JVM性能调优实战
JVM调优调什么
JVM 调优是一个系统而又复杂的过程,但我们知道,在大多数情况下,我们基本不用去调整 JVM 内存分配,因为一些初始化的参数已经可以保证应用服务正常稳定地工作了。而且一般情况下,就算出现了,也是架构师级别的去处理。
实际上,JVM调优,调的是稳定,并不能带给你性能的大幅提升。服务稳定的重要性就不用多说了,保证服务的稳定,gc永远会是Java程序员需要考虑的不稳定因素之一。复杂和高并发下的服务,必须保证每次gc不会出现性能下降,各种性能指标不会出现波动。因此我们通过压测的方式来看一下对JVM的性能是否造成影响。而压测主要就是看吞吐量和响应时间。
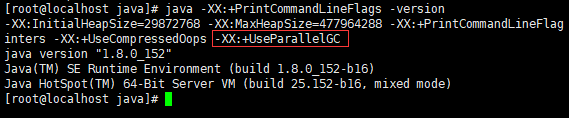
JDK1.8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)。Parallel就是关注吞吐量的垃圾收集器,高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务。通过命令java -XX:+PrintCommandLineFlags -version 可以查看默认垃圾回收器。
所谓吞吐量就是 CPU 用于运行用户代码的时间与 CPU 总消耗时间的比值,即:
- 吞吐量:吞吐量是指单位时间内系统能处理的请求数量,体现系统处理请求的能力,这是目前最常用的性能测试指标。即
吞吐量 = 运行用户代码时间 / (运行用户代码时间+垃圾收集时间)。 - 响应时间:执行一个请求从开始到最后收到响应数据所花费的总体时间,即从客户端发起请求到收到服务器响应结果的时间。
压测工具 AB
Ab(ApacheBench) 测试工具是 Apache 提供的一款测试工具,具有简单易上手的特点,在测试 Web 服务时非常实用。ab 一般都是在 Linux 上用。安装非常简单,只需要在 Linux 系统中输入命令安装:
yum-y install httpd-tools
AB命令参数
ab [options] 需要进行压力测试的url
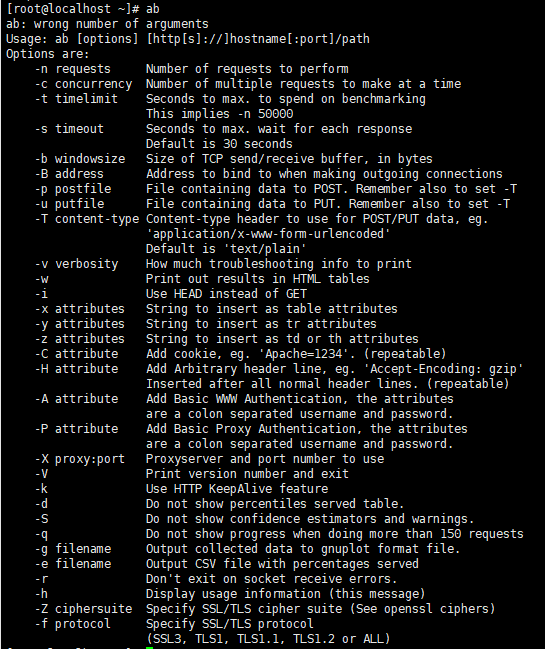
参数说明:
-n 即requests,用于指定压力测试总共的执行次数。
-c 即concurrency,用于指定的并发数。
-t 即timelimit,等待响应的最大时间(单位:秒)。
-b 即windowsize,TCP发送/接收的缓冲大小(单位:字节)。
-p 即postfile,发送POST请求时需要上传的文件,此外还必须设置-T参数。
-u 即putfile,发送PUT请求时需要上传的文件,此外还必须设置-T参数。
-T 即content-type,用于设置Content-Type请求头信息,例如:application/x-www-form-urlencoded,默认值为text/plain。
-v 即verbosity,指定打印帮助信息的冗余级别。
-w 以HTML表格形式打印结果。
-i 使用HEAD请求代替GET请求。
-x 插入字符串作为table标签的属性。
-y 插入字符串作为tr标签的属性。
-z 插入字符串作为td标签的属性。
-C 添加cookie信息,例如:"Apache=1234"(可以重复该参数选项以添加多个)。
