微服务学习|初识MQ、RabbitMQ快速入门、SpringAMQP
初识MQ
同步通讯和异步通讯
同步通讯是实时性质的,就好像你用手机与朋友打视频电话,但是,别人再想与你视频就不行了,异步通讯不要求实时性,就好像你用手机发短信,好多人都能同时给你发短信,你都可以收到,而且不用及时回复。
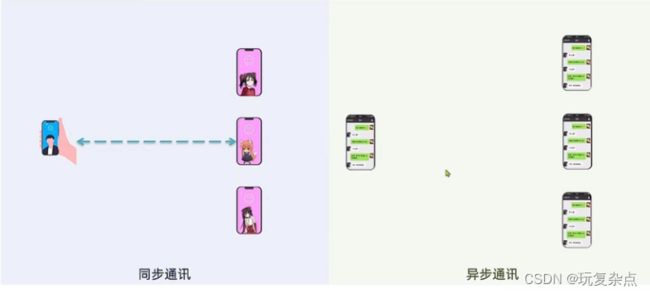
同步调用的问题
微服务间基于Feign的调用就属于同步方式,存在一些问题
比如用户调用支付服务时,它需要先后调用订单服务、仓储服务、短信服务等,都调用结束后,支付服务再返回用户相关信息,故这个过程的响应时间实际上就是所有这些相关服务执行之后所用时间之和,这样是非常影响效率的。但是也有优点,时效性较强,可以立即得到结果
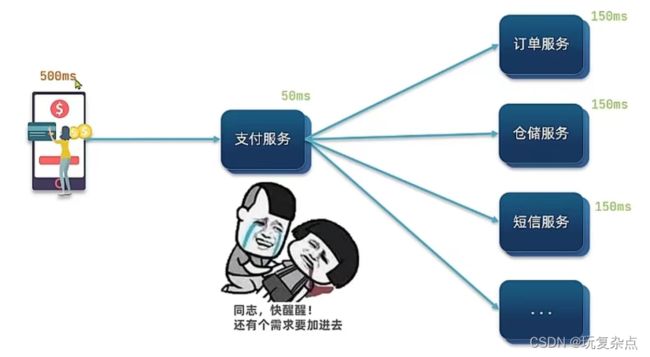
同步调用存在的问题
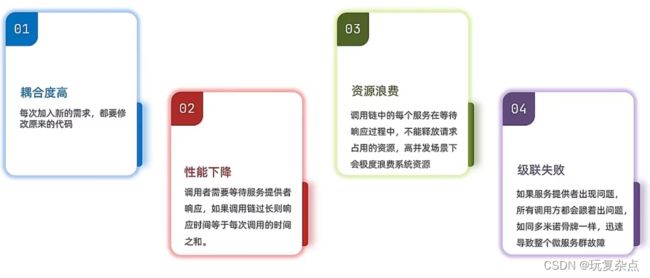
1.如果我们想对支付服务增加一些功能,增加一些别的服务,为了让支付功能调用这个新服务,我们需要改动相关的代码
2.调用者需要等待服务提供者响应,如果调用链过长则响应时间等于每次调用的时间之和。就如支付服务必须要等订单服务、仓储服务、短信服务都执行后,才能给出响应,很慢。
3.上述支付服务在等待其余服务响应的时候,资源是不释放的,一直在等待,高并发场景下嫉妒浪费系统资源
4.如果其中一个服务出现问题,例如仓储服务出现问题,则整个响应就无法进行了,就整个崩掉了。
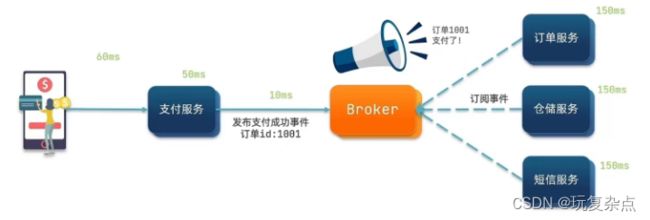
异步调用方案
异步调用常见实现就是事件驱动模式
比如用户发起支付服务,此时会将该消息发给Broker,然后就不用管后面了,支付服务直接给用户响应,不需要管订单、仓储、短信这些服务的执行了,这几个服务提前订阅了这个Broker,所以,支付服务消息来了,会从Broker中获取到消息,然后执行自己的逻辑就好。
优势一:服务解耦
当我们对支付服务增加一些新的功能,新服务时,只需要将该服务订阅这个Broker即可,不需要改动支付服务的代码
优势二:性能提升,吞吐量提高
因为是异步调用,支付服务不需要关注其相关的其他服务执行,只需将支付消息发给Broker即可,然后就能直接给用户响应,非常快,后续相关的服务只需要从Broker中收到该消息后执行相关的业务操作就可。
优势三:服务没有强依赖,不担心级联失败问题
其中一个服务发生故障,整个支付服务不会因为这个服务故障了而停掉,支付服务依然会直接给用户响应。
优势四:流量削峰
因为有Broker的缘故,如果并发量比较大,这些消息都会暂存在Broker中,慢慢的让其余各服务去处理,所以能够很好的将流量削峰。

