification methods for ImageNet-1K.
-
Object Detection and Instance Segmentation
-
我们基于Mask R-CNN 架构和COCO2017 评估FMViT在目标检测和实例分割任务上的性能。具体来说,我们所有的模型最初都是在ImageNet-1K上训练的,随后使用以前工作中的设置进行微调。采用AdamW优化器,权值衰减0.05,训练时间跨度为12个epoch。在训练过程中进行500次迭代的预热,在第8次和第11次迭代时学习率降低10%。输入分辨率为1344x800。为了公平的比较,我们仅评估骨干延迟,并且测试环境与分类保持一致。
-
下表给出了使用Mask R-CNN架构的评估结果。为了公平起见,我们专门测量了骨干网络的延迟。如表3所示,FMViT-B超过ResNet101 3.7 A P b AP^b APb,同时在TensorRT上实现了16%的快速推理。fmvitb在TensorRT上的推理速度与PoolFormer-S12 相当,但具有6.8 A P b AP^b APb的增强。与EfficientFormer-L3相比,fmvitb在TensorRT上的推理速度提高了7%,性能提高了2.7 AP / b。相对于Next-ViT-S, FMViT-B在CoreML上的推理速度提高了3.9倍,性能提高了0.3倍。fmvitl的性能比EfficientFormer-L7高出3.8 A P b AP^b APb,在TensorRT上的推理速度提高了32%。fmviti - l和resnesst101在TensorRT上具有相同的推理速度,但fmviti - l的性能提高了1.2 A P b AP^b APb。口罩的AP也表现出类似的优势。综上所述,FMViT在目标检测和实例分割方面表现出色,同时保持了较低的推理延迟。
-
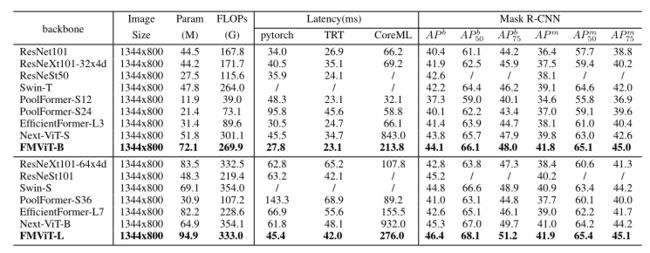
-
基于Mask r - cnn的不同骨干网目标检测和实例分割任务的比较。上标b和m表示盒检测和掩码实例分割。
-
ADE20K Semantic Segmentation
-
我们利用ADE20K数据集进行了语义分割测试,该数据集包括150个类别的大约20K训练图像和2K验证图像。为了公平比较,我们在语义FPN 上遵循前面视觉transformer的训练协议框架。模型首先在ImageNet-1K上以224x224的分辨率进行预训练,然后在ADE20K上以512x512的输入大小进行训练。对于语义FPN框架,我们采用了学习率和权重衰减为0.0001的AdamW优化器。我们训练整个网络进行40K次迭代,总批大小为32。考虑到在TensorRT和CoreML上实现Mask R-CNN的各个模块的复杂性,为了公平的比较,我们将延迟评估限制在主干上,保持与分类相同的测试设置。为简单起见,我们使用512x512的输入大小来测量延迟。
-
下表表明,FMViT-B在TensorRT和CoreML上保持一致的推理速度的同时,超过ResNet101 4.7 mIoU。超过swin - t 减少2.0miou。与PoolFormer-S24 相比,它实现了3.2 mIoU的更高性能,并且在TensorRT推理方面快了8%。与next - vits相比,我们的性能提高了0.5 mIoU,在TensorRT和CoreML上的推理速度分别提高了18%和43%。fmviti - l的性能比swing - s高1.7 mIoU,比CoreML高4.5 mIoU,比resnesst101快25倍。它与PoolFormer-S36的推理性能相当,但具有4.9 mIoU的优势。TensorRT和CoreML上的推理比next - vitb快2.5%和29%,mIoU相当。综合测试表明,我们的FMViT在分割任务中具有巨大的潜力。
-
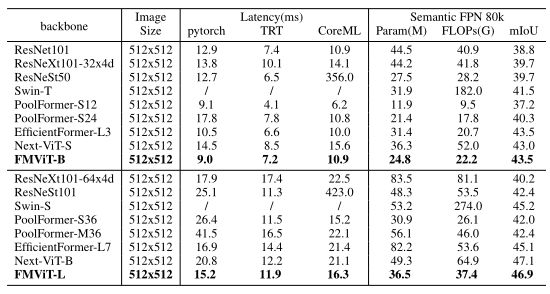
-
不同主干在ADE20K语义分割任务上的比较。
-
Ablation Study
-
我们建立了一系列实验来验证FMViT中FMB、gMPL和RLMHSA模块的效率,如下表所示。在这里,我们将我们提出的模块纳入FMViT-T0模型,并坚持与原始模型相同的训练方法。RLMHSA取代了传统的MHSA, gMPL取代了标准的MPL, FMB不用于混频;只有标准的MHSA输出特征直接馈送到MLP
-
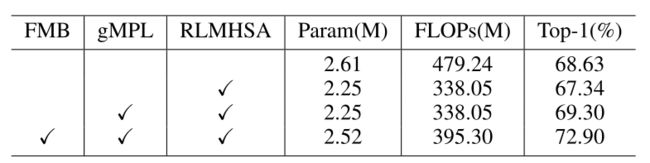
- Compare different modules.
-
-
实验结果表明,用我们更精简的RLMHSA取代标准MHSA会降低分类性能,尽管参数和FLOPs增加了。将传统的MLP模块替换为卷积多组重参数化gMLP模块后,推理阶段的参数数量和FLOPs保持相当,但分类性能有所提高。最后,引入FMB模块显著增加了参数数量和FLOPs。
Visualization
-
NextViT建立了CNN卷积块倾向于高频信号,而ViT则倾向于低频信号。我们提出的FMB同时捕获多种高频和低频信号,从而获得更丰富的纹理信息和更精确的全局信息,增强了FMViT的建模能力。为了更好地理解FMViT,我们可视化了FMViT - t0中RLMHSA输出特征在高频和低频下的傅立叶谱。RLMHSA内有5个不同频率的特征,每个特征代表不同的频率特征,记为f1-f5。下图说明了这一点。RLMHSA的输出特征f1捕获了低频信号,这表明RLMHSA擅长建模全局信息。f2-f5,各种cfb的输出,捕获不同的高频信号。每个输出对应一个不同的频率,所以他们精通处理各种纹理。f1-f5频率特征的融合增强了模型的表达能力。
-

-
FMViT中不同模块输出特征的傅里叶谱。
-
Conclusion
- 在本研究中,我们介绍了一种混合ViT架构,该架构针对移动设备和服务器gpu的高效部署进行了优化。这种结构通过合并不同频率的高频和低频特征来增强模型的预测能力,从而增强模型捕获本地和全局信息的能力。实验结果表明,FMViT在多种视觉任务(包括图像分类、目标检测和语义分割)中实现了最先进的延迟和精度权衡。然而,我们提供的模型没有经过进一步的审查就被堆放在一起。未来的工作可以采用网络架构搜索(NAS)或其他堆叠方法来探索不同组合模型对性能的影响。