-H 添加任意的请求头,例如:"Accept-Encoding: gzip",请求头将会添加在现有的多个请求头之后(可以重复该参数选项以添加多个)。
-A 添加一个基本的网络认证信息,用户名和密码之间用英文冒号隔开。
-P 添加一个基本的代理认证信息,用户名和密码之间用英文冒号隔开。
-X 指定使用的和端口号,例如:"126.10.10.3:88"。
-V 打印版本号并退出。
-k 使用HTTP的KeepAlive特性。
-d 不显示百分比。
-S 不显示预估和警告信息。
-g 输出结果信息到gnuplot格式的文件中。
-e 输出结果信息到CSV格式的文件中。
-r 指定接收到错误信息时不退出程序。
-h 显示用法信息,其实就是ab -help。
测试
模拟并发请求10次,总共请求10万次。
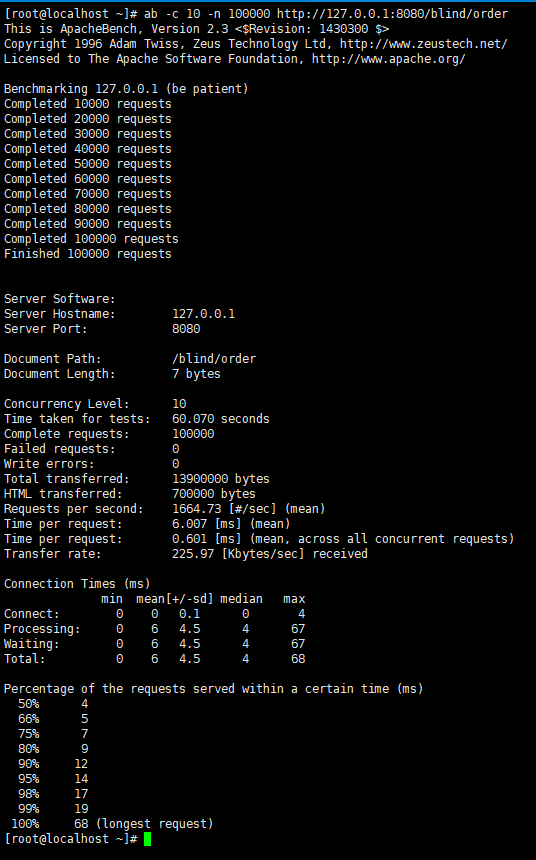
名词解释:
Server Software: (服务器软件名称及版本信息)
Server Hostname: 127.0.0.1(服务器主机名)
Server Port: 8080(服务器端口)
Document Path: /blind/order(供测试的URL路径)
Document Length: 7 bytes(供测试的URL返回的文档大小)
Concurrency Level: 10(并发数)
Time taken for tests: 60.070 seconds(压力测试消耗的总时间)
Complete requests: 100000(总次数)
Failed requests: 0(失败的请求数)
Write errors: 0(网络连接写入错误数)
Total transferred: 13900000 bytes(传输的总数据量)
HTML transferred: 700000 bytes(HTML文档的总数据量)
Requests per second: 1664.73 [#/sec] (mean)(平均每秒的请求数,即服务器的吞吐量)
Time per request: 6.007 [ms] (mean)(所有并发用户(这里是10)都请求一次的平均时间)
Time per request: 0.601 [ms] (mean, across all concurrent requests)(单个用户请求一次的平均时间)
Transfer rate: 225.97 [Kbytes/sec] received(每秒获取的数据长度 (传输速率,单位:KB/s))
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 4
Processing: 0 6 4.5 4 67
Waiting: 0 6 4.5 4 67
Total: 0 6 4.5 4 68
Percentage of the requests served within a certain time (ms)
50% 4 (50%的请求在4ms内返回 )
66% 5 (66%的请求在5ms内返回 )
75% 7
80% 9
90% 12
95% 14
98% 17
99% 19
100% 68 (longest request)
服务器信息
为了进行压力测试,在本地运行了一个虚拟机,可自行提取(其中包括 VMware 和 centos7,提取码:iew6,安装可参考:安装教程)。