异步通信的缺点
依赖于Broker的可靠性、安全性、吞吐能力
架构复杂了,业务没有明显的流程线,不好追踪管理
什么是MQ?
MQ(MessageQueue),中文是消息队列,字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。简单来讲,Kafka对并发场景性能更高,但是没有RabbitMQ安全,所以一般情况下就用RabbitMQ就可,中规中矩。

RabbitMQ快速入门
单机部署
我们在Centos7虚拟机中使用Docker来安装。
方式一:在线拉取

方式二:从本地加载
在课前资料已经提供了镜像包
上传到虚拟机中后,使用命令加载镜像即可

安装MQ
执行下面的命令来运行MQ容器
这里第一个15672端口是用来登录RabbitMQ控制台的,第二个5672端口是用来进行异步调用的。这里也要设置RabbitMQ控制台的登录账号itcast密码123321

用宿主机ip+第一个端口15672来访问RabbitMQ控制台,账号itcast密码123321,登录即可
RabbitMQ的结构和概念

RabbitMQ中的几个概念
channel:操作MQ的工具
exchange:路由消息到队列中
queue:缓存消息
virtualhost: 虚拟主机,是对queue、exchange等资源的逻辑分组
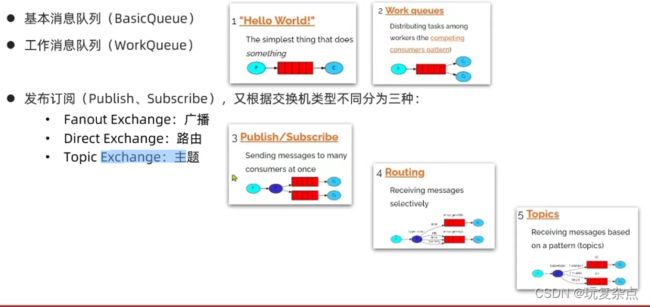
常见消息模型
MQ的官方文档中给出了5个MQ的Demo示例,对应了几种不同的用法
HelloWorld案例
官方的Helloworld是基于最基础的消息队列模型来实现的,只包括三个角色:
publisher:消息发布者,将消息发送到队列queue
queue:消息队列,负责接受并缓存消息
consumer:订阅队列,处理队列中的消息

编写publisher消息发布者代码,新建一个连接工厂,配置本机RabbitMQ的异步调用端口,以及账号密码,然后建立一个连接,connection对象。

连接对象connection生成后,我们可以在RabbitMQ的控制台,看到了这个新生成的连接

然后用这个connection连接对象创建一个通道channel对象

执行完后,控制台也能够看到这个新建的通道
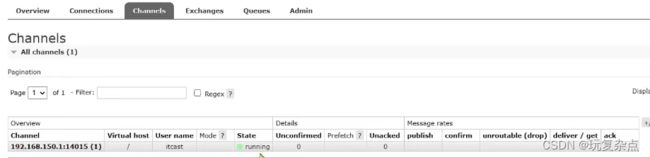
然后用channel对象新建一个名为simple.queue的队列,并给这个队列发消息

可以在控制台看到这个新创建的名为simple.queue的队列,并且队列中已经有了我们刚发送的消息
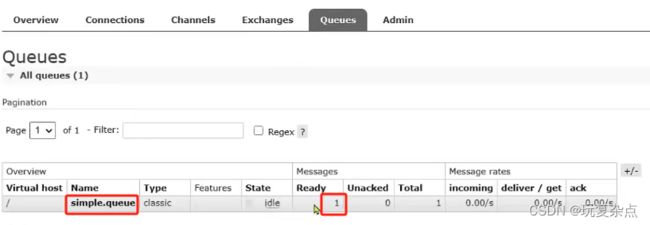
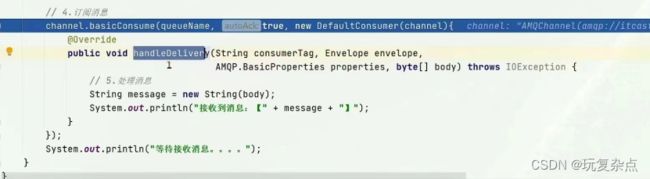
订阅该队列的consumer编写,前三步与publisher一致

