HBase详细部署流程
大数据平台XSailboat简介_OkGogooXSailboat的博客-CSDN博客
1、部署环境
在安装HBase之前,首先应确保以下基础设施构建成功:
- JDK 8版本安装设置成功:jdk8.0_161以上版本(JDK 8.0_161以上版本,默认启用无限强度加密,不需要再安装JCE Policy File。)
- Zookeeper-6.2安装部署成功
- Hadoop-3.2.2安装部署成功
- 操作系统设置完毕,包括:
- 用户hadoop,用户组hadoop
- 安装根目录/xcloud,用户hadoop及其组拥有完全权限
- 关闭SElinux
- 关闭防火墙
- 主机间无密码SSH登录
2、安装
2.1 上传安装包
使用FTP上传安装文件(hbase-2.4.2-bin.tar.gz)到主机的 /xcloud 目录。
2.2 解压并修改目录名
命令:
| su hadoop cd /xcloud tar -zxvf hbase-2.4.2-bin.tar.gz mv hbase-2.4.2 hbase |
2.3 修改系统环境变量
命令:
| su // 切换root用户 vi /etc/profile // 用root用户修改配置文件 source /etc/profile // 用root用户重新启用配置文件 su hadoop // 切换hadoop用户,重新启用配置 source /etc/profile |
修改后(添加以下内容):
![]()
2.4 修改xcloud/hbase/conf/hbase-env.sh文件
命令:
| su hadoop vi /xcloud/hbase/conf/hbase-env.sh |
修改后(添加如下内容):

补充:添加“export HBASE_PID_DIR=/xcloud/hbase/tmp”,否则,关闭master等节点时,提示找不到pid文件。
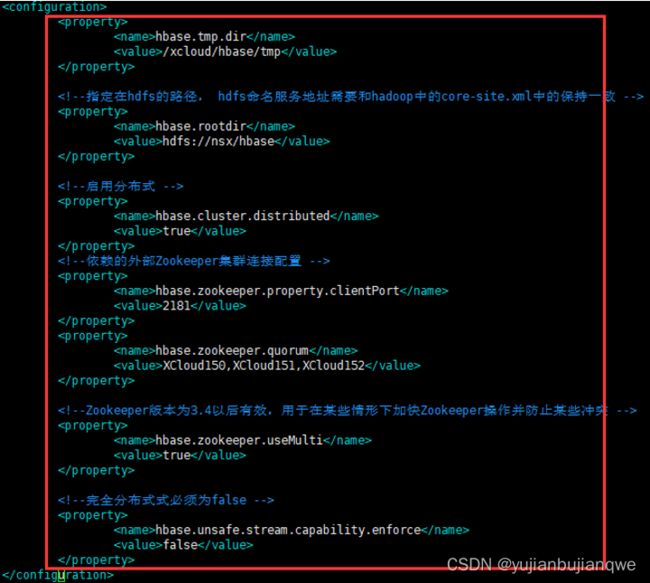
2.5 修改xcloud/hbase/conf/ hbase-site.xml文件
命令:
| su hadoop vi /xcloud/hbase/conf/hbase-site.xml |
修改后(添加如下内容):
2.6 修改/xcloud/hbase/conf/backup-masters文件
初始情况下,backup-masters文件不存在,需手动创建,然后添加master主机信息。
命令:
| su hadoop touch /xcloud/hbase/conf/backup-masters // 创建backup-masters配置文件 vi /xcloud/hbase/conf/backup-masters |
修改后(添加以下内容):
![]()
注意:backup-masters文件的参数取值必须是Unix格式,否则会引发如下错误:

2.7 修改/xcloud/hbase/conf/regionservers文件
命令:
| su hadoop vi /xcloud/hbase/conf/regionservers |
修改后(添加以下内容):

3、启动
3.1 方式一(未验证)
命令:
| su hadoop cp $HADOOP_HOME/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/client-facing-thirdparty/ // 将hadoop中的jar拷贝到hbase cd /xcloud/hbase/bin ./start-hbase.sh |
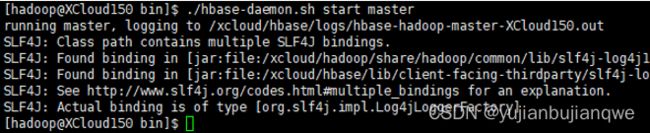
3.2 方式二
根据主机规划,分别在XCloud150、XCloud151上执行如下命令,启动master。
命令:
| su hadoop cd /xcloud/hbase/bin ./hbase-daemon.sh start master |
输出:
根据主机规划,分别在XCloud152、XCloud153、XCloud154上执行如下命令,启动regionserver:
命令:
| su hadoop cd /xcloud/hbase/bin ./hbase-daemon.sh start regionserver |
输出:

3.3 验证:进程
命令:jps
输出(master主机应显示HMaster进程;region主机应显示HRegionServer进程 ):


3.4 验证:Web界面
在浏览器中输入各服务节点的web地址,查看相应的web界面。
HMaster访问地址:
http://192.168.0.150:16010
http://192.168.0.151:16010
HRegionServer访问地址:
http://192.168.0.152:16030
http://192.168.0.153:16030
http://192.168.0.154:16030
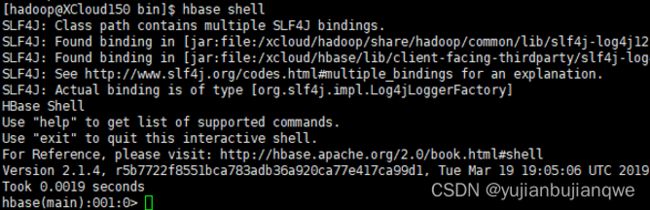
3.5 验证:HBase Shell
- 所有服务启动后,在任意主机上执行如下命令可进入HBase Shell:
| su hadoop hbase shell |
执行成功后,可进入HBase Shell环境:
- 创建一个表(test表,cf列簇):
| create 'test', 'cf' |
输出:

- 使用list命令确认表格test创建成功:
| list 'test' |
输出:

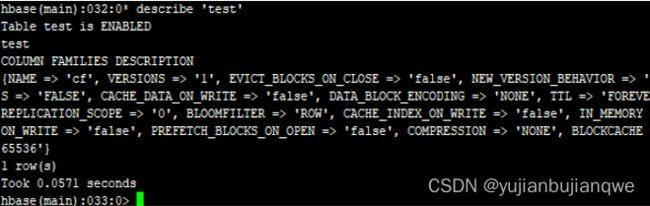
- 使用describe命令查看表test的属性(配置):
| describe 'test' |
输出:
- 插入数据:
| put 'test', 'row1', 'cf:a', 'value1' put 'test', 'row2', 'cf:b', 'value2' put 'test', 'row3', 'cf:c', 'value3' |
输出:

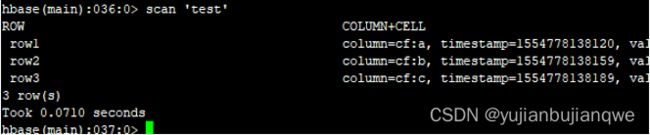
- 遍历(scan)表内容:
| scan ‘test’ |
输出:
- 获取(get)表的某一行:
| get 'test', 'row1' |
输出:

- 禁用(disable)表(删除表格或修改表格配置前,对应启用表格的命令为enable):
| disable 'test' |
输出:
![]()
- 启用(enable)表
| enable 'test' |
输出:
![]()
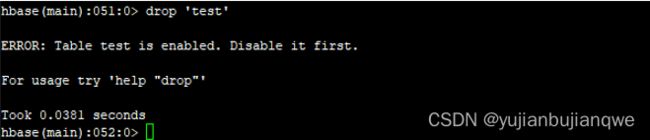
- 删除(drop)表
| drop 'test' |
输出(可以看到如果一个表未disable,直接删除会引发报错):
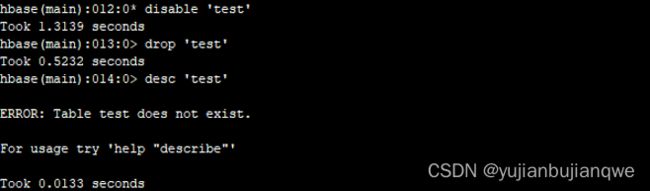
注意:删除表格(要首先disable),并确认表格已不存在(desc命令):
| disable 'test' drop 'test' desc 'test' |
输出:
- 退出HBase Shell:
| quit |
输出:
![]()
4、常见错误
4.1 org.apache.hadoop.hbase.ClockOutOfSyncException
org.apache.hadoop.hbase.ClockOutOfSyncException:
org.apache.hadoop.hbase.ClockOutOfSyncException: Server xxxxxx,60020,1416564592512 has been rejected; Reported time is too far out of sync with master. Time difference of xxxxx ms > max allowed of 30000ms
这是由于各节点的时间不同步引起的,解决这个问题需要在集群各几点上安装和启动NTP服务,并选取其中一台机器(往往是master节点)做为集群内的时间服务器,从而确保整个集群所有机器的时间是一致的。
每台机器可以使用如下命令与网络同步时间:
| ntpdate cn.pool.ntp.org |
4.2 FATAL [master:xxxxx:60000] master.HMaster
FATAL [master:xxxxx:60000] master.HMaster: Unhandled exception. Starting shutdown.
org.apache.hadoop.security.AccessControlException: Permission denied: user=hbase, access=WRITE, inode="/":hadoop:supergroup:drwxr-xr-x
这是由于启动HBase服务的用户没有在HDFS指定目录上(这里是根目录)进行写操作的权限。出现这种问题的常见原因是使用了某个专有帐号(比如hadoop)启动了hadoop的各项服务,而使用了另个某个专有帐号(比如hbase)去启动hbase,由于hbase在初次启动时需要在HDFS的根目录上建立一个hbase文件夹来存放数据,而对于hdfs来说,只有hadoop用户才有权在根目录上进行写操作。所以解决的方法就是使用hadoop用户在hdfs的根目录上建立一个hbase文件夹,同时把它的group和owner都改为hadoop就可以了。
4.3 java.net.UnknownHostException: nsx
Caused by: java.lang.IllegalArgumentException: java.net.UnknownHostException: nsx
原因:使用Hadoop的HA时,必须在conf/hbase-env.sh文件中指定HADOOP_CONF_DIR选项,才能使得HBase能够解析Hadoop配置中的dfs.nameservices=nsx指定的“nsx”这个Hadoop集群名。
具体设置可参考:2.4.2 conf/hbase-env.sh 。
4.4 java.lang.RuntimeException: HRegionServer Aborted
启动hbase集群的时候,刚启动时每个节点上的进程都显示正常,过一会其他两个节点上的HRegionServer自动挂掉。查看日志,报错:java.lang.RuntimeException: HRegionServer Aborted。重新启动,马上又挂掉。
原因:默认当加载错误的协处理器之后,会导致regionserver挂掉。
修改配置文件添加
在hbase的配置文件中hbase-site.xml添加:
然后重新启动habse,问题就解决。
5、HBase HBCK2问题修复
HBCK2命令详解,请阅读《HBaseFsck使用教程》
5.1 问题1
问题描述:机房突然断电,Hadoop集群服务器(含HBase服务器)全部死机,重启后,HBase的procedure被卡住了
部分问题截图:
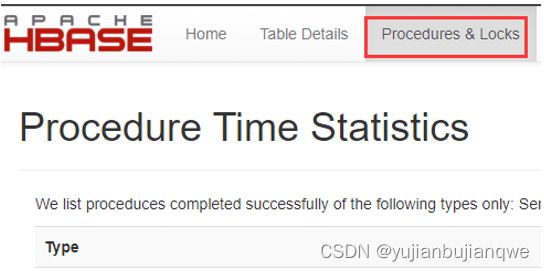

从截图中可以看到pid为835的procedure被锁住了,此外在Procedures列表中,可以看到835 的procedure下还有子procedure(截图缺失)。因此需人工释放procedure,命令bypass,选项 -o 、-r。
解决方法:
./hbase hbck -j /xcloud/HBCK2/hbase-operator-tools/hbase-hbck2/target/hbase-hbck2-1.3.0-SNAPSHOT.jar bypass -o -r 835
5.2 问题2
问题描述:衔接问题1,释放procedure后,发现被锁住的procedure相关region不一致。
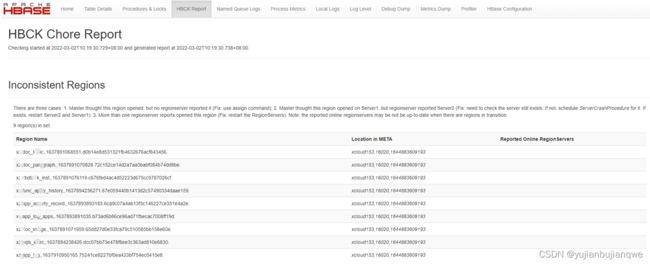
HBase 推荐解决方案如下:
There are three cases: 1. Master thought this region opened, but no regionserver reported it (Fix: use assign command); 2. Master thought this region opened on Server1, but regionserver reported Server2 (Fix: need to check the server still exists. If not, schedule ServerCrashProcedure for it. If exists, restart Server2 and Server1): 3. More than one regionserver reports opened this region (Fix: restart the RegionServers). Note: the reported online regionservers may be not be up-to-date when there are regions in transition.
有三种情况:1。Master认为该区域已打开,但没有regionserver报告(修复:使用assign命令);2.Master认为此区域已在Server1上打开,但regionserver报告Server2(修复:需要检查服务器是否仍然存在。如果不存在,请为其安排ServerCrashProcedure。如果存在,请重新启动Server2和Server1):3。多个regionserver报告打开了此区域(修复:重新启动regionserver)。注意:当存在过渡区域时,报告的在线区域服务器可能不是最新的。
解决方法:
./hbase hbck -j /xcloud/HBCK2/hbase-operator-tools/hbase-hbck2/target/hbase-hbck2-1.3.0-SNAPSHOT.jar assigns -o d0b14e8d531321fb4632676acf843456 72c152ce14d2a7aa3babf084b74dd8be c676fed4ac4d52223d675cc9787026cf 67e059440b1413d2c57490334daae159 6ca9c07a4ab13f3c146227ce351e4a2e b73ad6b86ce96ad71fbecac7008ff19d 65dd27d0e33fca79c510585bb158e60e dcc07bb73e478f8ee3c363ad810e6830 75241ce8227bf0ea423bf754ec0415e8
5.3 问题3:Master is initializing
问题表现:
- hbase shell命令行里,执行list卡死;
- master节点日志里,提示:
hbase:meta,,1.1588230740 is NOT online; state={1588230740 state=OPEN, ts=1665392578303, server=xcloud155,16020,1665108323474}; ServerCrashProcedures=false. Master startup cannot progress, in holding-pattern until region onlined. |
- hbase hbck -detail 校验,提示:
| ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing |
修复步骤一:
网上查询资料,提到可能是时间不同步导致的,查看后发现hbase集群的时间的确不同步,依次执行以下命令同步时间:
yum install -y chrony
systemctl start chronyd
systemctl enable chronyd
vim /etc/chrony.conf
修改后:

systemctl restart chronyd.service
chronyc sources -v 同步时间
同步时间后,重启hbase发现问题依旧存在,继续执行修复步骤二。
备注:Chrony是一个开源自由的网络时间协议 NTP 的客户端和服务器软软件。如果已经按照,可以直接同步时间。
修复步骤二:
在hbase-site.xml文件中,添加如下配置,并重启hbase。
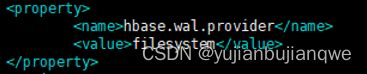
重启后,hbase依然存在问题,表现如下:
- hbase shell命令行里,执行list可查看命名空间及表,但scan 查看表数据,提示表不存在。
- hbase的表数据实际存储在hdfs中,查看hdfs文件系统,发现数据还在

- 执行scan 'hbase:meta',可查看元数据表信息
- 执行scan ‘hbase:namespace’,提示表不存在
- master节点日志里,提示:
| java.lang.IllegalStateException: Expected the service ClusterSchemaServiceImpl [FAILED] to be RUNNING, but the service has FAILED at org.apache.hbase.thirdparty.com.google.common.util.concurrent.AbstractService.checkCurrentState(AbstractService.java:379) at org.apache.hbase.thirdparty.com.google.common.util.concurrent.AbstractService.awaitRunning(AbstractService.java:319) at org.apache.hadoop.hbase.master.HMaster.initClusterSchemaService(HMaster.java:1317) at org.apache.hadoop.hbase.master.HMaster.finishActiveMasterInitialization(HMaster.java:1048) at org.apache.hadoop.hbase.master.HMaster.startActiveMasterManager(HMaster.java:2177) at org.apache.hadoop.hbase.master.HMaster.lambda$run$0(HMaster.java:509) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.IOException: Timedout 300000ms waiting for namespace table to be assigned and enabled: tableName=hbase:namespace, state=ENABLED at org.apache.hadoop.hbase.master.TableNamespaceManager.start(TableNamespaceManager.java:107) at org.apache.hadoop.hbase.master.ClusterSchemaServiceImpl.doStart(ClusterSchemaServiceImpl.java:63) at org.apache.hbase.thirdparty.com.google.common.util.concurrent.AbstractService.startAsync(AbstractService.java:249) at org.apache.hadoop.hbase.master.HMaster.initClusterSchemaService(HMaster.java:1315) |
修复步骤三:
根据以上表现,猜测hbase:meta因为某些原因丢失一些region的信息,这个时候可以使用hbck2的addFsRegionsMissingInMeta 进行修复,该命令会扫描hdfs中Region目录的region_info的信息并根据该信息进行region重建,最后在运行该命令输出的assign命令进行重新分配
在hbase/bin目录下执行命令:
| ./hbase hbck -j /xcloud/hbase/operator/hbase-hbck2-1.2.0-SNAPSHOT.jar addFsRegionsMissingInMeta hbase:namespace |
返回结果:

按返回结果的提示,在hbase/bin目录下,重启master节点,并重新分配region,命令:
| ./hbase-daemon.sh restart master ./hbase hbck -j /xcloud/hbase/operator/hbase-hbck2-1.2.0-SNAPSHOT.jar assigns 8917a5cfa9183f7ca7da0c052138b177 |
修复成功!
HBCK2参考资料:https://zhuanlan.zhihu.com/p/373957937
大数据平台XSailboat简介_OkGogooXSailboat的博客-CSDN博客