配置信息如下:内存为 2G,处理器数量为 2 个
堆空间监控
在默认不配置 JVM 堆内存大小的情况下,JVM 根据默认值来配置当前内存大小。
我们可以通过以下命令来查看堆内存配置的默认值:
java -XX:+PrintFlagsFinal -version | grep HeapSize
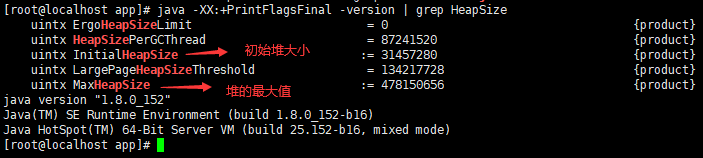
可以看到,这台机器上启动的 JVM 默认最大堆内存大约为 450MB,初始化大小为 30MB左右。
GC监控
调优我们还需要监控GC,JVM 中我们使用 jstat 命令监控一下 JVM 的 GC 情况。
jstat -gc

但是这太多信息了,我们只需要查看我们需要的列:
jstat -gc 5000 20 | awk '{print $13,$14,$15,$16,$17}'
解释:每间隔 5s 总共查询 20 次 GC 情况,且只显示13~17列的数据。
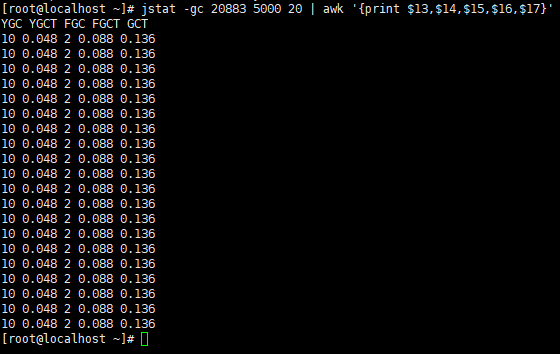
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
具体命令解释可参考:JDK自带性能诊断工具
JVM 内存优化案例
一个高并发系统中的抢购接口,假设高峰时有上万级别的并发请求,且每次请求会产生 20KB 对象(包括订单、用户、优惠券等对象数据),像我之前做过一个机票盲盒的下单接口和机票秒杀的接口,其中就包括一些订单、用户、供应商等对象数据。
因此,虽然这里没有真实的代码场景,但是我们可以通过一个创建一个 1MB 对象的接口来模拟万级并发请求产生大量对象的场景,具体代码如下:
/**
* 类说明:模拟下单接口,注意是模拟,不考虑代码bug问题
*/
@RestController
@RequestMapping("/blind")
public class BlindBoxController {
@RequestMapping("/order")
public String order() {
List list = new ArrayList<>();
Byte[] b = new Byte[1024 * 1024];
list.add(b);
return "success";
}
}
同时,我把 jar 包也提供出来,就是一个简单的SpringBoot项目:demo-0.0.1.jar(提取码:m5qk)
测试项目启动
根据上面提供的 jar 包,我们放到 linux 指定的目录下面,然后把他启动起来:
java -jar demo-0.0.1.jar
然后我们再去查看这个JVM实例占用的堆内存大小:
jmap -heap
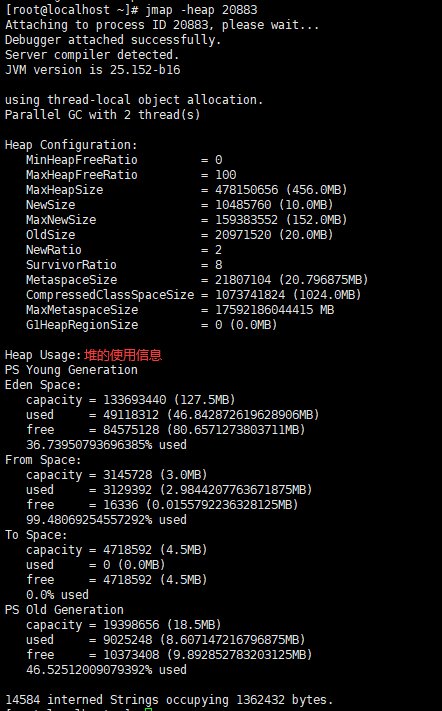
由上图可知,默认情况下,堆的最大内存为456MB,Eden区为127.5MB,From和To区为4.5MB,Old区为18.5MB。
测试前准备
我们主要从三个方面去统计:
- JVM 服务器发生的GC信息,因此在测试请求前先统计上次的GC信息
- 用户的吞吐量(即
Requests per second) - JVM 服务器平均请求处理时间(即
Time per request)
10 个并发/10万总请求
模拟并发请求10次,总共请求10万次。
命令:ab -c 10 -n 100000 url