最后一步变成了利用channel将消费者与队列绑定,在handleDelivery()中定义consumer的消费行为
SpringAMQP
什么是SpringAMQP

案例:利用SpringAMQP实现HelloWorld中的基础消息队列功能
流程如下:
1.在父工程中引入spring-amqp的依赖
2.在publisher服务中利用RabbitTemplate发送消息到simple.queue这个队列
3.在consumer服务中编写消费逻辑,绑定simple.queue这个队列
步骤1: 引入AMQP依赖
因为publisher和consumer服务都需要amqp依赖,因此这里把依赖直接放到父工程mq-demo中

步骤2: 在publisher中编写测试方法,向simple.queue发送消息
1.在publisher服务中编写application.yml,添加mq连接信息

2.在publisher服务中新建一个测试类,编写测试方法

运行后,可在RabbitMQ控制台看到该队列,以及队列中有消息了

什么是AMQP?
应用间消息通信的一种协议,与语言和平台无关。
SpringAMOP如何发送消息?
引入amqp的starter依赖
配置RabbitMo地址
利用RabbitTemplate的convertAndSend方法
步骤3: 在consumer中编写消费逻辑,监听simple.queue
1.在consumer服务中编写application.yml,添加mq连接信息
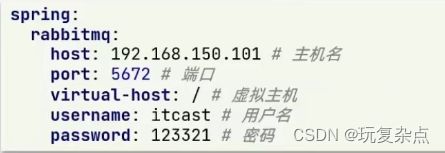
2.在consumer服务中新建一个类,编写消费逻辑

SpringAMQP如何接收消息?
引入amqp的starter依赖
配置RabbitMQ地址
定义类,添加@Component注解
类中声明方法,添加@RabbitListener注解,方法参数就是消息
注意:消息一旦消费就会从队列删除,RabbitMQ没有消息回溯功能
Work Queue 工作队列
Work queue,工作队列,可以提高消息处理速度,避免队列消息堆积,也就是两个消费者同时订阅一个队列,共同处理队列中的消息

案例:模拟WorkQueue,实现一个队列绑定多个消费者
基本思路如下
1.在publisher服务中定义测试方法,每秒产生50条消息,发送到simple.queue
2.在consumer服务中定义两个消息监听者,都监听simple.queue队列
3.消费者1每秒处理50条消息,消费者2每秒处理10条消息
publisher服务中定义测试方法,每20ms发送一个消息,发送50次,也就是1秒向消息队列中发送50条消息
定义两个消息监听者,都监听simple.queue队列,消费者1一秒钟能处理50条消息,消费者2一秒钟能处理5条消息,故理论上这两个消费者能在1秒内处理完publisher发送的所有(50条)消息

但是,运行起来发现,并不是按照能力强的处理的消息多这样来分配的,而是这两个监听者,各分到了一般的消息,消费者1处理偶数号的消息,消费者2处理奇数的消息,这样最终结果就是消费者1很快的处理完了总共消息的一半,25条消息,而消费者2却花了好多秒去处理分给自己25条消息,最终的结果就是这两个消费者不能够在1秒内处理完所有消息。
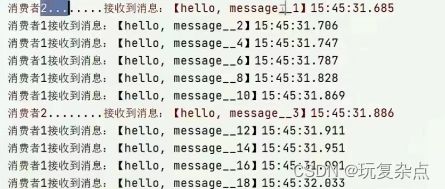
实际上,它是有一个预取机制造成的这样结果,进入到消息队列中的消息会被提前预取给消费者,默认的是一人一个,这样平均分配的,消费者还没处理完,但是消息都已经全部预取出来给了对应消费者,我们可以配置预取机制,让每个消费者预取消息的数量为1,每次只能获取一消息,处理完成才能获取下一个消息,这样就可以做到能者多劳的结果。