-
先查看上次GC信息
-
执行并发请求,ab -c 10 -n 100000 http://127.0.0.1:8080/blind/order

-
执行并发请求之后在统计GC信息
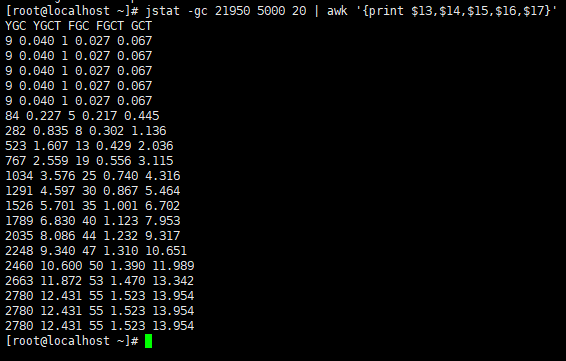
YGC次数:2780 - 10 = 2770次
YGC耗时:12.431 - 0.048 = 12.383s
FGC次数:55 - 2 = 53次
FGC耗时:1.523 - 0.088 = 1.435s
总耗时:13.954 - 0.136 = 13.818s
因此,可以得出以下结论:
- 用户的吞吐量:约 1751/s
- JVM 服务器平均请求处理时间:约 0.5ms
- GC信息:2770 次 YGC,耗时约 12 秒 , 53 次 FGC,耗时约 2 秒左右,GC总耗时约 14 秒
100 个并发/10万总请求
模拟并发请求100次,总共请求10万次。
命令:ab -c 100 -n 100000 url
-
先查看上次GC信息,其实就是上次请求完成后的GC信息
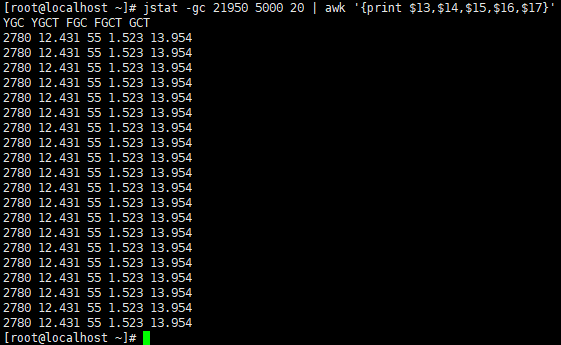
-
执行并发请求,ab -c 100 -n 100000 http://127.0.0.1:8080/blind/order
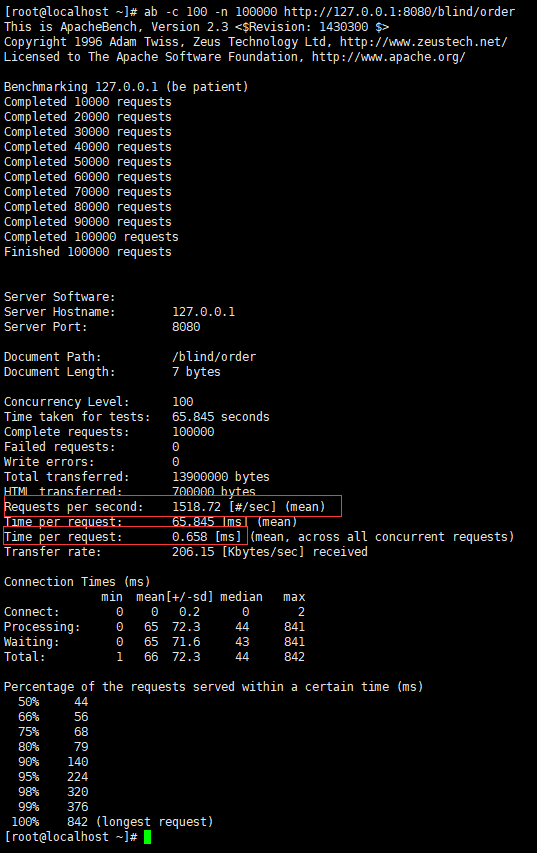
-
执行并发请求之后在统计GC信息
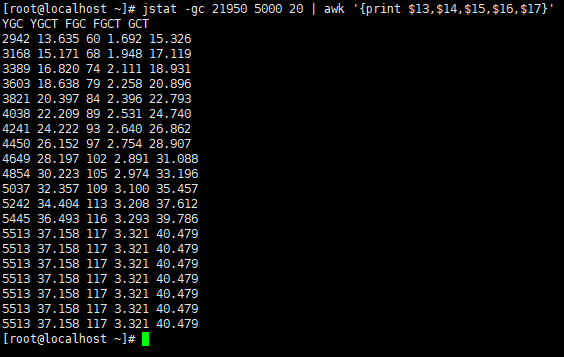
YGC次数:5513 - 2780 = 2733次
YGC耗时:37.158 - 12.431 = 24.727s
FGC次数:117 - 55 = 62次
FGC耗时:3.321 - 1.523 = 1.798s
总耗时:40.479 - 13.954 = 26.525s
因此,可以得出以下结论:
- 用户的吞吐量:约 1518/s
- JVM 服务器平均请求处理时间:约 0.7ms
- GC信息:2733 次 YGC,耗时约 24 秒 , 62 次 FGC,耗时约 2 秒左右,GC总耗时约 26 秒
1000 个并发/10万总请求
模拟并发请求1000次,总共请求10万次。
命令:ab -c 1000 -n 100000 url
-
先查看上次GC信息,其实就是上次请求完成后的GC信息
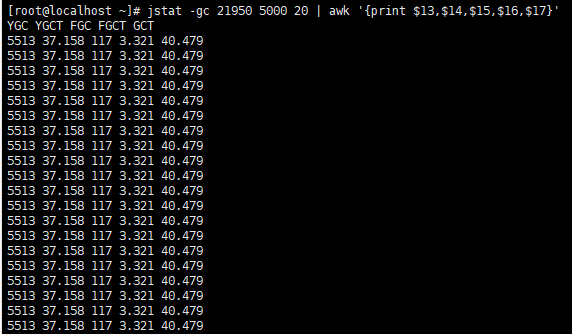
-
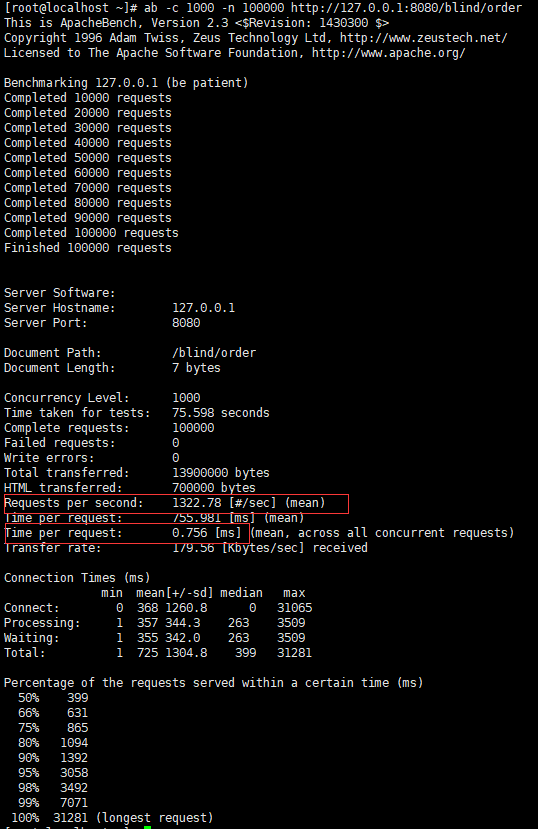
执行并发请求,ab -c 1000 -n 100000 http://127.0.0.1:8080/blind/order
-
执行并发请求之后在统计GC信息
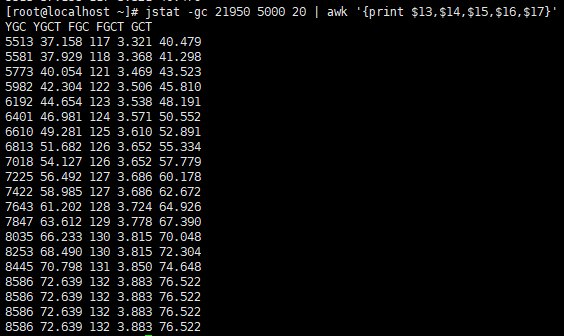
YGC次数:8586 - 5513 = 3073次
YGC耗时:72.639 - 37.158 = 35.481s
FGC次数:132 - 117 = 15次
FGC耗时:3.883 - 3.321 = 0.562s
总耗时:76.522 - 40.479 = 36.043s
因此,可以得出以下结论:
- 用户的吞吐量:约 1322/s
- JVM 服务器平均请求处理时间:约 0.8ms