消费预取限制
修改application.yml文件,设置preFetch这个值,可以控制预取消息的上限

配置完后再启动,就发现了消费者1执行的消息要比消费者2执行的消息多了,而不是简单的将消息都平均分配给监听的两个消费者。

Work模型的使用
多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
通过设置prefetch来控制消费者预取的消息数量
发布 ( Publish )、订阅 ( Subscribe )
发布订阅模式与之前案例的区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)。
常见exchange类型包括:
Fanout:广播
Direct: 路由
Topic: 话题

发布订阅-Fanout Exchange
Fanout Exchange会将接收到的消息路由到每一个跟其绑定的queue

案例:利用SpringAMQP演示FanoutExchange的使用
实现思路如下:
1.在consumer服务中,利用代码声明队列、交换机,并将两者绑定
2.在consumer服务中,编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
3.在publisher中编写测试方法,向itcast.fanout发送消息

步骤1: 在consumer服务声明Exchange、Queue、 Binding
在consumer服务常见一个类,添加@Configuration注解,并声明FanoutExchange、Queue和绑定关系对象Binding,代码如下


启动后,可以在RabbitMQ控制台看到我们声明的交换机与两个队列完成绑定。
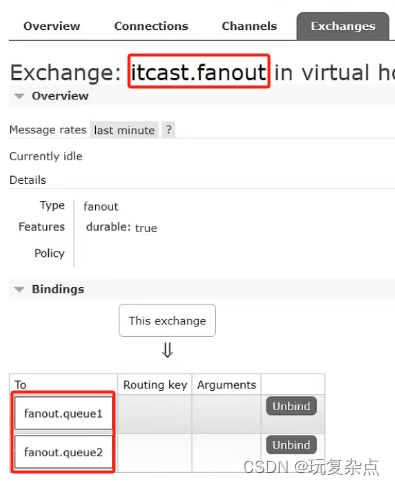
步骤2: 在consumer服务声明两个消费者
在consumer服务的SpringRabbitListener类中,添加两个方法,分别监听fanout.queue1和fanout.queue2

步骤3: 在publisher服务发送消息到FanoutExchange
在publisher服务的SpringAmqpTest类中添加测试方法

项目启动,两个消费者都收到了这个publisher发送的消息

交换机的作用是什么?
接收publisher发送的消息
将消息按照规则路由到与之绑定的队列
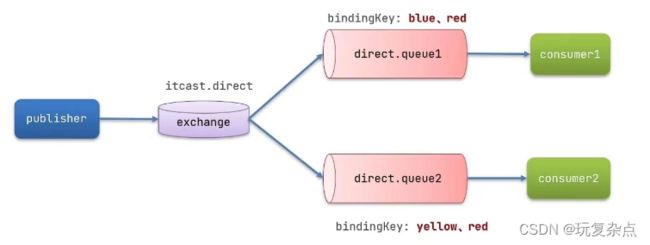
发布订阅-DirectExchange
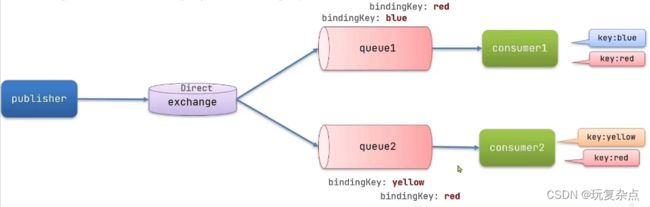
Direct Exchange 会将接收到的消息根据规则路由到指定的Queue,因此称为路由模式 (routes)。每一个Queue都与Exchange设置一个BindingKey
发布者发送消息时,指定消息的RoutingKey
Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
案例:利用SpringAMQP演示DirectExchange的使用
实现思路如下:
1.利用@RabbitListener声明Exchange、Queue、RoutingKey
2.在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
3.在publisher中编写测试方法,向itcast.direct发送消息
步骤1: 在consumer服务声明Exchange、Queue
1.在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2.
2.并利用@RabbitListener声明Exchange、Queue、RoutingKey

步骤2: 在publisher服务发送消息到DirectExchange
在publisher服务的SpringAmqpTest类中添加测试方法,convertAndSend的第二个参数就是RoutingKey,如果是red,则两个消费者都可收到,是blue,则只有消费者1收到,yellow则只有消费者2收到。

描述下Direct交换机与Fanout交换机的差异?
Fanout交换机将消息路由给每一个与之绑定的队列
Direct交换机根据RoutingKey判断路由给哪个队列
如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
@Queue
@Exchange
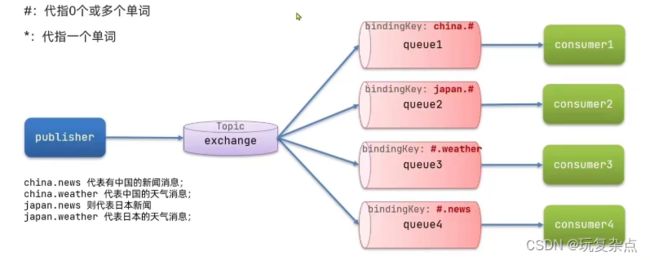
发布订阅-TopicExchange
TopicExchange与DirectExchange类似,区别在于routingKey必须是多个单词的列表,并且以.分割。Queue与Exchange指定BindingKey时可以使用通配符:
#:代指0个或多个单词
*:代指一个单词
案例:利用SpringAMQP演示TopicExchange的使用
实现思路如下:
1.并利用@RabbitListener声明Exchange、Queue、RoutingKey
2.在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
3.在publisher中编写测试方法,向itcast.topic发送消息

步骤1: 在consumer服务声明Exchange、Queue
1.在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
2.并利用@RabbitListener声明Exchange、Queue、RoutingKey

步骤2: 在publisher服务发送消息到TopicExchange
在publisher服务的SpringAmqpTest类中添加测试方法,如果RoutingKey是china.news,则两个消费者都能够接收到消息,如果为china.weather,则只有消费者1能收到消息,如果是usa.news,则只有消费者2能收到消息

消息转换器
案例:测试发送Object类型消息
说明:在SpringAMQP的发送方法中,接收消息的类型是object,也就是说我们可以发送任意对象类型的消息,SpringAMOP会帮我们序列化为字节后发送
先在consumer中的fanoutConfig中声明一个队列object.queue

在publisher中发送消息以测试

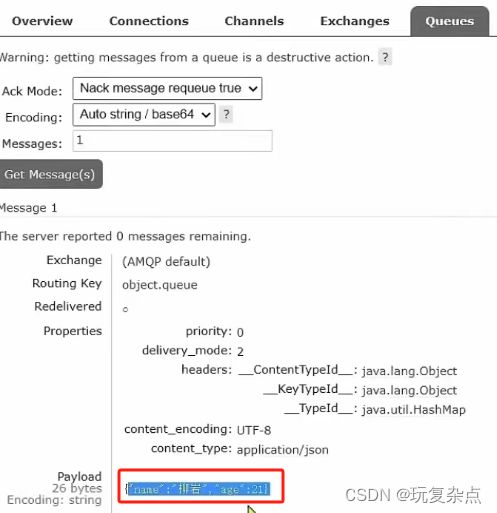
执行完publisher发消息后,RabbitMQ控制台查看object.queue队列中刚收到的消息,看到为乱码,被序列化了

Spring的对消息对象的处理是由org.springframeworkamqp.support.converterMessageConverter来处理的。而默认实现是simpleMessageConverter,基于]DK的ObjectOutputStream完成序列化。
如果要修改只需要定义一个MessaeConverter 类型的Bean即可。推荐用ISON方式序列化,步骤如下:
我们在publisher服务引入依赖

我们在publisher服务声明MessageConverter,在该服务的主启动函数中声明即可。

再次重新执行完publisher发消息后,RabbitMQ控制台查看object.queue队列中刚收到的消息,看到消息已经成为了json格式,而不是乱码了
我们在consumer服务引入Jackson依赖

我们在consumer服务定义MessageConverter,在该服务的主启动函数中声明即可
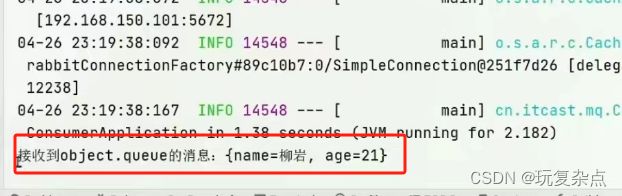
然后定义一个消费者,监听object.queue队列并消费消息

服务启动后,这个consumer消费者收到了这个json消息。
SpringAMQP中消息的序列化和反序列化是怎么实现的?
利用MessageConverter实现的,默认是JDK的序列化
注意发送方与接收方必须使用相同的MessageConverter