- GC信息:3073次 YGC,耗时约 35 秒 , 15 次 FGC,耗时约 1 秒左右,GC总耗时约 36 秒
结果分析
默认情况下,堆的最大内存为450MB,Eden区为127.5MB,From和To区为4.5MB,Old区为18.5MB。
| 性能指标 | 10 个并发/10万总请求 | 100 个并发/10万总请求 | 1000 个并发/10万总请求 |
|---|---|---|---|
| 吞吐量 | 1751/s | 1518/s | 1322/s |
| 平均处理时间 | 0.5ms | 0.7ms | 0.8ms |
| GC耗时 | 14s | 26s | 36s |
通过上面的数据我们可以看到,GC 频率、堆内存大小会影响到的每次请求的响应时间,因为堆内存基本被用完了,所以存在大量 MinorGC 和 FullGC,这意味着我们的堆内存严重不足,因此我们可以考虑需要调大堆的内存空间来进行优化。
调优方案
调优方案一:增大堆空间
我们把堆空间加大到 1.5G,然后重启
java -jar -Xms1500m -Xmx1500m demo-0.0.1.jar
然后在进行上面案例测试,因为操作一致,所以这里直接得出结论。
-
10 个并发/10万总请求
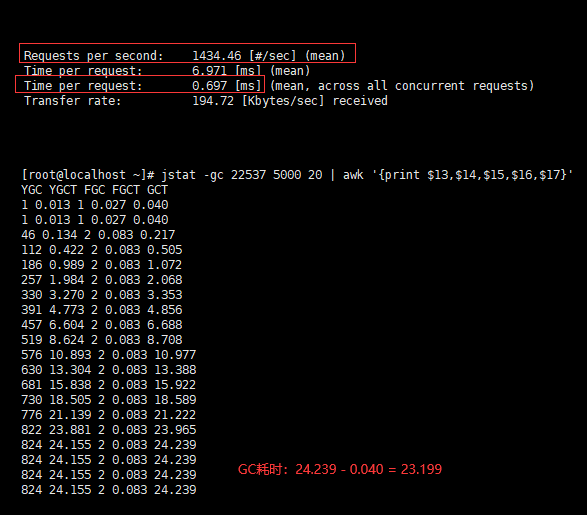
- 用户的吞吐量:约 1434/s
- JVM 服务器平均请求处理时间:约 0.7ms
- GC总耗时:约 24s
-
100 个并发/10万总请求
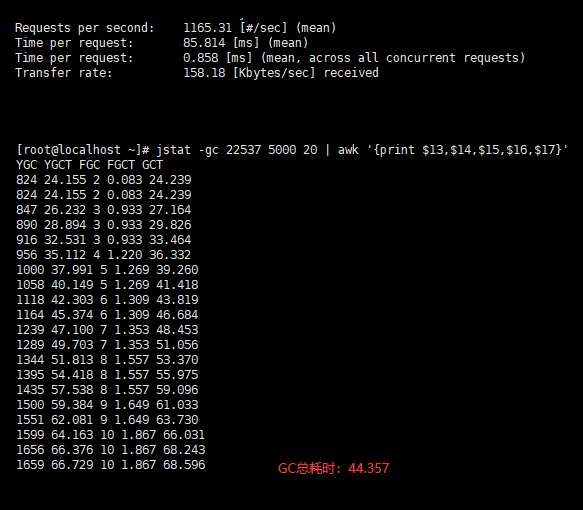
- 用户的吞吐量:约 1165/s
- JVM 服务器平均请求处理时间:约 0.9ms
- GC总耗时:约 45s
-
1000 个并发/10万总请求
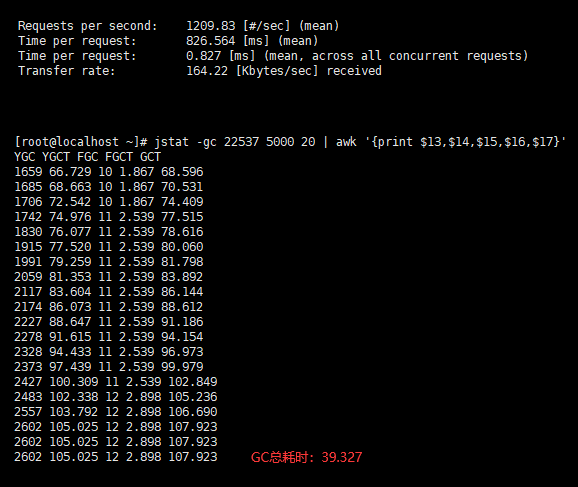
- 用户的吞吐量:约 1209/s
- JVM 服务器平均请求处理时间:0.9ms
- GC总耗时:约 40s
| 性能指标 | 10 个并发/10万总请求 | 100 个并发/10万总请求 | 1000 个并发/10万总请求 |
|---|---|---|---|
| 吞吐量 | 1434/s | 1165/s | 1209/s |
| 平均处理时间 | 0.7ms | 0.9ms | 0.9ms |
| GC耗时 | 24s | 45s | 40s |
调优方案二:增大堆的新生代
我们把堆空间加大到 1.5G,增大堆的新生代的内存空间,并且Eden区和Survivor区按照8:1分配。
java -jar -Xms1500m -Xmx1500m -Xmn1000m -XX:SurvivorRatio=8 demo-0.0.1.jar
然后在进行上面案例测试,因为操作一致,所以这里直接得出结论。
-
10 个并发/10万总请求
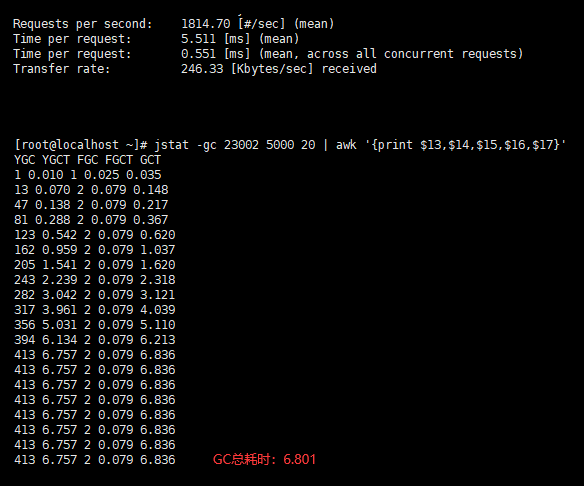
- 用户的吞吐量:约 1815/s
- JVM 服务器平均请求处理时间:约 0.5ms
- GC总耗时:约 7s
-
100 个并发/10万总请求
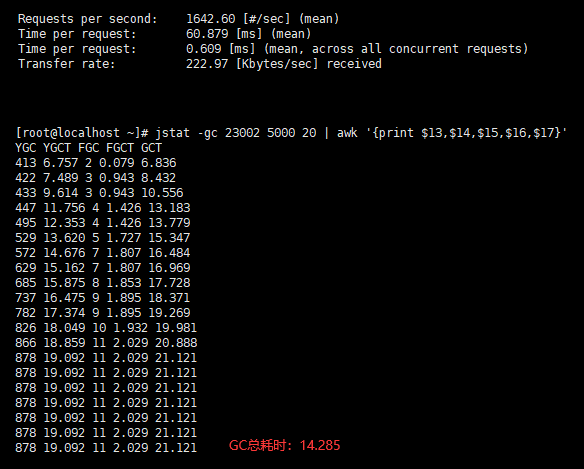
- 用户的吞吐量:约 1642/s
- JVM 服务器平均请求处理时间:约 0.6ms
- GC总耗时:约 14s
-
1000 个并发/10万总请求
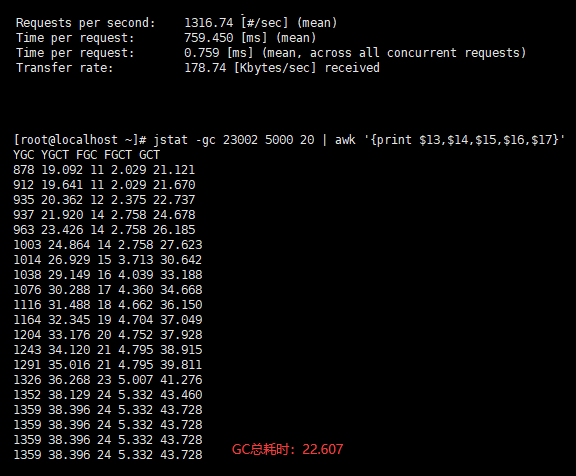
- 用户的吞吐量:约 1316/s
- JVM 服务器平均请求处理时间:0.7ms
- GC总耗时:约 23s
| 性能指标 | 10 个并发/10万总请求 | 100 个并发/10万总请求 | 1000 个并发/10万总请求 |
|---|---|---|---|
| 吞吐量 | 1815/s | 1642/s | 1316/s |
| 平均处理时间 | 0.5ms | 0.6ms | 0.7ms |
| GC耗时 | 7s | 14s | 23s |
调优策略
我们把上面3种情况总结如下:
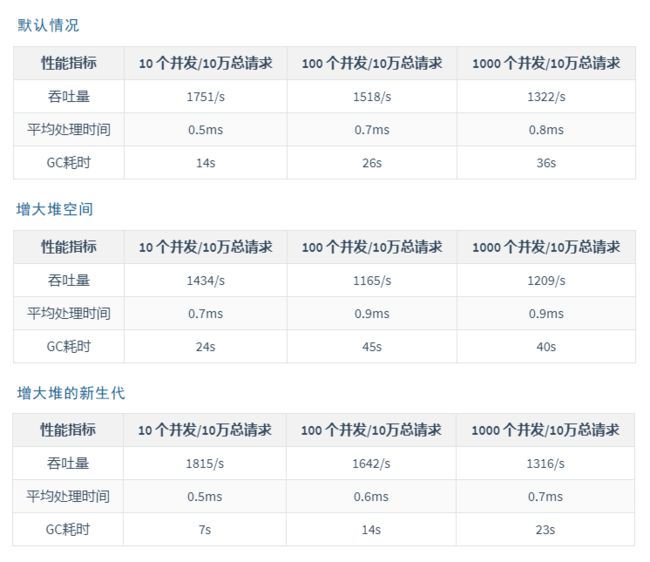
一般情况下,高并发业务场景中,需要一个比较大的堆空间,而默认参数情况下,堆空间不会很大,所以我们需要进行调整。
但是不要单纯的调整堆的总大小,要调整新生代和老年代的比例,以及 Eden 区还有 From 区,还有 To 区的比例。
所以在我们上述的测试中,调整方案二,得到结果是最好的。在三种测试情况下都能够有非常好的性能指标,同时 GC 耗时相对控制也较好。
对于方案一,就是单纯的加大堆空间,里面的比例不适合高并发场景,反而导致堆空间变大,没有明显减少 GC 的次数,但是每次 GC 需要检索对象的堆空间更大,所以 GC 耗时更长。
对于方案二,调整为一个很大的新生代和一个较小的老年代,原因是这样可以尽可能回收掉大部分短期对象(大部分对象朝生夕死),减少中期的对象,而老年代尽存放长期存活对象。
通过上面的场景测试,我们可以知道影响其性能主要原因是由于新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此我们可以通过增大新生代空间来降低 Minor GC 的频率。
性能分析
一次 Minor GC 时间是由两部分组成:T1(扫描新生代)和 T2(复制存活对象)。 因此:
默认情况:假设一个对象在 Eden 区的存活时间为 500ms,Minor GC 的时间间隔是 300ms,因为这个对象存活时间 > 间隔时间,那么正常情况下,Minor GC 的时间为 :T1+T2。
方案一:整堆空间加大,但是新生代没有增大多少(只增加了一点点),那么正常情况下,新生代的扫描时间肯定会变长(假设为原来1.5倍的T1),假设对象在 Eden 区的存活时间为 500ms,Minor GC 的时间可能会扩大到 400ms,因为这个对象存活时间 > 间隔时间,因此Minor GC 的时间为 :1.5*T1+T2。
方案二:当我们增大新生代空间,假设新生代的扫描时间为原来的2倍(2 * T1),因此Minor GC 的时间间隔可能会扩大到 600ms,假设对象在 Eden 区的存活时间为 500ms,此时这个对象存活时间 < 间隔时间,因此这个对象会在 Eden 区中被回收掉,此时就不存在复制存活对象了(对象的复制是非常耗时的),所以再发生 Minor GC 的时间为: 2*T1+T2*0 = 2*T1
可见,扩容后,Minor GC 时增加了 T1,但省去了 T2 的时间。
在 JVM 中,复制对象的成本要远高于扫描成本。如果在堆内存中存在较多的长期存活的对象,此时增加年轻代空间,反而会增加 Minor GC 的时间。如果堆中的短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。因此,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden 区的大小。
这个就解释了在上面2中内存调整方案中,都是增大内存,方案一为什么性能还差些,但是到了方案二话,性能就有明显的上升。所以在面试中经如果被问到怎么调优,不仅仅是一句简单的加内存就完事了。
推荐策略
主要从堆的新生代和老年的内存大小以及功能性需求推荐。
新生代大小
-
响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,新生代收集发生的频率也是最小的,同时,减少到达老年代的对象。
-
吞吐量优先的应用:尽可能的设置大,可能到达 GB 的程度,因为对响应时间没有要求,垃圾收集可以并行进行,一般适合 8CPU 以上的应用,避免设置过小,当新生代设置过小时会导致:
- MinorGC 次数更加频繁。
- 可能导致 MinorGC 对象直接进入老年代,如果此时老年代满了,会触发 FullGC(会带来上下文切换,增加系统的性能开销)。
老年代大小
-
响应时间优先的应用:老年代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。
- 如果堆设置小了,可能会造成内存碎片,高回收频率以及应用暂停而使用传统的标记清除方式。
- 如果堆设置大了,则需要较长的收集时间,最优化的方案,一般需要参考以下数据获得:并发垃圾收集信息、持久代并发收集次数、传统 GC 信息、花在新生代和老年代回收上的时间比例。
-
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的新生代和一个较小的老年代,原因是这样可以尽可能回收掉大部分短期对象,减少中期的对象,而老年代尽存放长期存活对象。
GC优化
在上面的案例中,如果说要追求响应时间,那就得通过GC优化。
GC 性能衡量指标
吞吐量
这里的衡量吞吐量是指应用程序所花费的时间和系统总运行时间的比值。我们可以按照这个公式来计算:
GC的吞吐量 = 系统总运行时间 = 应用程序耗时 + GC 耗时
如果系统运行了 100 分钟,GC 耗时 1 分钟,则系统吞吐量为 99%。一般来说,GC 的吞吐量不能低于 95%。
停顿时间
指垃圾回收器正在运行时,应用程序的暂停时间(即STW)。对于串行回收器而言,停顿时间可能会比较长,而使用并发回收器,由于垃圾收集器和应用程序交替运行,程序的停顿时间就会变短,但其效率很可能不如独占垃圾收集器,系统的吞吐量也很可能会降低。
垃圾回收频率
通常垃圾回收的频率越低越好,增大堆内存空间可以有效降低垃圾回收发生的频率,但同时也意味着堆积的回收对象越多,最终也会增加回收时的停顿时间。所以我们需要适当地增大堆内存空间,保证正常的垃圾回收频率即可。
分析 GC 日志
通过 JVM 参数预先设置 GC 日志,几种 JVM 参数设置如下:
-XX:+PrintGC 输出 GC 日志
-XX:+PrintGCDetails 输出 GC 的详细日志
-XX:+PrintGCTimeStamps 输出 GC 的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出 GC 的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行 GC 的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
正常的话GC日志一般来说都是都是运维人员操作,我们这里通过虚拟机来测试。
1000 个并发/10万总请求:ab -c 1000 -n 100000 http://127.0.0.1:8080/blind/order
默认情况
java -jar -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/app/gclogs demo-0.0.1.jar
调优方案二
java -jar -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/app/gclogs2 -Xms1500m -Xmx1500m -Xmn1000m -XX:SurvivorRatio=8 demo-0.0.1.jar
怎么分析
得到两次GC日志以后,使用日志工具 gcViewer(提取码:r9bh)来分析,官方使用文档:点击。
我们对比GC的暂停时间
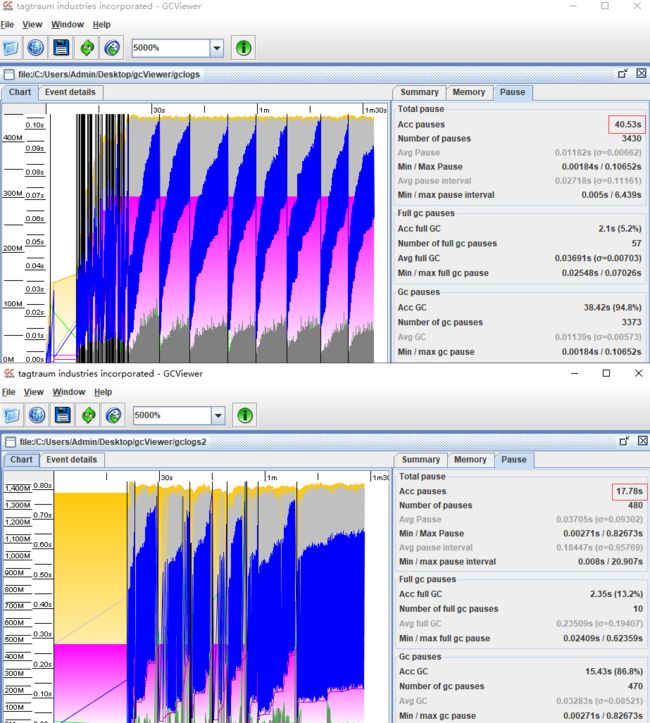
很明显第一个暂停总耗时比第二个要多很多,一个是 40 秒,一个是 18 秒左右,相差很多,这个本质上也可以分析出来,对于系统来说,第二个的 GC 日志情况更加的好。
调优策略
降低 Minor GC 频率
增大新生代空间,即调优方案二。新生代空间增大,也就意味着未死的对象会增多,如果未进入老年代,则下次GC回收对象会变多,若进入老年代,同时也会影响下次Full GC。
降低 Full GC 的频率
由于堆内存空间不足或老年代对象太多,会触发 Full GC,频繁的 Full GC 会带来上下文切换,增加系统的性能开销。
减少创建大对象
在平常的业务场景中,我们一次性从数据库中查询出一个大对象用于 web 端显示。比如,一次性查询出 60 个字段的业务操作,这种大对象如果超过年轻代最大对象阈值,会被直接创建在老年代,即使被创建在了年轻代,由于年轻代的内存空间有限,通过 Minor GC 之后也会进入到老年代。这种大对象很容易产生较多的 Full GC。
增大堆内存空间
在堆内存不足的情况下,增大堆内存空间,且设置初始化堆内存为最大堆内存,也可以降低 Full GC 的频率。
选择合适的 GC 回收器
如果要求每次操作的响应时间必须在 500ms 以内。这个时候我们一般会选择响应速度较快的 GC 回收器,堆内存比较小的情况下(小于6G)选择 CMS(Concurrent Mark Sweep)回收器,堆内存比较大的情况下(大于8G选择)G1 回收器。
总结
GC 调优是个很复杂、很细致的过程,要根据实际情况调整,不同的机器、不同的应用、不同的性能要求调优的手段都是不同的,这些都需要平时去积累,去观察,去实践。一般调优的思路:
- 记录好日志。
- 对程序做好性能监控。
- 根据日志和性能监控数据修改程序。
- 使用专业工具通过不同的JVM参数进行压测并获得最佳配置。
需要注意的是任何调优都需要结合场景,明确已知问题和性能目标,绝大部分情况下,并不需要特意去调优JVM,如果出现问题,我们最主要做的应该是去检查我们的代码,以免引入新的 Bug,不能为了调优而调优,以免带来风险和弊端。